इस वर्ष मेरी सभी पोस्ट आँकड़ों की प्रतीक्षा करने के लिए घुटने-झटके प्रतिक्रियाओं के बारे में हैं, लेकिन इस पोस्ट में मैं उस विषय से भटक रहा हूँ जो मेरे एक विशेष बग भालू के बारे में बात कर रहा है:पृष्ठ जीवन प्रत्याशा प्रदर्शन काउंटर (जिसे मैं पीएलई कहूंगा) )।
पीएलई का क्या मतलब है?
इंटरनेट पर पृष्ठ जीवन प्रत्याशा के बारे में सभी प्रकार के गलत कथन हैं, और सबसे गंभीर वे हैं जो निर्दिष्ट करते हैं कि मूल्य 300 वह सीमा है जहां आपको चिंतित होना चाहिए।
यह समझने के लिए कि यह कथन इतना भ्रामक क्यों है, आपको यह समझने की आवश्यकता है कि वास्तव में PLE क्या है।
पीएलई की परिभाषा अपेक्षित समय है, सेकंड में, कि एक डेटा फ़ाइल पृष्ठ बफर पूल में पढ़ा जाता है (डेटा फ़ाइल पृष्ठों का इन-मेमोरी कैश) एक अलग डेटा के लिए जगह बनाने के लिए मेमोरी से बाहर धकेलने से पहले मेमोरी में रहेगा। फ़ाइल पृष्ठ। पीएलई के बारे में सोचने का दूसरा तरीका बफर पूल पर डिस्क से पढ़ने वाले पृष्ठों के लिए खाली जगह बनाने के लिए दबाव का एक तात्कालिक उपाय है। इन दोनों परिभाषाओं के लिए, एक बड़ी संख्या बेहतर है।
एक अच्छी पीएलई सीमा क्या है?
300 के PLE का मतलब है कि आपके पूरे बफर पूल को प्रभावी ढंग से फ्लश किया जा रहा है और हर पांच मिनट में फिर से पढ़ा जा रहा है। जब 2005/2006 के आस-पास माइक्रोसॉफ्ट द्वारा पहली बार पीएलई 300 के लिए थ्रेशोल्ड मार्गदर्शन दिया गया था, तो उस संख्या का अधिक अर्थ हो सकता था क्योंकि सर्वर पर मेमोरी की औसत मात्रा बहुत कम थी।
आजकल, जहां सर्वरों में नियमित रूप से 64GB, 128GB, और अधिक मात्रा में मेमोरी होती है, लगभग हर पांच मिनट में डिस्क से इतना अधिक डेटा पढ़ा जा रहा है, संभवतः एक अपंग प्रदर्शन समस्या का कारण होगा
वास्तव में, जब तक पीएलई 300 या उससे कम पर मँडरा रहा होता है, तब तक आपका सर्वर पहले से ही गंभीर संकट में होता है। पीएलई के इतना कम होने से बहुत पहले आप चिंतित होने लगेंगे।
तो जब आपको चिंतित होना चाहिए तो किस सीमा का उपयोग करना चाहिए?
खैर, बस यही बात है। मैं आपको कोई सीमा नहीं दे सकता, क्योंकि वह संख्या सभी के लिए अलग-अलग होगी। यदि आप वास्तव में, वास्तव में किसी संख्या का उपयोग करना चाहते हैं, तो मेरे सहयोगी जोनाथन केहैयस एक सूत्र के साथ आए:
(जीबी / 4 में बफर पूल मेमोरी) x 300यहां तक कि वह संख्या भी कुछ हद तक मनमानी है, और आपका माइलेज अलग-अलग होगा।
मैं किसी भी संख्या की सिफारिश करना पसंद नहीं करता। मेरी सलाह है कि आप अपने पीएलई को मापें जब प्रदर्शन वांछित स्तर पर हो - यही है आपके द्वारा उपयोग की जाने वाली दहलीज।
तो क्या आप चिंता करना शुरू कर देते हैं जैसे ही पीएलई उस सीमा से नीचे चला जाता है? नहीं। जब पीएलई उस सीमा से नीचे चला जाता है और उस सीमा से नीचे रहता है, या यदि यह तेजी से गिरता है और आप नहीं जानते, तो आपको चिंता होने लगती है।
ऐसा इसलिए है क्योंकि कुछ ऑपरेशन हैं जो PLE ड्रॉप का कारण बनेंगे (उदाहरण के लिए DBCC CHECKDB चलाना) या अनुक्रमणिका पुनर्निर्माण कभी-कभी ऐसा कर सकते हैं) और चिंता का कारण नहीं हैं। लेकिन अगर आपको PLE में बड़ी गिरावट दिखाई देती है और आप नहीं जानते कि इसका क्या कारण है, तो आपको चिंतित होना चाहिए।
आप सोच रहे होंगे कि कैसे DBCC CHECKDB जब यह प्रतिकूल होता है तो पीएलई ड्रॉप का कारण बन सकता है और इसके द्वारा उपयोग किए जाने वाले डेटा के साथ बफर पूल को फ्लश करने से बचने के लिए कड़ी मेहनत करता है (देखें यह ब्लॉग पोस्ट स्पष्टीकरण के लिए)। ऐसा इसलिए है क्योंकि DBCC CHECKDB . के लिए क्वेरी निष्पादन मेमोरी अनुदान क्वेरी ऑप्टिमाइज़र द्वारा गलत गणना की जाती है और इससे बफर पूल के आकार में बड़ी कमी आ सकती है (अनुदान के लिए मेमोरी बफर पूल से चोरी हो जाती है) और इसके परिणामस्वरूप PLE में गिरावट आती है।
आप PLE की निगरानी कैसे करते हैं?
यह मुश्किल सा है। अधिकांश लोग सीधे Buffer Manager के पास जाएंगे PerfMon में प्रदर्शन वस्तु और Page life expectancy की निगरानी करें विरोध करना। क्या यह सही तरीका है? शायद नहीं।
मैं कहूंगा कि आज वहां मौजूद अधिकांश सर्वर NUMA आर्किटेक्चर का उपयोग कर रहे हैं, और इसका आपके PLE की निगरानी करने के तरीके पर गहरा प्रभाव पड़ता है।
जब NUMA शामिल होता है, तो बफर पूल को बफर नोड्स में विभाजित किया जाता है, जिसमें प्रति NUMA नोड में एक बफर नोड होता है जिसे SQL सर्वर 'देख' सकता है। प्रत्येक बफ़र नोड PLE को अलग से ट्रैक करता है और Buffer Manager:Page life expectancy काउंटर बफर नोड पीएलई का औसत है। यदि आप केवल समग्र बफर पूल पीएलई की निगरानी कर रहे हैं, तो बफर नोड्स में से किसी एक पर दबाव औसत द्वारा छुपाया जा सकता है (मैं यहां एक ब्लॉग पोस्ट में इसकी चर्चा करता हूं)।
इसलिए यदि आपका सर्वर NUMA का उपयोग कर रहा है, तो आपको व्यक्तिगत Buffer Node:Page life expectancy की निगरानी करने की आवश्यकता है काउंटर (प्रत्येक NUMA नोड के लिए एक बफ़र नोड प्रदर्शन ऑब्जेक्ट होगा), अन्यथा आप Buffer Manager:Page life expectancy की अच्छी निगरानी कर रहे हैं काउंटर।
SQL संतरी प्रदर्शन सलाहकार जैसे निगरानी उपकरण का उपयोग करना और भी बेहतर है, जो इस काउंटर को डैशबोर्ड के हिस्से के रूप में दिखाएगा, सर्वर पर NUMA नोड्स को ध्यान में रखते हुए, और आपको आसानी से अलर्ट कॉन्फ़िगर करने की अनुमति देगा।
प्रदर्शन सलाहकार का उपयोग करने के उदाहरण
एक NUMA नोड वाले सिस्टम के लिए प्रदर्शन सलाहकार से स्क्रीन कैप्चर का एक उदाहरण नीचे दिया गया है:
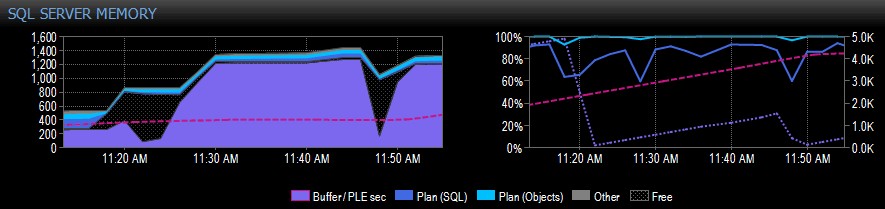
कैप्चर के दाईं ओर, गुलाबी-धराशायी रेखा 10.30 बजे और लगभग 11.20 बजे के बीच पीएलई है - यह 5,000 या उससे अधिक तक लगातार चढ़ रही है, वास्तव में स्वस्थ संख्या। 11.20 बजे से ठीक पहले एक बड़ी गिरावट आती है, और फिर यह 11.45 बजे तक फिर से चढ़ना शुरू कर देती है, जहां यह फिर से गिरती है।
यह आमतौर पर आप देखेंगे कि क्या बफर पूल भरा हुआ है, सभी पृष्ठों का उपयोग किया जा रहा है, और फिर एक क्वेरी चलती है जिसके कारण डिस्क से बड़ी मात्रा में विभिन्न डेटा को पढ़ा जा सकता है, जो पहले से ही स्मृति में है और एक का कारण बनता है पीएलई में भारी गिरावट। अगर आपको नहीं पता था कि ऐसा कुछ किस कारण से हुआ है, तो आप जांच करना चाहेंगे, जैसा कि मैं आगे बताता हूं।
दूसरे उदाहरण के रूप में, नीचे दिया गया स्क्रीन कैप्चर हमारे रिमोट डीबीए क्लाइंट में से एक है जहां सर्वर में दो NUMA नोड्स हैं (आप देख सकते हैं कि दो बैंगनी पीएलई लाइनें हैं), और जहां हम प्रदर्शन सलाहकार का व्यापक रूप से उपयोग करते हैं:

इस क्लाइंट के सर्वर पर, हर सुबह लगभग 5 बजे, एक इंडेक्स मेंटेनेंस और कंसिस्टेंसी चेकिंग जॉब शुरू हो जाती है, जिससे PLE दोनों बफर नोड्स में गिर जाता है। यह अपेक्षित व्यवहार है इसलिए जब तक पीएलई दिन के दौरान फिर से ऊपर उठता है, तब तक जांच करने की कोई आवश्यकता नहीं है।
पीएलई छोड़ने के बारे में आप क्या कर सकते हैं?
अगर पीएलई ड्रॉप का कारण ज्ञात नहीं है, तो आप कई चीजें कर सकते हैं:
- यदि समस्या अभी हो रही है, तो
sys.dm_os_waiting_tasksका उपयोग करके जांच करें कि कौन सी क्वेरीज़ रीड कर रही हैं DMV यह देखने के लिए कि कौन से थ्रेड डिस्क से पृष्ठों के पढ़ने की प्रतीक्षा कर रहे हैं (अर्थात वे जोPAGEIOLATCH_SHकी प्रतीक्षा कर रहे हैं) ), और फिर उन प्रश्नों को ठीक करें। - यदि समस्या अतीत में हुई है, तो sys.dm_exec_query_stats DMV में उच्च संख्या में भौतिक पठन वाले प्रश्नों के लिए देखें, या एक निगरानी उपकरण का उपयोग करें जो आपको वह जानकारी दे सकता है (उदाहरण के लिए प्रदर्शन सलाहकार में शीर्ष SQL दृश्य), और फिर उन प्रश्नों को ठीक करें।
- पीएलई ड्रॉप को शेड्यूल किए गए एजेंट कार्यों के साथ सहसंबंधित करें जो डेटाबेस रखरखाव करते हैं।
sys.dm_exec_query_memory_grantsका उपयोग करके बहुत बड़ी क्वेरी निष्पादन मेमोरी मेमोरी ग्रांट वाली क्वेरी खोजें DMV, और फिर उन प्रश्नों को ठीक करें।
मेरी पिछली पोस्ट यहां #1 और #2 के बारे में अधिक बताती है, और एक सर्वर पर होने वाली प्रतीक्षा की जांच के लिए एक स्क्रिप्ट और उनकी क्वेरी योजनाओं का लिंक यहां है।
"उन प्रश्नों को ठीक करें" इस पोस्ट के दायरे से बाहर है, इसलिए मैं इसे दूसरी बार या पाठक के लिए एक अभ्यास के रूप में छोड़ दूंगा ☺
सारांश
किसी भी अनुशंसित पीएलई सीमा पर विश्वास करने के जाल में न पड़ें जिसे आप ऑनलाइन पढ़ सकते हैं। पीएलई परिवर्तनों पर प्रतिक्रिया करने का सबसे अच्छा तरीका है जब पीएलई आपका . जो कुछ भी नीचे गिर जाता है आराम का स्तर है और वहीं रहता है - वह एक प्रदर्शन समस्या का संकेत जिसकी आपको जांच करनी चाहिए।
श्रृंखला के अगले लेख में, मैं घुटने के बल चलने वाले प्रदर्शन ट्यूनिंग के एक अन्य सामान्य कारण पर चर्चा करूँगा। तब तक, समस्या निवारण के लिए शुभकामनाएँ!