फ़िल्टर किए गए अनुक्रमणिका को जोड़ने से मौजूदा प्रश्नों पर आश्चर्यजनक दुष्प्रभाव हो सकते हैं, यहां तक कि जहां ऐसा लगता है कि नया फ़िल्टर किया गया अनुक्रमणिका पूरी तरह से असंबंधित है। यह पोस्ट DELETE कथनों को प्रभावित करने वाले एक उदाहरण को देखती है जिसके परिणामस्वरूप खराब प्रदर्शन और गतिरोध का खतरा बढ़ जाता है।
परीक्षण पर्यावरण
इस पूरी पोस्ट में निम्न तालिका का उपयोग किया जाएगा:
CREATE TABLE dbo.Data
(
RowID integer IDENTITY NOT NULL,
SomeValue integer NOT NULL,
StartDate date NOT NULL,
CurrentFlag bit NOT NULL,
Padding char(50) NOT NULL DEFAULT REPLICATE('ABCDE', 10),
CONSTRAINT PK_Data_RowID
PRIMARY KEY CLUSTERED (RowID)
); यह अगला कथन नमूना डेटा की 499,999 पंक्तियाँ बनाता है:
INSERT dbo.Data WITH (TABLOCKX)
(SomeValue, StartDate, CurrentFlag)
SELECT
CONVERT(integer, RAND(n) * 1e6) % 1000,
DATEADD(DAY, (N.n - 1) % 31, '20140101'),
CONVERT(bit, 0)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n < 500000; यह 1 से 499,999 तक लगातार पूर्णांकों के स्रोत के रूप में एक संख्या तालिका का उपयोग करता है। यदि आपके पास अपने परीक्षण वातावरण में उनमें से एक नहीं है, तो निम्नलिखित कोड का उपयोग कुशलतापूर्वक 1 से 1,000,000 तक के पूर्णांक वाले एक को बनाने के लिए किया जा सकता है:
WITH
N1 AS (SELECT N1.n FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS N1 (n)),
N2 AS (SELECT L.n FROM N1 AS L CROSS JOIN N1 AS R),
N3 AS (SELECT L.n FROM N2 AS L CROSS JOIN N2 AS R),
N4 AS (SELECT L.n FROM N3 AS L CROSS JOIN N2 AS R),
N AS (SELECT ROW_NUMBER() OVER (ORDER BY n) AS n FROM N4)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM N
OPTION (MAXDOP 1);
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1); बाद के परीक्षणों का आधार किसी विशेष StartDate के लिए परीक्षण तालिका से पंक्तियों को हटाना होगा। हटाने के लिए पंक्तियों की पहचान करने की प्रक्रिया को अधिक कुशल बनाने के लिए, इस गैर-संकुल अनुक्रमणिका को जोड़ें:
CREATE NONCLUSTERED INDEX
IX_Data_StartDate
ON dbo.Data
(StartDate); नमूना डेटा
एक बार वे चरण पूरे हो जाने पर, नमूना इस तरह दिखेगा:
SELECT TOP (100)
D.RowID,
D.SomeValue,
D.StartDate,
D.CurrentFlag,
D.Padding
FROM dbo.Data AS D
ORDER BY
D.RowID;
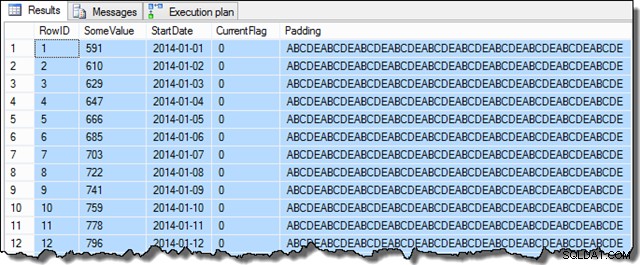
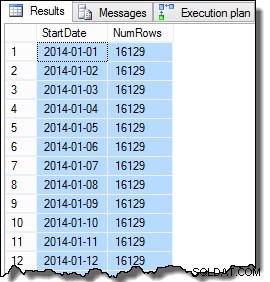
कुछ वैल्यू कॉलम डेटा छद्म-यादृच्छिक पीढ़ी के कारण थोड़ा अलग हो सकता है, लेकिन यह अंतर महत्वपूर्ण नहीं है। कुल मिलाकर, नमूना डेटा में जनवरी 2014 में 31 प्रारंभ दिनांक दिनांकों में से प्रत्येक के लिए 16,129 पंक्तियाँ हैं:
SELECT
D.StartDate,
NumRows = COUNT_BIG(*)
FROM dbo.Data AS D
GROUP BY
D.StartDate
ORDER BY
D.StartDate;
डेटा को कुछ हद तक यथार्थवादी बनाने के लिए हमें जो अंतिम चरण करने की आवश्यकता है, वह है प्रत्येक StartDate के लिए उच्चतम RowID के लिए CurrentFlag कॉलम को सही पर सेट करना। निम्न स्क्रिप्ट इस कार्य को पूरा करती है:
WITH LastRowPerDay AS
(
SELECT D.CurrentFlag
FROM dbo.Data AS D
WHERE D.RowID =
(
SELECT MAX(D2.RowID)
FROM dbo.Data AS D2
WHERE D2.StartDate = D.StartDate
)
)
UPDATE LastRowPerDay
SET CurrentFlag = 1; इस अद्यतन के लिए निष्पादन योजना में प्रति दिन उच्चतम RowID का कुशलतापूर्वक पता लगाने के लिए एक सेगमेंट-टॉप संयोजन है:

ध्यान दें कि निष्पादन योजना क्वेरी के लिखित रूप से कैसे मिलती-जुलती है। यह एक बेहतरीन उदाहरण है कि कैसे ऑप्टिमाइज़र सीधे SQL को लागू करने के बजाय तार्किक SQL विनिर्देश से काम करता है। यदि आप सोच रहे हैं, हैलोवीन सुरक्षा के लिए उस योजना में उत्सुक टेबल स्पूल आवश्यक है।
एक दिन का डेटा मिटाना
ठीक है, इसलिए प्रारंभिक कार्य पूरा होने के साथ, हाथ में कार्य किसी विशेष StartDate के लिए पंक्तियों को हटाना है। यह एक प्रकार की क्वेरी है जिसे आप नियमित रूप से किसी तालिका में सबसे प्रारंभिक तिथि पर चला सकते हैं, जहां डेटा अपने उपयोगी जीवन के अंत तक पहुंच गया है।
1 जनवरी 2014 को हमारे उदाहरण के रूप में लेते हुए, परीक्षण हटाने की क्वेरी सरल है:
DELETE dbo.Data WHERE StartDate = '20140101';
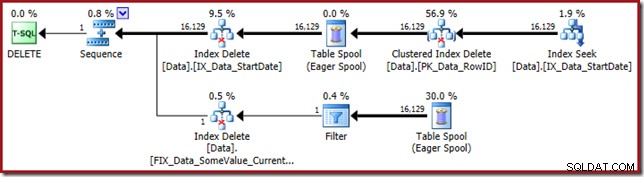
निष्पादन योजना भी काफी सरल है, हालांकि थोड़ा विस्तार से देखने लायक है:

योजना विश्लेषण
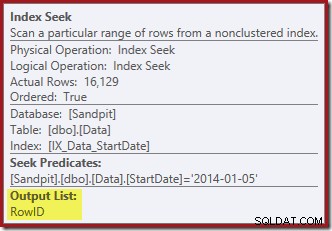
इंडेक्स सीक दूर दाईं ओर निर्दिष्ट स्टार्टडेट मान के लिए पंक्तियों को खोजने के लिए गैर-संकुल सूचकांक का उपयोग करता है। जैसा कि ऑपरेटर टूलटिप पुष्टि करता है, यह केवल RowID मान देता है जो इसे पाता है:
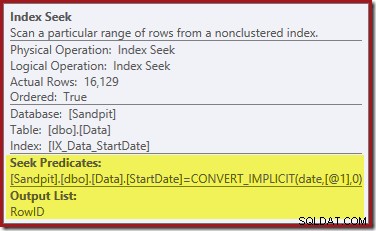
यदि आप सोच रहे हैं कि StartDate अनुक्रमणिका RowID को वापस करने का प्रबंधन कैसे करती है, तो याद रखें कि RowID तालिका के लिए अद्वितीय संकुल अनुक्रमणिका है, इसलिए यह स्वचालित रूप से StartDate गैर-संकुल अनुक्रमणिका में शामिल हो जाती है।
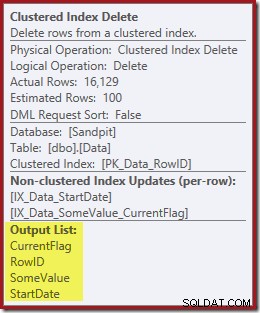
योजना में अगला ऑपरेटर क्लस्टर इंडेक्स डिलीट है। यह निकालने के लिए पंक्तियों का पता लगाने के लिए अनुक्रमणिका सीक द्वारा प्राप्त RowID मान का उपयोग करता है।
योजना में अंतिम ऑपरेटर इंडेक्स डिलीट है। यह गैर-संकुल अनुक्रमणिका IX_Data_StartDate . से पंक्तियों को हटा देता है जो क्लस्टर्ड इंडेक्स डिलीट द्वारा हटाए गए RowID से संबंधित हैं। गैर-संकुल अनुक्रमणिका में इन पंक्तियों का पता लगाने के लिए, क्वेरी प्रोसेसर को StartDate (गैर-संकुल अनुक्रमणिका की कुंजी) की आवश्यकता होती है।
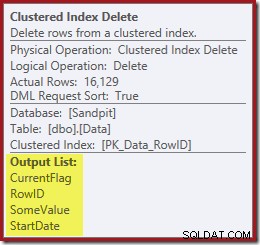
याद रखें कि मूल अनुक्रमणिका सीक ने प्रारंभ दिनांक, केवल RowID को वापस नहीं किया। तो क्वेरी प्रोसेसर को इंडेक्स डिलीट के लिए स्टार्टडेट कैसे मिलता है? इस विशेष मामले में, ऑप्टिमाइज़र ने देखा होगा कि StartDate मान स्थिर है और इसे अनुकूलित किया गया है, लेकिन ऐसा नहीं हुआ है। इसका उत्तर यह है कि क्लस्टर्ड इंडेक्स डिलीट ऑपरेटर पढ़ता है वर्तमान पंक्ति के लिए StartDate मान और इसे स्ट्रीम में जोड़ता है। नीचे दिखाए गए क्लस्टर इंडेक्स डिलीट की आउटपुट लिस्ट की तुलना इंडेक्स सीक के साथ करें:
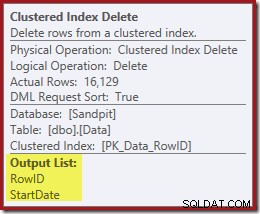
डिलीट ऑपरेटर को डेटा पढ़ते हुए देखना आश्चर्यजनक लग सकता है, लेकिन यह काम करने का तरीका है। क्वेरी प्रोसेसर जानता है कि उसे हटाने के लिए उसे क्लस्टर्ड इंडेक्स में पंक्ति का पता लगाना होगा, इसलिए यह उस समय तक गैर-क्लस्टर इंडेक्स को बनाए रखने के लिए आवश्यक रीडिंग कॉलम को भी स्थगित कर सकता है, यदि ऐसा हो सकता है।
फ़िल्टर की गई अनुक्रमणिका जोड़ना
अब कल्पना कीजिए कि किसी के पास इस तालिका के खिलाफ एक महत्वपूर्ण प्रश्न है जो खराब प्रदर्शन कर रहा है। सहायक डीबीए एक विश्लेषण करता है और निम्नलिखित फ़िल्टर्ड इंडेक्स जोड़ता है:
CREATE NONCLUSTERED INDEX
FIX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue)
INCLUDE (CurrentFlag)
WHERE CurrentFlag = 1; नए फ़िल्टर किए गए इंडेक्स का समस्याग्रस्त क्वेरी पर वांछित प्रभाव पड़ता है, और हर कोई खुश है। ध्यान दें कि नया इंडेक्स स्टार्टडेट कॉलम का बिल्कुल भी संदर्भ नहीं देता है, इसलिए हम यह उम्मीद नहीं करते हैं कि यह हमारी दिन-डिलीट क्वेरी को बिल्कुल भी प्रभावित करेगा।
फ़िल्टर किए गए अनुक्रमणिका के साथ एक दिन हटाना
हम दूसरी बार डेटा हटाकर उस अपेक्षा का परीक्षण कर सकते हैं:
DELETE dbo.Data WHERE StartDate = '20140102';
अचानक, निष्पादन योजना एक समानांतर क्लस्टर इंडेक्स स्कैन में बदल गई है:

ध्यान दें कि नए फ़िल्टर किए गए इंडेक्स के लिए कोई अलग इंडेक्स डिलीट ऑपरेटर नहीं है। ऑप्टिमाइज़र ने इस इंडेक्स को क्लस्टर्ड इंडेक्स डिलीट ऑपरेटर के अंदर बनाए रखने के लिए चुना है। इसे SQL सेंट्री प्लान एक्सप्लोरर में हाइलाइट किया गया है जैसा कि ऊपर दिखाया गया है ("+1 गैर-क्लस्टर इंडेक्स") टूलटिप में पूर्ण विवरण के साथ:
यदि तालिका बड़ी है (डेटा वेयरहाउस सोचें) समानांतर स्कैन में यह परिवर्तन बहुत महत्वपूर्ण हो सकता है। StartDate पर अच्छे इंडेक्स सीक का क्या हुआ, और पूरी तरह से असंबंधित फ़िल्टर्ड इंडेक्स ने चीजों को इतना नाटकीय रूप से क्यों बदल दिया?
समस्या का पता लगाना
क्लस्टर इंडेक्स स्कैन के गुणों को देखने से पहला सुराग मिलता है:
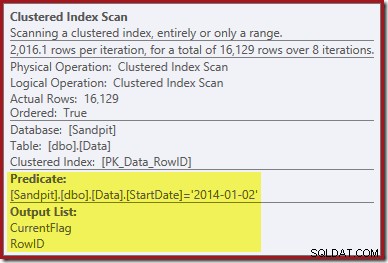
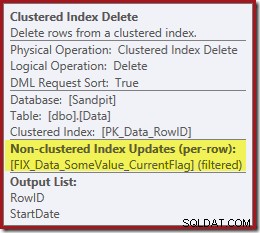
क्लस्टर इंडेक्स डिलीट ऑपरेटर को हटाने के लिए RowID मानों को खोजने के साथ-साथ, यह ऑपरेटर अब CurrentFlag मान पढ़ रहा है। इस कॉलम की आवश्यकता स्पष्ट नहीं है, लेकिन यह कम से कम स्कैन करने के निर्णय की व्याख्या करना शुरू कर देता है:CurrentFlag कॉलम हमारे StartDate गैर-संकुल सूचकांक का हिस्सा नहीं है।
StartDate गैर-संकुल अनुक्रमणिका के उपयोग के लिए बाध्य करने के लिए हम डिलीट क्वेरी को फिर से लिखकर इसकी पुष्टि कर सकते हैं:
DELETE D
FROM dbo.Data AS D
WITH (INDEX(IX_Data_StartDate))
WHERE StartDate = '20140103'; निष्पादन योजना अपने मूल स्वरूप के करीब है, लेकिन अब इसमें एक मुख्य खोज शामिल है:
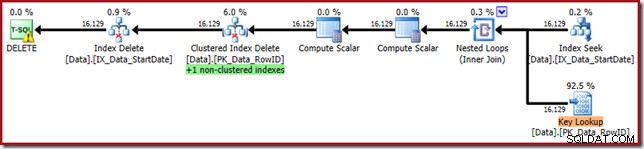
मुख्य लुकअप गुण पुष्टि करते हैं कि यह ऑपरेटर CurrentFlag मान प्राप्त कर रहा है:
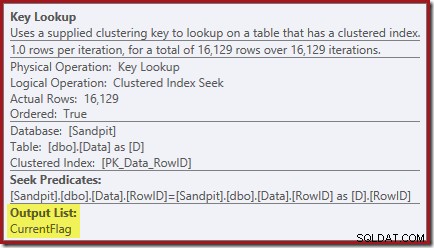
आपने पिछली दो योजनाओं में चेतावनी त्रिकोण पर भी ध्यान दिया होगा। इनमें अनुक्रमणिका चेतावनियां नहीं हैं:
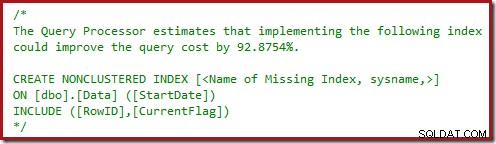
यह आगे पुष्टि करता है कि SQL सर्वर गैर-संकुल अनुक्रमणिका में शामिल CurrentFlag कॉलम को देखना चाहेगा। समानांतर क्लस्टर इंडेक्स स्कैन में परिवर्तन का कारण अब स्पष्ट है:क्वेरी प्रोसेसर यह तय करता है कि की लुकअप करने की तुलना में टेबल को स्कैन करना सस्ता होगा।
हां, लेकिन क्यों?
यह सब बहुत अजीब है। मूल निष्पादन योजना में, SQL सर्वर पढ़ने में सक्षम था क्लस्टर्ड इंडेक्स डिलीट ऑपरेटर पर गैर-क्लस्टर इंडेक्स को बनाए रखने के लिए अतिरिक्त कॉलम डेटा की आवश्यकता होती है। फ़िल्टर किए गए अनुक्रमणिका को बनाए रखने के लिए CurrentFlag कॉलम मान की आवश्यकता होती है, तो SQL सर्वर इसे उसी तरह से क्यों नहीं संभालता है?
संक्षिप्त उत्तर यह है कि यह कर सकता है, लेकिन केवल अगर फ़िल्टर किए गए इंडेक्स को एक अलग इंडेक्स डिलीट ऑपरेटर में बनाए रखा जाता है। हम गैर-दस्तावेजी ट्रेस ध्वज 8790 का उपयोग करके वर्तमान क्वेरी के लिए इसे बाध्य कर सकते हैं। इस ध्वज के बिना, अनुकूलक चुनता है कि प्रत्येक अनुक्रमणिका को एक अलग ऑपरेटर में बनाए रखना है या बेस टेबल ऑपरेशन के हिस्से के रूप में।
-- Forced wide update plan DELETE dbo.Data WHERE StartDate = '20140105' OPTION (QUERYTRACEON 8790);
निष्पादन योजना StartDate गैर-संकुल अनुक्रमणिका की तलाश में वापस आ गई है:
इंडेक्स सीक केवल RowID मान देता है (कोई CurrentFlag नहीं):
और क्लस्टर्ड इंडेक्स डिलीट पढ़ता है गैर-संकुल अनुक्रमणिका को बनाए रखने के लिए आवश्यक स्तंभ, जिसमें CurrentFlag भी शामिल है:
यह डेटा उत्सुकता से एक टेबल स्पूल को लिखा जाता है, जिसे प्रत्येक इंडेक्स के लिए फिर से चलाया जाता है जिसे बनाए रखने की आवश्यकता होती है। फ़िल्टर किए गए इंडेक्स के लिए इंडेक्स डिलीट ऑपरेटर से पहले स्पष्ट फ़िल्टर ऑपरेटर पर भी ध्यान दें।
देखने के लिए एक और पैटर्न
यह समस्या हमेशा इंडेक्स सीक के बजाय टेबल स्कैन में परिणत नहीं होती है। इसका एक उदाहरण देखने के लिए, परीक्षण तालिका में एक और अनुक्रमणिका जोड़ें:
CREATE NONCLUSTERED INDEX
IX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue, CurrentFlag); ध्यान दें कि यह अनुक्रमणिका नहीं है फ़िल्टर किया गया है, और इसमें StartDate कॉलम शामिल नहीं है। अब एक दिन-डिलीट क्वेरी का पुन:प्रयास करें:
DELETE dbo.Data WHERE StartDate = '20140104';
अनुकूलक अब इस राक्षस के साथ आता है:
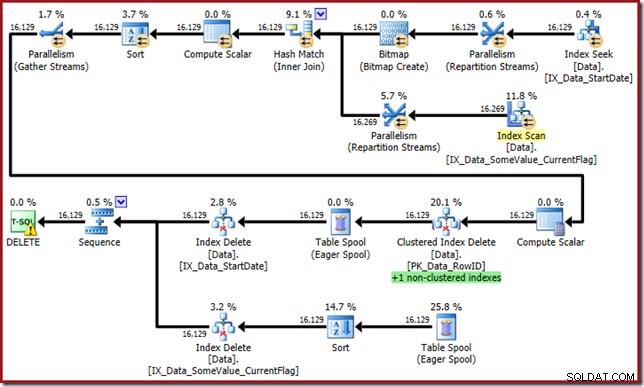
इस क्वेरी प्लान में एक उच्च आश्चर्य कारक है, लेकिन मूल कारण वही है। CurrentFlag कॉलम की अभी भी आवश्यकता है, लेकिन अब ऑप्टिमाइज़र टेबल स्कैन के बजाय इसे प्राप्त करने के लिए एक इंडेक्स इंटरसेक्शन रणनीति चुनता है। ट्रेस फ्लैग का उपयोग करने से प्रति-सूचकांक रखरखाव योजना को बल मिलता है और विवेक एक बार फिर से बहाल हो जाता है (नई अनुक्रमणिका को बनाए रखने के लिए केवल एक अतिरिक्त स्पूल रीप्ले का अंतर है):
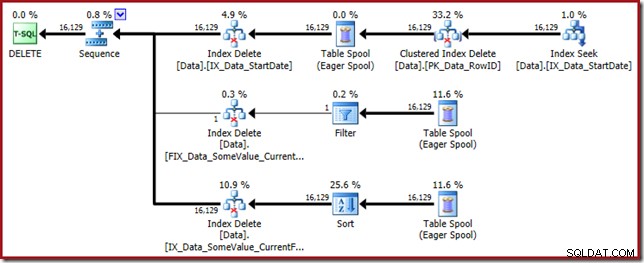
केवल फ़िल्टर किए गए इंडेक्स ही इसका कारण बनते हैं
यह समस्या केवल तब होती है जब ऑप्टिमाइज़र क्लस्टर्ड इंडेक्स डिलीट ऑपरेटर में फ़िल्टर किए गए इंडेक्स को बनाए रखना चुनता है। गैर-फ़िल्टर्ड इंडेक्स प्रभावित नहीं होते हैं, जैसा कि निम्न उदाहरण दिखाता है। फ़िल्टर किए गए इंडेक्स को छोड़ना पहला कदम है:
DROP INDEX FIX_Data_SomeValue_CurrentFlag ON dbo.Data;
अब हमें क्वेरी को इस तरह से लिखने की आवश्यकता है जो ऑप्टिमाइज़र को क्लस्टर्ड इंडेक्स डिलीट में सभी इंडेक्स को बनाए रखने के लिए आश्वस्त करे। इसके लिए मेरी पसंद अनुकूलक की पंक्ति गणना अपेक्षाओं को कम करने के लिए एक चर और एक संकेत का उपयोग करना है:
-- All qualifying rows will be deleted
DECLARE @Rows bigint = 9223372036854775807;
-- Optimize the plan for deleting 100 rows
DELETE TOP (@Rows)
FROM dbo.Data
OUTPUT
Deleted.RowID,
Deleted.SomeValue,
Deleted.StartDate,
Deleted.CurrentFlag
WHERE StartDate = '20140106'
OPTION (OPTIMIZE FOR (@Rows = 100)); निष्पादन योजना है:
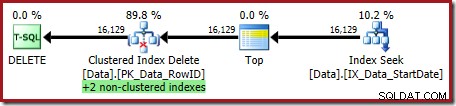
दोनों गैर-संकुल अनुक्रमणिकाएँ संकुल अनुक्रमणिका हटाएँ द्वारा बनाए रखी जाती हैं:
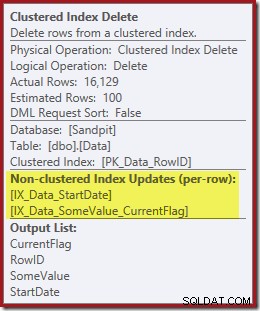
इंडेक्स सीक केवल RowID लौटाता है:
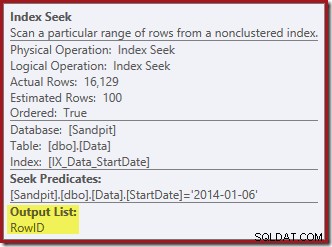
इंडेक्स रखरखाव के लिए आवश्यक कॉलम डिलीट ऑपरेटर द्वारा आंतरिक रूप से पुनर्प्राप्त किए जाते हैं; ये विवरण शो प्लान आउटपुट में उजागर नहीं होते हैं (इसलिए डिलीट ऑपरेटर की आउटपुट सूची खाली होगी)। मैंने एक OUTPUT जोड़ा है क्लस्टर्ड इंडेक्स दिखाने के लिए क्वेरी का क्लॉज एक बार फिर से डेटा लौटाता है जो इसे अपने इनपुट पर प्राप्त नहीं होता है:
अंतिम विचार
यह काम करने के लिए एक मुश्किल सीमा है। एक ओर, हम आम तौर पर उत्पादन प्रणालियों में अनिर्दिष्ट ट्रेस फ़्लैग का उपयोग नहीं करना चाहते हैं।
प्राकृतिक 'समाधान' फ़िल्टर किए गए अनुक्रमणिका रखरखाव के लिए आवश्यक कॉलम को सभी . में जोड़ना है गैर-संकुल अनुक्रमणिका जिनका उपयोग हटाने के लिए पंक्तियों का पता लगाने के लिए किया जा सकता है। यह कई दृष्टिकोणों से बहुत आकर्षक प्रस्ताव नहीं है। एक अन्य विकल्प यह है कि फ़िल्टर किए गए इंडेक्स का बिल्कुल भी उपयोग न करें, लेकिन यह शायद ही आदर्श हो।
मेरी भावना यह है कि क्वेरी ऑप्टिमाइज़र को स्वचालित रूप से फ़िल्टर किए गए इंडेक्स के लिए प्रति-इंडेक्स रखरखाव विकल्प पर विचार करना चाहिए, लेकिन इसका तर्क अभी इस क्षेत्र में अधूरा प्रतीत होता है (और प्रति-सूचकांक/प्रति-पंक्ति की उचित लागत के बजाय सरल अनुमानों के आधार पर) विकल्प)।
उस कथन के आस-पास कुछ संख्याएं रखने के लिए, अनुकूलक द्वारा चुनी गई समानांतर संकुल अनुक्रमणिका स्कैन योजना 5.5 पर आई मेरे परीक्षणों में इकाइयाँ। ट्रेस फ़्लैग वाली वही क्वेरी 1.4 . की लागत का अनुमान लगाती है इकाइयां तीसरी अनुक्रमणिका के साथ, अनुकूलक द्वारा चुनी गई समानांतर अनुक्रमणिका-चौराहे योजना की अनुमानित लागत 4.9 थी , जबकि ट्रेस फ़्लैग योजना 2.7 . पर आई थी इकाइयां (एसक्यूएल सर्वर 2014 आरटीएम सीयू1 पर सभी परीक्षण 120 कार्डिनैलिटी अनुमान मॉडल के तहत 12.0.2342 का निर्माण करते हैं, और ट्रेस फ्लैग 4199 सक्षम हैं)।
मैं इसे व्यवहार के रूप में मानता हूं जिसमें सुधार किया जाना चाहिए। आप इस कनेक्ट आइटम पर मुझसे सहमत या असहमत होने के लिए वोट कर सकते हैं।