परीक्षण डेटा उत्पन्न करने और MySQL OLTP बेंचमार्क निष्पादित करने के लिए Sysbench एक बेहतरीन टूल है। आमतौर पर, Sysbench का उपयोग करते हुए बेंचमार्क निष्पादित करते समय कोई तैयार-रन-क्लीनअप चक्र करेगा। डिफ़ॉल्ट रूप से, Sysbench द्वारा उत्पन्न तालिका एक मानक गैर-विभाजन आधार तालिका है। बेशक, इस व्यवहार को बढ़ाया जा सकता है, लेकिन आपको यह जानना होगा कि इसे LUA स्क्रिप्ट में कैसे लिखना है।
इस ब्लॉग पोस्ट में, हम यह दिखाने जा रहे हैं कि Sysbench का उपयोग करके MySQL में एक विभाजित तालिका के लिए परीक्षण डेटा कैसे उत्पन्न किया जाए। टेबल विभाजन, डेटा वितरण और क्वेरी रूटिंग के कारण-प्रभाव में आगे बढ़ने के लिए इसका उपयोग खेल के मैदान के रूप में किया जा सकता है।
एकल सर्वर तालिका विभाजन
सिंगल-सर्वर पार्टीशन का सीधा सा मतलब है कि सभी टेबल के पार्टिशन एक ही MySQL सर्वर/इंस्टेंस पर रहते हैं। तालिका संरचना बनाते समय, हम सभी विभाजनों को एक साथ परिभाषित करेंगे। इस प्रकार का विभाजन अच्छा है यदि आपके पास डेटा है जो समय के साथ अपनी उपयोगिता खो देता है और केवल उस डेटा वाले विभाजन (या विभाजन) को हटाकर विभाजित तालिका से आसानी से हटाया जा सकता है।
सिसबेंच स्कीमा बनाएं:
mysql> CREATE SCHEMA sbtest;sysbench डेटाबेस उपयोगकर्ता बनाएं:
mysql> CREATE USER 'sbtest'@'%' IDENTIFIED BY 'passw0rd';
mysql> GRANT ALL PRIVILEGES ON sbtest.* TO 'sbtest'@'%';Sysbench में, स्कीमा संरचनाओं के साथ MySQL सर्वर तैयार करने और डेटा की पंक्तियों को उत्पन्न करने के लिए --prepare कमांड का उपयोग किया जाएगा। हमें इस भाग को छोड़ना होगा और तालिका संरचना को मैन्युअल रूप से परिभाषित करना होगा।
एक विभाजित तालिका बनाएं। इस उदाहरण में, हम sbtest1 नामक केवल एक तालिका बनाने जा रहे हैं और इसे "k" नामक कॉलम द्वारा विभाजित किया जाएगा, जो मूल रूप से 0 से 1,000,000 के बीच एक पूर्णांक पूर्णांक है (--टेबल-आकार विकल्प के आधार पर जो हम हैं बाद में केवल-इन्सर्ट ऑपरेशन में उपयोग करने जा रहा है):
mysql> CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`,`k`)
)
PARTITION BY RANGE (k) (
PARTITION p1 VALUES LESS THAN (499999),
PARTITION p2 VALUES LESS THAN MAXVALUE
);हम 2 विभाजन करने जा रहे हैं - पहला विभाजन p1 कहलाता है और डेटा संग्रहीत करेगा जहां कॉलम "k" में मान 499,999 से कम है और दूसरा विभाजन, p2, शेष मानों को संग्रहीत करेगा . हम एक प्राथमिक कुंजी भी बनाते हैं जिसमें दोनों महत्वपूर्ण कॉलम होते हैं - "आईडी" पंक्ति पहचानकर्ता के लिए है और "के" विभाजन कुंजी है। विभाजन में, प्राथमिक कुंजी में तालिका के विभाजन फ़ंक्शन में सभी कॉलम शामिल होने चाहिए (जहां हम श्रेणी विभाजन फ़ंक्शन में "k" का उपयोग करते हैं)।
सत्यापित करें कि विभाजन मौजूद हैं:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest2'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest | sbtest1 | p1 | 0 |
| sbtest | sbtest1 | p2 | 0 |
+--------------+------------+----------------+------------+फिर हम नीचे के रूप में एक Sysbench इंसर्ट-ओनली ऑपरेशन शुरू कर सकते हैं:
$ sysbench \
/usr/share/sysbench/oltp_insert.lua \
--report-interval=2 \
--threads=4 \
--rate=20 \
--time=9999 \
--db-driver=mysql \
--mysql-host=192.168.11.131 \
--mysql-port=3306 \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=passw0rd \
--tables=1 \
--table-size=1000000 \
runसिसबेंच के चलने पर तालिका विभाजन को बढ़ते हुए देखें:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest2'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest | sbtest1 | p1 | 1021 |
| sbtest | sbtest1 | p2 | 1644 |
+--------------+------------+----------------+------------+यदि हम COUNT फ़ंक्शन का उपयोग करके पंक्तियों की कुल संख्या की गणना करते हैं, तो यह विभाजन द्वारा रिपोर्ट की गई पंक्तियों की कुल संख्या के अनुरूप होगी:
mysql> SELECT COUNT(id) FROM sbtest1;
+-----------+
| count(id) |
+-----------+
| 2665 |
+-----------+बस। हमारे पास सिंगल-सर्वर टेबल पार्टिशनिंग तैयार है जिसके साथ हम खेल सकते हैं।
मल्टी-सर्वर तालिका विभाजन
बहु-सर्वर विभाजन में, हम एक विशेष तालिका (sbtest1) के डेटा के सबसेट को भौतिक रूप से संग्रहीत करने के लिए कई MySQL सर्वरों का उपयोग करने जा रहे हैं, जैसा कि निम्नलिखित आरेख में दिखाया गया है:
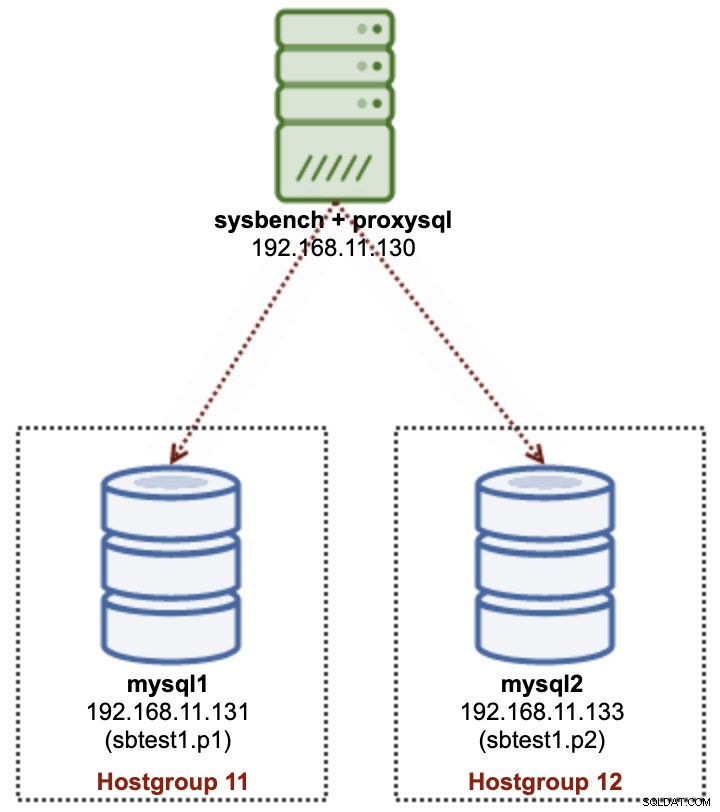
हम 2 स्वतंत्र MySQL नोड्स - mysql1 और mysql2 तैनात करने जा रहे हैं। sbtest1 तालिका को इन दो नोड्स पर विभाजित किया जाएगा और हम इस विभाजन + होस्ट संयोजन को एक शार्प कहेंगे। Sysbench एप्लिकेशन टियर की नकल करते हुए, तीसरे सर्वर पर दूरस्थ रूप से चल रहा है। चूंकि Sysbench विभाजन-जागरूक नहीं है, इसलिए हमें डेटाबेस क्वेरी को सही शार्ड पर रूट करने के लिए डेटाबेस ड्राइवर या राउटर की आवश्यकता होती है। हम इस उद्देश्य को प्राप्त करने के लिए ProxySQL का उपयोग करेंगे।
आइए इस उद्देश्य के लिए sbtest3 नामक एक और नया डेटाबेस बनाएं:
mysql> CREATE SCHEMA sbtest3;
mysql> USE sbtest3;sbtest डेटाबेस उपयोगकर्ता को सही विशेषाधिकार प्रदान करें:
mysql> CREATE USER 'sbtest'@'%' IDENTIFIED BY 'passw0rd';
mysql> GRANT ALL PRIVILEGES ON sbtest3.* TO 'sbtest'@'%';Mysql1 पर, टेबल का पहला पार्टिशन बनाएं:
mysql> CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`,`k`)
)
PARTITION BY RANGE (k) (
PARTITION p1 VALUES LESS THAN (499999)
);स्टैंडअलोन विभाजन के विपरीत, हम तालिका में केवल विभाजन p1 के लिए शर्त को परिभाषित करते हैं जिसमें सभी पंक्तियों को कॉलम "k" मानों के साथ 0 से 499,999 तक संग्रहीत किया जाता है।
mysql2 पर, एक और विभाजित तालिका बनाएं:
mysql> CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`,`k`)
)
PARTITION BY RANGE (k) (
PARTITION p2 VALUES LESS THAN MAXVALUE
);दूसरे सर्वर पर, इसे कॉलम "k" के शेष अनुमानित मानों को संग्रहीत करके दूसरे विभाजन का डेटा रखना चाहिए।
हमारी तालिका संरचना अब परीक्षण डेटा से भरे जाने के लिए तैयार है।
इससे पहले कि हम Sysbench इन्सर्ट-ओनली ऑपरेशन चला सकें, हमें एक ProxySQL सर्वर को क्वेरी राउटर के रूप में स्थापित करना होगा और हमारे MySQL शार्क के लिए गेटवे के रूप में कार्य करना होगा। मल्टी-सर्वर शार्डिंग के लिए एप्लिकेशन से आने वाले डेटाबेस कनेक्शन को सही शार्ड पर रूट करने की आवश्यकता होती है। अन्यथा, आपको निम्न त्रुटि दिखाई देगी:
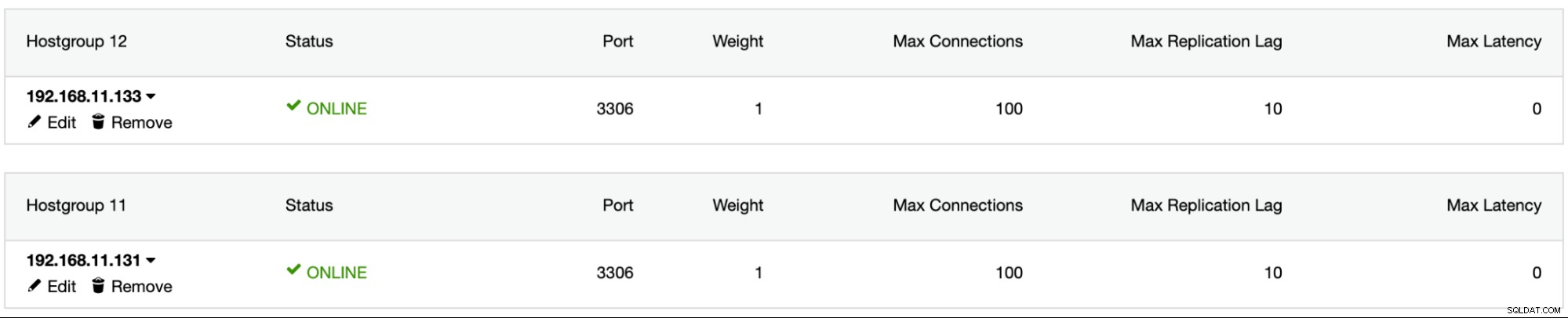
1526 (Table has no partition for value 503599)ClusterControl का उपयोग करके ProxySQL स्थापित करें, sbtest डेटाबेस उपयोगकर्ता को ProxySQL में जोड़ें, दोनों MySQL सर्वरों को ProxySQL में जोड़ें और mysql1 को होस्टग्रुप 11 और mysql2 को होस्टग्रुप 12 के रूप में कॉन्फ़िगर करें:
अगला, हमें इस पर काम करने की जरूरत है कि क्वेरी को कैसे रूट किया जाना चाहिए। INSERT क्वेरी का एक नमूना जो Sysbench द्वारा निष्पादित किया जाएगा, कुछ इस तरह दिखाई देगा:
INSERT INTO sbtest1 (id, k, c, pad)
VALUES (0, 503502, '88816935247-23939908973-66486617366-05744537902-39238746973-63226063145-55370375476-52424898049-93208870738-99260097520', '36669559817-75903498871-26800752374-15613997245-76119597989')इसलिए हम विभाजन की स्थिति को पूरा करने के लिए "k" => 500000 के लिए INSERT क्वेरी को फ़िल्टर करने के लिए निम्नलिखित नियमित अभिव्यक्ति का उपयोग करने जा रहे हैं:
^INSERT INTO sbtest1 \(id, k, c, pad\) VALUES \([0-9]\d*, ([5-9]{1,}[0-9]{5}|[1-9]{1,}[0-9]{6,}).*उपरोक्त अभिव्यक्ति केवल निम्नलिखित को फ़िल्टर करने का प्रयास करती है:
-
[0-9]\d* - हम यहां एक ऑटो-इंक्रीमेंट पूर्णांक की अपेक्षा कर रहे हैं, इस प्रकार, हम किसी भी पूर्णांक से मेल खाते हैं।
-
[5-9]{1,}[0-9]{5} - मान 500,000 से 999,999 तक की सीमा मान से मेल खाने के लिए पहले अंक के रूप में 5 से किसी भी पूर्णांक और अंतिम 5 अंकों पर 0-9 से मेल खाता है।
-
[1-9]{1,}[0-9]{6,} - मान 1-9 से पहले अंक के रूप में किसी भी पूर्णांक से मेल खाता है, और अंतिम 6 या बड़े अंकों पर 0-9, 1,000,000 और उससे अधिक के मान से मेल खाने के लिए।
हम दो समान क्वेरी नियम बनाएंगे। पहला क्वेरी नियम उपरोक्त नियमित अभिव्यक्ति का निषेध है। हम यह नियम आईडी 51 देते हैं और गंतव्य होस्टग्रुप 11 कॉलम "k" <500,000 से मेल खाने के लिए होस्टग्रुप 11 होना चाहिए और प्रश्नों को पहले विभाजन में अग्रेषित करना चाहिए। यह इस तरह दिखना चाहिए:
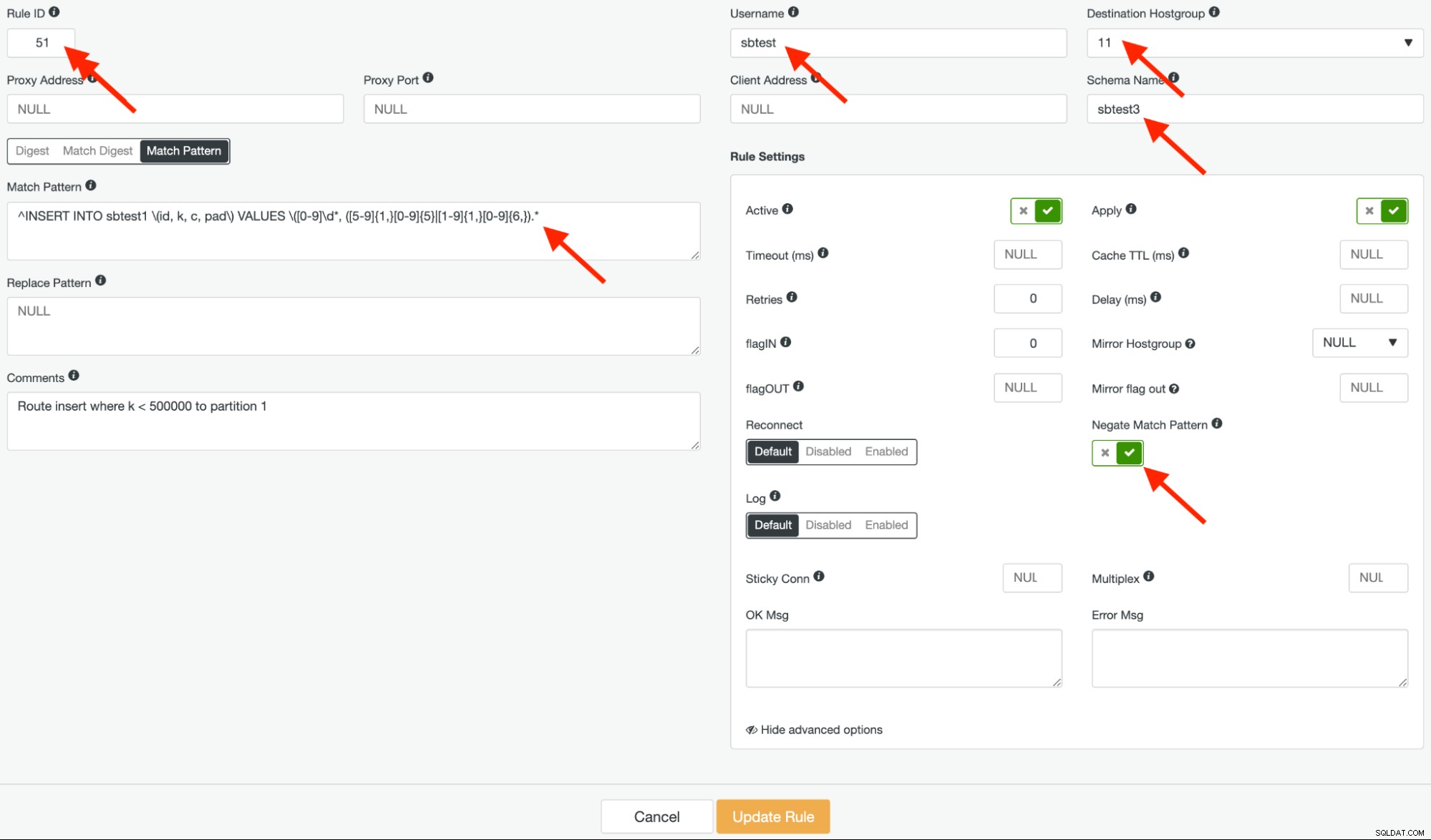
उपरोक्त स्क्रीनशॉट में "नेगेट मैच पैटर्न" पर ध्यान दें। इस क्वेरी नियम के उचित रूटिंग के लिए वह विकल्प महत्वपूर्ण है।
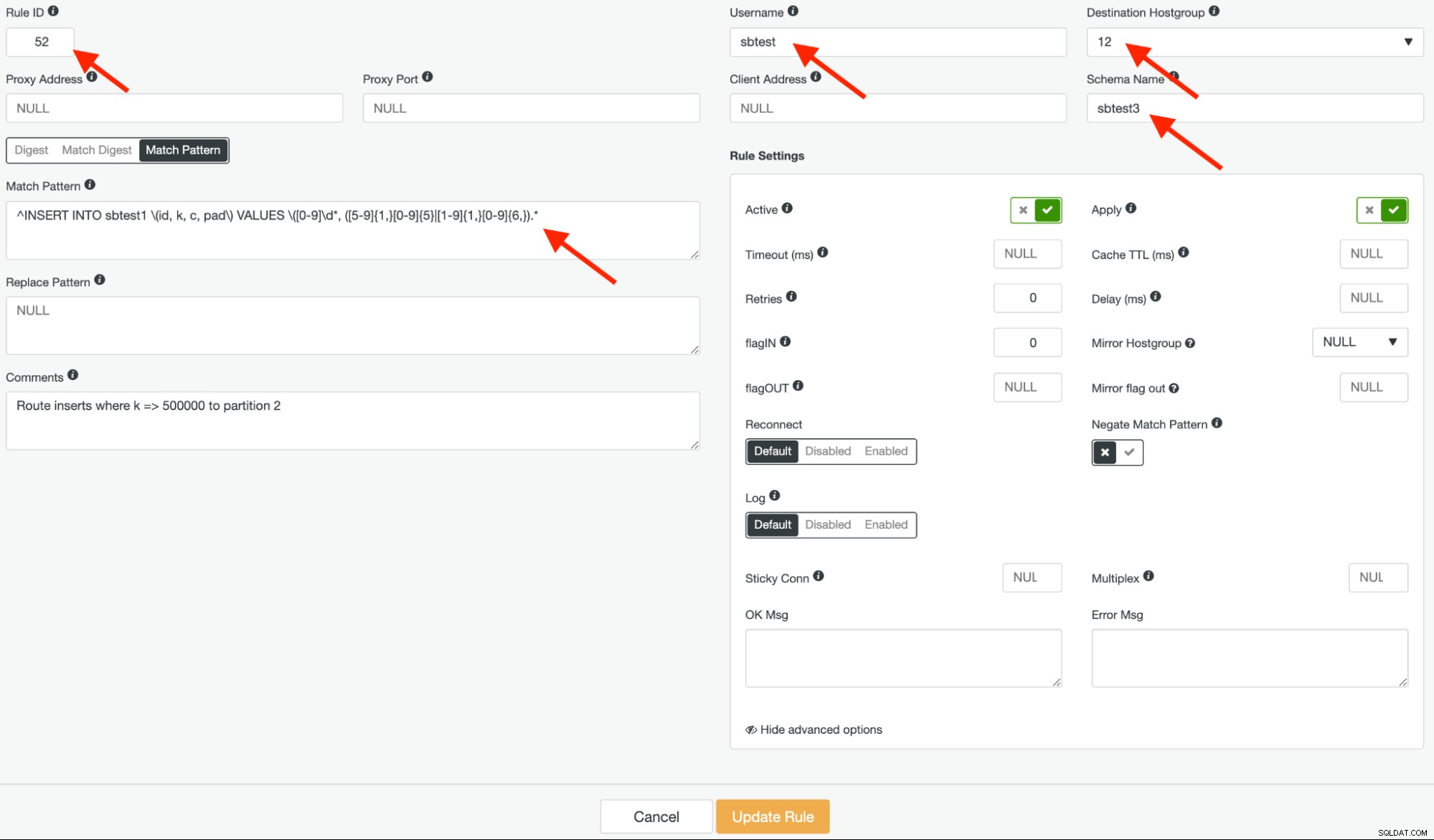
इसके बाद, समान रेगुलर एक्सप्रेशन का उपयोग करते हुए नियम आईडी 52 के साथ एक और क्वेरी नियम बनाएं और गंतव्य होस्टग्रुप 12 होना चाहिए, लेकिन इस बार, "नकारात्मक मिलान पैटर्न" को गलत के रूप में छोड़ दें, जैसा कि नीचे दिखाया गया है:
फिर हम टेस्ट डेटा जेनरेट करने के लिए Sysbench का उपयोग करके केवल-इन्सर्ट ऑपरेशन शुरू कर सकते हैं . MySQL एक्सेस से संबंधित जानकारी ProxySQL होस्ट (पोर्ट 6033 पर 192.168.11.130) होनी चाहिए:
$ sysbench \
/usr/share/sysbench/oltp_insert.lua \
--report-interval=2 \
--threads=4 \
--rate=20 \
--time=9999 \
--db-driver=mysql \
--mysql-host=192.168.11.130 \
--mysql-port=6033 \
--mysql-user=sbtest \
--mysql-db=sbtest3 \
--mysql-password=passw0rd \
--tables=1 \
--table-size=1000000 \
runयदि आपको कोई त्रुटि दिखाई नहीं देती है, तो इसका मतलब है कि ProxySQL ने हमारे प्रश्नों को सही शार्प/पार्टीशन पर भेज दिया है। आपको देखना चाहिए कि Sysbench प्रक्रिया के चलने के दौरान क्वेरी नियम हिट बढ़ रहे हैं:
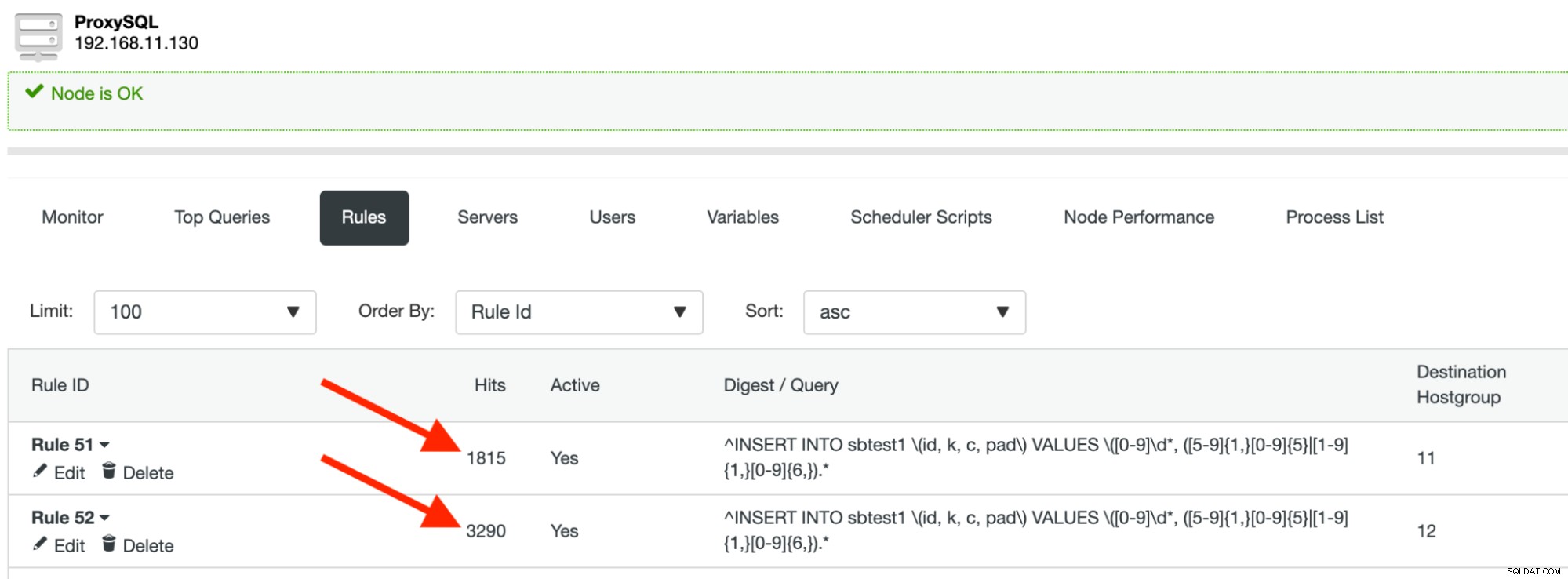
शीर्ष क्वेरी अनुभाग के अंतर्गत, हम क्वेरी रूटिंग का सारांश देख सकते हैं:
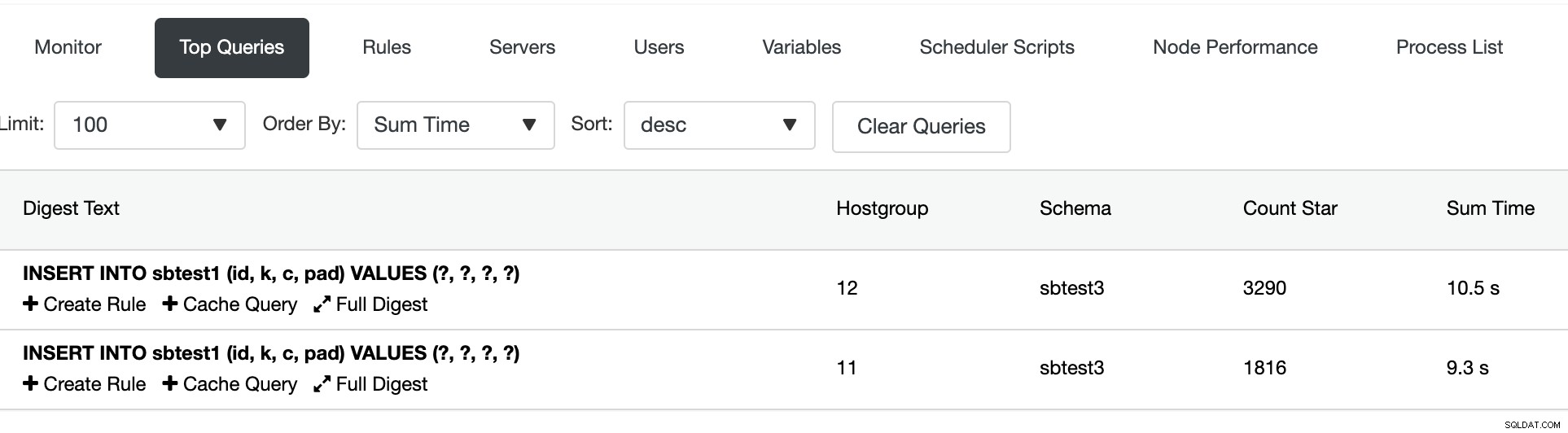
दोबारा जांच करने के लिए, पहले विभाजन को देखने के लिए mysql1 में लॉगिन करें और तालिका sbtest1 पर कॉलम 'k' के न्यूनतम और अधिकतम मान की जांच करें:
mysql> USE sbtest3;
mysql> SELECT min(k), max(k) FROM sbtest1;
+--------+--------+
| min(k) | max(k) |
+--------+--------+
| 232185 | 499998 |
+--------+--------+बहुत अच्छा लग रहा है। कॉलम "के" का अधिकतम मान 499,999 की सीमा से अधिक नहीं है। आइए इस विभाजन के लिए संग्रहीत पंक्तियों की संख्या की जाँच करें:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest3'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest3 | sbtest1 | p1 | 1815 |
+--------------+------------+----------------+------------+अब दूसरे MySQL सर्वर (mysql2) की जांच करते हैं:
mysql> USE sbtest3;
mysql> SELECT min(k), max(k) FROM sbtest1;
+--------+--------+
| min(k) | max(k) |
+--------+--------+
| 500003 | 794952 |
+--------+--------+आइए इस विभाजन के लिए संग्रहीत पंक्तियों की संख्या की जांच करें:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest3'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest3 | sbtest1 | p2 | 3247 |
+--------------+------------+----------------+------------+उत्तम! हमारे पास खेलने के लिए Sysbench का उपयोग करके उचित डेटा विभाजन के साथ एक शार्प MySQL परीक्षण सेटअप है। हैप्पी बेंचमार्किंग!



