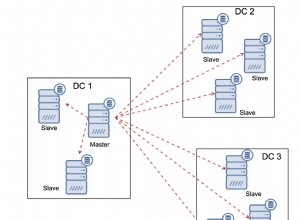
MySQL के लिए उच्च उपलब्धता प्राप्त करने के सबसे लोकप्रिय तरीकों में से एक प्रतिकृति है। प्रतिकृति लगभग कई वर्षों से है, और जीटीआईडी की शुरूआत के साथ और अधिक स्थिर हो गई है। लेकिन इन सुधारों के साथ भी, विभिन्न कारणों से प्रतिकृति प्रक्रिया टूट सकती है - उदाहरण के लिए, जब मास्टर और दास सिंक से बाहर हो जाते हैं क्योंकि लेखन सीधे दास को भेजे गए थे। आप प्रतिकृति समस्याओं का निवारण कैसे करते हैं, और आप उन्हें कैसे ठीक करते हैं?
इस ब्लॉग पोस्ट में, हम प्रतिकृति के साथ कुछ सामान्य मुद्दों पर चर्चा करेंगे और उन्हें ClusterControl के साथ कैसे ठीक करें। आइए पहले वाले से शुरू करें।
कुछ त्रुटि के साथ प्रतिकृति रोकी गई
अधिकांश MySQL DBA को आमतौर पर अपने करियर में कम से कम एक बार इस तरह की समस्या का सामना करना पड़ेगा। विभिन्न कारणों से, एक दास भ्रष्ट हो सकता है या हो सकता है कि स्वामी के साथ तालमेल बिठाना बंद कर दे। जब ऐसा होता है, तो समस्या निवारण शुरू करने के लिए सबसे पहले संदेशों के लिए त्रुटि लॉग की जांच करना है। अधिकांश समय, त्रुटि संदेश त्रुटि लॉग में या SHOW SLAVE STATUS क्वेरी चलाकर आसानी से पता लगाया जा सकता है।
आइए SHOW STATUS SLAVE से निम्नलिखित उदाहरण देखें:
********** 0. row **********
Slave_IO_State:
Master_Host: 10.2.9.71
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000111
Read_Master_Log_Pos: 255477362
Relay_Log_File: relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: binlog.000111
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 255477362
Relay_Log_Space: 256
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master:
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1000
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 1000-1000-2268440
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: optimistic
SQL_Delay: 0
SQL_Remaining_Delay:
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0हम स्पष्ट रूप से देख सकते हैं कि बाइनरी लॉग से डेटा पढ़ते समय त्रुटि मास्टर से मिली घातक त्रुटि 1236 से संबंधित है:'किसी भी बिनलॉग फ़ाइलों में दास द्वारा अनुरोधित GTID स्थिति नहीं मिली। शायद गुलाम राज्य बहुत पुराना है और आवश्यक बिनलॉग फाइलों को शुद्ध कर दिया गया है।'। क्रम शब्दों में, त्रुटि हमें अनिवार्य रूप से बता रही है कि डेटा में असंगति है और आवश्यक बाइनरी लॉग फ़ाइलें पहले ही हटा दी गई हैं।
यह एक अच्छा उदाहरण है जहां प्रतिकृति प्रक्रिया काम करना बंद कर देती है। SHOW SLAVE STATUS के अलावा, आप ClusterControl में क्लस्टर के "अवलोकन" टैब में भी स्थिति को ट्रैक कर सकते हैं। तो इसे ClusterControl के साथ कैसे ठीक करें? कोशिश करने के लिए आपके पास दो विकल्प हैं:
-
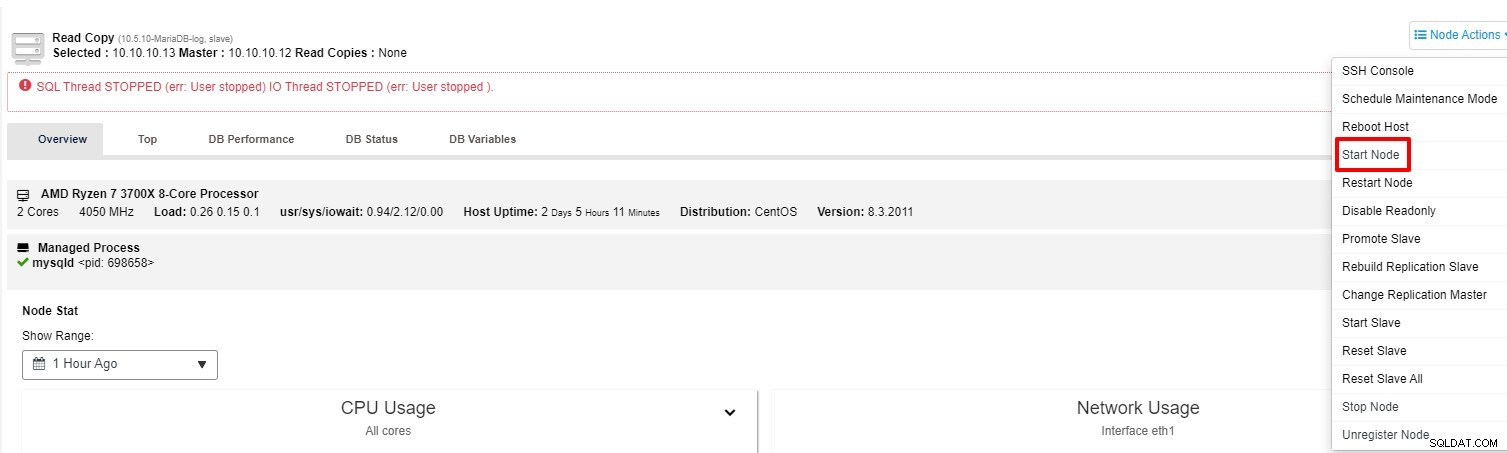
आप "नोड एक्शन" से स्लेव को फिर से शुरू करने का प्रयास कर सकते हैं
-
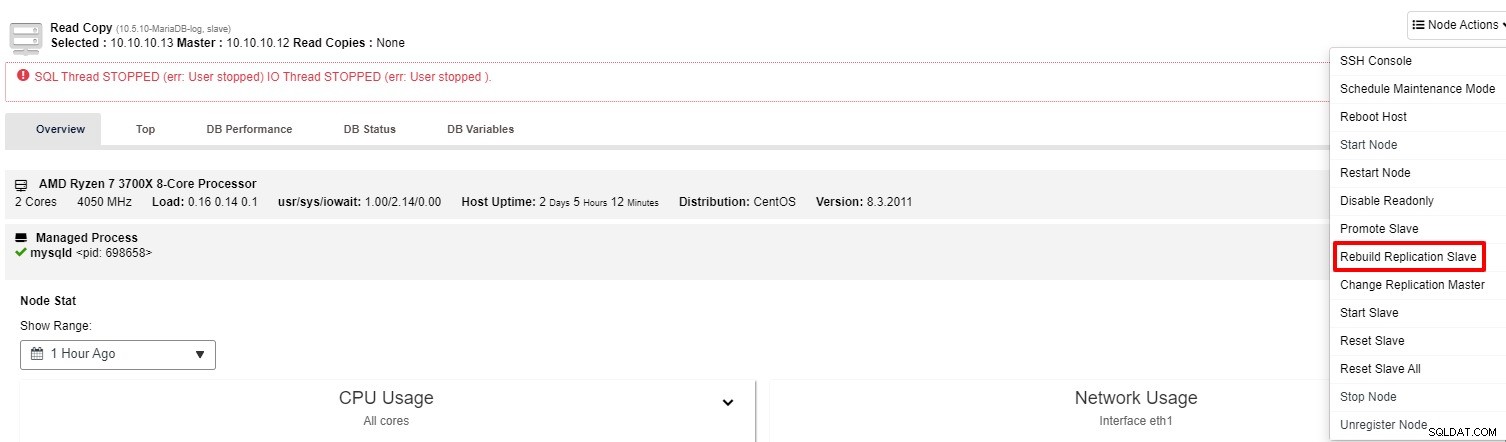
यदि दास अभी भी काम नहीं कर रहा है, तो आप "पुनर्निर्माण दास का पुनर्निर्माण" कार्य चला सकते हैं "नोड एक्शन" से
अधिकांश समय, दूसरा विकल्प समस्या का समाधान कर देगा। ClusterControl मास्टर का बैकअप लेगा, और डेटा को पुनर्स्थापित करके टूटे हुए दास का पुनर्निर्माण करेगा। एक बार डेटा बहाल हो जाने के बाद, दास मास्टर से जुड़ा होता है ताकि वह पकड़ सके।
नीचे सूचीबद्ध दास के पुनर्निर्माण के कई मैन्युअल तरीके भी हैं, अधिक विवरण के लिए आप इस लिंक को भी देख सकते हैं:
-
एक असंगत MySQL स्लेव के पुनर्निर्माण के लिए Mysqldump का उपयोग करना
-
एक असंगत MySQL स्लेव के पुनर्निर्माण के लिए Mydumper का उपयोग करना
-
एक असंगत MySQL स्लेव को फिर से बनाने के लिए स्नैपशॉट का उपयोग करना
-
एक असंगत MySQL स्लेव के पुनर्निर्माण के लिए एक्स्ट्राबैकअप या मारियाबैकअप का उपयोग करना
एक गुलाम को गुरु बनने के लिए प्रोत्साहित करें
समय के साथ, स्थिरता और सुरक्षा बनाए रखने के लिए OS या डेटाबेस को पैच या अपग्रेड करने की आवश्यकता होती है। डाउनटाइम को कम करने के लिए विशेष रूप से एक प्रमुख अपग्रेड के लिए सर्वोत्तम प्रथाओं में से एक दास में से एक को उस विशेष नोड पर अपग्रेड सफलतापूर्वक किए जाने के बाद मास्टर करने के लिए बढ़ावा देना है।
इसे निष्पादित करके, आप अपने आवेदन को नए मास्टर की ओर इंगित कर सकते हैं और मास्टर-स्लेव प्रतिकृति काम करना जारी रखेगी। इस बीच, आप मन की शांति के साथ पुराने गुरु के उन्नयन के साथ भी आगे बढ़ सकते हैं। ClusterControl के साथ इसे केवल कुछ क्लिकों के साथ निष्पादित किया जा सकता है, केवल यह मानते हुए कि प्रतिकृति को ग्लोबल ट्रांजैक्शन आईडी-आधारित या GTID-आधारित संक्षिप्त के रूप में कॉन्फ़िगर किया गया है। किसी भी डेटा हानि से बचने के लिए, पुराने मास्टर के ठीक से काम करने की स्थिति में किसी भी एप्लिकेशन क्वेरी को रोकना उचित है। यह एकमात्र स्थिति नहीं है कि आप दास को बढ़ावा दे सकते हैं। मास्टर नोड के डाउन होने की स्थिति में, आप यह क्रिया भी कर सकते हैं।
ClusterControl के बिना, दास को बढ़ावा देने के लिए कुछ चरण हैं। प्रत्येक चरण को चलाने के लिए भी कुछ प्रश्नों की आवश्यकता होती है:
-
मैन्युअल रूप से मास्टर को नीचे ले जाएं
-
मास्टर बनने के लिए सबसे उन्नत दास का चयन करें और इसे तैयार करें
-
अन्य दासों को नए मास्टर से दोबारा कनेक्ट करें
-
पुराने मालिक को गुलाम के रूप में बदलना
फिर भी, ClusterControl के साथ स्लेव को बढ़ावा देने के चरण केवल कुछ ही क्लिक हैं:क्लस्टर> नोड्स> स्लेव नोड चुनें> नीचे दिए गए स्क्रीनशॉट के अनुसार स्लेव को बढ़ावा दें:
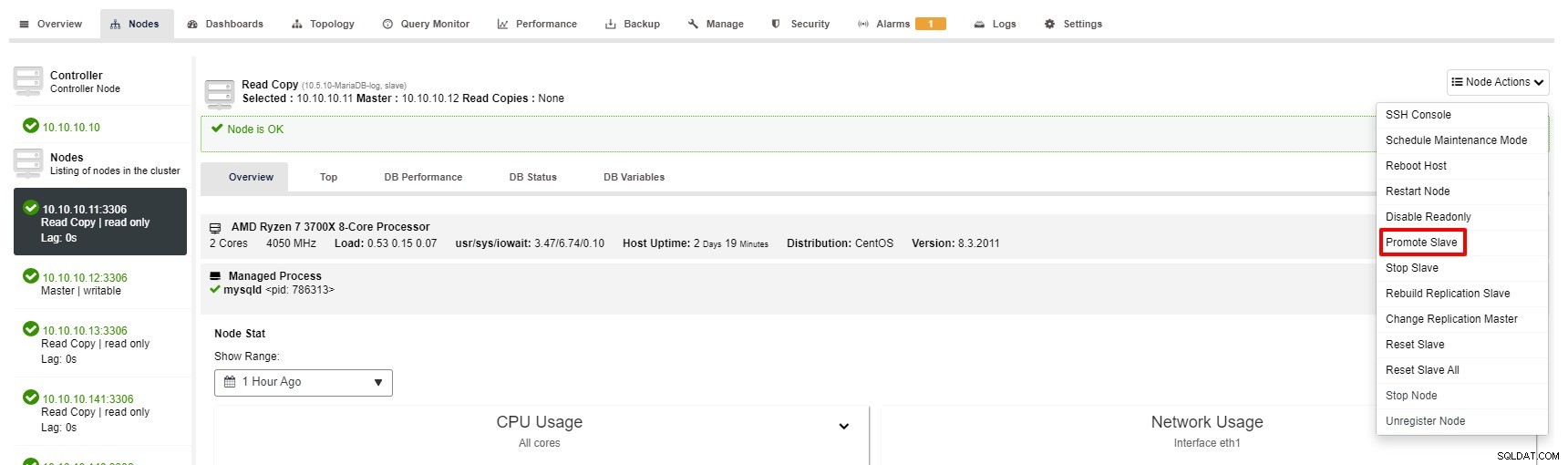
मास्टर अनुपलब्ध हो जाता है
कल्पना करें कि आपके पास चलाने के लिए बड़े लेन-देन हैं लेकिन डेटाबेस डाउन है। इससे कोई फर्क नहीं पड़ता कि आप कितने सावधान हैं, प्रतिकृति सेटअप के लिए यह शायद सबसे गंभीर या महत्वपूर्ण स्थिति है। जब ऐसा होता है, तो आपका डेटाबेस एक भी लेखन को स्वीकार करने में सक्षम नहीं होता है, जो कि खराब है। इसके अलावा, आपका आवेदन, निश्चित रूप से, ठीक से काम नहीं करेगा।
इस समस्या के कुछ कारण या कारण हैं। कुछ उदाहरण हार्डवेयर विफलता, ओएस भ्रष्टाचार, डेटाबेस भ्रष्टाचार आदि हैं। DBA के रूप में, आपको मास्टर डेटाबेस को पुनर्स्थापित करने के लिए शीघ्रता से कार्य करने की आवश्यकता है।
क्लस्टरकंट्रोल में उपलब्ध "ऑटो रिकवरी" क्लस्टर फ़ंक्शन के लिए धन्यवाद, विफलता प्रक्रिया को स्वचालित किया जा सकता है। इसे एक क्लिक से सक्षम या अक्षम किया जा सकता है। जैसा कि नाम से पता चलता है, यह क्या करेगा जब आवश्यक हो तो संपूर्ण क्लस्टर टोपोलॉजी को सामने लाएगा। उदाहरण के लिए, उपलब्ध दासों की संख्या की परवाह किए बिना, किसी भी समय मास्टर-दास प्रतिकृति में कम से कम एक मास्टर जीवित होना चाहिए। जब मास्टर उपलब्ध नहीं होता है, तो यह स्वचालित रूप से दासों में से एक को बढ़ावा देगा।
आइए नीचे स्क्रीनशॉट पर एक नजर डालते हैं:
उपरोक्त स्क्रीनशॉट में, हम देख सकते हैं कि क्लस्टर और नोड दोनों के लिए "ऑटो रिकवरी" सक्षम है। टोपोलॉजी में, ध्यान दें कि वर्तमान मास्टर आईपी पता 10.10.10.11 है। यदि हम परीक्षण के उद्देश्य से मास्टर नोड को हटा देते हैं तो क्या होगा?
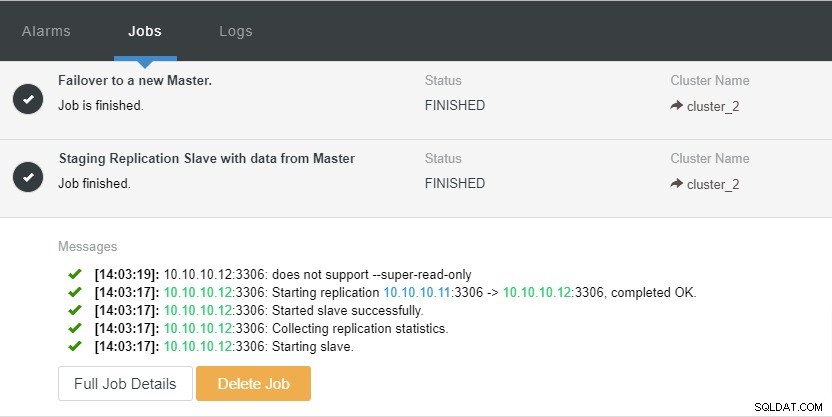
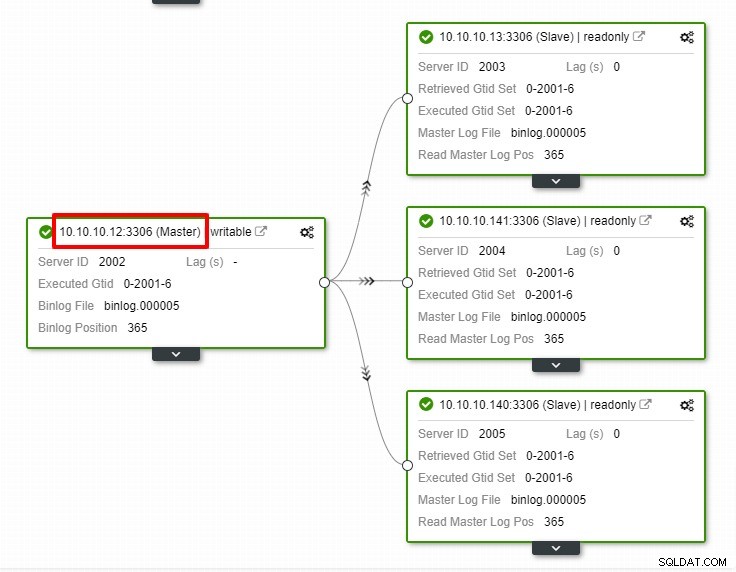
जैसा कि आप देख सकते हैं, IP 10.10.10.12 वाला स्लेव नोड अपने आप है मास्टर में पदोन्नत किया जाता है, ताकि प्रतिकृति टोपोलॉजी को पुन:कॉन्फ़िगर किया जा सके। इसे मैन्युअल रूप से करने के बजाय, निश्चित रूप से, जिसमें बहुत सारे चरण शामिल होंगे, ClusterControl आपके हाथों की परेशानी को दूर करके आपके प्रतिकृति सेटअप को बनाए रखने में आपकी सहायता करता है।
निष्कर्ष
आपके प्रतिकृति के साथ किसी भी दुर्भाग्यपूर्ण घटना में, क्लस्टरकंट्रोल के साथ फिक्स बहुत आसान और कम परेशानी है। ClusterControl आपकी प्रतिकृति समस्याओं को शीघ्रता से ठीक करने में आपकी सहायता करता है, जिससे आपके डेटाबेस का अपटाइम बढ़ जाता है।