प्रत्येक भारी लोड वाले डेटाबेस में प्रश्नों को कैश किया जाना है, डेटाबेस के लिए उचित प्रदर्शन के साथ सभी ट्रैफ़िक को संभालने का कोई तरीका नहीं है। ऐसे कई तंत्र हैं जिनमें एक क्वेरी कैश लागू किया जा सकता है। MySQL क्वेरी कैश से शुरू, जो ज्यादातर रीड-ओनली, कम समवर्ती वर्कलोड के लिए ठीक काम करता था और जिसका उच्च समवर्ती वर्कलोड में कोई स्थान नहीं है (इस हद तक कि Oracle ने इसे MySQL 8.0 में हटा दिया), बाहरी की-वैल्यू स्टोर्स के लिए जैसे Redis, memcached या CouchBase।
बाहरी समर्पित डेटा स्टोर का उपयोग करने में मुख्य समस्या (जैसा कि हम किसी को भी MySQL क्वेरी कैश का उपयोग करने की अनुशंसा नहीं करेंगे) यह है कि यह अभी तक प्रबंधित करने के लिए एक और डेटास्टोर है। यह अभी तक बनाए रखने के लिए एक और वातावरण है, मुद्दों को संभालने के लिए स्केलिंग, डीबग करने के लिए बग इत्यादि।
तो क्यों न अपने प्रॉक्सी का लाभ उठाकर दो पक्षियों को एक पत्थर से मार दिया जाए? यहां धारणा यह है कि आप अपने उत्पादन वातावरण में एक प्रॉक्सी का उपयोग कर रहे हैं, क्योंकि यह उदाहरणों में संतुलन प्रश्नों को लोड करने में मदद करता है, और अनुप्रयोगों के लिए एक सरल समापन बिंदु प्रदान करके अंतर्निहित डेटाबेस टोपोलॉजी को मास्क करता है। ProxySQL नौकरी के लिए एक बेहतरीन टूल है, क्योंकि यह अतिरिक्त रूप से कैशिंग लेयर के रूप में कार्य कर सकता है। इस ब्लॉग पोस्ट में, हम आपको दिखाएंगे कि कैसे ClusterControl का उपयोग करके ProxySQL में क्वेरी को कैश किया जाए।
प्रॉक्सीएसक्यूएल में क्वेरी कैश कैसे काम करता है?
सबसे पहले, पृष्ठभूमि का एक सा। ProxySQL क्वेरी नियमों के माध्यम से ट्रैफ़िक का प्रबंधन करता है और यह उसी तंत्र का उपयोग करके क्वेरी कैशिंग को पूरा कर सकता है। ProxySQL कैश्ड क्वेरीज़ को मेमोरी स्ट्रक्चर में स्टोर करता है। कैश्ड डेटा को टाइम-टू-लाइव (TTL) सेटिंग का उपयोग करके बेदखल किया जाता है। टीटीएल को प्रत्येक क्वेरी नियम के लिए व्यक्तिगत रूप से परिभाषित किया जा सकता है, इसलिए यह तय करना उपयोगकर्ता पर निर्भर है कि क्या प्रत्येक व्यक्तिगत क्वेरी के लिए अलग-अलग टीटीएल के साथ क्वेरी नियमों को परिभाषित किया जाना है या यदि उसे केवल कुछ नियम बनाने की आवश्यकता है जो बहुमत से मेल खाएंगे यातायात।
दो कॉन्फ़िगरेशन सेटिंग्स हैं जो परिभाषित करती हैं कि क्वेरी कैश का उपयोग कैसे किया जाना चाहिए। सबसे पहले, mysql-query_cache_size_MB जो क्वेरी कैश आकार पर एक नरम सीमा को परिभाषित करता है। यह एक कठिन सीमा नहीं है इसलिए ProxySQL इससे थोड़ी अधिक मेमोरी का उपयोग कर सकता है, लेकिन यह मेमोरी उपयोग को नियंत्रण में रखने के लिए पर्याप्त है। दूसरी सेटिंग जिसे आप बदल सकते हैं वह है mysql-query_cache_stores_empty_result . यह परिभाषित करता है कि एक खाली परिणाम सेट कैश किया गया है या नहीं।
ProxySQL क्वेरी कैश को की-वैल्यू स्टोर के रूप में डिज़ाइन किया गया है। मान एक क्वेरी का परिणाम सेट है और कुंजी को संयोजित मानों से बनाया गया है जैसे:उपयोगकर्ता, स्कीमा और क्वेरी टेक्स्ट। फिर उस स्ट्रिंग से एक हैश बनाया जाता है और उस हैश को कुंजी के रूप में प्रयोग किया जाता है।
ClusterControl का उपयोग करके ProxySQL को क्वेरी कैश के रूप में सेट करना
प्रारंभिक सेटअप के रूप में, हमारे पास एक मास्टर और एक दास का प्रतिकृति क्लस्टर है। हमारे पास एक ही ProxySQL भी है।
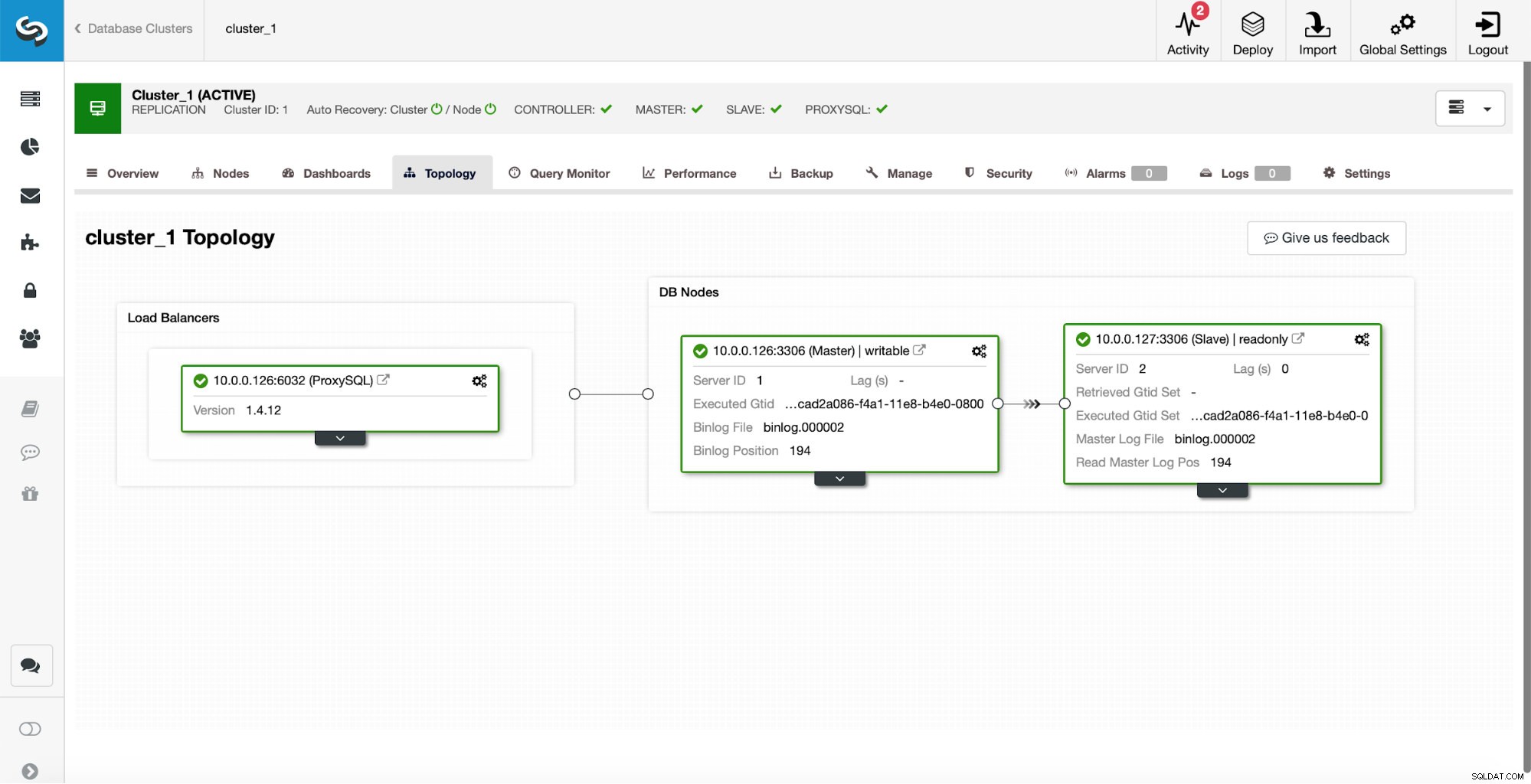
यह किसी भी तरह से उत्पादन-ग्रेड सेटअप नहीं है क्योंकि हमें प्रॉक्सी परत के लिए किसी प्रकार की उच्च उपलब्धता को लागू करना होगा (उदाहरण के लिए एक से अधिक प्रॉक्सीएसक्यूएल इंस्टेंस को तैनात करके, और फिर वर्चुअल आईपी फ़्लोटिंग के लिए उनके ऊपर रखा गया), लेकिन यह हमारे परीक्षणों के लिए पर्याप्त से अधिक होगा।
सबसे पहले, हम यह सुनिश्चित करने के लिए ProxySQL कॉन्फ़िगरेशन को सत्यापित करने जा रहे हैं कि क्वेरी कैश सेटिंग्स वही हैं जो हम चाहते हैं।
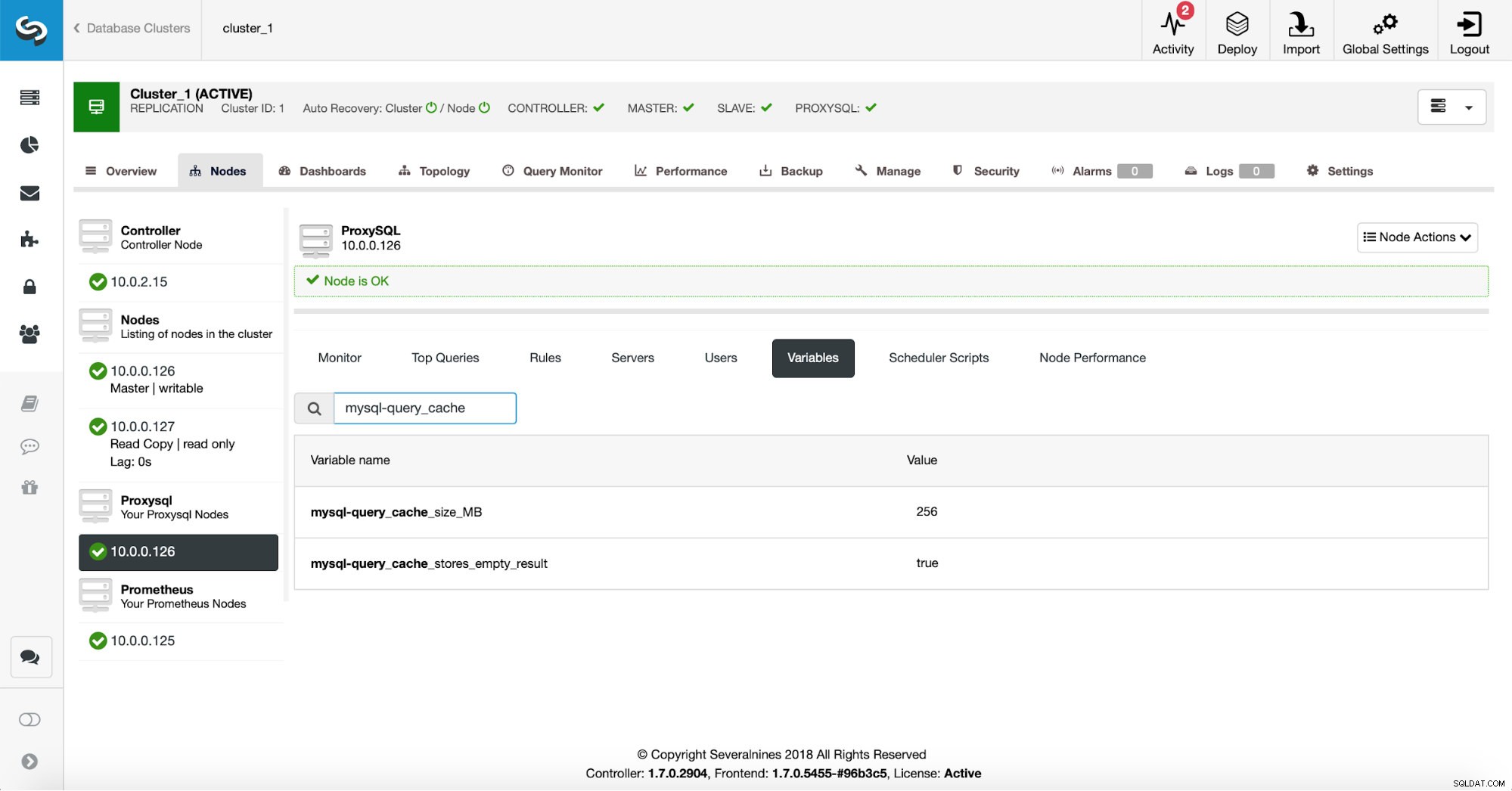
256 एमबी का क्वेरी कैश लगभग सही होना चाहिए और हम खाली परिणाम सेट को भी कैश करना चाहते हैं - कभी-कभी एक क्वेरी जो कोई डेटा नहीं लौटाती है, यह सत्यापित करने के लिए अभी भी बहुत काम करना पड़ता है कि वापस करने के लिए कुछ भी नहीं है।
अगला कदम क्वेरी नियम बनाना है जो उन प्रश्नों से मेल खाएगा जिन्हें आप कैश करना चाहते हैं। ClusterControl में ऐसा करने के दो तरीके हैं।
मैन्युअल रूप से क्वेरी नियम जोड़ना
पहले तरीके के लिए थोड़ी अधिक मैन्युअल क्रियाओं की आवश्यकता होती है। ClusterControl का उपयोग करके आप आसानी से कोई भी क्वेरी नियम बना सकते हैं, जिसमें कैशिंग करने वाले क्वेरी नियम भी शामिल हैं। सबसे पहले, नियमों की सूची पर एक नजर डालते हैं:
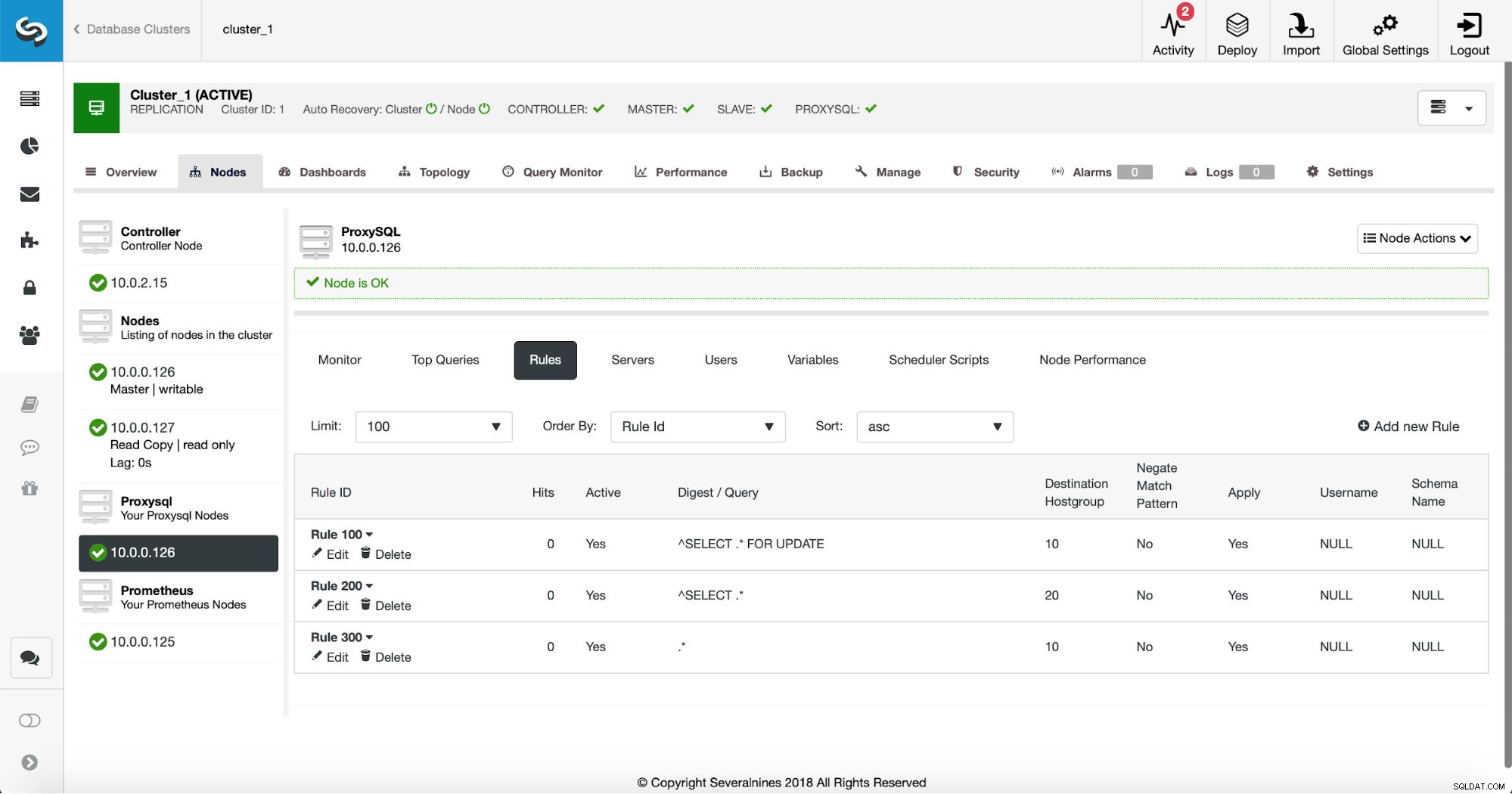
इस बिंदु पर, हमारे पास पढ़ने/लिखने के विभाजन को करने के लिए क्वेरी नियमों का एक सेट है। पहले नियम में 100 की एक आईडी है। हमारे नए क्वेरी नियम को उससे पहले संसाधित किया जाना है, इसलिए हम निचले नियम आईडी का उपयोग करेंगे। आइए एक क्वेरी नियम बनाएं जो इस तरह के प्रश्नों की कैशिंग करेगा:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY c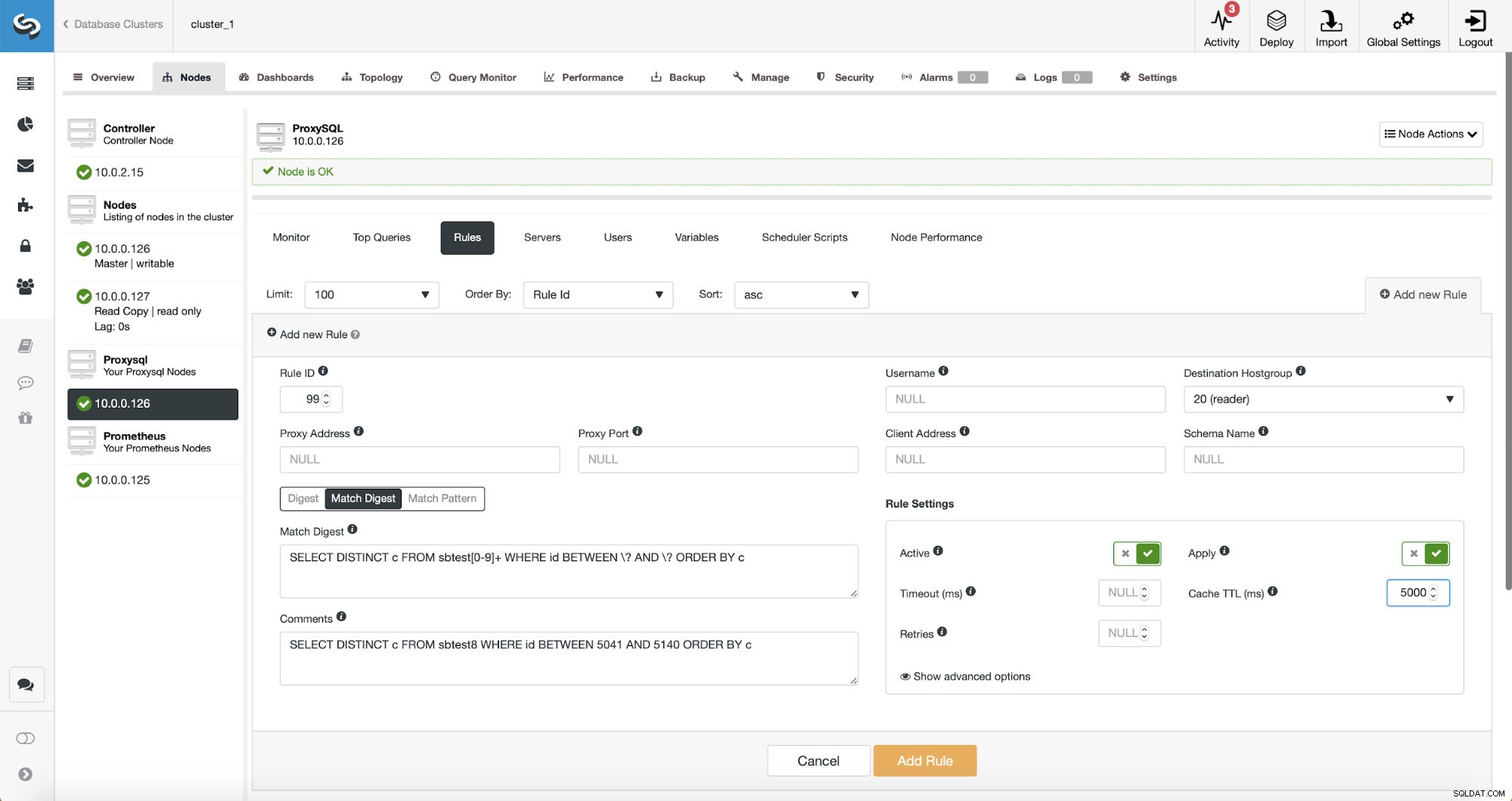
क्वेरी के मिलान के तीन तरीके हैं:डाइजेस्ट, मैच डाइजेस्ट और मैच पैटर्न। आइए यहां उनके बारे में थोड़ी बात करते हैं। सबसे पहले, मैच डाइजेस्ट। हम यहां एक रेगुलर एक्सप्रेशन सेट कर सकते हैं जो एक सामान्यीकृत क्वेरी स्ट्रिंग से मेल खाएगा जो कुछ क्वेरी प्रकार का प्रतिनिधित्व करता है। उदाहरण के लिए, हमारी क्वेरी के लिए:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY cसामान्य प्रतिनिधित्व होगा:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN ? AND ? ORDER BY cजैसा कि आप देख सकते हैं, इसने तर्कों को WHERE क्लॉज से हटा दिया है इसलिए इस प्रकार के सभी प्रश्नों को एक स्ट्रिंग के रूप में दर्शाया जाता है। यह विकल्प उपयोग करने के लिए काफी अच्छा है क्योंकि यह संपूर्ण क्वेरी प्रकार से मेल खाता है और इससे भी अधिक महत्वपूर्ण बात यह है कि यह किसी भी खाली स्थान को हटा देता है। इससे रेगुलर एक्सप्रेशन लिखना इतना आसान हो जाता है क्योंकि आपको अजीब लाइन ब्रेक, स्ट्रिंग की शुरुआत या अंत में व्हाइटस्पेस आदि का हिसाब नहीं देना पड़ता है।
डाइजेस्ट मूल रूप से एक हैश है जिसे ProxySQL मैच डाइजेस्ट फॉर्म पर परिकलित करता है।
अंत में, मैच पैटर्न पूर्ण क्वेरी टेक्स्ट से मेल खाता है, क्योंकि यह क्लाइंट द्वारा भेजा गया था। हमारे मामले में, क्वेरी का एक रूप होगा:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY cहम मैच डाइजेस्ट का उपयोग करने जा रहे हैं क्योंकि हम चाहते हैं कि उन सभी प्रश्नों को क्वेरी नियम द्वारा कवर किया जाए। यदि हम केवल उस विशेष क्वेरी को कैश करना चाहते हैं, तो मैच पैटर्न का उपयोग करना एक अच्छा विकल्प होगा।
हम जिस रेगुलर एक्सप्रेशन का उपयोग करते हैं वह है:
SELECT DISTINCT c FROM sbtest[0-9]+ WHERE id BETWEEN \? AND \? ORDER BY cहम एक अपवाद के साथ शाब्दिक रूप से सटीक सामान्यीकृत क्वेरी स्ट्रिंग का मिलान कर रहे हैं - हम जानते हैं कि यह क्वेरी कई तालिकाओं को प्रभावित करती है इसलिए हमने उन सभी से मेल खाने के लिए एक नियमित अभिव्यक्ति जोड़ा।
एक बार ऐसा करने के बाद, हम देख सकते हैं कि क्वेरी नियम प्रभावी है या नहीं।
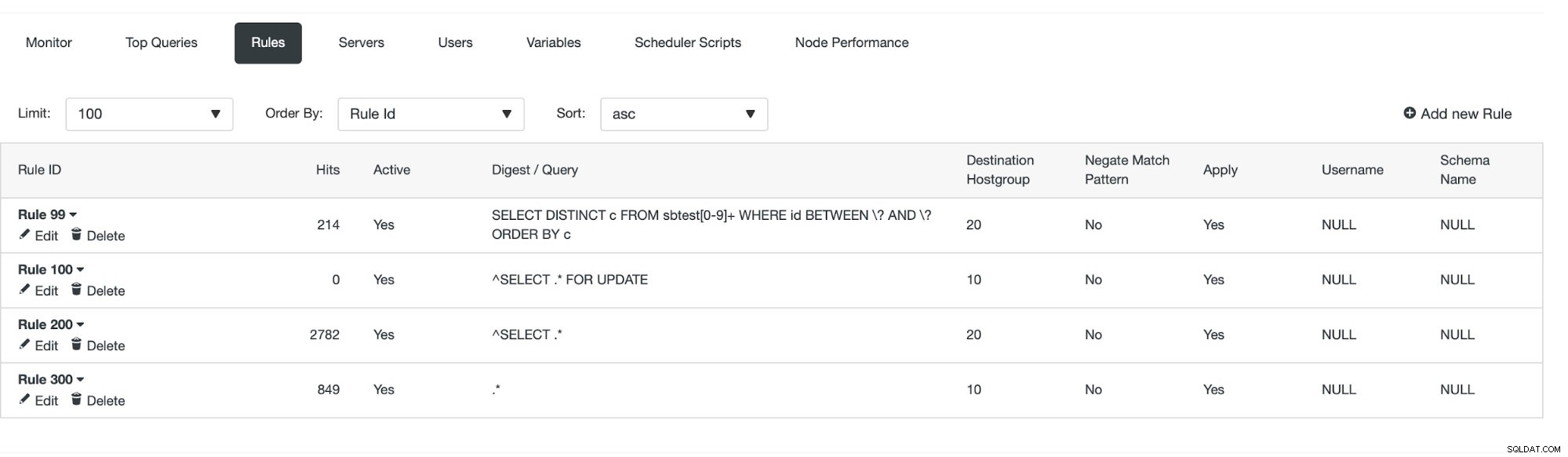
हम देख सकते हैं कि 'हिट' बढ़ रहे हैं जिसका अर्थ है कि हमारे क्वेरी नियम का उपयोग किया जा रहा है। इसके बाद, हम क्वेरी नियम बनाने का दूसरा तरीका देखेंगे।
क्वेरी नियम बनाने के लिए ClusterControl का उपयोग करना
ProxySQL के पास रूट किए गए प्रश्नों के आंकड़े एकत्र करने की उपयोगी कार्यक्षमता है। आप निष्पादन समय जैसे डेटा को ट्रैक कर सकते हैं कि किसी दिए गए क्वेरी को कितनी बार निष्पादित किया गया था और इसी तरह। यह डेटा ClusterControl में भी मौजूद है:
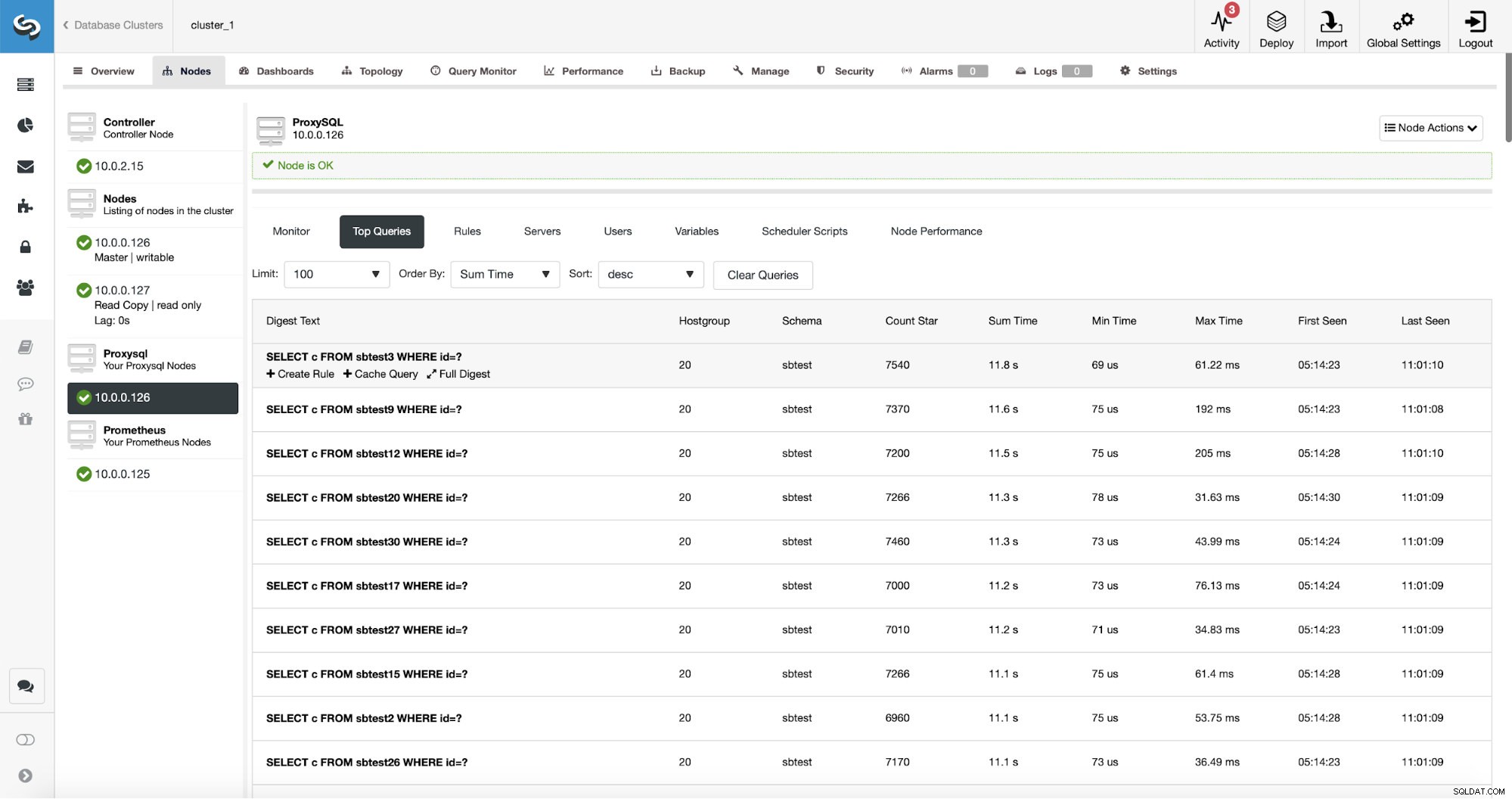
इससे भी बेहतर क्या है, यदि आप किसी दिए गए क्वेरी प्रकार की ओर इशारा करते हैं, तो आप उससे संबंधित एक क्वेरी नियम बना सकते हैं। आप इस विशेष क्वेरी प्रकार को आसानी से कैश भी कर सकते हैं।
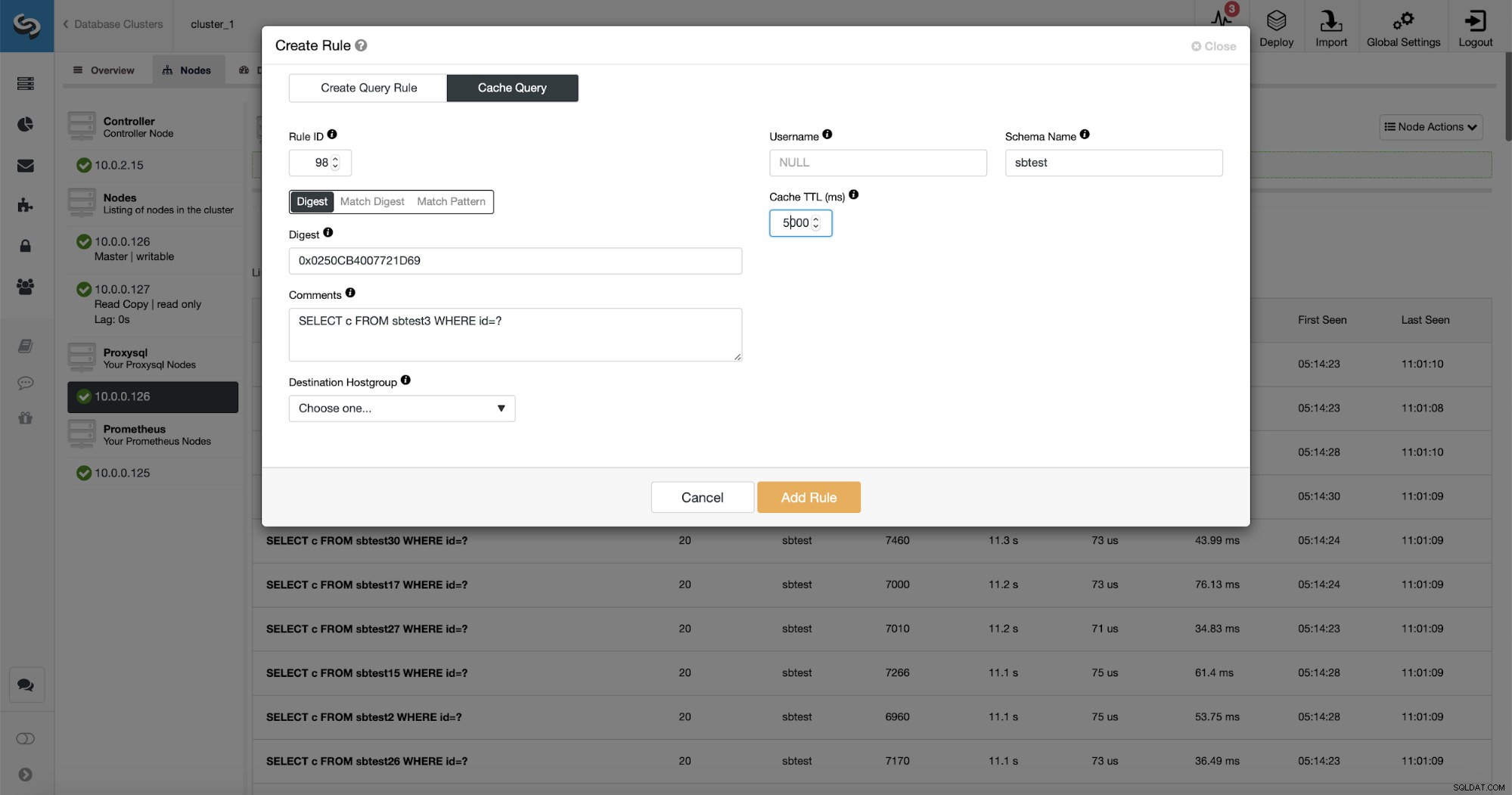
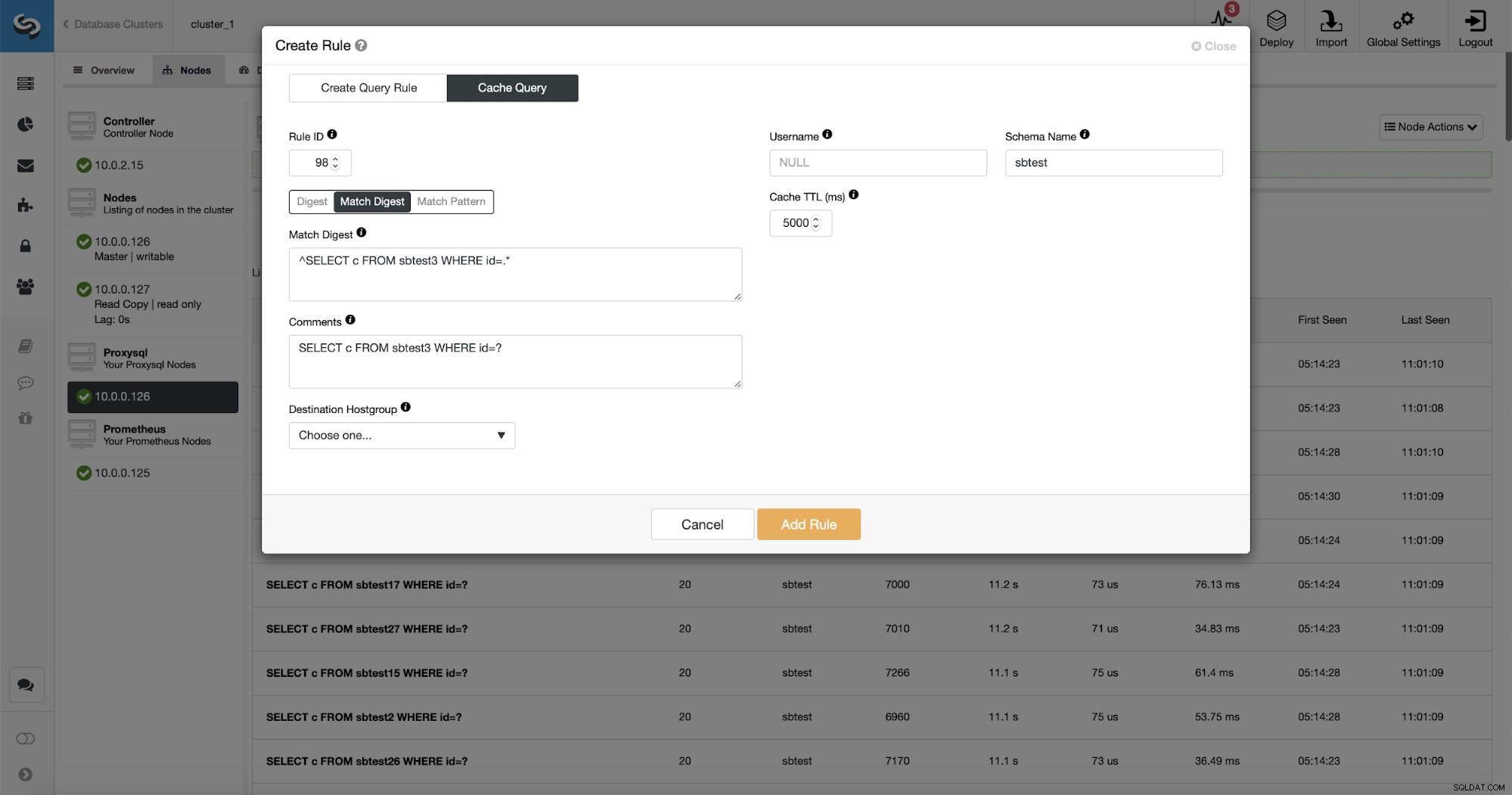
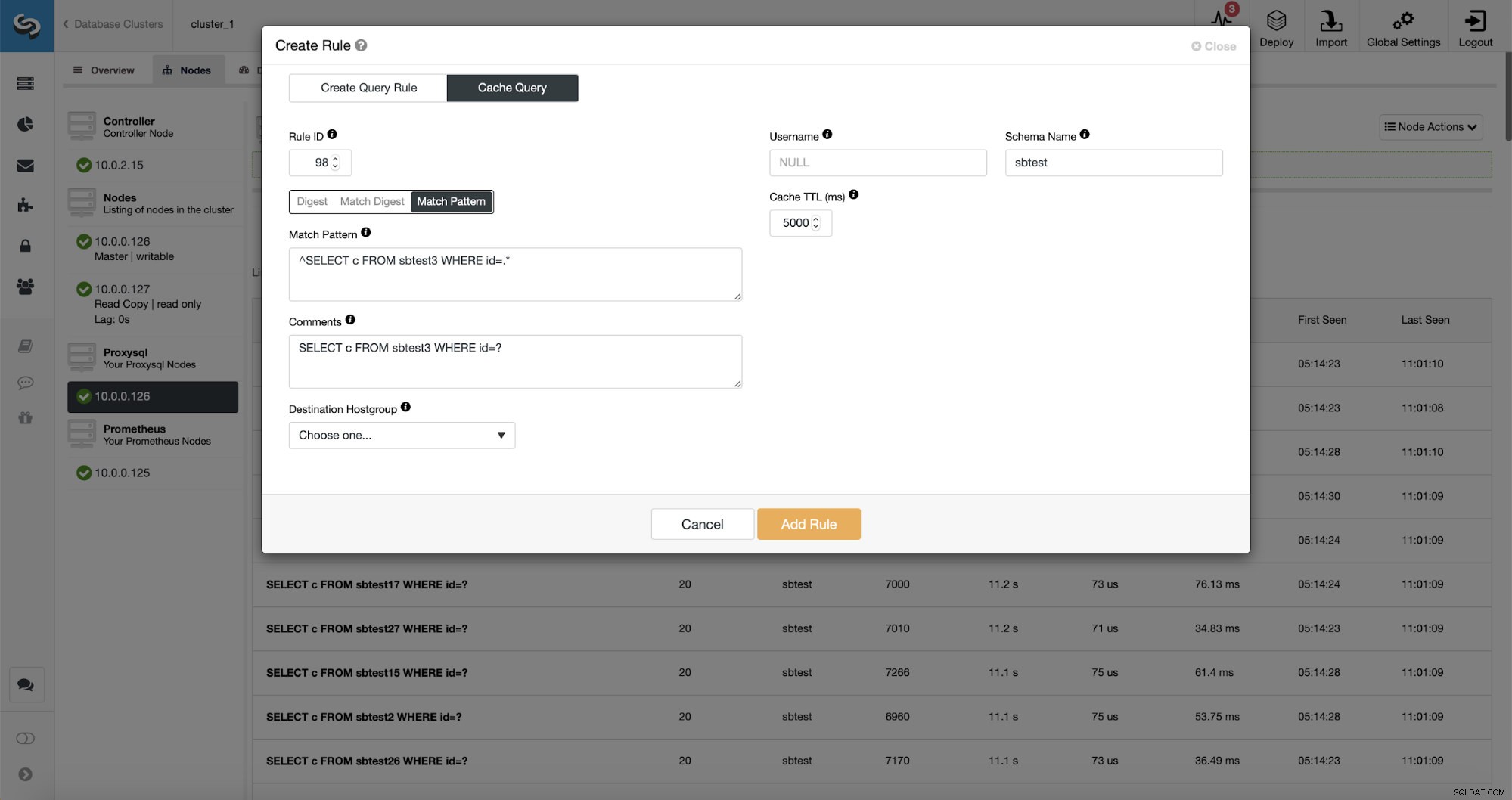
जैसा कि आप देख सकते हैं, कुछ डेटा जैसे रूल आईपी, कैशे टीटीएल या स्कीमा नाम पहले से ही भरे हुए हैं। ClusterControl आपके द्वारा उपयोग किए जाने वाले मिलान तंत्र के आधार पर डेटा भी भरेगा। हम किसी दिए गए क्वेरी प्रकार के लिए आसानी से हैश का उपयोग कर सकते हैं या हम मैच डाइजेस्ट या मैच पैटर्न का उपयोग कर सकते हैं यदि हम नियमित अभिव्यक्ति को ठीक करना चाहते हैं (उदाहरण के लिए जैसा हमने पहले किया था और सभी से मेल खाने के लिए नियमित अभिव्यक्ति का विस्तार करना) sbtest स्कीमा में टेबल)।
ProxySQL में आसानी से क्वेरी कैश नियम बनाने के लिए आपको बस इतना ही करना होगा। इसे आज ही आज़माने के लिए ClusterControl डाउनलोड करें।