यह आलेख तालिका के भावों के बारे में श्रृंखला का आठवां भाग है। अब तक मैंने टेबल एक्सप्रेशन की पृष्ठभूमि प्रदान की, व्युत्पन्न तालिकाओं के तार्किक और अनुकूलन दोनों पहलुओं, सीटीई के तार्किक पहलुओं और सीटीई के कुछ अनुकूलन पहलुओं को कवर किया। इस महीने मैं सीटीई के अनुकूलन पहलुओं का कवरेज जारी रखता हूं, विशेष रूप से यह संबोधित करते हुए कि कैसे कई सीटीई संदर्भों को संभाला जाता है।
यह आलेख तालिका के भावों के बारे में श्रृंखला का आठवां भाग है। अब तक मैंने टेबल एक्सप्रेशन की पृष्ठभूमि प्रदान की, व्युत्पन्न तालिकाओं के तार्किक और अनुकूलन दोनों पहलुओं, सीटीई के तार्किक पहलुओं और सीटीई के कुछ अनुकूलन पहलुओं को कवर किया। इस महीने मैं सीटीई के अनुकूलन पहलुओं का कवरेज जारी रखता हूं, विशेष रूप से यह संबोधित करते हुए कि कैसे कई सीटीई संदर्भों को संभाला जाता है।
अपने उदाहरणों में मैं नमूना डेटाबेस TSQLV5 का उपयोग करना जारी रखूंगा। आप यहां TSQLV5 बनाने और पॉप्युलेट करने वाली स्क्रिप्ट और इसके ईआर आरेख यहां पा सकते हैं।
एकाधिक संदर्भ और गैर-निर्धारणवाद
पिछले महीने मैंने समझाया और दिखाया कि सीटीई अननेस्टेड हो जाते हैं, जबकि अस्थायी टेबल और टेबल वेरिएबल वास्तव में डेटा जारी रखते हैं। मैंने इस संदर्भ में सिफारिशें प्रदान कीं कि जब सीटीई का उपयोग करना समझ में आता है बनाम जब क्वेरी प्रदर्शन के दृष्टिकोण से अस्थायी वस्तुओं का उपयोग करना समझ में आता है। लेकिन समाधान के प्रदर्शन से परे विचार करने के लिए सीटीई ऑप्टिमाइज़ेशन, या भौतिक प्रसंस्करण का एक और महत्वपूर्ण पहलू है- बाहरी क्वेरी से सीटीई के कई संदर्भों को कैसे संभाला जाता है। यह महसूस करना महत्वपूर्ण है कि यदि आपके पास एक ही सीटीई के कई संदर्भों के साथ एक बाहरी क्वेरी है, तो प्रत्येक अलग से अननेस्टेड हो जाता है। यदि आपके पास सीटीई की आंतरिक क्वेरी में गैर-निर्धारक गणनाएं हैं, तो उन गणनाओं के अलग-अलग संदर्भों में अलग-अलग परिणाम हो सकते हैं।
उदाहरण के लिए कहें कि आप CTE की आंतरिक क्वेरी में SYSDATETIME फ़ंक्शन को लागू करते हैं, जिससे dt नामक एक परिणाम कॉलम बनता है। आम तौर पर, इनपुट में कोई बदलाव नहीं मानते हुए, एक अंतर्निहित फ़ंक्शन का मूल्यांकन प्रति क्वेरी और संदर्भ में एक बार किया जाता है, भले ही इसमें शामिल पंक्तियों की संख्या कुछ भी हो। यदि आप बाहरी क्वेरी से केवल एक बार सीटीई को संदर्भित करते हैं, लेकिन डीटी कॉलम के साथ कई बार इंटरैक्ट करते हैं, तो सभी संदर्भों को एक ही फ़ंक्शन मूल्यांकन का प्रतिनिधित्व करना चाहिए और समान मान वापस करना चाहिए। हालाँकि, यदि आप बाहरी क्वेरी में कई बार सीटीई का उल्लेख करते हैं, तो चाहे वह सीटीई को संदर्भित करने वाली कई उपश्रेणियों के साथ हो या एक ही सीटीई के कई उदाहरणों के बीच एक जुड़ाव हो (जैसे कि C1 और C2 के रूप में उपनाम), C1.dt के संदर्भ और C2.dt अंतर्निहित अभिव्यक्ति के विभिन्न मूल्यांकनों का प्रतिनिधित्व करता है और इसके परिणामस्वरूप अलग-अलग मान हो सकते हैं।
इसे प्रदर्शित करने के लिए, निम्नलिखित तीन बैचों पर विचार करें:
-- Batch 1
DECLARE @i AS INT = 1;
WHILE @@ROWCOUNT = 1
SELECT @i += 1 WHERE SYSDATETIME() = SYSDATETIME();
PRINT @i;
GO
-- Batch 2
DECLARE @i AS INT = 1;
WHILE @@ROWCOUNT = 1
WITH C AS ( SELECT SYSDATETIME() AS dt )
SELECT @i += 1 FROM C WHERE dt = dt;
PRINT @i;
GO
-- Batch 3
DECLARE @i AS INT = 1;
WHILE @@ROWCOUNT = 1
WITH C AS ( SELECT SYSDATETIME() AS dt )
SELECT @i += 1 WHERE (SELECT dt FROM C) = (SELECT dt FROM C);
PRINT @i;
GO मैंने अभी जो समझाया है, उसके आधार पर क्या आप पहचान सकते हैं कि किस बैच में अनंत लूप है और जो किसी बिंदु पर अलग-अलग मूल्यों का मूल्यांकन करने वाले विधेय के दो तुलनाओं के कारण रुक जाएगा?
याद रखें कि मैंने कहा था कि SYSDATETIME जैसे अंतर्निहित नोडेटर्मिनिस्टिक फ़ंक्शन के लिए कॉल का मूल्यांकन प्रति क्वेरी और संदर्भ में एक बार किया जाता है। इसका मतलब है कि बैच 1 में आपके पास दो अलग-अलग मूल्यांकन हैं और लूप के पर्याप्त पुनरावृत्तियों के बाद वे अलग-अलग मान प्राप्त करेंगे। इसे अजमाएं। कोड ने कितने पुनरावृत्तियों की रिपोर्ट की?
बैच 2 के लिए, कोड में एक ही सीटीई उदाहरण से डीटी कॉलम के दो संदर्भ हैं, जिसका अर्थ है कि दोनों एक ही फ़ंक्शन मूल्यांकन का प्रतिनिधित्व करते हैं और समान मान का प्रतिनिधित्व करना चाहिए। नतीजतन, बैच 2 में एक अनंत लूप है। इसे जितनी बार चाहें उतनी समय तक चलाएं, लेकिन अंततः आपको कोड निष्पादन को रोकना होगा।
बैच 3 के लिए, बाहरी क्वेरी में CTE C के साथ इंटरैक्ट करने वाली दो अलग-अलग उपश्रेणियाँ हैं, प्रत्येक एक अलग उदाहरण का प्रतिनिधित्व करती है जो अलग से एक अननेस्टिंग प्रक्रिया से गुजरती है। कोड स्पष्ट रूप से सीटीई के विभिन्न उदाहरणों के लिए अलग-अलग उपनाम निर्दिष्ट नहीं करता है क्योंकि दो उपश्रेणियाँ स्वतंत्र क्षेत्रों में दिखाई देती हैं, लेकिन इसे समझना आसान बनाने के लिए, आप दोनों के बारे में सोच सकते हैं जैसे कि एक उपश्रेणी में C1 जैसे विभिन्न उपनामों का उपयोग करना और दूसरे में C2। तो यह ऐसा है जैसे एक सबक्वेरी C1.dt के साथ और दूसरा C2.dt के साथ इंटरैक्ट करता है। विभिन्न संदर्भ अंतर्निहित अभिव्यक्ति के विभिन्न मूल्यांकनों का प्रतिनिधित्व करते हैं और इसलिए विभिन्न मूल्यों का परिणाम हो सकता है। कोड चलाने का प्रयास करें और देखें कि यह किसी बिंदु पर रुक जाता है। इसे रुकने तक कितने पुनरावृत्तियों का समय लगा?
उन मामलों की कोशिश करना और उनकी पहचान करना दिलचस्प है जहां आपके पास क्वेरी निष्पादन योजना में अंतर्निहित अभिव्यक्ति के एकल बनाम एकाधिक मूल्यांकन हैं। चित्र 1 में तीन बैचों के लिए ग्राफिकल निष्पादन योजनाएं हैं (विस्तार करने के लिए क्लिक करें)।
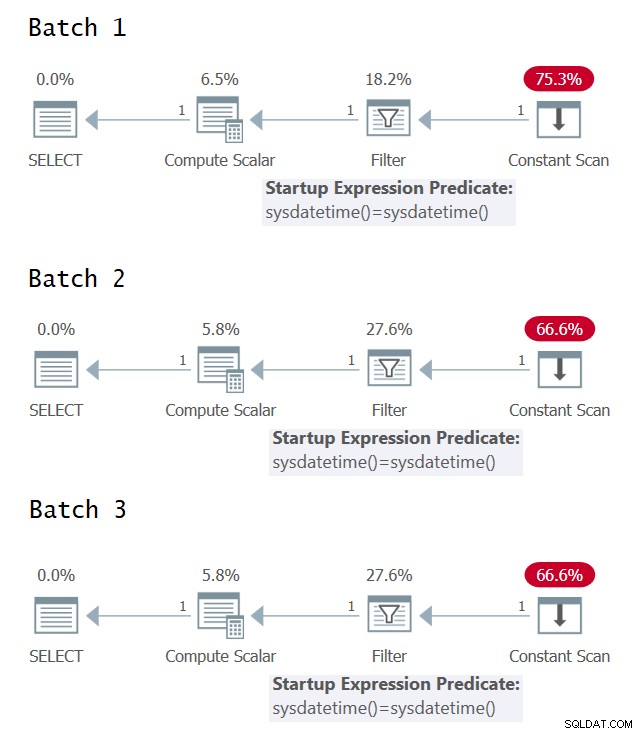 चित्र 1:बैच 1, बैच 2 और बैच 3 के लिए ग्राफिकल निष्पादन योजनाएं
चित्र 1:बैच 1, बैच 2 और बैच 3 के लिए ग्राफिकल निष्पादन योजनाएं
दुर्भाग्य से, चित्रमय निष्पादन योजनाओं से कोई खुशी नहीं; वे सभी समान प्रतीत होते हैं, भले ही, शब्दार्थ की दृष्टि से, तीन बैचों के समान अर्थ नहीं हैं। @CodeRecce और Forrest (@tsqladdict) के लिए धन्यवाद, एक समुदाय के रूप में हम अन्य माध्यमों से इसकी तह तक जाने में कामयाब रहे।
जैसा कि @CodeRecce ने खोजा, XML योजनाओं का उत्तर है। यहां तीन बैचों के लिए XML के प्रासंगिक भाग दिए गए हैं:
-− बैच 1
<भविष्यवाणी>
…
<तुलना करेंOp="EQ">
<स्केलरऑपरेटर>
<आंतरिक फ़ंक्शननाम ="sysdatetime" />
<स्केलरऑपरेटर>
<आंतरिक फ़ंक्शननाम ="sysdatetime" />
…
−− बैच 2
<भविष्यवाणी>
…
<तुलना करेंOp="EQ">
<स्केलरऑपरेटर>
<पहचानकर्ता>
<स्केलरऑपरेटर>
<आंतरिक फ़ंक्शननाम ="sysdatetime" />
<स्केलरऑपरेटर>
<पहचानकर्ता>
<स्केलरऑपरेटर>
<आंतरिक फ़ंक्शननाम ="sysdatetime" />
…
−− बैच 3
<भविष्यवाणी>
…
<तुलना करेंOp="EQ">
<स्केलरऑपरेटर>
<पहचानकर्ता>
<स्केलरऑपरेटर>
<आंतरिक फ़ंक्शननाम ="sysdatetime" />
<स्केलरऑपरेटर>
<पहचानकर्ता>
<स्केलरऑपरेटर>
<आंतरिक फ़ंक्शननाम ="sysdatetime" />
…
आप बैच 1 के लिए XML योजना में स्पष्ट रूप से देख सकते हैं कि फ़िल्टर विधेय आंतरिक SYSDATETIME फ़ंक्शन के दो अलग-अलग प्रत्यक्ष आमंत्रणों के परिणामों की तुलना करता है।
बैच 2 के लिए XML योजना में, फ़िल्टर विधेय निरंतर अभिव्यक्ति ConstExpr1002 की तुलना करता है जो SYSDATETIME फ़ंक्शन के एक आमंत्रण का प्रतिनिधित्व करता है।
बैच 3 के लिए XML योजना में, फ़िल्टर विधेय दो अलग-अलग स्थिर अभिव्यक्तियों की तुलना करता है जिन्हें ConstExpr1005 और ConstExpr1006 कहा जाता है, प्रत्येक SYSDATETIME फ़ंक्शन के एक अलग आह्वान का प्रतिनिधित्व करता है।
एक अन्य विकल्प के रूप में, फ़ॉरेस्ट (@tsqladdict) ने ट्रेस फ़्लैग 8605 का उपयोग करने का सुझाव दिया, जो ट्रेस फ़्लैग 3604 को सक्षम करने के बाद SQL सर्वर द्वारा बनाए गए प्रारंभिक क्वेरी ट्री प्रतिनिधित्व को दर्शाता है, जिसके कारण TF 8605 के आउटपुट को SSMS क्लाइंट को निर्देशित किया जाता है। दोनों ट्रेस फ़्लैग को सक्षम करने के लिए निम्न कोड का उपयोग करें:
DBCC TRACEON(3604); -- direct output to client GO DBCC TRACEON(8605); -- show initial query tree GO
इसके बाद आप वह कोड चलाते हैं जिसके लिए आप क्वेरी ट्री प्राप्त करना चाहते हैं। तीन बैचों के लिए मुझे TF 8605 से प्राप्त आउटपुट के प्रासंगिक भाग यहां दिए गए हैं:
-− बैच 1
*** परिवर्तित पेड़:***
LogOp_Project COL:Expr1000
LogOp_Select
LogOp_ConstTableGet (1) [खाली]
ScaOp_Comp x_cmpEq
ScaOp_Intrinsic sysdatetime
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Arithmetic x_aopजोड़ें
ScaOp_Identifier COL:@i
ScaOp_Const TI (int, ML =4) XVAR (int, स्वामित्व नहीं, मान =1)
-− बैच 2
*** परिवर्तित पेड़:***
LogOp_Project COL:Expr1001
LogOp_Select
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [खाली]
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Intrinsic sysdatetime
ScaOp_Comp x_cmpEq
ScaOp_Identifier COL:Expr1000
ScaOp_Identifier COL:Expr1000
AncOp_PrjList
AncOp_PrjEl COL:Expr1001
ScaOp_Arithmetic x_aopजोड़ें
ScaOp_Identifier COL:@i
ScaOp_Const TI (int, ML =4) XVAR (int, स्वामित्व नहीं, मान =1)
-− बैच 3
*** परिवर्तित पेड़:***
LogOp_Project COL:Expr1004
LogOp_Select
LogOp_ConstTableGet (1) [खाली]
ScaOp_Comp x_cmpEq
ScaOp_Subquery COL:Expr1001
LogOp_Project
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [खाली]
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1001
ScaOp_Identifier COL:Expr1000
ScaOp_Subquery COL:Expr1003
LogOp_Project
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [खाली]
AncOp_PrjList
AncOp_PrjEl COL:Expr1002
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1003
ScaOp_Identifier COL:Expr1002
AncOp_PrjList
AncOp_PrjEl COL:Expr1004
ScaOp_Arithmetic x_aopजोड़ें
ScaOp_Identifier COL:@i
ScaOp_Const TI (int, ML =4) XVAR (int, स्वामित्व नहीं, मान =1)
बैच 1 में, आप आंतरिक फ़ंक्शन SYSDATETIME के दो अलग-अलग मूल्यांकनों के परिणामों के बीच तुलना देख सकते हैं।
बैच 2 में, आप फ़ंक्शन का एक मूल्यांकन देखते हैं जिसके परिणामस्वरूप Expr1000 नामक कॉलम होता है, और फिर इस कॉलम और स्वयं के बीच तुलना होती है।
बैच 3 में, आप फ़ंक्शन के दो अलग-अलग मूल्यांकन देखते हैं। Expr1000 नामक कॉलम में से एक (बाद में Expr1001 नामक सबक्वायरी कॉलम द्वारा प्रक्षेपित)। Expr1002 नामक कॉलम में एक और (बाद में Expr1003 नामक सबक्वायरी कॉलम द्वारा प्रक्षेपित)। फिर आपके पास Expr1001 और Expr1003 के बीच तुलना है।
इसलिए, ग्राफ़िकल निष्पादन योजना जो उजागर करती है, उससे थोड़ी अधिक खुदाई के साथ, आप वास्तव में यह पता लगा सकते हैं कि एक अंतर्निहित अभिव्यक्ति का मूल्यांकन केवल एक बार बनाम कई बार किया जाता है। अब जब आप अलग-अलग मामलों को समझ गए हैं, तो आप अपने इच्छित व्यवहार के आधार पर अपने समाधान विकसित कर सकते हैं।
विंडो गैर-निर्धारिती क्रम के साथ कार्य करता है
गणनाओं का एक और वर्ग है जो एक ही सीटीई के कई संदर्भों के साथ समाधान में उपयोग किए जाने पर आपको परेशानी में डाल सकता है। वे विंडो फ़ंक्शंस हैं जो नॉनडेटर्मिनिस्टिक ऑर्डरिंग पर निर्भर करते हैं। एक उदाहरण के रूप में ROW_NUMBER विंडो फ़ंक्शन को लें। जब आंशिक ऑर्डरिंग . के साथ प्रयोग किया जाता है (ऐसे तत्वों द्वारा क्रमित करना जो पंक्ति की विशिष्ट रूप से पहचान नहीं करते हैं), अंतर्निहित क्वेरी के प्रत्येक मूल्यांकन के परिणामस्वरूप पंक्ति संख्याओं का एक अलग असाइनमेंट हो सकता है, भले ही अंतर्निहित डेटा नहीं बदला हो। कई सीटीई संदर्भों के साथ, याद रखें कि प्रत्येक अलग-अलग अननेस्टेड हो जाता है, और आप अलग-अलग परिणाम सेट प्राप्त कर सकते हैं। प्रत्येक संदर्भ के साथ बाहरी क्वेरी क्या करती है, इस पर निर्भर करता है, उदा। प्रत्येक संदर्भ के कौन से कॉलम के साथ यह इंटरैक्ट करता है और कैसे, ऑप्टिमाइज़र अलग-अलग ऑर्डरिंग आवश्यकताओं के साथ अलग-अलग इंडेक्स का उपयोग करके प्रत्येक इंस्टेंस के डेटा तक पहुंचने का निर्णय ले सकता है।
एक उदाहरण के रूप में निम्नलिखित कोड पर विचार करें:
USE TSQLV5;
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum
FROM Sales.Orders
)
SELECT C1.orderid, C1.shipcountry, C2.orderid
FROM C AS C1
INNER JOIN C AS C2
ON C1.rownum = C2.rownum
WHERE C1.orderid <> C2.orderid; क्या यह क्वेरी कभी भी एक गैर-रिक्त परिणाम सेट लौटा सकती है? शायद आपकी प्रारंभिक प्रतिक्रिया यह है कि यह नहीं हो सकता। लेकिन जो मैंने अभी थोड़ा और ध्यान से समझाया है उसके बारे में सोचें और आप महसूस करेंगे कि, कम से कम सैद्धांतिक रूप से, दो अलग-अलग सीटीई अननेस्टिंग प्रक्रियाओं के कारण जो यहां होंगे - एक सी 1 और दूसरा सी 2 - यह संभव है। हालाँकि, यह सिद्ध करना एक बात है कि कुछ हो सकता है, और दूसरा इसे प्रदर्शित करना। उदाहरण के लिए, जब मैंने कोई नई अनुक्रमणिका बनाए बिना इस कोड को चलाया, तो मुझे एक खाली परिणाम सेट मिलता रहा:
orderid shipcountry orderid ----------- --------------- ----------- (0 rows affected)
मुझे इस प्रश्न के लिए चित्र 23 में दिखाया गया प्लान मिला है।
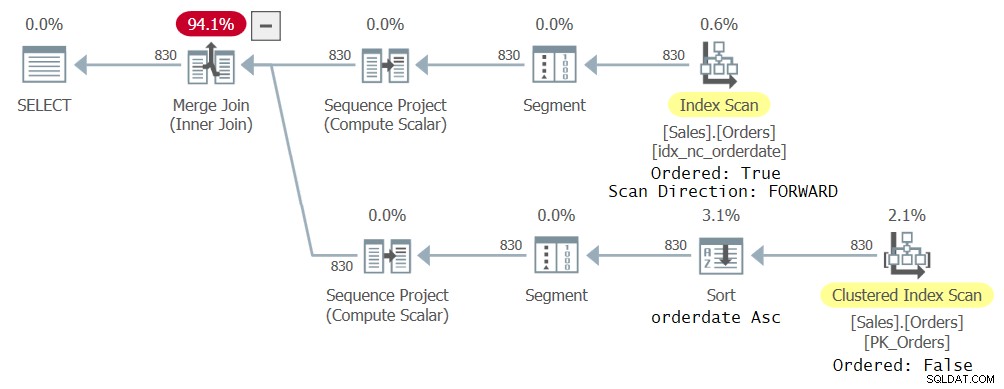 चित्र 2:दो सीटीई संदर्भों के साथ क्वेरी के लिए पहली योजना
चित्र 2:दो सीटीई संदर्भों के साथ क्वेरी के लिए पहली योजना
यहां ध्यान देने योग्य बात यह है कि ऑप्टिमाइज़र ने अलग-अलग CTE संदर्भों को संभालने के लिए अलग-अलग इंडेक्स का उपयोग करना चुना क्योंकि यह वही है जो इसे इष्टतम माना जाता है। आखिरकार, बाहरी क्वेरी में प्रत्येक संदर्भ सीटीई कॉलम के एक अलग सबसेट से संबंधित है। एक संदर्भ के परिणामस्वरूप इंडेक्स idx_nc_orderedate का एक ऑर्डर किया गया फ़ॉरवर्ड स्कैन हुआ, और दूसरा क्लस्टर्ड इंडेक्स के एक अनियंत्रित स्कैन में जिसके बाद ऑर्डरडेट आरोही द्वारा सॉर्ट ऑपरेशन किया गया। भले ही इंडेक्स idx_nc_orderedate को केवल ऑर्डरडेट कॉलम पर कुंजी के रूप में स्पष्ट रूप से परिभाषित किया गया है, व्यवहार में इसे (ऑर्डरडेट, ऑर्डरिड) पर इसकी कुंजी के रूप में परिभाषित किया गया है क्योंकि ऑर्डरिड क्लस्टर इंडेक्स कुंजी है, और सभी गैर-क्लस्टर इंडेक्स में अंतिम कुंजी के रूप में शामिल है। तो इंडेक्स का ऑर्डर किया गया स्कैन वास्तव में ऑर्डरडेट, ऑर्डरिड द्वारा ऑर्डर की गई पंक्तियों को उत्सर्जित करता है। जहां तक संकुल सूचकांक के अनियंत्रित स्कैन का संबंध है, भंडारण इंजन स्तर पर, डेटा को सूचकांक कुंजी क्रम (ऑर्डरिड के आधार पर) में स्कैन किया जाता है ताकि प्रतिबद्ध पढ़े गए डिफ़ॉल्ट अलगाव स्तर की न्यूनतम स्थिरता अपेक्षाओं को पूरा किया जा सके। इसलिए सॉर्ट ऑपरेटर ऑर्डरिड द्वारा ऑर्डर किए गए डेटा को निगला करता है, ऑर्डरडेट द्वारा पंक्तियों को सॉर्ट करता है, और व्यवहार में ऑर्डरडेट, ऑर्डरिड द्वारा ऑर्डर की गई पंक्तियों को उत्सर्जित करता है।
फिर, सिद्धांत रूप में इस बात का कोई आश्वासन नहीं है कि दो संदर्भ हमेशा एक ही परिणाम सेट का प्रतिनिधित्व करेंगे, भले ही अंतर्निहित डेटा न बदले। इसे प्रदर्शित करने का एक आसान तरीका दो संदर्भों के लिए दो अलग-अलग इष्टतम इंडेक्स की व्यवस्था करना है, लेकिन ऑर्डरडेट एएससी, ऑर्डरिड एएससी, और दूसरा ऑर्डर ऑर्डर डीईएससी, ऑर्डरिड एएससी (या बिल्कुल विपरीत) द्वारा डेटा ऑर्डर करें। हमारे पास पहले से ही पूर्व सूचकांक है। बाद वाला बनाने के लिए यहां कोड है:
CREATE INDEX idx_nc_odD_oid_I_sc ON Sales.Orders(orderdate DESC, orderid) INCLUDE(shipcountry);
अनुक्रमणिका बनाने के बाद कोड को दूसरी बार चलाएँ:
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum
FROM Sales.Orders
)
SELECT C1.orderid, C1.shipcountry, C2.orderid
FROM C AS C1
INNER JOIN C AS C2
ON C1.rownum = C2.rownum
WHERE C1.orderid <> C2.orderid; नई अनुक्रमणिका बनाने के बाद इस कोड को चलाने पर मुझे निम्न आउटपुट मिला:
orderid shipcountry orderid ----------- --------------- ----------- 10251 France 10250 10250 Brazil 10251 10261 Brazil 10260 10260 Germany 10261 10271 USA 10270 ... 11070 Germany 11073 11077 USA 11074 11076 France 11075 11075 Switzerland 11076 11074 Denmark 11077 (546 rows affected)
उफ़.
इस निष्पादन के लिए क्वेरी योजना की जाँच करें जैसा कि चित्र 3 में दिखाया गया है:
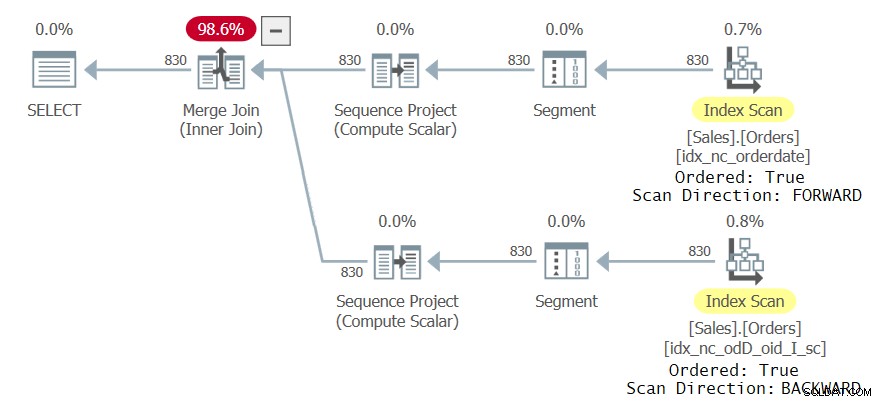 चित्र 3:दो सीटीई संदर्भों के साथ क्वेरी के लिए दूसरी योजना
चित्र 3:दो सीटीई संदर्भों के साथ क्वेरी के लिए दूसरी योजना
ध्यान दें कि योजना की शीर्ष शाखा idx_nc_orderdate को एक क्रमबद्ध फ़ॉरवर्ड फ़ैशन में स्कैन करती है, जिससे सीक्वेंस प्रोजेक्ट ऑपरेटर होता है जो ऑर्डरडेट एएससी, ऑर्डरिड एएससी द्वारा आदेशित डेटा को व्यवहार में लाने के लिए पंक्ति संख्याओं की गणना करता है। योजना की निचली शाखा नई अनुक्रमणिका idx_nc_odD_oid_I_sc को एक क्रमबद्ध बैकवर्ड फैशन में स्कैन करती है, जिससे सीक्वेंस प्रोजेक्ट ऑपरेटर ऑर्डरडेट एएससी, ऑर्डरिड डीईएससी द्वारा ऑर्डर किए गए डेटा को व्यवहार में लाता है। इसका परिणाम दो सीटीई संदर्भों के लिए पंक्ति संख्याओं की एक अलग व्यवस्था में होता है जब भी एक ही ऑर्डरडेट मान की एक से अधिक घटनाएं होती हैं। नतीजतन, क्वेरी एक गैर-रिक्त परिणाम सेट उत्पन्न करती है।
यदि आप ऐसी बग से बचना चाहते हैं, तो एक स्पष्ट विकल्प अस्थायी तालिका या तालिका चर जैसे अस्थायी ऑब्जेक्ट में आंतरिक क्वेरी परिणाम को जारी रखना है। हालांकि, अगर आपके पास ऐसी स्थिति है जहां आप सीटीई का उपयोग करना पसंद करते हैं, तो एक आसान समाधान एक टाईब्रेकर जोड़कर विंडो फ़ंक्शन में कुल ऑर्डर का उपयोग करना है। दूसरे शब्दों में, सुनिश्चित करें कि आप उन भावों के संयोजन से ऑर्डर करते हैं जो विशिष्ट रूप से एक पंक्ति की पहचान करते हैं। हमारे मामले में, आप ऑर्डरिड को स्पष्ट रूप से टाईब्रेकर के रूप में जोड़ सकते हैं, जैसे:
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate, orderid) AS rownum
FROM Sales.Orders
)
SELECT C1.orderid, C1.shipcountry, C2.orderid
FROM C AS C1
INNER JOIN C AS C2
ON C1.rownum = C2.rownum
WHERE C1.orderid <> C2.orderid; आपको उम्मीद के मुताबिक एक खाली परिणाम सेट मिलता है:
orderid shipcountry orderid ----------- --------------- ----------- (0 rows affected)
कोई और इंडेक्स जोड़े बिना, आपको चित्र 4 में दिखाया गया प्लान मिलता है:
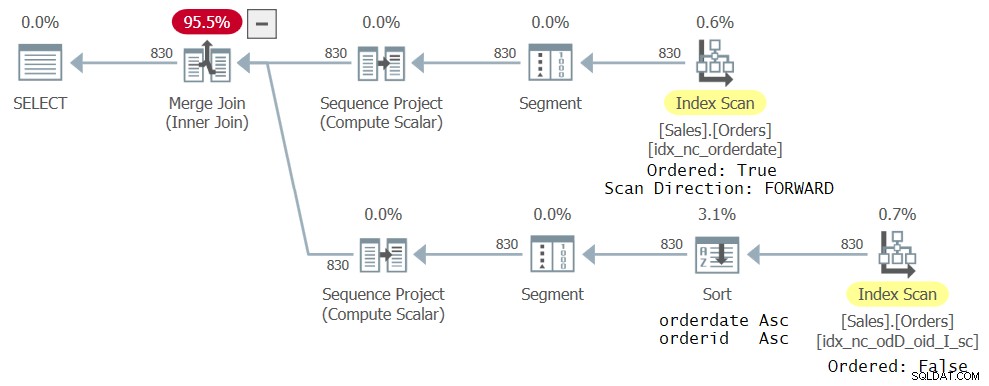 चित्र 4:दो सीटीई संदर्भों के साथ पूछताछ के लिए तीसरी योजना
चित्र 4:दो सीटीई संदर्भों के साथ पूछताछ के लिए तीसरी योजना
योजना की शीर्ष शाखा चित्र 3 में दर्शाई गई पिछली योजना के समान है। हालांकि निचली शाखा थोड़ी भिन्न है। पहले बनाई गई नई अनुक्रमणिका नई क्वेरी के लिए वास्तव में आदर्श नहीं है क्योंकि इसमें ROW_NUMBER फ़ंक्शन आवश्यकताओं (ऑर्डरडेट, ऑर्डरिड) की तरह डेटा ऑर्डर नहीं किया गया है। यह अभी भी सबसे छोटा कवरिंग इंडेक्स है जिसे ऑप्टिमाइज़र अपने संबंधित सीटीई संदर्भ के लिए ढूंढ सकता है, इसलिए इसे चुना गया है; हालांकि, यह एक आदेशित:गलत फैशन में स्कैन किया गया है। एक स्पष्ट सॉर्ट ऑपरेटर तब डेटा को ऑर्डरडेट, ऑर्डरिड जैसे ROW_NUMBER गणना आवश्यकताओं के अनुसार सॉर्ट करता है। बेशक, आप इंडेक्स परिभाषा को बदल सकते हैं ताकि ऑर्डरडेट और ऑर्डरिड दोनों एक ही दिशा का उपयोग कर सकें और इस तरह योजना से स्पष्ट सॉर्टिंग समाप्त हो जाएगी। हालांकि मुख्य बात यह है कि कुल ऑर्डरिंग का उपयोग करके, आप इस विशिष्ट बग के कारण परेशानी में पड़ने से बचते हैं।
जब आप कर लें, तो सफाई के लिए निम्न कोड चलाएँ:
DROP INDEX IF EXISTS idx_nc_odD_oid_I_sc ON Sales.Orders;
निष्कर्ष
यह समझना महत्वपूर्ण है कि बाहरी क्वेरी से एक ही सीटीई के कई संदर्भों के परिणामस्वरूप सीटीई की आंतरिक क्वेरी का अलग-अलग मूल्यांकन होता है। गैर-नियतात्मक गणनाओं के साथ विशेष रूप से सावधान रहें, क्योंकि अलग-अलग मूल्यांकनों के परिणामस्वरूप अलग-अलग मान हो सकते हैं।
विंडो फ़ंक्शंस जैसे ROW_NUMBER और एक फ्रेम के साथ एग्रीगेट का उपयोग करते समय, अलग-अलग CTE संदर्भों में एक ही पंक्ति के लिए अलग-अलग परिणाम प्राप्त करने से बचने के लिए कुल ऑर्डर का उपयोग करना सुनिश्चित करें।