किसी भी प्रोग्रामिंग भाषा की तरह, टी-एसक्यूएल में आम बग और नुकसान हैं, जिनमें से कुछ गलत परिणाम देते हैं और अन्य प्रदर्शन समस्याओं का कारण बनते हैं। उनमें से कई मामलों में, सर्वोत्तम प्रथाएं हैं जो आपको परेशानी में पड़ने से बचने में मदद कर सकती हैं। मैंने साथी Microsoft डेटा प्लेटफ़ॉर्म MVP का सर्वेक्षण करके उन बगों और कमियों के बारे में पूछा जो वे अक्सर देखते हैं या जिन्हें वे विशेष रूप से दिलचस्प पाते हैं, और उनसे बचने के लिए वे सर्वोत्तम प्रथाओं का उपयोग करते हैं। मेरे पास बहुत सारे दिलचस्प मामले हैं।
अपने ज्ञान और अनुभव को साझा करने के लिए एरलैंड सोमरस्कोग, आरोन बर्ट्रेंड, एलेजांद्रो मेसा, उमाचंदर जयचंद्रन (यूसी), फैबियानो नेव्स अमोरिम, मिलोस रेडिवोजेविक, साइमन सबिन, एडम मचानिक, थॉमस ग्रोसर और चैन मिंग मैन को बहुत-बहुत धन्यवाद!
यह लेख इस विषय पर श्रृंखला में पहला है। प्रत्येक लेख एक निश्चित विषय पर केंद्रित है। इस महीने मैं नियतिवाद से संबंधित बग, नुकसान और सर्वोत्तम प्रथाओं पर ध्यान केंद्रित करता हूं। एक नियतात्मक गणना वह है जो समान इनपुट दिए गए दोहराने योग्य परिणाम उत्पन्न करने की गारंटी देता है। कई बग और नुकसान हैं जो गैर-निर्धारक गणनाओं के उपयोग के परिणामस्वरूप होते हैं। इस लेख में मैं नॉनडेटर्मिनिस्टिक ऑर्डर, नॉनडेटर्मिनिस्टिक फ़ंक्शंस, नॉनडेटर्मिनिस्टिक कैलकुलेशन के साथ टेबल एक्सप्रेशन के कई संदर्भों और नॉनडेर्मिनिस्टिक कैलकुलेशन के साथ CASE एक्सप्रेशन और NULLIF फ़ंक्शन के उपयोग के निहितार्थ को कवर करता हूँ।
मैं इस श्रृंखला के कई उदाहरणों में नमूना डेटाबेस TSQLV5 का उपयोग करता हूं।
निर्धारणात्मक क्रम
टी-एसक्यूएल में बग के लिए एक सामान्य स्रोत नोडेटर्मिनिस्टिक ऑर्डर का उपयोग है। यानी, जब सूची के आधार पर आपका आदेश विशिष्ट रूप से किसी पंक्ति की पहचान नहीं करता है। यह प्रेजेंटेशन ऑर्डरिंग, टॉप/ऑफसेट-फ़ेच ऑर्डरिंग या विंडो ऑर्डरिंग हो सकता है।
उदाहरण के लिए OFFSET-FETCH फ़िल्टर का उपयोग करके एक क्लासिक पेजिंग परिदृश्य लें। आपको Sales.Orders तालिका को क्वेरी करने की आवश्यकता है जो एक समय में 10 पंक्तियों के एक पृष्ठ को लौटाती है, क्रम दिनांक, अवरोही (सबसे हाल ही में पहले) द्वारा क्रमबद्ध है। मैं ऑफसेट के लिए स्थिरांक का उपयोग करूंगा और सरलता के लिए तत्वों को प्राप्त करूंगा, लेकिन आम तौर पर वे ऐसे भाव होते हैं जो इनपुट मापदंडों पर आधारित होते हैं।
निम्न क्वेरी (इसे क्वेरी 1 कहते हैं) सबसे हाल के 10 आदेशों का पहला पृष्ठ लौटाती है:
USE TSQLV5; SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY;
प्रश्न 1 की योजना चित्र 1 में दिखाई गई है।
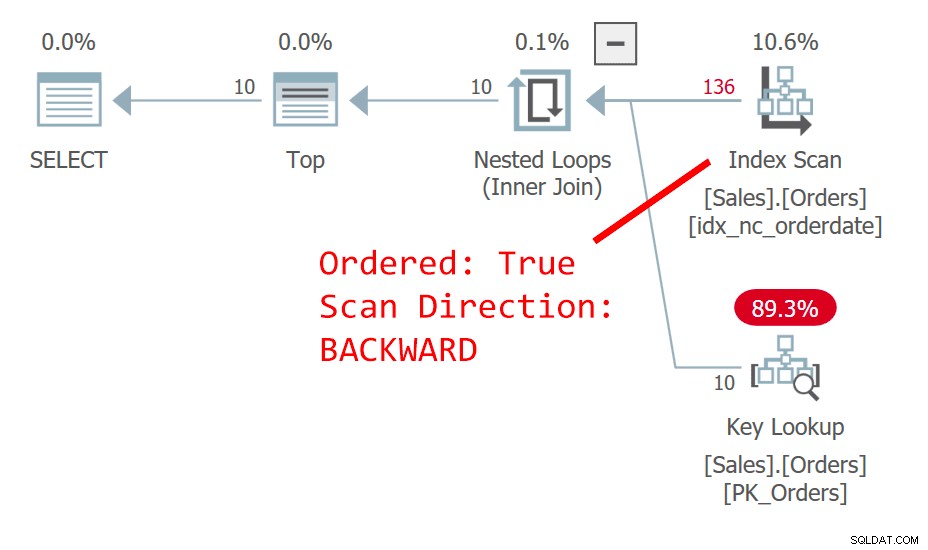 चित्र 1:क्वेरी 1 के लिए योजना
चित्र 1:क्वेरी 1 के लिए योजना
क्वेरी ऑर्डरडेट, अवरोही द्वारा पंक्तियों को ऑर्डर करती है। ऑर्डरडेट कॉलम विशिष्ट रूप से एक पंक्ति की पहचान नहीं करता है। इस nondeterministic क्रम का अर्थ है कि वैचारिक रूप से, समान तिथि वाली पंक्तियों के बीच कोई वरीयता नहीं है। संबंधों के मामले में, यह निर्धारित करता है कि SQL सर्वर कौन सी पंक्ति पसंद करेगा, योजना विकल्प और भौतिक डेटा लेआउट जैसी चीजें हैं-ऐसा कुछ नहीं जिसे आप दोहराने योग्य होने पर भरोसा कर सकते हैं। चित्र 1 में योजना इंडेक्स को ऑर्डर की गई तारीख को पीछे की ओर स्कैन करती है। ऐसा होता है कि इस तालिका में ऑर्डरिड पर क्लस्टर इंडेक्स होता है, और क्लस्टर्ड टेबल में क्लस्टर्ड इंडेक्स कुंजी को गैर-क्लस्टर इंडेक्स में पंक्ति लोकेटर के रूप में उपयोग किया जाता है। यह वास्तव में सभी गैर-अनुक्रमित अनुक्रमितों में अंतिम कुंजी तत्व के रूप में निहित रूप से स्थित हो जाता है, भले ही सैद्धांतिक रूप से SQL सर्वर इसे इंडेक्स में शामिल कॉलम के रूप में रख सकता था। तो, स्पष्ट रूप से, ऑर्डरडेट पर गैर-संकुल सूचकांक वास्तव में (ऑर्डरडेट, ऑर्डरिड) पर परिभाषित किया गया है। नतीजतन, इंडेक्स के हमारे ऑर्डर किए गए बैकवर्ड स्कैन में, ऑर्डरडेट के आधार पर बंधी हुई पंक्तियों के बीच, उच्च ऑर्डरिड मान वाली एक पंक्ति को कम ऑर्डरिड मान वाली पंक्ति से पहले एक्सेस किया जाता है। यह क्वेरी निम्न आउटपुट उत्पन्न करती है:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 *** 11068 2019-05-04 62
इसके बाद, 10 पंक्तियों का दूसरा पृष्ठ प्राप्त करने के लिए निम्न क्वेरी (इसे क्वेरी 2 कहते हैं) का उपयोग करें:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY;
क्वेरी की योजना चित्र 2 में दिखाई गई है।
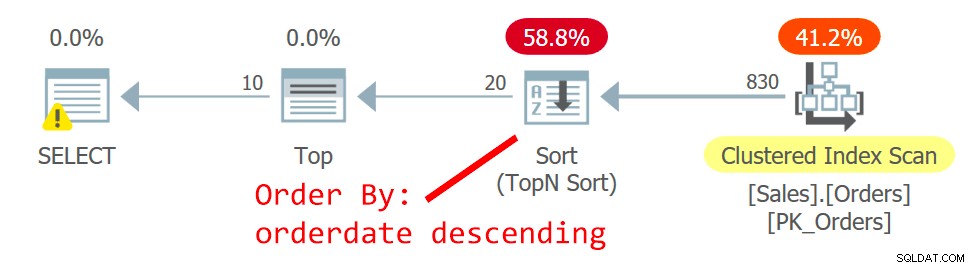
चित्र 2:क्वेरी 2 के लिए योजना
ऑप्टिमाइज़र एक अलग योजना चुनता है - एक अनियंत्रित तरीके से क्लस्टर किए गए इंडेक्स को स्कैन करता है, और ऑफसेट-फ़ेच फ़िल्टर को संभालने के लिए शीर्ष ऑपरेटर के अनुरोध का समर्थन करने के लिए टॉपएन सॉर्ट का उपयोग करता है। परिवर्तन का कारण यह है कि चित्र 1 में योजना एक गैर-संकुलित गैर-आवरण सूचकांक का उपयोग करती है, और आप जिस पृष्ठ से आगे हैं, उतने अधिक लुकअप की आवश्यकता है। दूसरे पेज के अनुरोध के साथ, आपने उस महत्वपूर्ण बिंदु को पार कर लिया है जो गैर-कवरिंग इंडेक्स का उपयोग करने को सही ठहराता है।
भले ही क्लस्टर्ड इंडेक्स का स्कैन, जिसे ऑर्डरिड के साथ कुंजी के रूप में परिभाषित किया गया है, एक अनियंत्रित है, स्टोरेज इंजन आंतरिक रूप से एक इंडेक्स ऑर्डर स्कैन को नियोजित करता है। यह सूचकांक के आकार के साथ करना है। 64 पृष्ठों तक स्टोरेज इंजन आमतौर पर आवंटन ऑर्डर स्कैन के लिए इंडेक्स ऑर्डर स्कैन को प्राथमिकता देता है। यहां तक कि अगर सूचकांक बड़ा था, तो पढ़ने के लिए प्रतिबद्ध अलगाव स्तर और डेटा जो केवल पढ़ने के रूप में चिह्नित नहीं है, के दौरान होने वाले पृष्ठ विभाजन के परिणामस्वरूप पंक्तियों को डबल-रीडिंग और स्किप करने से बचने के लिए स्टोरेज इंजन इंडेक्स ऑर्डर स्कैन का उपयोग करता है। स्कैन। दी गई शर्तों के तहत, व्यवहार में, एक ही तिथि वाली पंक्तियों के बीच, यह योजना एक उच्च ऑर्डरिड वाली एक से पहले एक निचले क्रम के साथ एक पंक्ति तक पहुँचती है।
यह क्वेरी निम्न आउटपुट उत्पन्न करती है:
orderid orderdate custid ----------- ---------- ----------- 11069 2019-05-04 80 *** 11064 2019-05-01 71 11065 2019-05-01 46 11066 2019-05-01 89 11060 2019-04-30 27 11061 2019-04-30 32 11062 2019-04-30 66 11063 2019-04-30 37 11057 2019-04-29 53 11058 2019-04-29 6
ध्यान दें कि भले ही अंतर्निहित डेटा नहीं बदला हो, आप पहले और दूसरे दोनों पेजों में उसी ऑर्डर (ऑर्डर आईडी 11069 के साथ) के साथ समाप्त हुए!
उम्मीद है, यहां सबसे अच्छा अभ्यास स्पष्ट है। नियतात्मक आदेश प्राप्त करने के लिए सूची के अनुसार अपने आदेश में एक टाईब्रेकर जोड़ें। उदाहरण के लिए, क्रम से क्रम दिनांक अवरोही, क्रमानुसार अवरोही।
पहले पृष्ठ के लिए फिर से प्रयास करें, इस बार एक नियतात्मक क्रम के साथ:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY;
आपको निम्न आउटपुट मिलता है, गारंटीकृत:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 11068 2019-05-04 62
दूसरे पेज के लिए पूछें:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY;
आपको निम्न आउटपुट मिलता है, गारंटीकृत:
orderid orderdate custid ----------- ---------- ----------- 11067 2019-05-04 17 11066 2019-05-01 89 11065 2019-05-01 46 11064 2019-05-01 71 11063 2019-04-30 37 11062 2019-04-30 66 11061 2019-04-30 32 11060 2019-04-30 27 11059 2019-04-29 67 11058 2019-04-29 6
जब तक अंतर्निहित डेटा में कोई परिवर्तन नहीं होता है, तब तक आपको लगातार पृष्ठ प्राप्त होने की गारंटी है जिसमें कोई दोहराव या पृष्ठों के बीच पंक्तियों को छोड़ना नहीं है।
इसी तरह, गैर-निर्धारिती क्रम के साथ ROW_NUMBER जैसे विंडो फ़ंक्शंस का उपयोग करके, आप योजना के आकार और संबंधों के बीच वास्तविक एक्सेस ऑर्डर के आधार पर एक ही क्वेरी के लिए अलग-अलग परिणाम प्राप्त कर सकते हैं। निम्नलिखित क्वेरी पर विचार करें (इसे क्वेरी 3 कहें), पंक्ति संख्याओं का उपयोग करके प्रथम पृष्ठ अनुरोध को लागू करना (चित्रण उद्देश्यों के लिए ऑर्डरडेट पर इंडेक्स के उपयोग को मजबूर करना):
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders WITH (INDEX(idx_nc_orderdate))
)
SELECT orderid, orderdate, custid
FROM C
WHERE n BETWEEN 1 AND 10; इस क्वेरी की योजना चित्र 3 में दिखाई गई है:
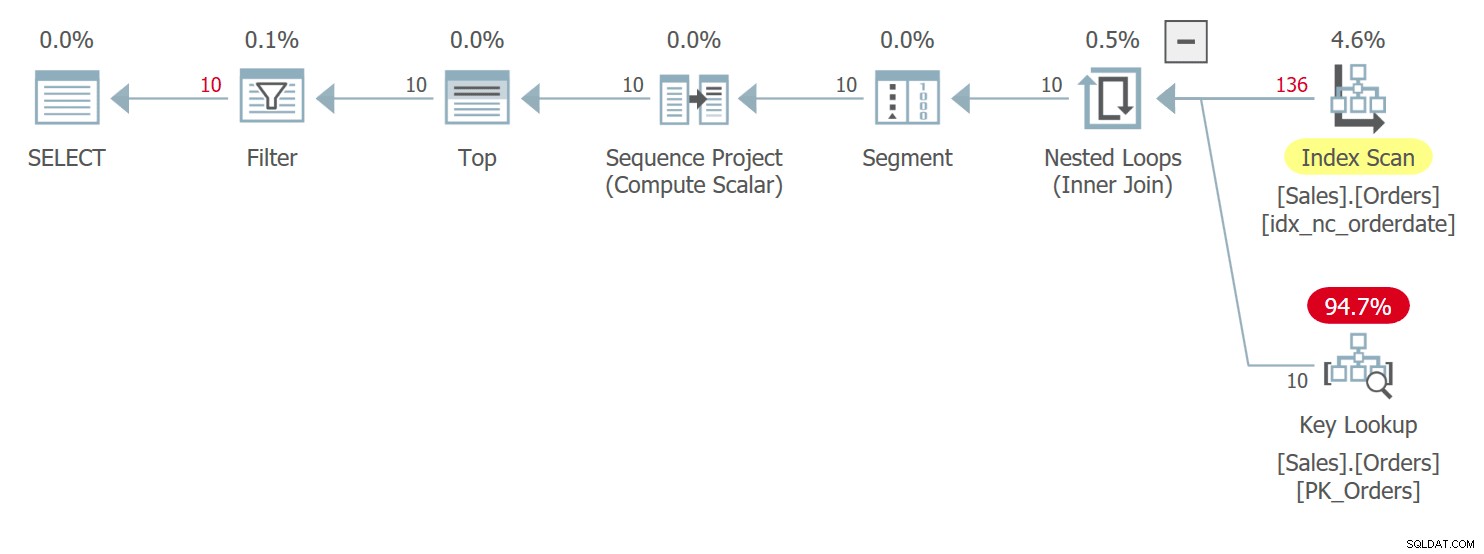
चित्र 3:क्वेरी 3 के लिए योजना
आपके पास यहां बहुत समान स्थितियां हैं जिन्हें मैंने पहले क्वेरी 1 के लिए वर्णित किया था, जो कि पहले चित्र 1 में दिखाया गया था। ऑर्डरडेट मानों में संबंधों के साथ पंक्तियों के बीच, यह योजना निम्न के साथ एक से पहले उच्च ऑर्डरिड मान वाली पंक्ति तक पहुंचती है ऑर्डरिड मूल्य। यह क्वेरी निम्न आउटपुट उत्पन्न करती है:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 *** 11068 2019-05-04 62
इसके बाद, क्वेरी को फिर से चलाएं (इसे क्वेरी 4 कहते हैं), पहले पृष्ठ का अनुरोध करते हुए, केवल इस बार क्लस्टर इंडेक्स PK_Orders के उपयोग के लिए बाध्य करें:
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders WITH (INDEX(PK_Orders))
)
SELECT orderid, orderdate, custid
FROM C
WHERE n BETWEEN 1 AND 10; इस क्वेरी की योजना चित्र 4 में दिखाई गई है।

चित्र 4:क्वेरी 4 के लिए योजना
इस बार आपके पास क्वेरी 2 के लिए पहले वर्णित की गई स्थितियों के समान ही है, जो कि पहले चित्र 2 में दिखाया गया था। ऑर्डरडेट मानों में संबंधों के साथ पंक्तियों के बीच, यह योजना एक के साथ एक से पहले कम ऑर्डरिड मान वाली पंक्ति तक पहुंचती है। उच्च आदेश मूल्य। यह क्वेरी निम्न आउटपुट उत्पन्न करती है:
orderid orderdate custid ----------- ---------- ----------- 11074 2019-05-06 73 11075 2019-05-06 68 11076 2019-05-06 9 11077 2019-05-06 65 11070 2019-05-05 44 11071 2019-05-05 46 11072 2019-05-05 20 11073 2019-05-05 58 11067 2019-05-04 17 *** 11068 2019-05-04 62
ध्यान दें कि दो निष्पादनों ने अलग-अलग परिणाम दिए, भले ही अंतर्निहित डेटा में कुछ भी नहीं बदला।
फिर से, यहां सबसे अच्छा अभ्यास सरल है—एक टाईब्रेकर जोड़कर नियतात्मक क्रम का उपयोग करें, जैसे:
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n
FROM Sales.Orders
)
SELECT orderid, orderdate, custid
FROM C
WHERE n BETWEEN 1 AND 10; यह क्वेरी निम्न आउटपुट उत्पन्न करती है:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 11068 2019-05-04 62
लौटाए गए सेट को योजना के आकार के बावजूद दोहराने योग्य होने की गारंटी है।
यह शायद उल्लेखनीय है कि चूंकि इस क्वेरी में बाहरी क्वेरी में क्लॉज द्वारा प्रेजेंटेशन ऑर्डर नहीं है, इसलिए यहां कोई गारंटीकृत प्रेजेंटेशन ऑर्डर नहीं है। यदि आपको ऐसी गारंटी की आवश्यकता है, तो आपको खंड दर प्रस्तुति क्रम जोड़ना होगा, जैसे:
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n
FROM Sales.Orders
)
SELECT orderid, orderdate, custid
FROM C
WHERE n BETWEEN 1 AND 10
ORDER BY n; गैर नियतात्मक कार्य
एक nondeterministic फ़ंक्शन एक ऐसा फ़ंक्शन है जो समान इनपुट देता है, फ़ंक्शन के विभिन्न निष्पादन में अलग-अलग परिणाम लौटा सकता है। क्लासिक उदाहरण हैं SYSDATETIME, NEWID, और RAND (जब इनपुट बीज के बिना लागू किया जाता है)। टी-एसक्यूएल में गैर-निर्धारिती कार्यों का व्यवहार कुछ के लिए आश्चर्यजनक हो सकता है, और कुछ मामलों में बग और नुकसान हो सकता है।
बहुत से लोग मानते हैं कि जब आप किसी क्वेरी के हिस्से के रूप में एक नोडेटर्मिनिस्टिक फ़ंक्शन का आह्वान करते हैं, तो फ़ंक्शन का मूल्यांकन प्रति पंक्ति अलग से किया जाता है। व्यवहार में, क्वेरी में प्रति संदर्भ एक बार अधिकांश गैर-निर्धारणात्मक कार्यों का मूल्यांकन किया जाता है। एक उदाहरण के रूप में निम्नलिखित प्रश्न पर विचार करें:
SELECT orderid, SYSDATETIME() AS dt, RAND() AS rnd FROM Sales.Orders;
चूंकि क्वेरी में प्रत्येक नोडेटर्मिनिस्टिक फ़ंक्शन SYSDATETIME और RAND के लिए केवल एक संदर्भ है, इनमें से प्रत्येक फ़ंक्शन का मूल्यांकन केवल एक बार किया जाता है, और इसका परिणाम सभी परिणाम पंक्तियों में दोहराया जाता है। इस क्वेरी को चलाते समय मुझे निम्न आउटपुट मिला:
orderid dt rnd ----------- --------------------------- ---------------------- 11008 2019-02-04 17:03:07.9229177 0.962042872007464 11019 2019-02-04 17:03:07.9229177 0.962042872007464 11039 2019-02-04 17:03:07.9229177 0.962042872007464 11040 2019-02-04 17:03:07.9229177 0.962042872007464 11045 2019-02-04 17:03:07.9229177 0.962042872007464 11051 2019-02-04 17:03:07.9229177 0.962042872007464 11054 2019-02-04 17:03:07.9229177 0.962042872007464 11058 2019-02-04 17:03:07.9229177 0.962042872007464 11059 2019-02-04 17:03:07.9229177 0.962042872007464 11061 2019-02-04 17:03:07.9229177 0.962042872007464 ...
एक उदाहरण के रूप में जहां इस व्यवहार को नहीं समझने के परिणामस्वरूप बग हो सकता है, मान लीजिए कि आपको एक क्वेरी लिखनी है जो Sales.Orders तालिका से तीन यादृच्छिक ऑर्डर लौटाती है। एक सामान्य प्रारंभिक प्रयास रैंड फ़ंक्शन के आधार पर ऑर्डरिंग के साथ एक TOP क्वेरी का उपयोग करना है, यह सोचकर कि फ़ंक्शन का मूल्यांकन प्रति पंक्ति अलग से किया जाएगा, जैसे:
SELECT TOP (3) orderid FROM Sales.Orders ORDER BY RAND();
व्यवहार में, फ़ंक्शन का मूल्यांकन संपूर्ण क्वेरी के लिए केवल एक बार किया जाता है; इसलिए, सभी पंक्तियों को एक ही परिणाम मिलता है, और क्रम पूरी तरह से अप्रभावित रहता है। वास्तव में, यदि आप इस क्वेरी के लिए योजना की जांच करते हैं, तो आपको कोई सॉर्ट ऑपरेटर नहीं दिखाई देगा। जब मैंने इस क्वेरी को कई बार चलाया, तो मुझे वही परिणाम मिलते रहे:
orderid ----------- 11008 11019 11039
क्वेरी वास्तव में ORDER BY क्लॉज के बिना एक के बराबर है, जहां प्रेजेंटेशन ऑर्डरिंग की गारंटी नहीं है। तो तकनीकी रूप से ऑर्डरिंग नॉनडेटर्मिनिस्टिक है, और सैद्धांतिक रूप से अलग-अलग निष्पादन के परिणामस्वरूप अलग-अलग क्रम हो सकते हैं, और इसलिए शीर्ष 3 पंक्तियों के एक अलग चयन में। हालाँकि, इसकी संभावना कम है, और आप इस समाधान को प्रत्येक निष्पादन में तीन यादृच्छिक पंक्तियों के निर्माण के रूप में नहीं सोच सकते।
इस नियम का अपवाद है कि क्वेरी में प्रति संदर्भ एक बार एक गैर-नियतात्मक फ़ंक्शन को लागू किया जाता है, वह है NEWID फ़ंक्शन, जो एक विश्व स्तर पर विशिष्ट पहचानकर्ता (GUID) देता है। जब किसी क्वेरी में उपयोग किया जाता है, तो यह फ़ंक्शन है प्रति पंक्ति अलग से आह्वान किया। निम्न क्वेरी इसे प्रदर्शित करती है:
SELECT orderid, NEWID() AS mynewid FROM Sales.Orders;
इस क्वेरी ने निम्न आउटपुट उत्पन्न किया:
orderid mynewid ----------- ------------------------------------ 11008 D6417542-C78A-4A2D-9517-7BB0FCF3B932 11019 E2E46BF1-4FA6-4EF2-8328-18B86259AD5D 11039 2917D923-AC60-44F5-92D7-FF84E52250CC 11040 B6287B49-DAE7-4C6C-98A8-7DB8A879581C 11045 2E14D8F7-21E5-4039-BF7E-0A27D1A0E186 11051 FA0B7B3E-BA41-4D80-8581-782EB88836C0 11054 1E6146BB-FEE7-4FF4-A4A2-3243AA2CBF78 11058 49302EA9-0243-4502-B9D2-46D751E6EFA9 11059 F5BB7CB2-3B17-4D01-ABD2-04F3C5115FCF 11061 09E406CA-0251-423B-8DF5-564E1257F93E ...
NEWID का मान अपने आप में काफी यादृच्छिक है। यदि आप इसके ऊपर CHECKSUM फ़ंक्शन लागू करते हैं, तो आपको एक बेहतर यादृच्छिक वितरण के साथ एक पूर्णांक परिणाम मिलता है। तो तीन यादृच्छिक ऑर्डर प्राप्त करने का एक तरीका है CHECKSUM(NEWID()) के आधार पर ऑर्डरिंग के साथ एक TOP क्वेरी का उपयोग करना, जैसे:
SELECT TOP (3) orderid FROM Sales.Orders ORDER BY CHECKSUM(NEWID());
इस क्वेरी को बार-बार चलाएं और ध्यान दें कि आपको हर बार तीन रैंडम ऑर्डर का एक अलग सेट मिलता है। मुझे एक निष्पादन में निम्न आउटपुट मिला:
orderid ----------- 11031 10330 10962
और दूसरे निष्पादन में निम्न आउटपुट:
orderid ----------- 10308 10885 10444
NEWID के अलावा, क्या होगा यदि आपको किसी क्वेरी में SYSDATETIME जैसे नोडेटर्मिनिस्टिक फ़ंक्शन का उपयोग करने की आवश्यकता है, और आपको प्रति पंक्ति अलग से मूल्यांकन करने की आवश्यकता है? इसे प्राप्त करने का एक तरीका एक उपयोगकर्ता परिभाषित फ़ंक्शन (यूडीएफ) का उपयोग करना है जो नोडेटर्मिनिस्टिक फ़ंक्शन को आमंत्रित करता है, जैसे:
CREATE OR ALTER FUNCTION dbo.MySysDateTime() RETURNS DATETIME2
AS
BEGIN
RETURN SYSDATETIME();
END;
GO फिर आप इस तरह की क्वेरी में यूडीएफ का आह्वान करते हैं (इसे क्वेरी 5 कहते हैं):
SELECT orderid, dbo.MySysDateTime() AS mydt FROM Sales.Orders;
यूडीएफ इस बार प्रति पंक्ति निष्पादित हो जाता है। हालाँकि, आपको जागरूक होने की आवश्यकता है, कि UDF के प्रति पंक्ति निष्पादन के साथ बहुत तेज प्रदर्शन दंड जुड़ा हुआ है। इसके अलावा, स्केलर टी-एसक्यूएल यूडीएफ को लागू करना एक समानांतरवाद अवरोधक है।
इस क्वेरी की योजना चित्र 5 में दिखाई गई है।
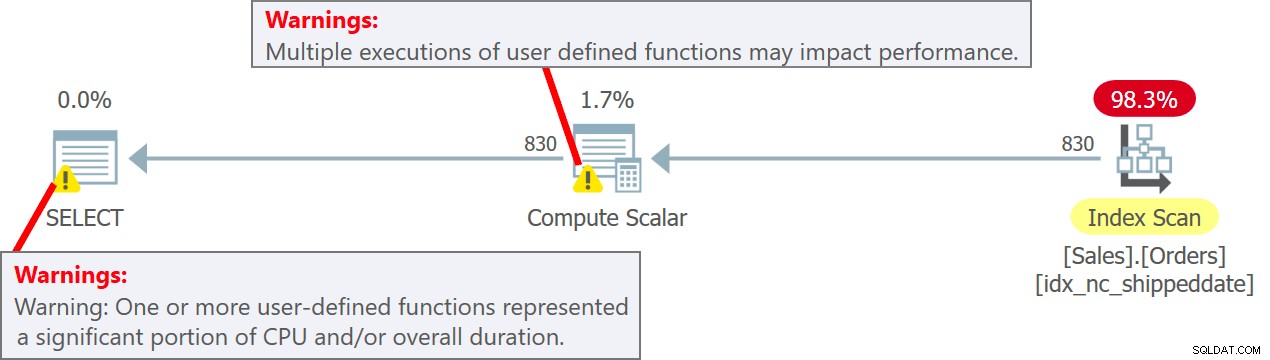
चित्र 5:क्वेरी 5 के लिए योजना
योजना में ध्यान दें कि वास्तव में यूडीएफ को कंप्यूट स्केलर ऑपरेटर में प्रति स्रोत पंक्ति में बुलाया जाता है। यह भी ध्यान दें कि SentryOne Plan Explorer आपको कंप्यूट स्केलर ऑपरेटर और योजना के रूट नोड दोनों में UDF के उपयोग से जुड़े संभावित प्रदर्शन दंड के बारे में चेतावनी देता है।
मुझे इस क्वेरी के निष्पादन से निम्न आउटपुट मिला:
orderid mydt ----------- --------------------------- 11008 2019-02-04 17:07:03.7221339 11019 2019-02-04 17:07:03.7221339 11039 2019-02-04 17:07:03.7221339 ... 10251 2019-02-04 17:07:03.7231315 10255 2019-02-04 17:07:03.7231315 10248 2019-02-04 17:07:03.7231315 ... 10416 2019-02-04 17:07:03.7241304 10420 2019-02-04 17:07:03.7241304 10421 2019-02-04 17:07:03.7241304 ...
ध्यान दें कि mydt कॉलम में आउटपुट पंक्तियों के कई अलग-अलग दिनांक और समय मान हैं।
आपने सुना होगा कि SQL सर्वर 2019 स्केलर T-SQL UDFs के कारण होने वाली सामान्य प्रदर्शन समस्या को ऐसे कार्यों को इनलाइन करके संबोधित करता है। हालांकि, यूडीएफ को इनलाइन करने योग्य होने के लिए आवश्यकताओं की एक सूची को पूरा करना होगा। आवश्यकताओं में से एक यह है कि यूडीएफ किसी भी गैर-निर्धारिती आंतरिक कार्य जैसे कि SYSDATETIME को लागू नहीं करता है। इस आवश्यकता का तर्क यह है कि शायद आपने प्रति पंक्ति निष्पादन प्राप्त करने के लिए बिल्कुल यूडीएफ बनाया है। यदि यूडीएफ इनलाइन हो गया है, तो अंतर्निहित नोडेटर्मिनिस्टिक फ़ंक्शन पूरी क्वेरी के लिए केवल एक बार निष्पादित किया जाएगा। वास्तव में, चित्र 5 में योजना SQL सर्वर 2019 में बनाई गई थी, और आप स्पष्ट रूप से देख सकते हैं कि UDF इनलाइन नहीं हुआ है। यह गैर-नियतात्मक फ़ंक्शन SYSDATETIME के उपयोग के कारण है। आप sys.sql_modules दृश्य में is_inlineable विशेषता को क्वेरी करके SQL सर्वर 2019 में UDF इनलाइन करने योग्य है या नहीं, इसकी जांच कर सकते हैं, जैसे:
SELECT is_inlineable FROM sys.sql_modules WHERE object_id = OBJECT_ID(N'dbo.MySysDateTime');
यह कोड निम्न आउटपुट उत्पन्न करता है जो आपको बताता है कि UDF MySysDateTime इनलाइन करने योग्य नहीं है:
is_inlineable ------------- 0
एक यूडीएफ प्रदर्शित करने के लिए जो इनलाइन करने योग्य नहीं है, यहां एक यूडीएफ की परिभाषा दी गई है जिसे एंडऑफियर कहा जाता है जो एक इनपुट तिथि को स्वीकार करता है और संबंधित वर्ष की समाप्ति तिथि देता है:
CREATE OR ALTER FUNCTION dbo.EndOfYear(@dt AS DATE) RETURNS DATE
AS
BEGIN
RETURN DATEADD(year, DATEDIFF(year, '18991231', @dt), '18991231');
END;
GO यहां गैर-निर्धारिती कार्यों का कोई उपयोग नहीं है, और कोड इनलाइनिंग के लिए अन्य आवश्यकताओं को भी पूरा करता है। आप निम्न कोड का उपयोग करके सत्यापित कर सकते हैं कि UDF इनलाइन करने योग्य है:
SELECT is_inlineable FROM sys.sql_modules WHERE object_id = OBJECT_ID(N'dbo.EndOfYear');
यह कोड निम्न आउटपुट उत्पन्न करता है:
is_inlineable ------------- 1
निम्न क्वेरी (इसे क्वेरी 6 कहते हैं) UDF EndOfYear का उपयोग उन आदेशों को फ़िल्टर करने के लिए करती है जो वर्ष के अंत की तिथि पर रखे गए थे:
SELECT orderid FROM Sales.Orders WHERE orderdate = dbo.EndOfYear(orderdate);
इस क्वेरी की योजना चित्र 6 में दिखाई गई है।
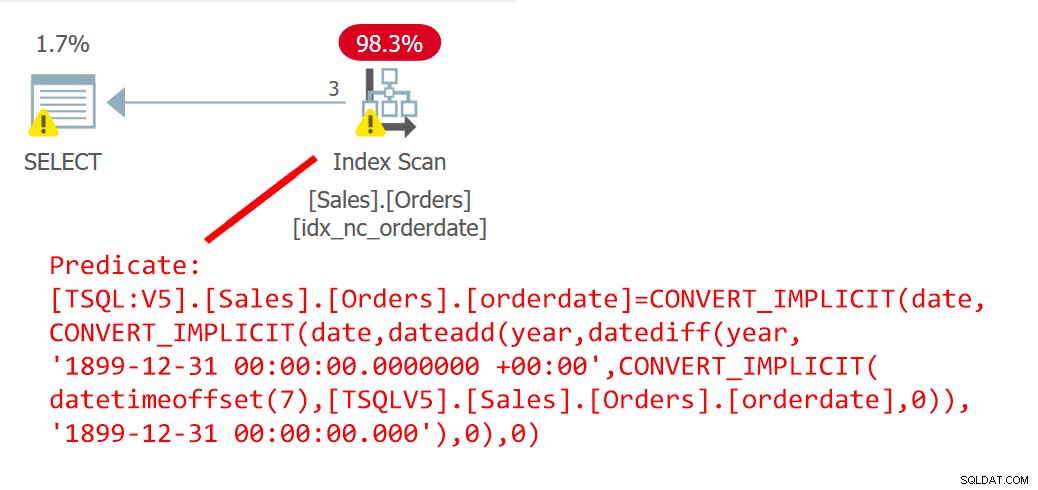
चित्र 6:प्रश्न 6 के लिए योजना
योजना स्पष्ट रूप से दिखाती है कि यूडीएफ इनलाइन हो गया है।
टेबल एक्सप्रेशन, nondeterminism और कई संदर्भ
जैसा कि उल्लेख किया गया है, एक प्रश्न में प्रति संदर्भ एक बार SYSDATETIME जैसे nondeterministic कार्यों को लागू किया जाता है। लेकिन क्या होगा यदि आप CTE जैसी तालिका अभिव्यक्ति में क्वेरी में एक बार ऐसे फ़ंक्शन का संदर्भ देते हैं, और फिर CTE के कई संदर्भों के साथ एक बाहरी क्वेरी है? बहुत से लोग यह महसूस नहीं करते हैं कि तालिका अभिव्यक्ति के प्रत्येक संदर्भ को अलग से विस्तारित किया जाता है, और इनलाइन कोड का परिणाम अंतर्निहित नोडेटर्मिनिस्टिक फ़ंक्शन के कई संदर्भों में होता है। SYSDATETIME जैसे फ़ंक्शन के साथ, प्रत्येक निष्पादन के सटीक समय के आधार पर, आप प्रत्येक के लिए एक अलग परिणाम प्राप्त कर सकते हैं। कुछ लोगों को यह व्यवहार आश्चर्यजनक लगता है।
इसे निम्नलिखित कोड से स्पष्ट किया जा सकता है:
DECLARE @i AS INT = 1, @rc AS INT = NULL;
WHILE 1 = 1
BEGIN;
WITH C1 AS
(
SELECT SYSDATETIME() AS dt
),
C2 AS
(
SELECT dt FROM C1
UNION
SELECT dt FROM C1
)
SELECT @rc = COUNT(*) FROM C2;
IF @rc > 1 BREAK;
SET @i += 1;
END;
SELECT @rc AS distinctvalues, @i AS iterations; यदि C2 में क्वेरी में C1 के दोनों संदर्भ एक ही चीज़ का प्रतिनिधित्व करते हैं, तो इस कोड के परिणामस्वरूप एक अनंत लूप होगा। हालाँकि, चूंकि दो संदर्भ अलग-अलग विस्तारित होते हैं, जब समय ऐसा होता है कि प्रत्येक आह्वान एक अलग 100-नैनोसेकंड अंतराल (परिणाम मूल्य की सटीकता) में होता है, तो संघ का परिणाम दो पंक्तियों में होता है, और कोड को तोड़ना चाहिए कुंडली। इस कोड को चलाएं और अपने लिए देखें। दरअसल, कुछ पुनरावृत्तियों के बाद यह टूट जाता है। मुझे एक निष्पादन में निम्नलिखित परिणाम मिले:
distinctvalues iterations -------------- ----------- 2 448
सबसे अच्छा अभ्यास सीटीई और विचारों जैसे टेबल एक्सप्रेशन का उपयोग करने से बचना है, जब आंतरिक क्वेरी नॉनडेटर्मिनिस्टिक गणनाओं का उपयोग करती है और बाहरी क्वेरी कई बार टेबल एक्सप्रेशन को संदर्भित करती है। यह निश्चित रूप से है जब तक कि आप निहितार्थों को नहीं समझते हैं और आप उनके साथ ठीक हैं। वैकल्पिक विकल्प आंतरिक क्वेरी परिणाम को जारी रखने के लिए हो सकते हैं, जैसे कि एक अस्थायी तालिका में, और फिर अस्थायी तालिका को जितनी बार चाहें उतनी बार क्वेरी करना।
उन उदाहरणों को प्रदर्शित करने के लिए जहां सर्वोत्तम अभ्यास का पालन न करना आपको परेशानी में डाल सकता है, मान लीजिए कि आपको एक प्रश्न लिखना है जो कर्मचारियों को एचआर से जोड़ता है। कर्मचारी तालिका यादृच्छिक रूप से। कार्य को संभालने के लिए आप निम्न क्वेरी (इसे क्वेरी 7 कहते हैं) के साथ आते हैं:
WITH C AS
(
SELECT empid, firstname, lastname, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n
FROM HR.Employees
)
SELECT
C1.empid AS empid1, C1.firstname AS firstname1, C1.lastname AS lastname1,
C2.empid AS empid2, C2.firstname AS firstname2, C2.lastname AS lastname2
FROM C AS C1
INNER JOIN C AS C2
ON C1.n = C2.n + 1; इस क्वेरी की योजना चित्र 7 में दिखाई गई है।
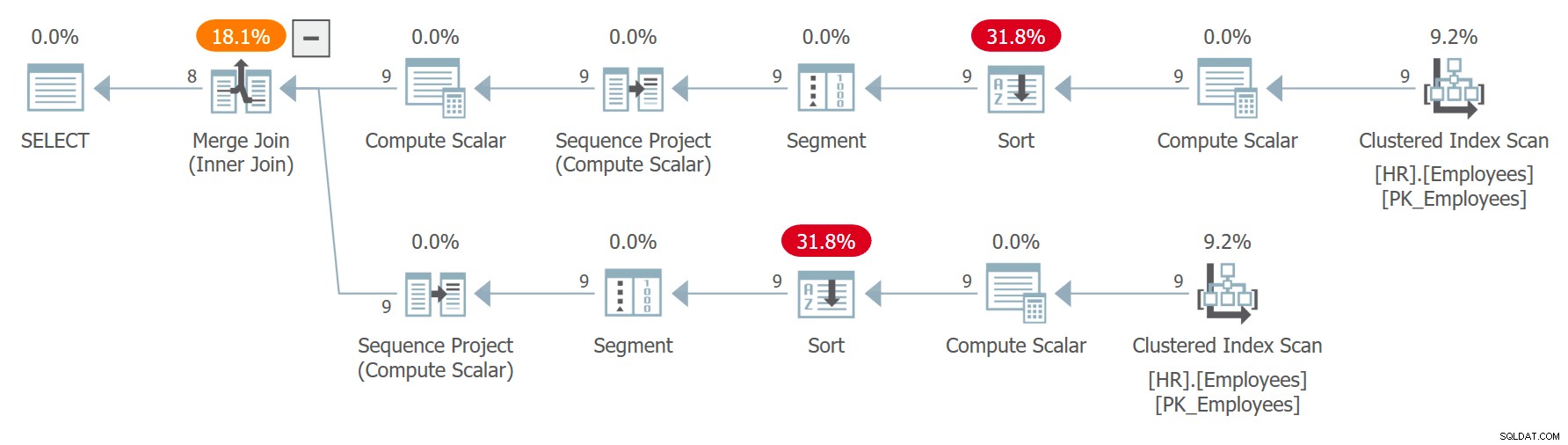
चित्र 7:प्रश्न 7 की योजना
ध्यान दें कि C के दो संदर्भों को अलग-अलग विस्तारित किया गया है, और CHECKSUM (NEWID ()) अभिव्यक्ति के स्वतंत्र आह्वान द्वारा आदेशित प्रत्येक संदर्भ के लिए पंक्ति संख्याओं की स्वतंत्र रूप से गणना की जाती है। इसका मतलब है कि एक ही कर्मचारी को दो विस्तारित संदर्भों में समान पंक्ति संख्या प्राप्त करने की गारंटी नहीं है। यदि किसी कर्मचारी को C1 में पंक्ति संख्या x और C2 में पंक्ति संख्या x - 1 मिलती है, तो क्वेरी कर्मचारी को उसके साथ जोड़ेगी। उदाहरण के लिए, मुझे एक निष्पादन में निम्न परिणाम मिला:
empid1 firstname1 lastname1 empid2 firstname2 lastname2 ----------- ---------- -------------------- ----------- ---------- -------------------- 3 Judy Lew 6 Paul Suurs 9 Patricia Doyle *** 9 Patricia Doyle *** 5 Sven Mortensen 4 Yael Peled 6 Paul Suurs 8 Maria Cameron 8 Maria Cameron 5 Sven Mortensen 2 Don Funk *** 2 Don Funk *** 4 Yael Peled 3 Judy Lew 7 Russell King *** 7 Russell King ***
ध्यान दें कि यहां स्व-जोड़े के तीन मामले हैं। विशेष रूप से सेल्फ़-पेयर की तलाश करने वाली बाहरी क्वेरी में फ़िल्टर जोड़कर इसे देखना आसान है, जैसे:
WITH C AS
(
SELECT empid, firstname, lastname, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n
FROM HR.Employees
)
SELECT
C1.empid AS empid1, C1.firstname AS firstname1, C1.lastname AS lastname1,
C2.empid AS empid2, C2.firstname AS firstname2, C2.lastname AS lastname2
FROM C AS C1
INNER JOIN C AS C2
ON C1.n = C2.n + 1
WHERE C1.empid = C2.empid; समस्या देखने के लिए आपको इस क्वेरी को कई बार चलाने की आवश्यकता हो सकती है। एक निष्पादन में मुझे जो परिणाम मिला, उसके लिए यहां एक उदाहरण दिया गया है:
empid1 firstname1 lastname1 empid2 firstname2 lastname2 ----------- ---------- -------------------- ----------- ---------- -------------------- 5 Sven Mortensen 5 Sven Mortensen 2 Don Funk 2 Don Funk
सर्वोत्तम अभ्यास के बाद, इस समस्या को हल करने का एक तरीका एक अस्थायी तालिका में आंतरिक क्वेरी परिणाम को जारी रखना है और फिर आवश्यकतानुसार अस्थायी तालिका के कई उदाहरणों को क्वेरी करना है।
एक अन्य उदाहरण उन बगों को दिखाता है जो गैर-निर्धारिती क्रम के उपयोग और तालिका अभिव्यक्ति के कई संदर्भों के परिणामस्वरूप हो सकते हैं। मान लीजिए कि आपको Sales.Orders तालिका को क्वेरी करने की आवश्यकता है और प्रवृत्ति विश्लेषण करने के लिए, आप प्रत्येक ऑर्डर को ऑर्डरडेट ऑर्डरिंग के आधार पर अगले के साथ पेयर करना चाहते हैं। आपका समाधान पूर्व-एसक्यूएल सर्वर 2012 सिस्टम के साथ संगत होना चाहिए जिसका अर्थ है कि आप स्पष्ट एलएजी/लीड फ़ंक्शन का उपयोग नहीं कर सकते हैं। आप एक सीटीई का उपयोग करने का निर्णय लेते हैं जो ऑर्डरडेट ऑर्डरिंग के आधार पर पंक्तियों की स्थिति के लिए पंक्ति संख्याओं की गणना करता है, और फिर सीटीई के दो उदाहरणों में शामिल होता है, पंक्ति संख्याओं के बीच 1 के ऑफ़सेट के आधार पर ऑर्डर जोड़ना, जैसे (इस क्वेरी 8 को कॉल करें):
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders
)
SELECT
C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1,
C2.orderid AS orderid2, C2.orderdate AS orderdate2
FROM C AS C1
LEFT OUTER JOIN C AS C2
ON C1.n = C2.n + 1; इस क्वेरी की योजना चित्र 8 में दिखाई गई है।
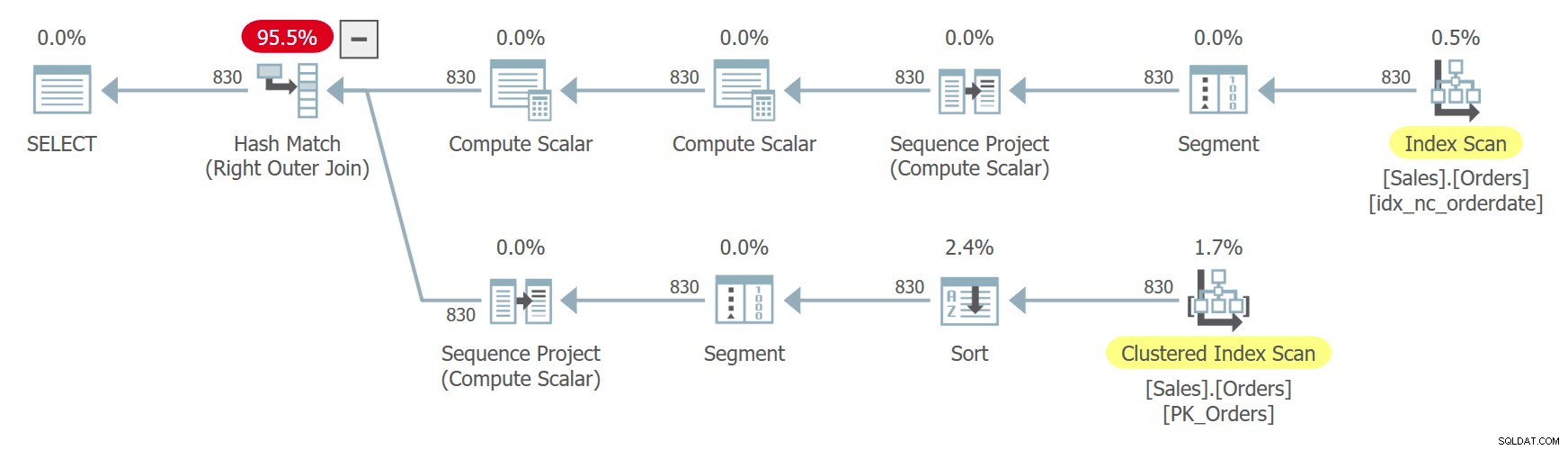 चित्र 8:क्वेरी 8 के लिए योजना
चित्र 8:क्वेरी 8 के लिए योजना
पंक्ति संख्या क्रम निश्चित नहीं है क्योंकि आदेश दिनांक अद्वितीय नहीं है। ध्यान दें कि सीटीई के दो संदर्भ अलग-अलग विस्तारित हो जाते हैं। उत्सुकता से, चूंकि क्वेरी प्रत्येक इंस्टेंस से कॉलम के एक अलग सबसेट की तलाश में है, ऑप्टिमाइज़र प्रत्येक मामले में एक अलग इंडेक्स का उपयोग करने का निर्णय लेता है। एक मामले में यह ऑर्डरडेट पर इंडेक्स के ऑर्डर किए गए बैकवर्ड स्कैन का उपयोग करता है, ऑर्डरिड अवरोही क्रम के आधार पर उसी तारीख के साथ पंक्तियों को प्रभावी ढंग से स्कैन करता है। दूसरे मामले में यह क्लस्टर्ड इंडेक्स को स्कैन करता है, गलत और फिर सॉर्ट करता है, लेकिन प्रभावी रूप से उसी तारीख के साथ पंक्तियों के बीच, यह क्रमबद्ध आरोही क्रम में पंक्तियों तक पहुंचता है। यह इसी तरह के तर्क के कारण है जो मैंने पहले गैर-निर्धारक आदेश के बारे में अनुभाग में प्रदान किया था। इसके परिणामस्वरूप एक ही पंक्ति को एक उदाहरण में पंक्ति संख्या x और दूसरे उदाहरण में पंक्ति संख्या x - 1 प्राप्त हो सकती है। ऐसी स्थिति में, जॉइन एक ऑर्डर का मिलान खुद से करेगा, न कि अगले ऑर्डर के साथ जैसा उसे होना चाहिए।
इस क्वेरी को निष्पादित करते समय मुझे निम्नलिखित परिणाम मिले:
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ----------- ---------- 11074 2019-05-06 73 NULL NULL 11075 2019-05-06 68 11077 2019-05-06 11076 2019-05-06 9 11076 2019-05-06 *** 11077 2019-05-06 65 11075 2019-05-06 11070 2019-05-05 44 11074 2019-05-06 11071 2019-05-05 46 11073 2019-05-05 11072 2019-05-05 20 11072 2019-05-05 *** ...
परिणाम में स्व-मैचों का निरीक्षण करें। फिर से, स्व-मिलान की तलाश में एक फ़िल्टर जोड़कर समस्या को और अधिक आसानी से पहचाना जा सकता है, जैसे:
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders
)
SELECT
C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1,
C2.orderid AS orderid2, C2.orderdate AS orderdate2
FROM C AS C1
LEFT OUTER JOIN C AS C2
ON C1.n = C2.n + 1
WHERE C1.orderid = C2.orderid; मुझे इस क्वेरी से निम्न आउटपुट मिला:
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ----------- ---------- 11076 2019-05-06 9 11076 2019-05-06 11072 2019-05-05 20 11072 2019-05-05 11062 2019-04-30 66 11062 2019-04-30 11052 2019-04-27 34 11052 2019-04-27 11042 2019-04-22 15 11042 2019-04-22 ...
यहां सबसे अच्छा अभ्यास यह सुनिश्चित करना है कि आप विंडो ऑर्डर क्लॉज में ऑर्डरिड जैसे टाईब्रेकर जोड़कर नियतत्ववाद की गारंटी के लिए अद्वितीय ऑर्डर का उपयोग करते हैं। तो भले ही आपके पास एक ही सीटीई के कई संदर्भ हों, दोनों में पंक्ति संख्या समान होगी। यदि आप गणनाओं की पुनरावृत्ति से बचना चाहते हैं, तो आप आंतरिक क्वेरी परिणाम को जारी रखने पर भी विचार कर सकते हैं, लेकिन फिर आपको ऐसे कार्य की अतिरिक्त लागत पर विचार करने की आवश्यकता है।
CASE/NULLIF और गैर-निर्धारिती फ़ंक्शन
जब आपके पास किसी क्वेरी में किसी गैर-निर्धारिती फ़ंक्शन के लिए कई संदर्भ होते हैं, तो प्रत्येक संदर्भ का मूल्यांकन अलग से किया जाता है। आश्चर्य की बात यह हो सकती है और यहां तक कि बग का परिणाम यह है कि कभी-कभी आप एक संदर्भ लिखते हैं, लेकिन स्पष्ट रूप से यह कई संदर्भों में परिवर्तित हो जाता है। CASE एक्सप्रेशन और IIF फ़ंक्शन के कुछ उपयोगों के साथ ऐसी ही स्थिति है।
निम्नलिखित उदाहरण पर विचार करें:
SELECT CASE ABS(CHECKSUM(NEWID())) % 2 WHEN 0 THEN 'Even' WHEN 1 THEN 'Odd' END;
यहां परीक्षित व्यंजक का परिणाम एक ऋणात्मक पूर्णांक मान है, इसलिए स्पष्ट रूप से इसे सम या विषम होना चाहिए। It cannot be neither even nor odd. However, if you run this code enough times, you will sometimes get a NULL indicating that the implied ELSE NULL clause of the CASE expression was activated. The reason for this is that the above expression translates to the following:
SELECT
CASE
WHEN ABS(CHECKSUM(NEWID())) % 2 = 0 THEN 'Even'
WHEN ABS(CHECKSUM(NEWID())) % 2 = 1 THEN 'Odd'
ELSE NULL
END; In the converted expression there are two separate references to the tested expression that generates a random nonnegative value, and each gets evaluated separately. One possible path is that the first evaluation produces an odd number, the second produces an even number, and then the ELSE NULL clause is activated.
Here’s a very similar situation with the NULLIF function:
SELECT NULLIF(ABS(CHECKSUM(NEWID())) % 2, 0);
This expression generates a random nonnegative value, and is supposed to return 1 when it’s odd, and NULL otherwise. It’s never supposed to return 0 since in such a case the 0 is supposed to be replaced with a NULL. Run it a few times and you will see that in some cases you get a 0. The reason for this is that the above expression internally translates to the following one:
SELECT
CASE
WHEN ABS(CHECKSUM(NEWID())) % 2 = 0 THEN NULL
ELSE ABS(CHECKSUM(NEWID())) % 2
END; A possible path is that the first WHEN clause generates a random odd value, so the ELSE clause is activated, and the ELSE clause generates a random even value so the % 2 calculation results in a 0.
In both cases this behavior is standard, so the bug is more in the eyes of the beholder based on your expectations and your choice of how to write the code. The best practice in both cases is to persist the result of the original calculation and then interact with the persisted result. If it’s a single value, store the result in a variable first. If you’re querying tables, first persist the result of the nondeterministic calculation in a column in a temporary table, and then apply the CASE/IIF logic in the query against the temporary table.
Conclusion
This article is the first in a series about T-SQL bugs, pitfalls and best practices, and is the result of discussions with fellow Microsoft Data Platform MVPs who shared their experiences. This time I focused on bugs and pitfalls that resulted from using nondeterministic order and nondeterministic calculations. In future articles I’ll continue with other themes. If you have bugs and pitfalls that you often stumble into, or that you find as particularly interesting, please do share!