इस पोस्ट में "स्ट्रिंग संलग्न हैं:एक अच्छे कारण के लिए। हम SQL VARCHAR में गहराई से खोज करने जा रहे हैं, डेटा प्रकार जो स्ट्रिंग्स से संबंधित है।
साथ ही, यह "केवल आपकी आंखों के लिए" है क्योंकि स्ट्रिंग्स के बिना, कोई ब्लॉग पोस्ट, वेब पेज, गेम निर्देश, बुकमार्क किए गए व्यंजन, और हमारी आंखों को पढ़ने और आनंद लेने के लिए और भी बहुत कुछ नहीं होगा। हम हर दिन एक गजियन स्ट्रिंग्स से निपटते हैं। इसलिए, डेवलपर के रूप में, आप और मैं इस प्रकार के डेटा को स्टोर और एक्सेस करने के लिए कुशल बनाने के लिए जिम्मेदार हैं।
इसे ध्यान में रखते हुए, हम भंडारण और प्रदर्शन के लिए सबसे महत्वपूर्ण चीजों को कवर करेंगे। इस डेटा प्रकार के लिए क्या करें और क्या न करें दर्ज करें।
लेकिन इससे पहले, VARCHAR SQL में केवल एक स्ट्रिंग प्रकार है। क्या इसे अलग बनाता है?
SQL में VARCHAR क्या है? (उदाहरण के साथ)
VARCHAR अलग-अलग आकार का एक स्ट्रिंग या वर्ण डेटा प्रकार है। आप इसके साथ अक्षरों, संख्याओं और प्रतीकों को स्टोर कर सकते हैं। SQL सर्वर 2019 से शुरू करते हुए, आप UTF-8 समर्थन के साथ संयोजन का उपयोग करते समय यूनिकोड वर्णों की पूरी श्रृंखला का उपयोग कर सकते हैं।
आप VARCHAR[(n)] का उपयोग करके VARCHAR कॉलम या वेरिएबल घोषित कर सकते हैं, जहां n बाइट्स में स्ट्रिंग आकार के लिए खड़ा है। n . के लिए मानों की श्रेणी 1 से 8000 है। यह बहुत अधिक वर्ण डेटा है। लेकिन इससे भी अधिक, यदि आपको 2GB तक की विशाल स्ट्रिंग की आवश्यकता है, तो आप इसे VARCHAR(MAX) का उपयोग करके घोषित कर सकते हैं। आपकी डायरी में रहस्यों और निजी चीजों की सूची के लिए यह काफी बड़ा है! हालांकि, ध्यान दें कि आप इसे बिना आकार के भी घोषित कर सकते हैं और यदि आप ऐसा करते हैं तो यह डिफ़ॉल्ट रूप से 1 हो जाता है।
आइए एक उदाहरण लेते हैं।
DECLARE @actor VARCHAR(20) = 'Robert Downey Jr.';
DECLARE @movieCharacter VARCHAR(10) = 'Iron Man';
DECLARE @movie VARCHAR = 'Avengers';
SELECT @actor, @movieCharacter, @movie
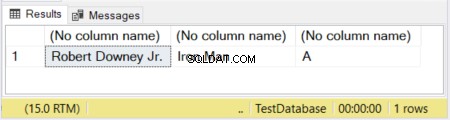
चित्र 1 में, पहले 2 स्तंभों के आकार परिभाषित हैं। तीसरा स्तंभ बिना आकार के छोड़ दिया गया है। इसलिए, "एवेंजर्स" शब्द को छोटा कर दिया गया है क्योंकि एक VARCHAR बिना आकार के 1 वर्ण के लिए डिफ़ॉल्ट घोषित किया गया है।
अब, कुछ बड़ा करने की कोशिश करते हैं। लेकिन ध्यान दें कि इस क्वेरी को चलने में थोड़ा समय लगेगा - मेरे लैपटॉप पर 23 सेकंड।
-- This will take a while
DECLARE @giganticString VARCHAR(MAX);
SET @giganticString = REPLICATE(CAST('kage bunshin no jutsu' AS VARCHAR(MAX)),100000000)
SELECT DATALENGTH(@giganticString)
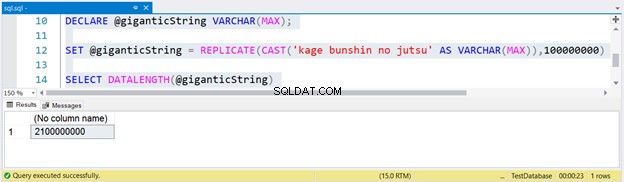
एक विशाल स्ट्रिंग उत्पन्न करने के लिए, हमने केज बंशिन नो जुत्सु को 100 मिलियन बार दोहराया। REPLICATE में CAST नोट करें। यदि आप स्ट्रिंग एक्सप्रेशन को VARCHAR(MAX) पर कास्ट नहीं करते हैं, तो परिणाम केवल 8000 वर्णों तक ही छोटा किया जाएगा।
लेकिन SQL VARCHAR अन्य स्ट्रिंग डेटा प्रकारों की तुलना कैसे करता है?
SQL में CHAR और VARCHAR के बीच अंतर
VARCHAR की तुलना में, CHAR एक निश्चित-लंबाई वाला वर्ण डेटा प्रकार है। कोई फर्क नहीं पड़ता कि आप CHAR चर में कितना छोटा या बड़ा मान रखते हैं, अंतिम आकार चर का आकार है। नीचे दी गई तुलनाओं की जाँच करें।
DECLARE @tvSeriesTitle1 VARCHAR(20) = 'The Mandalorian';
DECLARE @tvSeriesTitle2 CHAR(20) = 'The Mandalorian';
SELECT DATALENGTH(@tvSeriesTitle1) AS VarcharValue,
DATALENGTH(@tvSeriesTitle2) AS CharValue
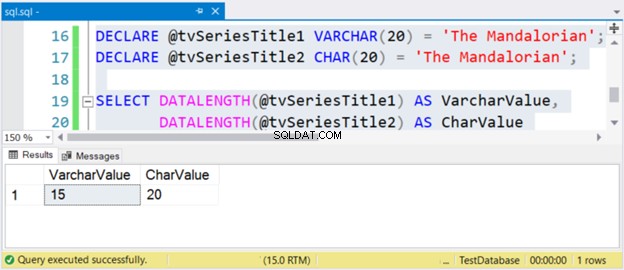
स्ट्रिंग "द मंडलोरियन" का आकार 15 वर्ण है। तो, VarcharValue कॉलम इसे सही ढंग से दर्शाता है। हालांकि, चारवैल्यू 20 के आकार को बरकरार रखता है - यह दाईं ओर 5 रिक्त स्थान के साथ गद्देदार है।
SQL VARCHAR बनाम NVARCHAR
इन डेटा प्रकारों की तुलना करते समय दो बुनियादी बातें ध्यान में आती हैं।
सबसे पहले, यह बाइट्स में आकार है। NVARCHAR में प्रत्येक वर्ण का आकार VARCHAR से दोगुना है। NVARCHAR(n) केवल 1 से 4000 तक है।
फिर, वह पात्रों को संग्रहीत कर सकता है। NVARCHAR कोरियाई, जापानी, अरबी आदि जैसे बहुभाषी वर्णों को संग्रहीत कर सकता है। यदि आप अपने डेटाबेस में कोरियाई के-पॉप गीत संग्रहीत करने की योजना बना रहे हैं, तो यह डेटा प्रकार आपके विकल्पों में से एक है।
आइए एक उदाहरण लेते हैं। हम अंग्रेजी में के-पॉप समूह 세븐틴 या सत्रह का उपयोग करने जा रहे हैं।
DECLARE @kpopGroupKorean NVARCHAR(5) = N'세븐틴';
SELECT @kpopGroupKorean AS KPopGroup,
DATALENGTH(@kpopGroupKorean) AS SizeInBytes,
LEN(@kpopGroupKorean) AS [NoOfChars]
उपरोक्त कोड स्ट्रिंग मान, बाइट्स में इसका आकार और वर्णों की संख्या को आउटपुट करेगा। यदि ये गैर-यूनिकोड वर्ण हैं, तो वर्णों की संख्या बाइट्स में आकार के बराबर है। पर ये स्थिति नहीं है। नीचे चित्र 4 देखें।
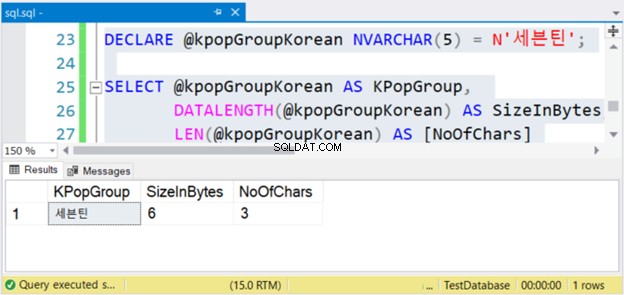
देखो? यदि NVARCHAR में 3 वर्ण हैं, तो बाइट्स में आकार दोगुना है। लेकिन वचर के साथ नहीं। यदि आप अंग्रेज़ी वर्णों का उपयोग करते हैं तो भी यही बात लागू होती है।
लेकिन एनसीएचएआर के बारे में कैसे? NCHAR यूनिकोड वर्णों के लिए CHAR का प्रतिरूप है।
SQL सर्वर VARCHAR UTF-8 समर्थन के साथ
UTF-8 समर्थन के साथ VARCHAR एक सर्वर स्तर, डेटाबेस स्तर, या तालिका स्तंभ स्तर पर कॉलेशन जानकारी को बदलकर संभव है। उपयोग किए जाने वाले संयोजन को UTF-8 का समर्थन करना चाहिए।
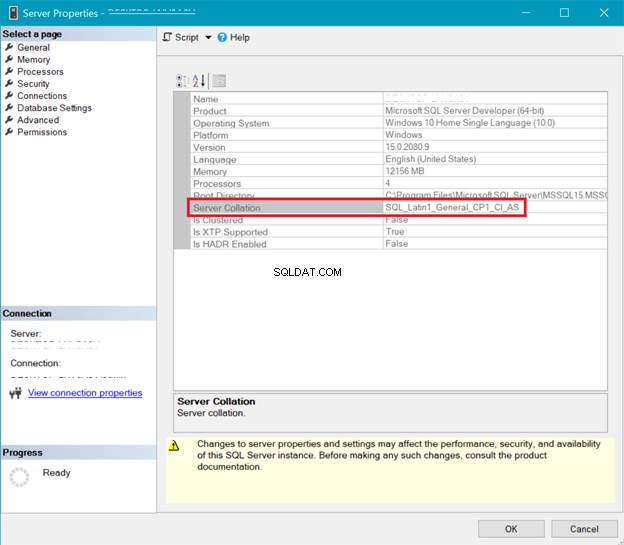
SQL सर्वर कॉलेशन
चित्रा 5 SQL सर्वर प्रबंधन स्टूडियो में विंडो प्रस्तुत करता है जो सर्वर संयोजन दिखाता है।
डेटाबेस संयोजन
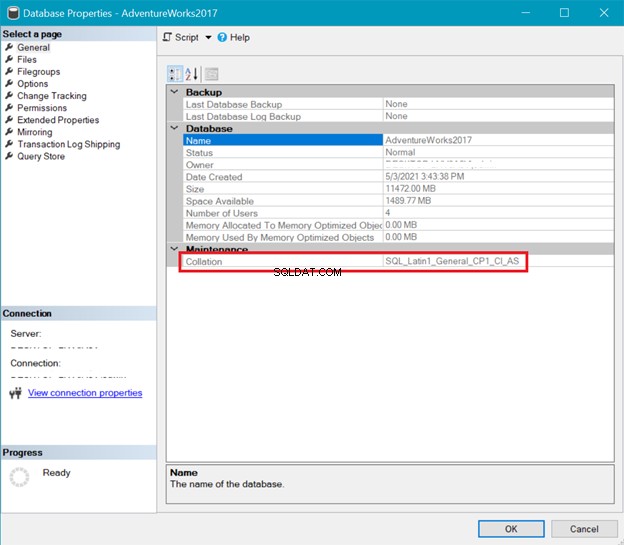
इस बीच, चित्र 6 AdventureWorks . के संयोजन को दर्शाता है डेटाबेस।
टेबल कॉलम कोलेशन
ऊपर दिए गए सर्वर और डेटाबेस कोलाज दोनों से पता चलता है कि UTF-8 समर्थित नहीं है। UTF-8 समर्थन के लिए संयोजन स्ट्रिंग में _UTF8 होना चाहिए। लेकिन आप अभी भी तालिका के स्तंभ स्तर पर UTF-8 समर्थन का उपयोग कर सकते हैं। उदाहरण देखें।
CREATE TABLE SeventeenMemberList
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
KoreanName VARCHAR(20) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL,
EnglishName VARCHAR(20) NOT NULL
)
उपरोक्त कोड में Latin1_General_100_BIN2_UTF8 . है कोरियाई नाम . के लिए मिलान कॉलम। हालांकि VARCHAR और NVARCHAR नहीं, यह कॉलम कोरियाई भाषा के वर्णों को स्वीकार करेगा। आइए कुछ रिकॉर्ड डालें और फिर उन्हें देखें।
INSERT INTO SeventeenMemberList
(KoreanName, EnglishName)
VALUES
(N'에스쿱스','S.Coups')
,(N'원우','Wonwoo')
,(N'민규','Mingyu')
,(N'버논','Vernon')
,(N'우지','Woozi')
,(N'정한','Jeonghan')
,(N'조슈아','Joshua')
,(N'도겸','DK')
,(N'승관','Seungkwan')
,(N'호시','Hoshi')
,(N'준','Jun')
,(N'디에잇','The8')
,(N'디노','Dino')
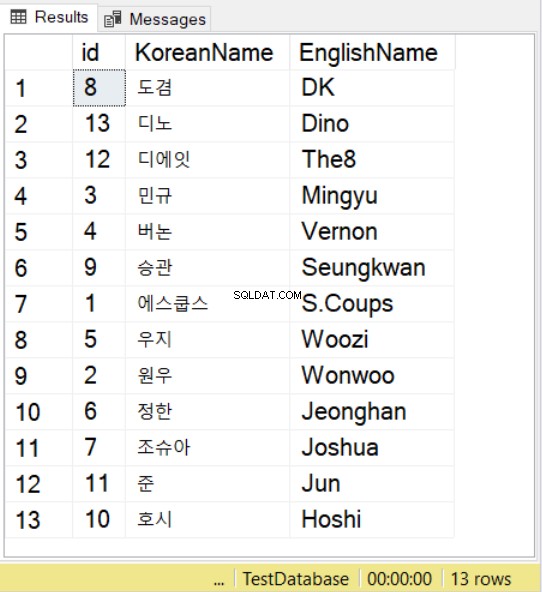
SELECT * FROM SeventeenMemberList
ORDER BY KoreanName
COLLATE Latin1_General_100_BIN2_UTF8
हम कोरियाई और अंग्रेजी समकक्षों का उपयोग करके सत्रह के-पॉप समूह के नामों का उपयोग कर रहे हैं। कोरियाई वर्णों के लिए, ध्यान दें कि आपको अभी भी N . के साथ मान उपसर्ग करना होगा , ठीक वैसे ही जैसे आप NVARCHAR मानों के साथ करते हैं।
फिर, ORDER BY के साथ SELECT का उपयोग करते समय, आप संयोजन का भी उपयोग कर सकते हैं। आप इसे ऊपर के उदाहरण में देख सकते हैं। यह निर्दिष्ट संयोजन के लिए छँटाई नियमों का पालन करेगा।
UTF-8 सपोर्ट के साथ VARCHAR का स्टोरेज
लेकिन इन पात्रों का भंडारण कैसा है? यदि आप प्रति चरित्र 2 बाइट्स की अपेक्षा करते हैं तो आप आश्चर्य में हैं। चित्र 8 देखें।
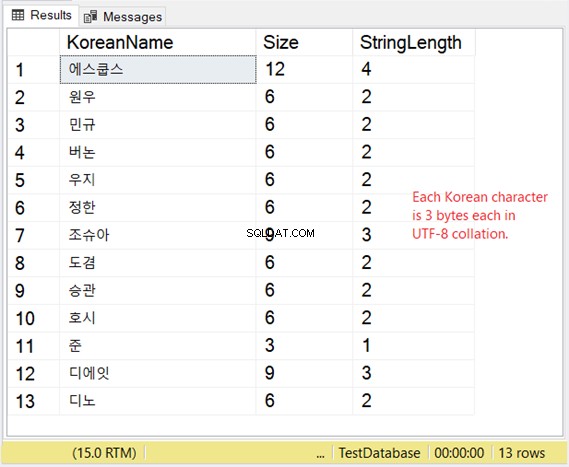
इसलिए, यदि संग्रहण आपके लिए बहुत मायने रखता है, तो UTF-8 समर्थन के साथ VARCHAR का उपयोग करते समय नीचे दी गई तालिका पर विचार करें।
| अक्षर | बाइट्स में आकार |
| असीसी 0 - 127 | 1 |
| लैटिन-आधारित लिपि, और ग्रीक, सिरिलिक, कॉप्टिक, अर्मेनियाई, हिब्रू, अरबी, सिरिएक, टाना और एन'को | 2 |
| चीनी, कोरियाई और जापानी जैसी पूर्वी एशियाई लिपि | 3 |
| 010000–10FFFF की सीमा में वर्ण | 4 |
हमारा कोरियाई उदाहरण एक पूर्वी एशियाई लिपि है, इसलिए यह प्रति वर्ण 3 बाइट्स है।
अब जबकि हमने VARCHAR का वर्णन और तुलना अन्य स्ट्रिंग प्रकारों से कर लिया है, आइए अब क्या करें और क्या न करें के बारे में बात करते हैं
SQL सर्वर में VARCHAR का उपयोग करने में क्या करें
1. आकार निर्दिष्ट करें
आकार निर्दिष्ट किए बिना क्या गलत हो सकता है?
STRING TRUNCATION
यदि आप आकार निर्दिष्ट करने में आलसी हो जाते हैं, तो स्ट्रिंग काट-छांट हो जाएगी। इसका एक उदाहरण आप पहले ही देख चुके हैं।
भंडारण और प्रदर्शन प्रभाव
एक और विचार भंडारण और प्रदर्शन है। आपको केवल अपने डेटा के लिए सही आकार सेट करने की आवश्यकता है, अधिक नहीं। लेकिन तुम कैसे जान सकते थे? भविष्य में काट-छांट से बचने के लिए, आप इसे केवल सबसे बड़े आकार पर सेट कर सकते हैं। वह है VARCHAR(8000) या यहां तक कि VARCHAR(MAX)। और 2 बाइट यथावत संग्रहीत किए जाएंगे। 2GB के साथ वही बात। क्या इससे कोई फर्क पड़ता है?
इसका उत्तर देना हमें इस अवधारणा पर ले जाएगा कि SQL सर्वर डेटा कैसे संग्रहीत करता है। मेरे पास उदाहरणों और दृष्टांतों के साथ इसे विस्तार से समझाते हुए एक और लेख है।
संक्षेप में, डेटा 8KB-पृष्ठों में संग्रहीत किया जाता है। जब डेटा की एक पंक्ति इस आकार से अधिक हो जाती है, तो SQL सर्वर इसे ROW_OVERFLOW_DATA नामक किसी अन्य पृष्ठ आवंटन इकाई में ले जाता है।
मान लें कि आपके पास 2-बाइट VARCHAR डेटा है जो मूल पृष्ठ आवंटन इकाई में फिट हो सकता है। जब आप 8000 बाइट्स से बड़ी स्ट्रिंग संग्रहीत करते हैं, तो डेटा को पंक्ति-ओवरफ़्लो पृष्ठ पर ले जाया जाएगा। फिर इसे फिर से कम आकार में सिकोड़ें, और इसे वापस मूल पृष्ठ पर ले जाया जाएगा। आगे-पीछे की गति बहुत सारे I/O और एक प्रदर्शन अड़चन का कारण बनती है। इसे 1 के बजाय 2 पृष्ठों से पुनर्प्राप्त करने के लिए अतिरिक्त I/O की भी आवश्यकता है।
एक अन्य कारण अनुक्रमण है। इंडेक्स कुंजी के रूप में VARCHAR (MAX) एक बड़ा NO है। इस बीच, VARCHAR(8000) अधिकतम सूचकांक कुंजी आकार से अधिक हो जाएगा। यानी नॉन-क्लस्टर इंडेक्स के लिए 1700 बाइट्स और क्लस्टर्ड इंडेक्स के लिए 900 बाइट्स।
डेटा रूपांतरण प्रभाव
फिर भी एक और विचार है:डेटा रूपांतरण। इसे नीचे दिए गए कोड जैसे आकार के बिना CAST के साथ आज़माएं।
SELECT
SYSDATETIMEOFFSET() AS DateTimeInput
,CAST(SYSDATETIMEOFFSET() AS VARCHAR) AS ConvertedDateTime
,DATALENGTH(CAST(SYSDATETIMEOFFSET() AS VARCHAR)) AS ConvertedLength
यह कोड किसी दिनांक/समय को समय क्षेत्र की जानकारी के साथ VARCHAR में परिवर्तित करेगा।
इसलिए, यदि हम CAST या CONVERT के दौरान आकार निर्दिष्ट करने में आलसी हो जाते हैं, तो परिणाम केवल 30 वर्णों तक सीमित होता है।
UTF-8 समर्थन के साथ NVARCHAR को VARCHAR में बदलने के बारे में कैसे? इसकी विस्तृत व्याख्या बाद में होगी, इसलिए पढ़ते रहें।
2. VARCHAR का उपयोग करें यदि स्ट्रिंग का आकार काफी भिन्न होता है
AdventureWorks . से नाम डेटाबेस आकार में भिन्न होता है। सबसे छोटे नामों में से एक मिन सु है, जबकि सबसे लंबा नाम ओसारुमवेन्स उवाइफियोकुन एग्बोनिल है। यह रिक्त स्थान सहित 6 और 31 वर्णों के बीच है। आइए इन नामों को 2 तालिकाओं में आयात करें और VARCHAR और CHAR के बीच तुलना करें।
-- Table using VARCHAR
CREATE TABLE VarcharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
varcharName VARCHAR(50) NOT NULL
)
GO
CREATE INDEX IX_VarcharAsIndexKey_varcharName ON VarcharAsIndexKey(varcharName)
GO
-- Table using CHAR
CREATE TABLE CharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
charName CHAR(50) NOT NULL
)
GO
CREATE INDEX IX_CharAsIndexKey_charName ON CharAsIndexKey(charName)
GO
INSERT INTO VarcharAsIndexKey (varcharName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
INSERT INTO CharAsIndexKey (charName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
GO
2 में से कौन बेहतर है? आइए नीचे दिए गए कोड का उपयोग करके और सांख्यिकी IO के आउटपुट का निरीक्षण करके तार्किक पठन की जाँच करें।
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT id, varcharName
FROM VarcharAsIndexKey
SELECT id, charName
FROM CharAsIndexKey
SET STATISTICS IO OFF
तार्किक पढ़ता है:
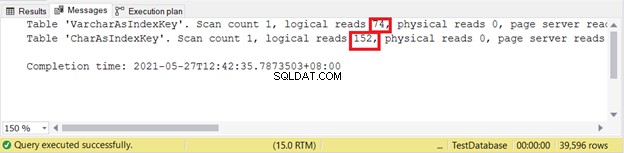
कम तार्किक बेहतर पढ़ता है। यहां, CHAR कॉलम ने VARCHAR समकक्ष के दोगुने से अधिक का उपयोग किया। इस प्रकार, इस उदाहरण में VARCHAR जीत गया।
3. जब मान आकार में भिन्न हों तब VARCHAR को CHAR के बजाय अनुक्रमणिका कुंजी के रूप में उपयोग करें
क्या हुआ जब अनुक्रमणिका कुंजियों के रूप में उपयोग किया गया? क्या VARCHAR से CHAR का किराया बेहतर होगा? आइए पिछले अनुभाग के समान डेटा का उपयोग करें और इस प्रश्न का उत्तर दें।
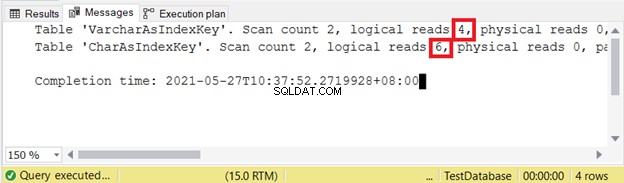
हम कुछ डेटा को क्वेरी करेंगे और लॉजिकल रीड्स की जांच करेंगे। इस उदाहरण में, फ़िल्टर अनुक्रमणिका कुंजी का उपयोग करता है।
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT varcharName FROM VarcharAsIndexKey
WHERE varcharName = 'Sai, Adriana A'
OR varcharName = 'Rogers, Caitlin D'
SELECT charName FROM CharAsIndexKey
WHERE charName = 'Sai, Adriana A'
OR charName = 'Rogers, Caitlin D'
SET STATISTICS IO OFF
तार्किक पढ़ता है:
इसलिए, जब कुंजी के अलग-अलग आकार होते हैं, तो VARCHAR अनुक्रमणिका कुंजियाँ CHAR अनुक्रमणिका कुंजियों से बेहतर होती हैं। लेकिन INSERT और UPDATE के बारे में क्या है जो अनुक्रमणिका प्रविष्टियों को बदल देगा?
इन्सर्ट और अपडेट का उपयोग करते समय
आइए 2 मामलों का परीक्षण करें और फिर तार्किक पठन की जांच करें जैसे हम आमतौर पर करते हैं।
SET STATISTICS IO ON
INSERT INTO VarcharAsIndexKey (varcharName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
INSERT INTO CharAsIndexKey (charName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
SET STATISTICS IO OFF
तार्किक पढ़ता है:
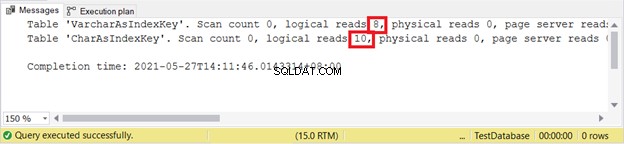
रिकॉर्ड डालने पर VARCHAR अभी भी बेहतर है। अद्यतन के बारे में कैसे?
SET STATISTICS IO ON
UPDATE VarcharAsIndexKey
SET varcharName = 'Hulk'
WHERE varcharName = 'Ruffalo, Mark'
UPDATE CharAsIndexKey
SET charName = 'Hulk'
WHERE charName = 'Ruffalo, Mark'
SET STATISTICS IO OFF
तार्किक पढ़ता है:
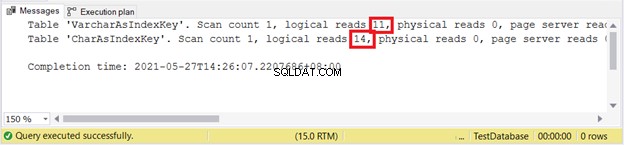
लगता है VARCHAR फिर से जीत गया।
आखिरकार, यह हमारी परीक्षा जीतता है, हालांकि यह छोटा हो सकता है। क्या आपके पास एक बड़ा परीक्षण मामला है जो इसके विपरीत साबित होता है?
4. बहुभाषी डेटा के लिए UTF-8 समर्थन के साथ VARCHAR पर विचार करें (SQL सर्वर 2019+)
यदि आपकी तालिका में यूनिकोड और गैर-यूनिकोड वर्णों का मिश्रण है, तो आप NVARCHAR पर UTF-8 समर्थन के साथ VARCHAR पर विचार कर सकते हैं। यदि अधिकांश वर्ण ASCII 0 से 127 की सीमा के भीतर हैं, तो यह NVARCHAR की तुलना में स्थान की बचत प्रदान कर सकता है।
यह देखने के लिए कि मेरा क्या मतलब है, आइए तुलना करें।
NVARCHAR से VARCHAR UTF-8 समर्थन के साथ
क्या आपने पहले ही अपने डेटाबेस को SQL Server 2019 में माइग्रेट कर लिया है? क्या आप अपने स्ट्रिंग डेटा को यूटीएफ -8 संयोजन में माइग्रेट करने की योजना बना रहे हैं? आपको एक विचार देने के लिए हमारे पास जापानी और गैर-जापानी वर्णों के मिश्रित मूल्य का एक उदाहरण होगा।
CREATE TABLE NVarcharToVarcharUTF8
(
NVarcharValue NVARCHAR(20) NOT NULL,
VarcharUTF8 VARCHAR(45) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL
)
GO
INSERT INTO NVarcharToVarcharUTF8
(NVarcharValue, VarcharUTF8)
VALUES
(N'NARUTO-ナルト- 疾風伝',N'NARUTO-ナルト- 疾風伝'); -- NARUTO Shippûden
SELECT
NVarcharValue
,LEN(NVarcharValue) AS nvarcharNoOfChars
,DATALENGTH(NVarcharValue) AS nvarcharSizeInBytes
,VarcharUTF8
,LEN(VarcharUTF8) AS varcharNoOfChars
,DATALENGTH(VarcharUTF8) AS varcharSizeInBytes
FROM NVarcharToVarcharUTF8
अब जब डेटा सेट हो गया है, हम 2 मानों के बाइट्स में आकार का निरीक्षण करेंगे:

हैरत में डालना! NVARCHAR के साथ, आकार 30 बाइट्स है। यह 2 वर्णों से 15 गुना अधिक है। लेकिन जब UTF-8 समर्थन के साथ VARCHAR में कनवर्ट किया जाता है, तो आकार केवल 27 बाइट्स होता है। 27 क्यों? जांचें कि इसकी गणना कैसे की जाती है।

इस प्रकार, 9 वर्ण प्रत्येक 1 बाइट हैं। यह दिलचस्प है क्योंकि, NVARCHAR के साथ, अंग्रेजी अक्षर भी 2 बाइट्स हैं। शेष जापानी वर्ण प्रत्येक में 3 बाइट हैं।
यदि यह सभी जापानी वर्ण हैं, तो 15-वर्ण वाली स्ट्रिंग 45 बाइट्स होगी और VarcharUTF8 के अधिकतम आकार का भी उपभोग करेगी। कॉलम। ध्यान दें कि NVarcharValue . का आकार कॉलम VarcharUTF8 . से छोटा है ।
NVARCHAR से कनवर्ट करते समय आकार समान नहीं हो सकते हैं, या डेटा फिट नहीं हो सकता है। आप पिछली तालिका 1 का संदर्भ ले सकते हैं।
UTF-8 समर्थन के साथ NVARCHAR को VARCHAR में कनवर्ट करते समय आकार पर प्रभाव पर विचार करें।
SQL सर्वर में VARCHAR का उपयोग करने में क्या नहीं है
1. जब स्ट्रिंग का आकार निश्चित और अशक्त हो, तो इसके बजाय CHAR का उपयोग करें।
अंगूठे का सामान्य नियम जब एक निश्चित आकार के तार की आवश्यकता होती है तो CHAR का उपयोग करना होता है। मैं इसका पालन करता हूं जब मेरे पास डेटा आवश्यकता होती है जिसके लिए दाएं-गद्देदार रिक्त स्थान की आवश्यकता होती है। अन्यथा, मैं वचर का उपयोग करूंगा। मेरे पास कुछ उपयोग के मामले थे जब मुझे क्लाइंट के लिए टेक्स्ट फ़ाइल में डिलीमीटर के बिना फिक्स्ड-लम्बाई स्ट्रिंग्स को डंप करने की आवश्यकता होती थी।
इसके अलावा, मैं CHAR कॉलम का उपयोग केवल तभी करता हूं जब कॉलम अशक्त होंगे। क्यों? क्योंकि CHAR कॉलम के बाइट्स में आकार जब NULL कॉलम के परिभाषित आकार के बराबर होता है। फिर भी VARCHAR जब NULL का आकार 1 होता है चाहे कितना भी परिभाषित आकार हो। नीचे दिए गए कोड को चलाएँ और इसे स्वयं देखें।
DECLARE @charValue CHAR(50) = NULL;
DECLARE @varcharValue VARCHAR(1000) = NULL;
SELECT
DATALENGTH(ISNULL(@charvalue,0)) AS CharSize
,DATALENGTH(ISNULL(@varcharvalue,0)) AS VarcharSize
2. VARCHAR(n) का उपयोग न करें यदि n 8000 बाइट्स से अधिक होगा। इसके बजाय VARCHAR(MAX) का उपयोग करें।
क्या आपके पास एक स्ट्रिंग है जो 8000 बाइट्स से अधिक होगी? यह वचर (मैक्स) का उपयोग करने का समय है। लेकिन नाम और पते जैसे डेटा के सबसे सामान्य रूपों के लिए, VARCHAR(MAX) अधिक है और प्रदर्शन को प्रभावित करेगा। मेरे व्यक्तिगत अनुभव में, मुझे एक आवश्यकता याद नहीं है कि मैंने VARCHAR(MAX) का उपयोग किया था।
3. SQL सर्वर 2017 और नीचे के साथ बहुभाषी वर्णों का उपयोग करते समय। इसके बजाय NVARCHAR का उपयोग करें।
यदि आप अभी भी SQL सर्वर 2017 और उससे नीचे का उपयोग करते हैं तो यह एक स्पष्ट विकल्प है।
द बॉटमलाइन
VARCHAR डेटा प्रकार ने इतने सारे पहलुओं के लिए हमारी अच्छी सेवा की है। यह मेरे लिए SQL सर्वर 7 के बाद से किया। फिर भी कभी-कभी, हम अभी भी खराब विकल्प बनाते हैं। इस पोस्ट में, SQL VARCHAR को परिभाषित किया गया है और उदाहरणों के साथ अन्य स्ट्रिंग डेटा प्रकारों की तुलना में। और फिर, तेज़ डेटाबेस के लिए क्या करें और क्या न करें ये हैं:
क्या करें:
- आकार निर्दिष्ट करें n में VARCHAR[(n)] भले ही यह वैकल्पिक हो।
- इसका उपयोग तब करें जब स्ट्रिंग का आकार काफी भिन्न हो।
- VARCHAR कॉलम को CHAR के बजाय इंडेक्स कुंजियों के रूप में मानें।
- और यदि आप अब SQL सर्वर 2019 का उपयोग कर रहे हैं, तो UTF-8 समर्थन के साथ बहुभाषी स्ट्रिंग के लिए VARCHAR पर विचार करें।
क्या न करें:
- जब स्ट्रिंग का आकार निश्चित हो और अशक्त हो तो VARCHAR का उपयोग न करें।
- VARCHAR(n) का उपयोग न करें जब स्ट्रिंग का आकार 8000 बाइट्स से अधिक हो।
- और SQL Server 2017 और इससे पहले के संस्करण का उपयोग करते समय बहुभाषी डेटा के लिए VARCHAR का उपयोग न करें।
क्या आपके पास जोड़ने के लिए कुछ और है? चलो टिप्पड़ियों के अनुभाग से पता करते हैं। अगर आपको लगता है कि इससे आपके डेवलपर मित्रों को मदद मिलेगी, तो कृपया इसे अपने पसंदीदा सोशल मीडिया प्लेटफॉर्म पर साझा करें।