हमारे एक ब्लॉग के टिप्पणी अनुभाग में एक पाठक ने गैलेरा क्लस्टर के I/O प्रदर्शन और मापनीयता पर wsrep_slave_threads के प्रभाव के बारे में पूछा। उस समय, हम आसानी से उस प्रश्न का उत्तर नहीं दे सकते थे और अधिक डेटा के साथ उसका बैकअप नहीं ले सकते थे, लेकिन अंत में हम वातावरण स्थापित करने और कुछ परीक्षण चलाने में कामयाब रहे।
हमारे पाठक ने बेंचमार्क की ओर इशारा किया जो दर्शाता है कि बढ़ते wsrep_slave_threads का गैलेरा क्लस्टर के प्रदर्शन पर कोई प्रभाव नहीं पड़ा।
यह समझाने के लिए कि उस सेटिंग का क्या प्रभाव है, हमने तीन नोड्स (m5d.xlarge) का एक छोटा समूह स्थापित किया है। इसने हमें MySQL डेटा निर्देशिका के लिए सीधे संलग्न nvme SSD का उपयोग करने की अनुमति दी। ऐसा करने से, हमने अपने सेटअप में भंडारण की अड़चन बनने की संभावना को कम कर दिया।
हमने InnoDB बफर पूल को 8GB पर सेट किया है और लॉग को दो फाइलों में फिर से करें, प्रत्येक 1GB। हमने innodb_io_capacity को 2000 तक और innodb_io_capacity_max को 10000 तक बढ़ा दिया है। इसका उद्देश्य यह भी सुनिश्चित करना था कि इनमें से कोई भी सेटिंग हमारे प्रदर्शन को प्रभावित नहीं करेगी।
ऐसे बेंचमार्क के साथ पूरी समस्या यह है कि इतनी सारी अड़चनें हैं कि आपको उन्हें एक-एक करके खत्म करना होगा। केवल कुछ कॉन्फ़िगरेशन ट्यूनिंग करने के बाद और यह सुनिश्चित करने के बाद कि हार्डवेयर कोई समस्या नहीं होगी, कोई उम्मीद कर सकता है कि कुछ और सूक्ष्म सीमाएं दिखाई देंगी।
हमने sysbench का उपयोग करके ~90GB डेटा जेनरेट किया:
sysbench /usr/share/sysbench/oltp_write_only.lua --threads=16 --events=0 --time=600 --mysql-host=172.30.4.245 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=3306 --tables=28 --report-interval=1 --skip-trx=off --table-size=10000000 --db-ps-mode=disable --mysql-db=sbtest_large prepareफिर बेंचमार्क निष्पादित किया गया था। हमने दो सेटिंग्स का परीक्षण किया:wsrep_slave_threads=1 और wsrep_slave_threads=16। हार्डवेयर इतना शक्तिशाली नहीं था कि इस वेरिएबल को और भी अधिक बढ़ा सके। कृपया यह भी ध्यान रखें कि हमने यह निर्धारित करने के लिए विस्तृत बेंचमार्किंग नहीं की है कि wsrep_slave_threads को सर्वश्रेष्ठ प्रदर्शन के लिए 16, 8 या शायद 4 पर सेट किया जाना चाहिए या नहीं। हमें यह देखने में दिलचस्पी थी कि क्या हम क्लस्टर पर प्रभाव दिखा सकते हैं। और हाँ, प्रभाव स्पष्ट रूप से दिखाई दे रहा था। शुरुआत के लिए, कुछ प्रवाह नियंत्रण ग्राफ़।
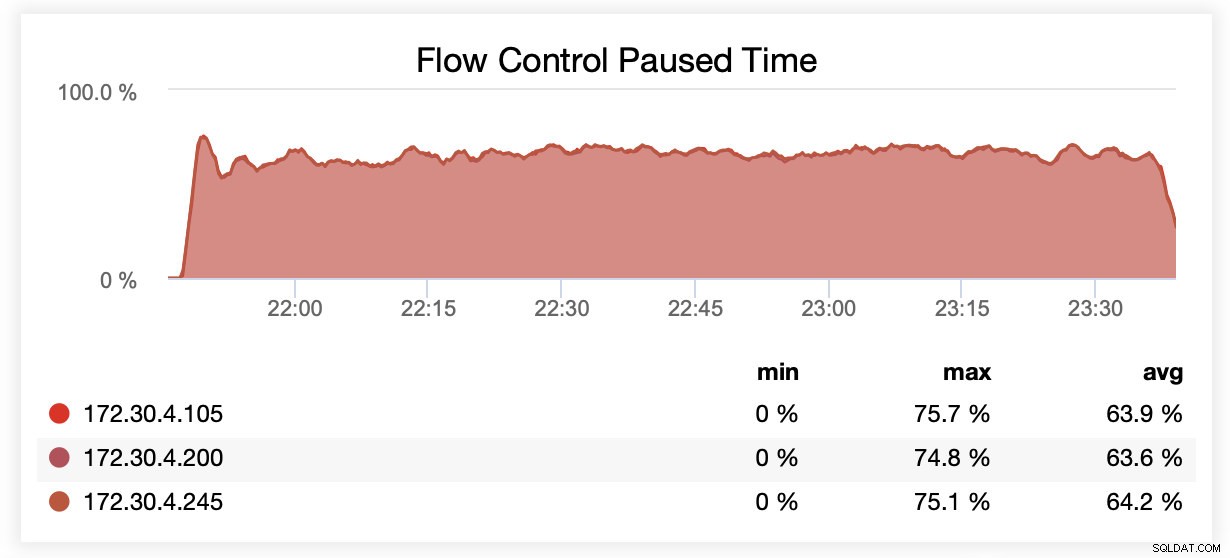
Wsrep_slave_threads=1 के साथ चलने के दौरान, औसतन ~64% समय प्रवाह नियंत्रण के कारण नोड्स रुके हुए थे।
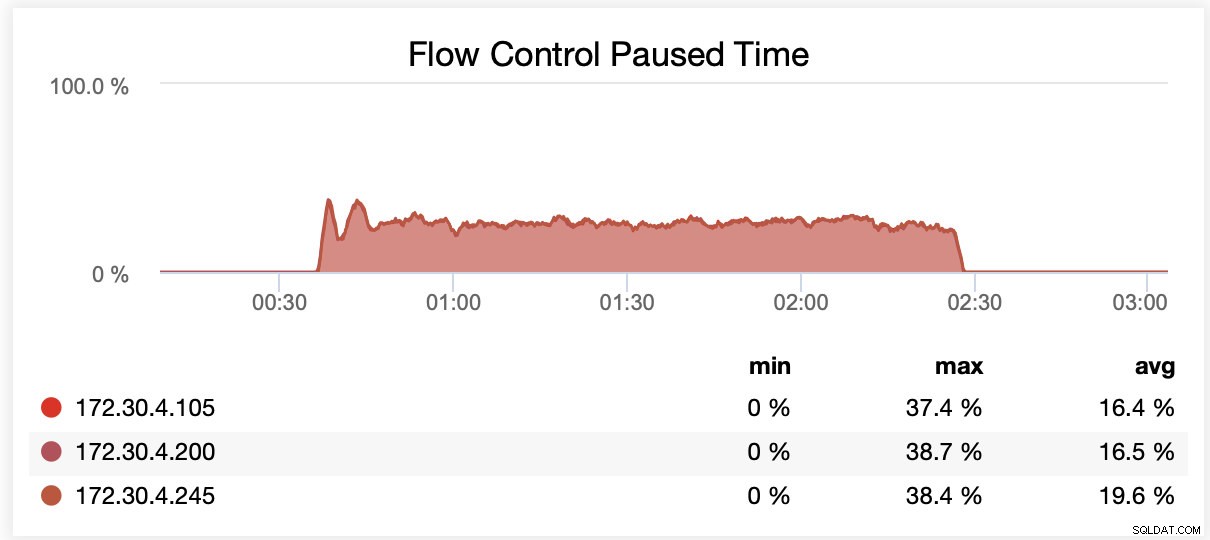
Wsrep_slave_threads=16 के साथ चलते समय, प्रवाह नियंत्रण के कारण लगभग 20% समय नोड्स को रोक दिया गया था।
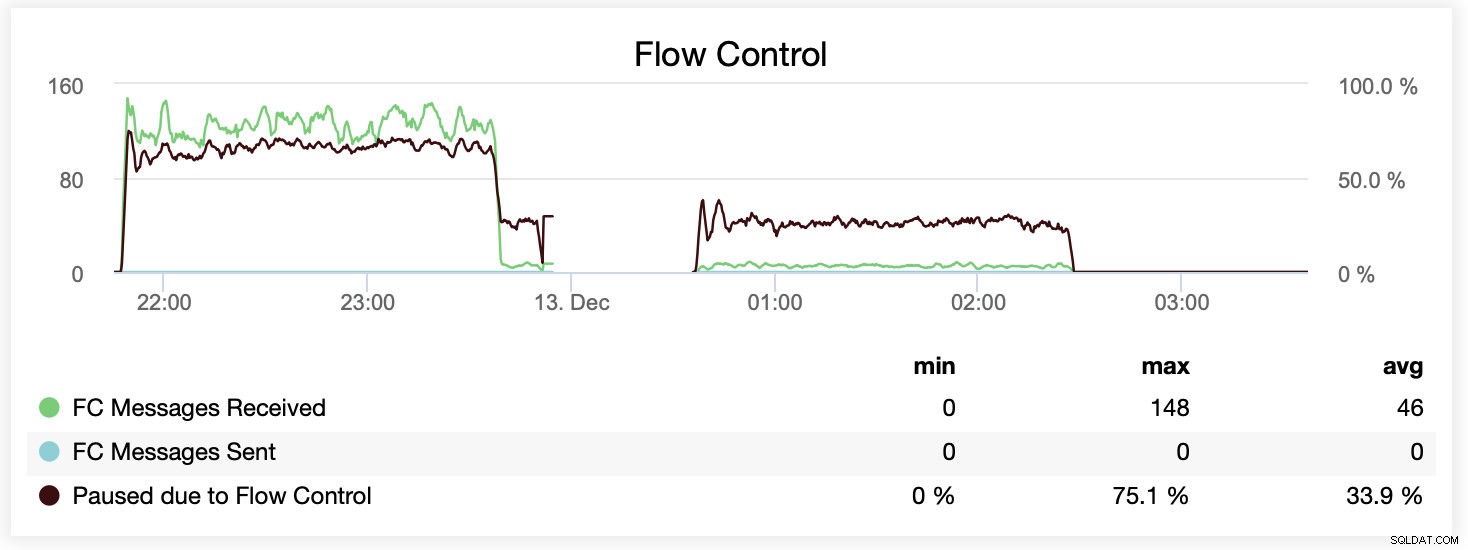
आप एक ग्राफ पर अंतर की तुलना भी कर सकते हैं। पहले भाग के अंत में ड्रॉप wsrep_slave_threads=16 के साथ चलने का पहला प्रयास है। सर्वर बाइनरी लॉग के लिए डिस्क स्थान से बाहर हो गए और हमें बाद में उस बेंचमार्क को एक बार फिर से चलाना पड़ा।
यह प्रदर्शन के संदर्भ में कैसे अनुवादित हुआ? अंतर दिखाई दे रहा है, हालांकि निश्चित रूप से उतना शानदार नहीं है।
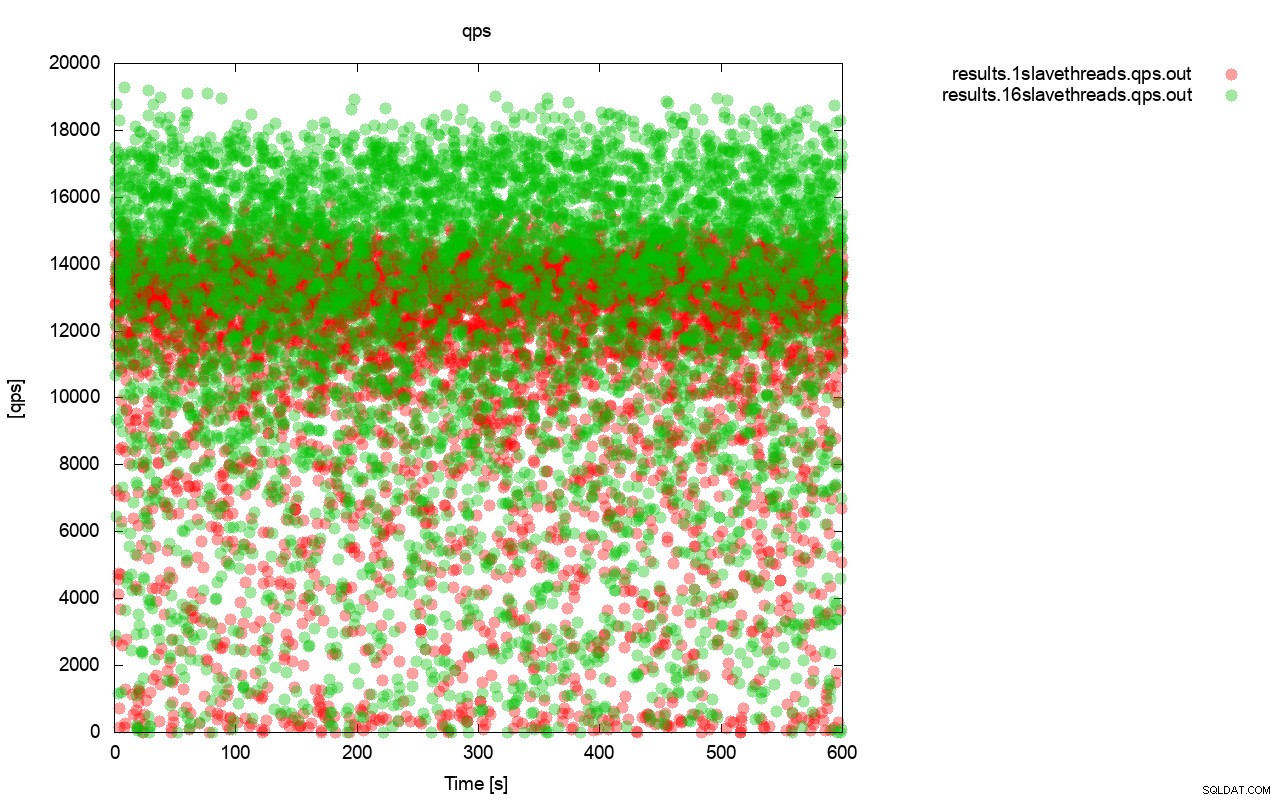
सबसे पहले, प्रति सेकंड ग्राफ क्वेरी। सबसे पहले, आप देख सकते हैं कि दोनों ही मामलों में परिणाम हर जगह हैं। यह ज्यादातर I/O भंडारण के अस्थिर प्रदर्शन से संबंधित है और प्रवाह नियंत्रण बेतरतीब ढंग से शुरू हो रहा है। आप अभी भी देख सकते हैं कि "लाल" परिणाम (wsrep_slave_threads=1) का प्रदर्शन "हरे" वाले की तुलना में काफी कम है ( wsrep_slave_threads=16.
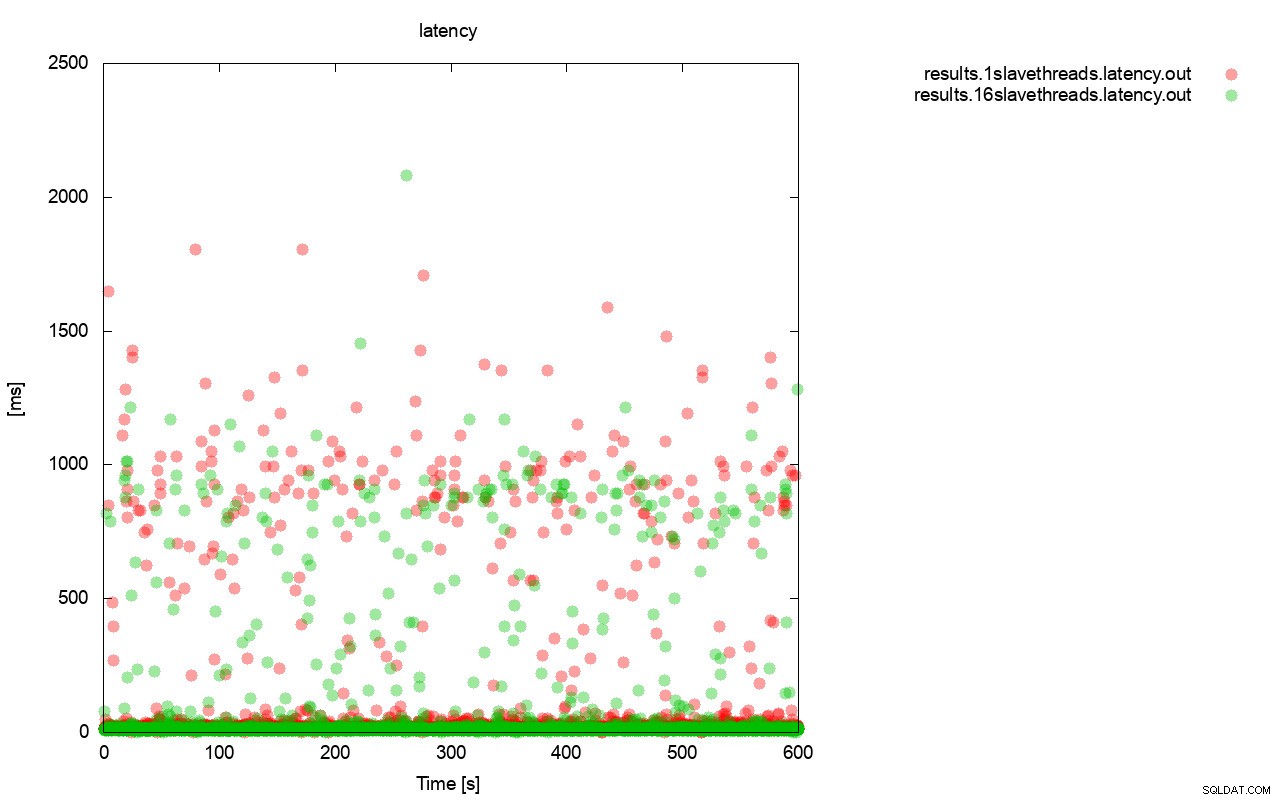
काफी समान तस्वीर तब है जब हम विलंबता को देखते हैं। आप wsrep_slave_thread=1 के साथ रन के लिए और अधिक (और आमतौर पर गहरे) स्टॉल देख सकते हैं।
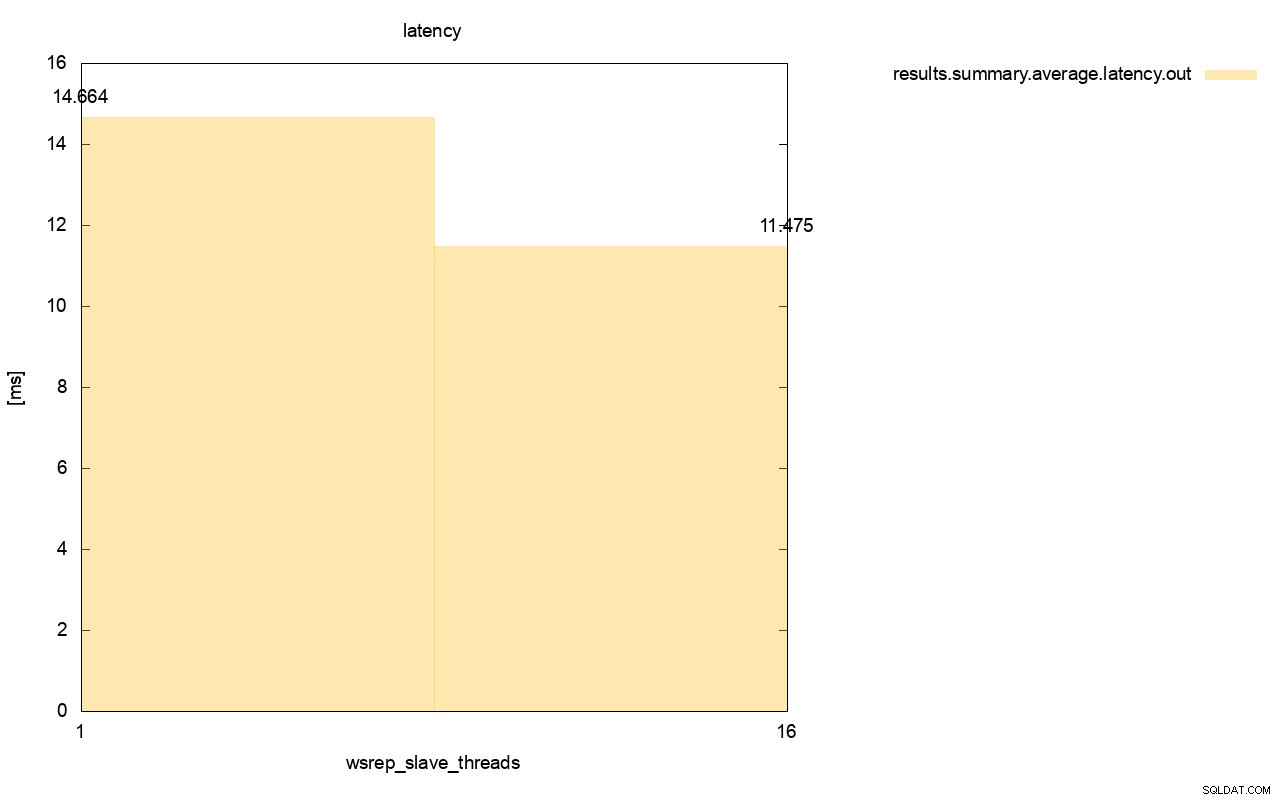
अंतर तब और भी अधिक दिखाई देता है जब हमने सभी रनों में औसत विलंबता की गणना की और आप देख सकते हैं कि wsrep_slave_thread=1 की विलंबता 16 स्लेव थ्रेड्स के साथ विलंबता से 27% अधिक है, जो स्पष्ट रूप से अच्छा नहीं है क्योंकि हम चाहते हैं कि विलंबता कम हो , उच्चतर नहीं।
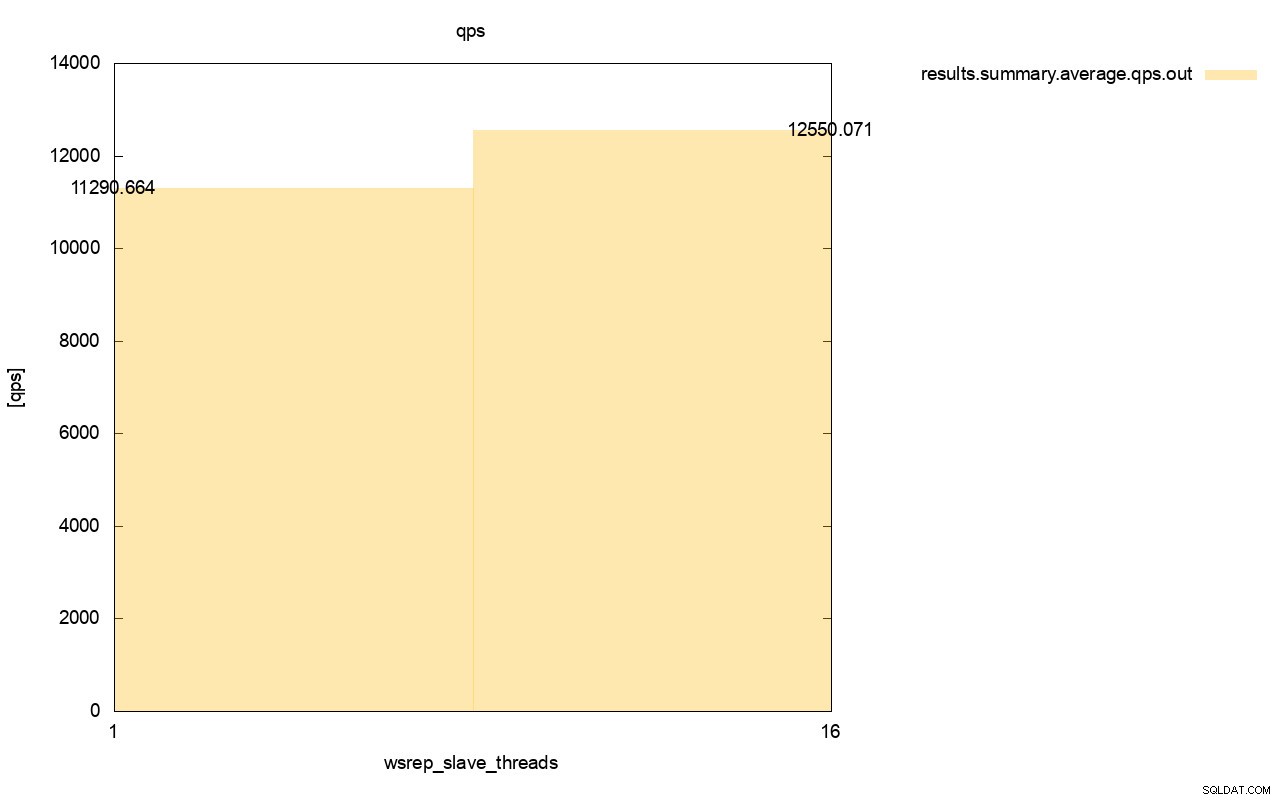
थ्रूपुट में अंतर भी दिखाई दे रहा है, जब हमने और wsrep_slave_threads जोड़े तो लगभग 11% सुधार हुआ।
जैसा कि आप देख सकते हैं, प्रभाव वहाँ है। यह किसी भी तरह से 16 गुना नहीं है (भले ही हमने गैलेरा में दास धागे की संख्या में वृद्धि की हो) लेकिन यह निश्चित रूप से इतना प्रमुख है कि हम इसे केवल एक सांख्यिकीय विसंगति के रूप में वर्गीकृत नहीं कर सकते हैं।
कृपया ध्यान रखें कि हमारे मामले में हमने काफी छोटे नोड्स का इस्तेमाल किया। अंतर और भी अधिक महत्वपूर्ण होना चाहिए यदि हम हजारों प्रावधानित आईओपीएस के साथ ईबीएस संस्करणों पर चलने वाले बड़े उदाहरणों के बारे में बात कर रहे हैं।
तब हम अधिक संख्या में समवर्ती संचालन के साथ, अधिक आक्रामक रूप से sysbench चलाने में सक्षम होंगे। इससे राइटसेट के समानांतरीकरण में सुधार होना चाहिए, मल्टीथ्रेडिंग से लाभ में और भी सुधार होगा। साथ ही, तेज़ हार्डवेयर का मतलब है कि गैलेरा उन 16 थ्रेड्स का अधिक कुशल तरीके से उपयोग करने में सक्षम होगा।
इस तरह के परीक्षण चलाते समय आपको यह ध्यान रखना होगा कि आपको अपने सेटअप को लगभग उसकी सीमा तक धकेलने की आवश्यकता है। सिंगल-थ्रेडेड प्रतिकृति काफी भार को संभाल सकती है और आपको वास्तव में कार्य को संभालने के लिए पर्याप्त प्रदर्शन नहीं करने के लिए भारी ट्रैफ़िक चलाने की आवश्यकता है।
हमें उम्मीद है कि यह ब्लॉग पोस्ट आपको समानांतर में राइटसेट लागू करने और इसके आसपास सीमित कारकों को लागू करने के लिए गैलेरा क्लस्टर की क्षमताओं के बारे में अधिक जानकारी प्रदान करता है।