अब हमारे बड़े डेटा एनालिटिक्स समुदाय ने बड़े डेटा प्रोसेसिंग के लिए अपाचे स्पार्क का पूरे जोरों पर उपयोग करना शुरू कर दिया है। प्रसंस्करण तदर्थ प्रश्नों, पूर्वनिर्मित प्रश्नों, ग्राफ प्रसंस्करण, मशीन सीखने और यहां तक कि डेटा स्ट्रीमिंग के लिए भी हो सकता है।
इसलिए समुदाय के लिए स्पार्क जॉब सबमिशन की समझ बहुत महत्वपूर्ण है। अपाचे स्पार्क जॉब सबमिशन में शामिल चरणों की सीख को आपके साथ साझा करने के लिए खुश रहें।
मूल रूप से इसके दो चरण हैं,

नौकरी जमा करना
जब RDD पर गिनती () जैसी क्रियाएं की जाती हैं, तो स्पार्क जॉब अपने आप सबमिट हो जाती है। /> अनुसूचक 2 भागों से बना है - DAG अनुसूचक और कार्य अनुसूचक।
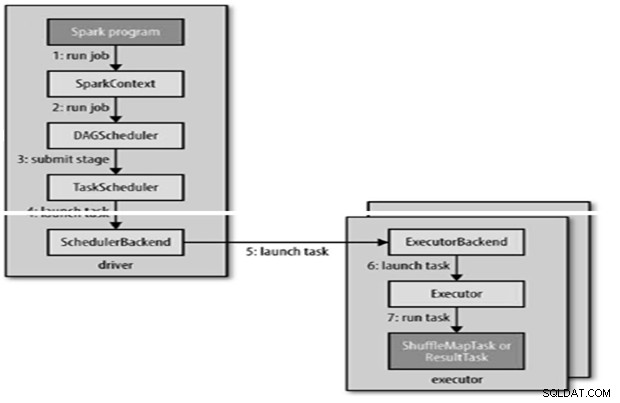
DAG निर्माण
DAG निर्माण दो प्रकार के होते हैं,

- सरल स्पार्क कार्य वह है जिसमें फेरबदल की आवश्यकता नहीं होती है और इसके लिए परिणाम कार्यों से बना केवल एक एकल चरण होता है, जैसे MapReduce में मानचित्र-केवल कार्य
- कॉम्प्लेक्स स्पार्क जॉब में ग्रुपिंग ऑपरेशंस शामिल हैं और एक या अधिक फेरबदल चरणों की आवश्यकता होती है।
- स्पार्क का DAG अनुसूचक कार्य को दो चरणों में बदल देता है।
- DAG अनुसूचक कार्य अनुसूचक को प्रस्तुत करने के लिए एक चरण को कार्यों में विभाजित करने के लिए जिम्मेदार है।
- प्रत्येक कार्य को DAG अनुसूचक द्वारा स्थान वरीयता दी जाती है ताकि कार्य अनुसूचक को डेटा स्थान का लाभ उठाने की अनुमति मिल सके।
- बाल चरण तभी सबमिट किए जाते हैं जब उनके माता-पिता सफलतापूर्वक पूरा कर लेते हैं।
कार्य निर्धारण
- कार्य अनुसूचक कार्यों का एक सेट भेजेगा; यह एक्ज़ीक्यूटर्स की अपनी सूची का उपयोग करता है जो एप्लिकेशन के लिए चल रहे हैं और एक्ज़ीक्यूटर्स के लिए कार्यों की मैपिंग का निर्माण करता है जो प्लेसमेंट प्राथमिकताओं को ध्यान में रखता है।
- कार्य अनुसूचक उन निष्पादकों को असाइन करता है जिनके पास मुक्त कोर हैं, प्रत्येक कार्य को डिफ़ॉल्ट रूप से एक कोर आवंटित किया जाता है। इसे Spark.task.cpu पैरामीटर द्वारा बदला जा सकता है।
- स्पार्क अक्का का उपयोग करता है, जो अत्यधिक स्केलेबल इवेंट-संचालित वितरित अनुप्रयोगों के निर्माण के लिए अभिनेता आधारित मंच है।
- स्पार्क दूरस्थ कॉल के लिए Hadoop RPC का उपयोग नहीं करता है।
कार्य निष्पादन
एक निष्पादक एक कार्य को निम्नानुसार चलाता है,
- यह सुनिश्चित करता है कि कार्य के लिए JAR और फ़ाइल निर्भरता अद्यतित हैं।
- कार्य कोड को डी-क्रमबद्ध करता है।
- कार्य कोड निष्पादित किया गया है।
- कार्य ड्राइवर को परिणाम लौटाता है, जो उपयोगकर्ता के पास लौटने के लिए अंतिम परिणाम में एकत्रित होता है।
संदर्भ
- द हडूप डेफिनिटिव गाइड
- एनालिटिक्स और बिग डेटा ओपन सोर्स कम्युनिटी
यह लेख मूल रूप से यहां प्रकाशित हुआ था। अनुमति के साथ पुनर्प्रकाशित। अपनी कॉपीराइट शिकायतें यहां सबमिट करें।