प्रिज्मा एक दिलचस्प ओआरएम है।
ORM डेटाबेस पर एक अमूर्त परत है।
मुझे पिछले महीनों में कुछ अलग-अलग परियोजनाओं में प्रिज्मा का उपयोग करने में खुशी हुई है, और यहां मैं आपको दिखाना चाहता हूं कि इसे शुरू करना (और जारी रखना) कितना आसान है।
मैं नेक्स्ट.जेएस पर आधारित रिएक्ट एप्लिकेशन में प्रिज्मा का उपयोग करने जा रहा हूं।
आप
. के साथ एक फ़ोल्डर में एक नया Next.js ऐप बना सकते हैंnpx create-next-app
प्रिज्मा जोड़ने के लिए सबसे पहले आपको prisma . को शामिल करना होगा आपकी देव निर्भरता में:
npm install -D prisma
अब आपके पास npx . का उपयोग करके प्रिज्मा सीएलआई उपयोगिता तक पहुंच है . दौड़ने का प्रयास करें:
npx prismaऔर आपको इसका उपयोग करने के निर्देश दिखाई देंगे।
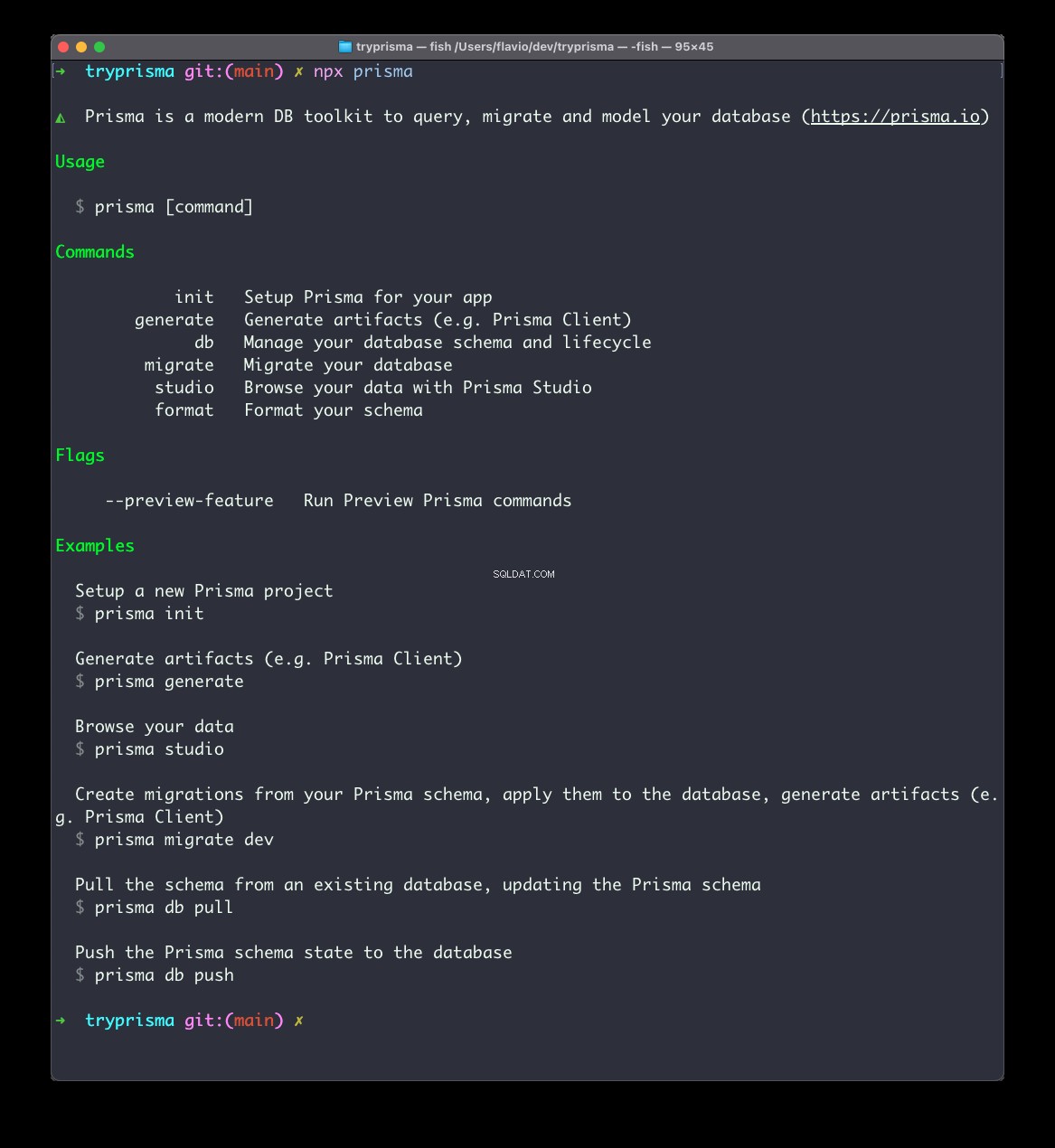
अब इसे अपने प्रोजेक्ट के लिए प्रिज्मा सेटअप करने के लिए चलाएँ:
npx prisma init

यह एक prismaबनेगा फ़ोल्डर, और उसके अंदर, एक schema.prisma फ़ाइल:
// This is your Prisma schema file,
// learn more about it in the docs: https://pris.ly/d/prisma-schema
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
generator client {
provider = "prisma-client-js"
}
इसने एक .env . भी बनाया फ़ाइल, यदि आपके पास पहले से एक नहीं है, तो DATABASE_URL . के साथ पर्यावरण चर:
DATABASE_URL="postgresql://johndoe:randompassword@localhost:5432/mydb?schema=public"इसे आपके डेटाबेस को इंगित करना होगा।
आइए पहले इस बिंदु को रास्ते से हटा दें। प्रिज्मा कई अलग-अलग प्रकार के (रिलेशनल) डेटाबेस का समर्थन करता है। मैंने इसे PostgreSQL और SQLite के साथ उपयोग किया है, लेकिन यह MySQL, AWS Aurora, MariaDB को भी सपोर्ट करता है।
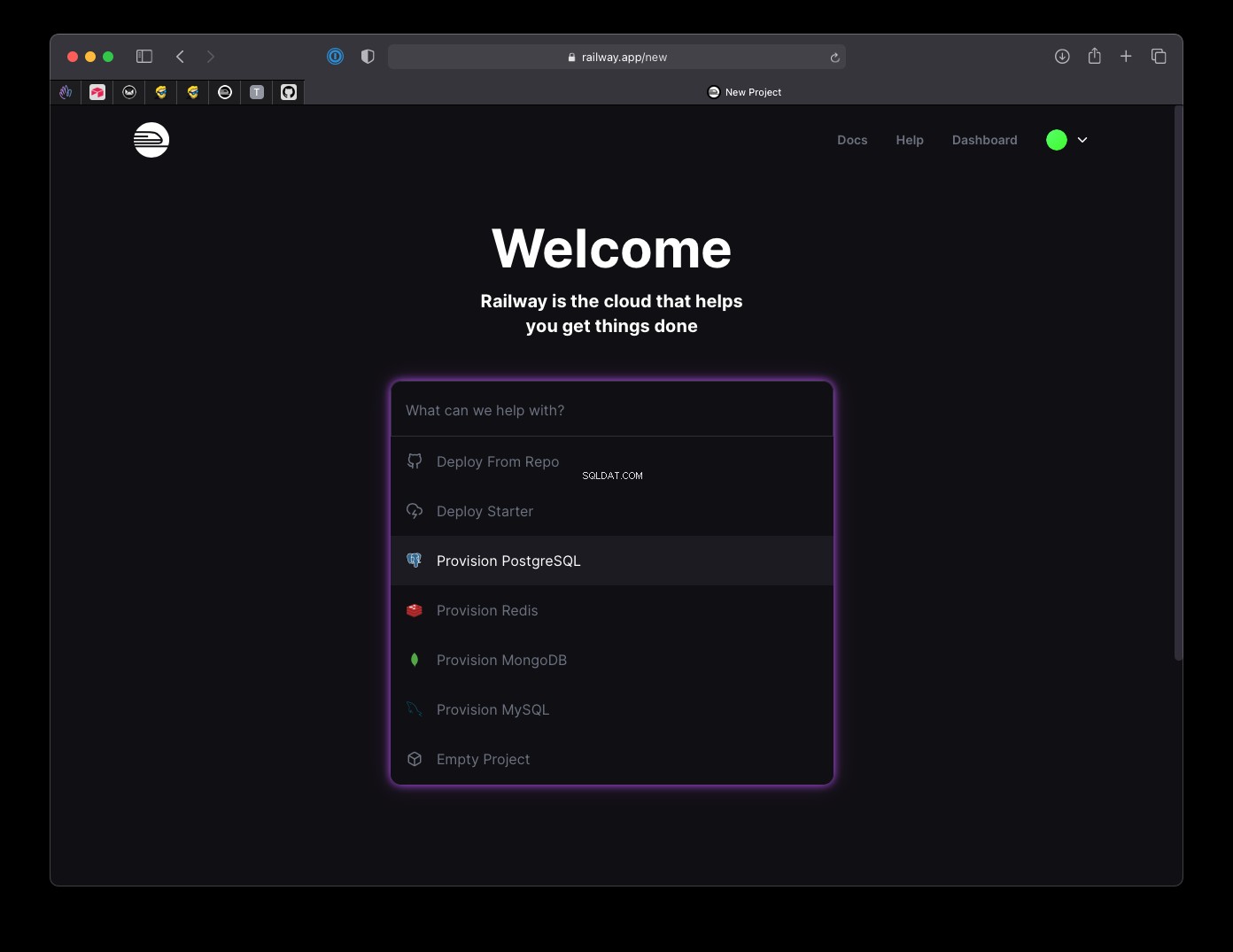
उत्पादन में मैं DigitalOcean के प्रबंधित डेटाबेस का उपयोग करना पसंद करता हूं (यहां $ 100 के मुफ्त क्रेडिट के लिए अनिवार्य रेफरल लिंक), लेकिन एक त्वरित उदाहरण ऐप के लिए, Railway.app एक अच्छा और मुफ्त विकल्प है।
साइन अप करने के बाद आप एक क्लिक के साथ PostgreSQL डेटाबेस का प्रावधान कर सकते हैं:
और इसके तुरंत बाद, आपको कनेक्शन URL प्राप्त होगा:
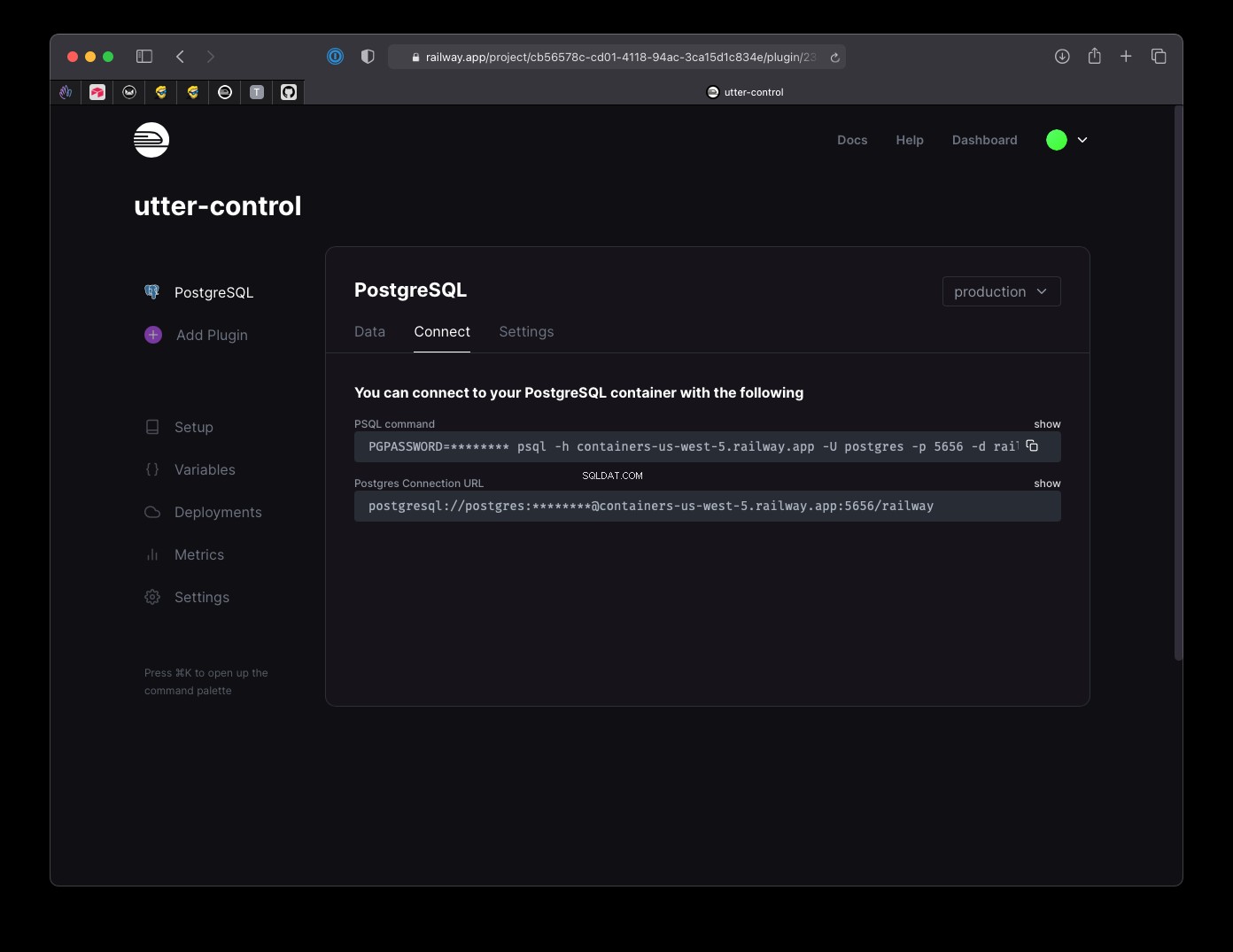
इसे अपने .env . पर कॉपी करें फ़ाइल को DATABASE_URL . के रूप में दर्ज करें मूल्य।
अब स्कीमा में एक मॉडल जोड़ने का समय है, जिसे डेटाबेस तालिका में अनुवादित किया जाएगा।
<ब्लॉकक्वॉट>
ध्यान दें कि आप इसके विपरीत भी कर सकते हैं, यदि आपके पास पहले से ही तालिकाओं से भरा एक डेटाबेस है, तो npx prisma introspect चलाकर . प्रिज्मा डेटाबेस से स्कीमा उत्पन्न करेगा।
मान लीजिए कि हम एक फैंसी अरबपति हैं जो कारों को इकट्ठा करना पसंद करते हैं। हम एक Car बनाते हैं कारों की सूची को स्टोर करने के लिए मॉडल जिसे हम खरीदना चाहते हैं:
model Car {
id Int @id @default(autoincrement())
brand String
model String
created_at DateTime @default(now())
bought Boolean @default(false)
}मैं आपको प्रिज्मा स्कीमा संदर्भ दस्तावेज़ीकरण में सब कुछ देखने की अत्यधिक अनुशंसा करता हूं।
यह मॉडल 5 क्षेत्रों को परिभाषित करता है:id , brand , model , created_at , bought , प्रत्येक अपने प्रकार के साथ, चाहे वह इंट, स्ट्रिंग, डेटाटाइम या बूलियन हो।
id में @id है विशेषता जिसका अर्थ है कि यह प्राथमिक कुंजी है , जो डेटाबेस प्रबंधन प्रणाली को इसे विशिष्ट बनाने के लिए कहता है। और यह डिफ़ॉल्ट रूप से उस मान पर आ जाता है जो स्वचालित रूप से बढ़ जाता है, इसलिए जब भी हम एक नया आइटम जोड़ते हैं, तो इसमें हमेशा एक अद्वितीय पूर्णांक संख्या होती है जो वृद्धि करती है:1, 2, 3, 4…
ध्यान दें कि आप @default(cuid()) . के साथ एक अद्वितीय मान का भी उपयोग कर सकते हैं या @default(uuid()) ।
created_at @default(now()) . के साथ वर्तमान डेटाटाइम के लिए डिफ़ॉल्ट , और bought डिफ़ॉल्ट रूप से false ।
अब हमें सिंक . करने की आवश्यकता है हमारे स्कीमा के साथ डेटाबेस। हम npx prisma migrate . कमांड चलाकर ऐसा करते हैं हमारा पहला माइग्रेशन बनाने के लिए :
npx prisma migrate dev
अब आप डेटाबेस में देख सकते हैं, एक Car होगा तालिका:
और आपके कोडबेस में prisma/migrations . में एक फ़ाइल उन तालिकाओं को बनाने के लिए उपयोग किए जाने वाले आदेशों के साथ फ़ोल्डर, इस मामले में:
-- CreateTable
CREATE TABLE "Car" (
"id" SERIAL NOT NULL,
"brand" TEXT,
"model" TEXT,
"created_at" TIMESTAMP(3) NOT NULL DEFAULT CURRENT_TIMESTAMP,
"bought" BOOLEAN NOT NULL DEFAULT false,
PRIMARY KEY ("id")
);
जब भी आप स्कीमा बदलते हैं तो आपको इस npx prisma migrate dev को चलाने की आवश्यकता होती है परिवर्तन लागू करने के लिए आदेश।
महान! अब हम डेटाबेस में डेटा डालने, डेटा पुनर्प्राप्त करने, डेटा हटाने .. और वह सब कुछ करने के लिए प्रिज्मा का उपयोग कर सकते हैं।
अब @prisma/client इंस्टॉल करें के साथ पैकेज
npm install @prisma/client
एक lib बनाएं फ़ोल्डर, और उसके अंदर एक prisma.js फ़ाइल। वहां, हम प्रिज्मा क्लाइंट ऑब्जेक्ट को इनिशियलाइज़ करते हैं:
import { PrismaClient } from '@prisma/client'
let global = {}
const prisma = global.prisma || new PrismaClient()
if (process.env.NODE_ENV === 'development') global.prisma = prisma
export default prisma
जब हम विकास मोड में चलते हैं, तो हॉट मॉड्यूल रीलोडिंग के कारण बार-बार रिफ्रेश होने के साथ, प्रिज्मा की अत्यधिक तात्कालिकता से बचने के लिए कोड के इस टुकड़े की आवश्यकता होती है। हम मूल रूप से prisma जोड़ रहे हैं पहली बार जब हम इसे चलाते हैं, तो एक वैश्विक चर के लिए, और अगली बार उस चर का पुन:उपयोग करते हैं।
अब आप जिस भी फाइल में प्रिज्मा का उपयोग करना चाहते हैं, उसमें आप जोड़ सकते हैं
import prisma from 'lib/prisma'और आप जाने के लिए तैयार हैं।
सभी कारों को पुनः प्राप्त करने के लिए, आप prisma.car.findMany() . का उपयोग करते हैं :
const cars = await prisma.car.findMany()
आप डेटा को फ़िल्टर करने के लिए किसी ऑब्जेक्ट को पास कर सकते हैं, उदाहरण के लिए सभी Ford . का चयन करके कारें:
const cars = await prisma.car.findMany({
where: {
brand: 'Ford',
},
})
आप किसी एक कार को उसके id . द्वारा खोज सकते हैं मान, prisma.car.findUnique() . का उपयोग करके :
const car = await prisma.car.findUnique({
where: {
id: 1,
},
})
आप prisma.car.create() . का उपयोग करके एक नई कार जोड़ सकते हैं :
const car = await prisma.car.create({
brand: 'Ford',
model: 'Fiesta',
})
आप prisma.car.delete() . का उपयोग करके कार को हटा सकते हैं :
await prisma.job.delete({
where: { id: 1 },
})
आप prisma.car.update() . का उपयोग करके कार के डेटा को अपडेट कर सकते हैं :
await prisma.job.delete({
where: { id: 1 },
data: {
bought: true
}
})आप और भी बहुत कुछ कर सकते हैं, लेकिन ये मूल बातें हैं, आरंभ करने के लिए आपको बस इतना करना है और एक साधारण सीआरयूडी एप्लिकेशन में जो आपको चाहिए उसका 95%।