विफलता का महत्व
फेलओवर डेटाबेस प्रशासन के लिए सबसे महत्वपूर्ण डेटाबेस प्रथाओं में से एक है। यह न केवल उत्पादन में बड़े डेटाबेस को प्रबंधित करते समय उपयोगी है, बल्कि यदि आप यह सुनिश्चित करना चाहते हैं कि जब भी आप इसे एक्सेस करते हैं तो आपका सिस्टम हमेशा उपलब्ध रहता है - विशेष रूप से एप्लिकेशन स्तर पर।
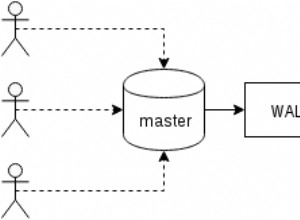
एक विफलता होने से पहले, आपके डेटाबेस इंस्टेंस को कुछ आवश्यकताओं को पूरा करना होगा। वास्तव में, ये आवश्यकताएं उच्च उपलब्धता के लिए बहुत महत्वपूर्ण हैं। आपके डेटाबेस इंस्टेंस को पूरा करने वाली आवश्यकताओं में से एक अतिरेक है। रिडंडेंसी फेलओवर को आगे बढ़ने में सक्षम बनाता है, जिसमें रिडंडेंसी को एक फेलओवर उम्मीदवार के लिए सेटअप किया जाता है जो एक प्रतिकृति (द्वितीयक) नोड हो सकता है या स्टैंडबाय या हॉट-स्टैंडबाय नोड्स के रूप में कार्य करने वाले प्रतिकृतियों के पूल से हो सकता है। उम्मीदवार का चयन या तो मैन्युअल रूप से या स्वचालित रूप से सबसे उन्नत या अप-टू-डेट नोड के आधार पर किया जाता है। आमतौर पर, आप एक हॉट-स्टैंडबाय प्रतिकृति चाहते हैं क्योंकि यह आपके डेटाबेस को डिस्क से इंडेक्स खींचने से बचा सकता है क्योंकि हॉट-स्टैंडबाय अक्सर डेटाबेस बफर पूल में इंडेक्स को पॉप्युलेट करता है।
विफलता वह शब्द है जिसका उपयोग यह वर्णन करने के लिए किया जाता है कि पुनर्प्राप्ति प्रक्रिया हुई है। पुनर्प्राप्ति प्रक्रिया से पहले, यह तब होता है जब एक प्राथमिक (या मास्टर) डेटाबेस नोड क्रैश के बाद, प्राकृतिक आपदाओं के बाद, हार्डवेयर विफलता के बाद विफल हो जाता है, या हो सकता है कि इसे नेटवर्क विभाजन का सामना करना पड़ा हो; ये सबसे आम मामले हैं कि विफलता क्यों हो सकती है। पुनर्प्राप्ति प्रक्रिया आमतौर पर स्वचालित रूप से आगे बढ़ती है और फिर सबसे वांछित और अद्यतित माध्यमिक (प्रतिकृति) की खोज करती है जैसा कि पहले बताया गया है।
उन्नत विफलता
यद्यपि एक विफलता के दौरान पुनर्प्राप्ति प्रक्रिया स्वचालित होती है, कुछ अवसर ऐसे होते हैं जब प्रक्रिया को स्वचालित करना आवश्यक नहीं होता है, और एक मैन्युअल प्रक्रिया को अपनाना पड़ता है। आपके डेटाबेस के पूरे स्टैक को शामिल करने वाली तकनीकों से जुड़ी जटिलता अक्सर मुख्य विचार है - स्वचालित फ़ेलओवर को मैन्युअल फ़ेलओवर के साथ भी मिलाया जा सकता है।
डेटाबेस के प्रबंधन के साथ अधिकांश दिन-प्रतिदिन के विचारों में, स्वचालित विफलता के आसपास की अधिकांश चिंताएं वास्तव में तुच्छ नहीं हैं। समस्या होने पर स्वचालित विफलता को लागू करने और सेटअप करने के लिए यह अक्सर आसान होता है। हालांकि यह आशाजनक लगता है क्योंकि यह जटिलताओं को कवर करता है, उन्नत विफलता तंत्र आता है और इसमें "पूर्व" घटनाएं और "पोस्ट" घटनाएं शामिल होती हैं जो एक विफलता सॉफ़्टवेयर या प्रौद्योगिकी में हुक के रूप में बंधे होते हैं।
ये प्री और पोस्ट इवेंट या तो चेक या कुछ निश्चित कार्रवाइयों के साथ आते हैं, इससे पहले कि यह अंत में फेलओवर के साथ आगे बढ़ सके, और एक फेलओवर होने के बाद, कुछ सफाई यह सुनिश्चित करने के लिए कि फेलओवर आखिरकार एक सफल है एक। सौभाग्य से, ऐसे उपकरण उपलब्ध हैं जो न केवल स्वचालित विफलता की अनुमति देते हैं, बल्कि स्क्रिप्ट हुक को पूर्व और बाद में लागू करने की क्षमता भी प्रदान करते हैं।
इस ब्लॉग में, हम ClusterControl (CC) स्वचालित विफलता का उपयोग करेंगे और बताएंगे कि स्क्रिप्ट से पहले और बाद के हुक का उपयोग कैसे करें और वे किस क्लस्टर पर लागू होते हैं।
ClusterControl प्रतिकृति विफलता
क्लस्टरकंट्रोल फेलओवर मैकेनिज्म एसिंक्रोनस प्रतिकृति पर कुशलता से लागू होता है जो MySQL वेरिएंट (MySQL/Percona Server/MariaDB) पर लागू होता है। यह PostgreSQL/TimescaleDB क्लस्टर पर भी लागू होता है - ClusterControl स्ट्रीमिंग प्रतिकृति का समर्थन करता है। MongoDB और Galera क्लस्टर की अपनी स्वयं की डेटाबेस तकनीक में निर्मित स्वचालित विफलता के लिए अपना तंत्र है। इस बारे में और पढ़ें कि ClusterControl स्वचालित डेटाबेस पुनर्प्राप्ति और फ़ेलओवर कैसे करता है।
ClusterControl फेलओवर तब तक काम नहीं करता जब तक कि नोड और क्लस्टर रिकवरी (ऑटो रिकवरी सक्षम नहीं है)। इसका मतलब है कि ये बटन हरे होने चाहिए।

दस्तावेज बताता है कि इन कॉन्फ़िगरेशन विकल्पों का उपयोग / को सक्षम करने के लिए भी किया जा सकता है। निम्न को अक्षम करें:
| enable_cluster_autorecovery=<बूलियन पूर्णांक> |
|
| enable_node_autorecovery=<बूलियन पूर्णांक> |
|
$ systemctl पुनरारंभ cmon
इस ब्लॉग के लिए, हम मुख्य रूप से प्री/पोस्ट स्क्रिप्ट हुक का उपयोग करने पर ध्यान केंद्रित कर रहे हैं जो अनिवार्य रूप से उन्नत प्रतिकृति विफलता के लिए एक बड़ा लाभ है।
क्लस्टर फेलओवर प्रतिकृति पूर्व/पोस्ट स्क्रिप्ट समर्थन
जैसा कि पहले उल्लेख किया गया है, MySQL वेरिएंट जो एसिंक्रोनस (सेमी-सिंक्रोनस सहित) प्रतिकृति का उपयोग करते हैं और PostgreSQL/TimescaleDB के लिए स्ट्रीमिंग प्रतिकृति इस तंत्र का समर्थन करते हैं। ClusterControl में निम्नलिखित कॉन्फ़िगरेशन विकल्प हैं जिनका उपयोग स्क्रिप्ट के पूर्व और बाद के हुक के लिए किया जा सकता है। मूल रूप से, इन कॉन्फ़िगरेशन विकल्पों को उनकी कॉन्फ़िगरेशन फ़ाइलों के माध्यम से सेट किया जा सकता है या वेब UI के माध्यम से सेट किया जा सकता है (हम इस पर बाद में विचार करेंगे)।
हमारे दस्तावेज़ में कहा गया है कि ये निम्नलिखित कॉन्फ़िगरेशन विकल्प हैं जो स्क्रिप्ट के पूर्व/पोस्ट हुक का उपयोग करके विफलता तंत्र को बदल सकते हैं:
| replication_pre_failover_script= |
|
| replication_post_failover_script= |
|
| replication_post_unsuccessful_failover_script= |
|
तकनीकी रूप से, एक बार जब आप अपनी /etc/cmon.d/cmon_ वैकल्पिक रूप से, आप <अपना क्लस्टर चुनें> → सेटिंग्स → रनटाइम कॉन्फ़िगरेशन पर जाकर कॉन्फ़िगरेशन विकल्प भी सेट कर सकते हैं। नीचे स्क्रीनशॉट देखें: इस दृष्टिकोण के लिए अभी भी cmon सेवा को फिर से शुरू करने की आवश्यकता होगी, इससे पहले कि यह प्रतिबिंबित कर सके स्क्रिप्ट के पूर्व/पोस्ट हुक के लिए इन कॉन्फ़िगरेशन विकल्पों के लिए किए गए परिवर्तन। आदर्श रूप से, प्री/पोस्ट स्क्रिप्ट हुक समर्पित होते हैं जब आपको एक उन्नत फ़ेलओवर की आवश्यकता होती है जिसके लिए ClusterControl आपके डेटाबेस सेटअप की जटिलता का प्रबंधन नहीं कर सकता है। उदाहरण के लिए, यदि आप कड़ी सुरक्षा के साथ अलग-अलग डेटा केंद्र चला रहे हैं और आप यह निर्धारित करना चाहते हैं कि नेटवर्क के अगम्य होने का अलर्ट गलत सकारात्मक अलार्म नहीं है। इसे जांचना है कि क्या प्राथमिक और दास एक दूसरे तक पहुंच सकते हैं और इसके विपरीत और यह क्लस्टर कंट्रोल होस्ट पर जाने वाले डेटाबेस नोड्स से भी पहुंच सकता है। आइए इसे अपने उदाहरण में करते हैं और प्रदर्शित करते हैं कि आप इससे कैसे लाभ उठा सकते हैं। इस उदाहरण में, मैं केवल एक प्राथमिक और एक प्रतिकृति के साथ एक मारियाडीबी प्रतिकृति क्लस्टर का उपयोग कर रहा हूं। विफलता को प्रबंधित करने के लिए ClusterControl द्वारा प्रबंधित। ClusterControl =192.168.40.110 प्राथमिक (debnode5) =192.168.30.50 प्रतिकृति (debnode9) =192.168.30.90 प्राथमिक नोड में, नीचे बताए अनुसार स्क्रिप्ट बनाएं, सुनिश्चित करें कि /opt/pre_failover.sh निष्पादन योग्य है, अर्थात फिर क्रॉन के माध्यम से शामिल होने के लिए इस स्क्रिप्ट का उपयोग करें। इस उदाहरण में, मैंने एक फ़ाइल /etc/cron.d/ccfailover बनाई है और इसमें निम्नलिखित सामग्री है: अपनी प्रतिकृति में, होस्टनाम बदलने के अलावा, प्राथमिक के लिए किए गए निम्न चरणों का उपयोग करें। मेरी प्रतिकृति में मेरे पास जो कुछ है, उसे नीचे देखें: और सुनिश्चित करें कि हमारे क्रॉन में लागू की गई स्क्रिप्ट निष्पादन योग्य है, इस प्रदर्शन में, मेरा क्लस्टर_आईडी 3 है। जैसा कि पहले हमारे दस्तावेज़ीकरण में कहा गया है, यह आवश्यक है कि ये स्क्रिप्ट हमारे सीसी नियंत्रक होस्ट में रहें। तो मेरे /etc/cmon.d/cmon_3.cnf में, मेरे पास निम्नलिखित हैं: जबकि, निम्न "पूर्व" विफलता स्क्रिप्ट निर्धारित करती है कि दोनों नोड सीसी नियंत्रक होस्ट तक पहुंचने में सक्षम थे या नहीं। निम्नलिखित देखें:
अब, प्राथमिक नोड पर नेटवर्क आउटेज का अनुकरण करने का प्रयास करते हैं और देखते हैं कि यह कैसे प्रतिक्रिया देगा। अपने प्राथमिक नोड में, मैं नेटवर्क इंटरफ़ेस को हटाता हूं जिसका उपयोग प्रतिकृति और सीसी नियंत्रक के साथ संचार करने के लिए किया जाता है। असफलता के पहले प्रयास के दौरान, सीसी मेरी पूर्व स्क्रिप्ट चलाने में सक्षम था जो /etc/cmon.d/failover/replication_failover_pre_clus3.sh पर स्थित है। नीचे देखें कि यह कैसे काम करता है: जाहिर है, यह विफल हो जाता है क्योंकि लॉग किया गया टाइमस्टैम्प अभी एक मिनट से अधिक नहीं है या यह कुछ ही सेकंड पहले था कि प्राथमिक अभी भी सीसी नियंत्रक से जुड़ने में सक्षम था। जाहिर है, जब आप वास्तविक परिदृश्य से निपट रहे हों तो यह सही तरीका नहीं है। हालांकि, ClusterControl अपेक्षित रूप से स्क्रिप्ट को पूरी तरह से लागू करने और निष्पादित करने में सक्षम था। अब, क्या होगा अगर यह वास्तव में एक मिनट से अधिक (यानी> 60 सेकंड) तक पहुंच जाए?
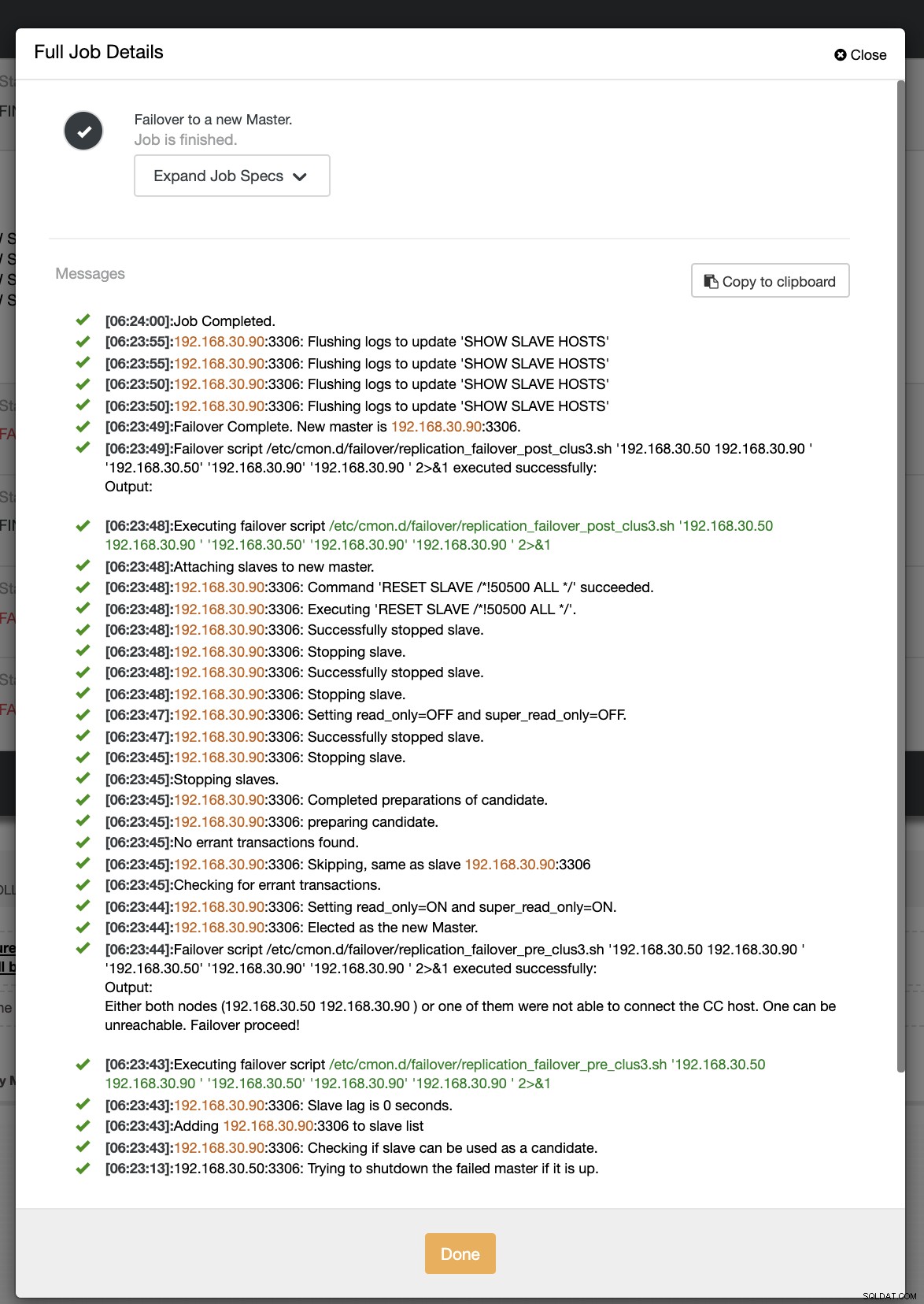
विफलता के हमारे दूसरे प्रयास में, चूंकि टाइमस्टैम्प 60 सेकंड से अधिक तक पहुंच जाता है, तो यह एक वास्तविक सकारात्मक माना जाता है, और इसका मतलब है कि हमें इरादा के अनुसार विफल होना है। सीसी इसे पूरी तरह से निष्पादित करने में सक्षम है और यहां तक कि पोस्ट स्क्रिप्ट को भी निष्पादित करने में सक्षम है। इसे जॉब लॉग में देखा जा सकता है। नीचे स्क्रीनशॉट देखें: यह सत्यापित करना कि मेरी पोस्ट स्क्रिप्ट चलाई गई थी, यह लॉग बनाने में सक्षम थी CC /tmp निर्देशिका में अपेक्षित रूप से फ़ाइल करें, आर्ग के साथ क्लस्टर 3 पर पोस्ट फेलओवर स्क्रिप्ट:192.168.30.50 192.168.30.90 192.168.30.50 192.168.30.90 192.168.30.90 अब, मेरी टोपोलॉजी बदल दी गई है और विफलता सफल रही! आपके पास किसी भी जटिल डेटाबेस सेटअप के लिए, जब एक उन्नत विफलता की आवश्यकता होती है, तो चीजों को प्राप्त करने योग्य बनाने के लिए पूर्व/पोस्ट स्क्रिप्ट बहुत मददगार हो सकती हैं। चूंकि ClusterControl इन सुविधाओं का समर्थन करता है, इसलिए हमने प्रदर्शित किया है कि यह कितना शक्तिशाली और सहायक है। यहां तक कि इसकी सीमाओं के साथ, विशेष रूप से उत्पादन वातावरण में चीजों को प्राप्त करने योग्य और उपयोगी बनाने के हमेशा तरीके होते हैं।$ systemctl restart cmon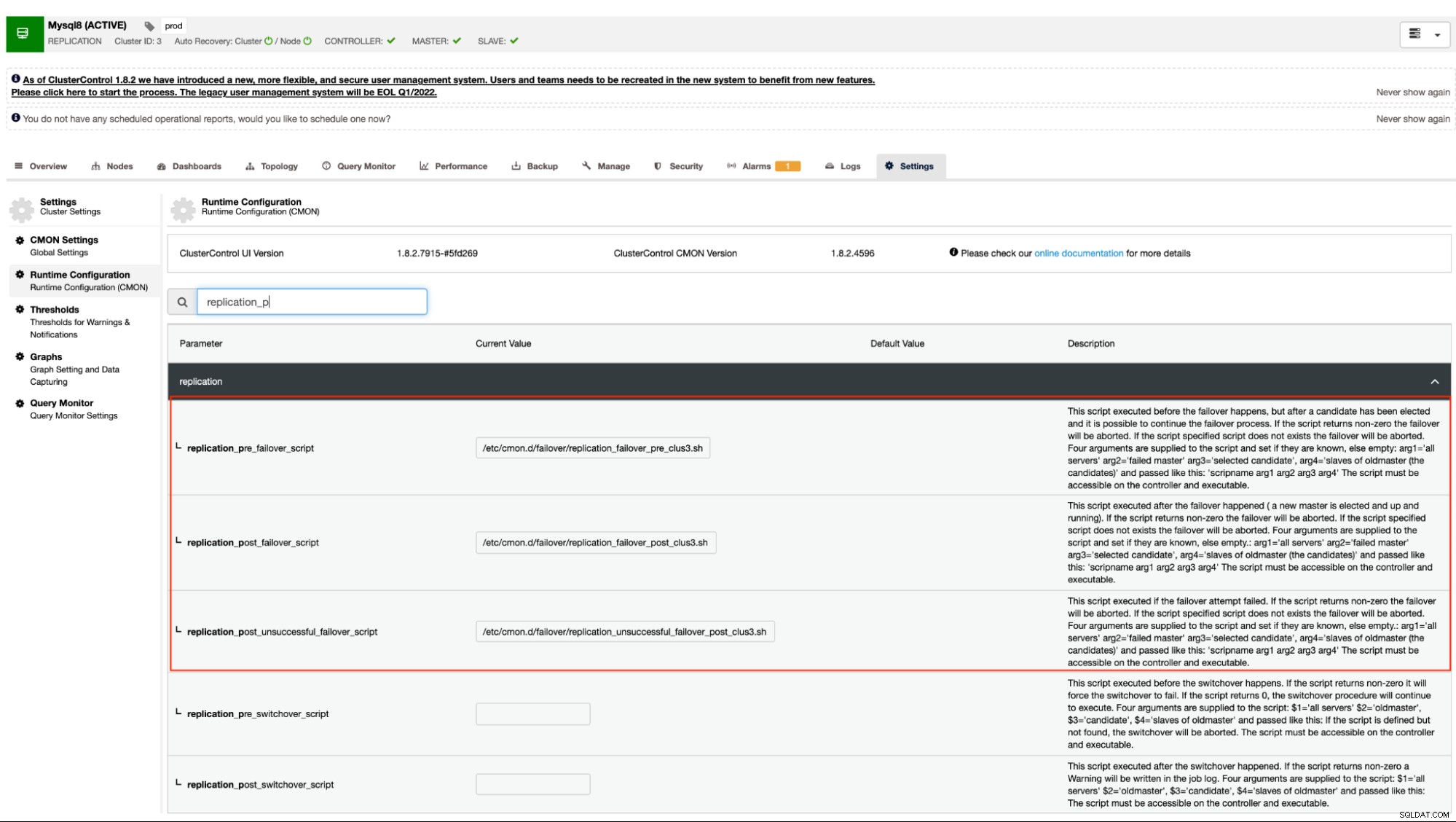
पूर्व/पोस्ट स्क्रिप्ट हुक का उदाहरण
सर्वर विवरण और स्क्रिप्ट
example@sqldat.com:~# cat /opt/pre_failover.sh
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat >> /tmp/debnode5.tmp"$ chmod +x /opt/pre_failover.shexample@sqldat.com:~# cat /etc/cron.d/ccfailover
#!/bin/bash
* * * * * vagrant /opt/pre_failover.shexample@sqldat.com:~# tail -n+1 /etc/cron.d/ccfailover /opt/pre_failover.sh
==> /etc/cron.d/ccfailover <==
#!/bin/bash
* * * * * vagrant /opt/pre_failover.sh
==> /opt/pre_failover.sh <==
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat > /tmp/debnode9.tmp"example@sqldat.com:~# ls -alth /opt/pre_failover.sh
-rwxr-xr-x 1 root root 104 Jun 14 05:09 /opt/pre_failover.shClusterControl प्री/पोस्ट स्क्रिप्ट
[example@sqldat.com cmon.d]# tail -n3 /etc/cmon.d/cmon_3.cnf
replication_pre_failover_script = /etc/cmon.d/failover/replication_failover_pre_clus3.sh
replication_post_failover_script = /etc/cmon.d/failover/replication_failover_post_clus3.sh
replication_post_unsuccessful_failover_script = /etc/cmon.d/failover/replication_unsuccessful_failover_post_clus3.sh[example@sqldat.com cmon.d]# tail -n+1 /etc/cmon.d/failover/replication_failover_pre_clus3.sh
#!/bin/bash
arg1=$1
debnode5_tstamp=$(tail /tmp/debnode5.tmp)
debnode9_tstamp=$(tail /tmp/debnode9.tmp)
cc_tstamp=$(date -u +%s)
diff_debnode5=$(expr $cc_tstamp - $debnode5_tstamp)
diff_debnode9=$(expr $cc_tstamp - $debnode5_tstamp)
if [[ "$diff_debnode5" -le 60 && "$diff_debnode9" -le 60 ]]; then
echo "failover cannot proceed. It's just a false alarm. Checkout the firewall in your CC host";
exit 1;
elif [[ "$diff_debnode5" -gt 60 || "$diff_debnode9" -gt 60 ]]; then
echo "Either both nodes ($arg1) or one of them were not able to connect the CC host. One can be unreachable. Failover proceed!";
exit 0;
else
echo "false alarm. Failover discarded!"
exit 1;
fi
Whereas my post scripts just simply echoes and redirects the output to a file, just for the test.
[example@sqldat.com failover]# tail -n+1 replication_*_post*3.sh
==> replication_failover_post_clus3.sh <==
#!/bin/bash
echo "post failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_failover_script_cid3.txt
==> replication_unsuccessful_failover_post_clus3.sh <==
#!/bin/bash
echo "post unsuccessful failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_unsuccessful_failover_script_cid3.txtविफलता का प्रदर्शन करें
example@sqldat.com:~# ip link set enp0s8 down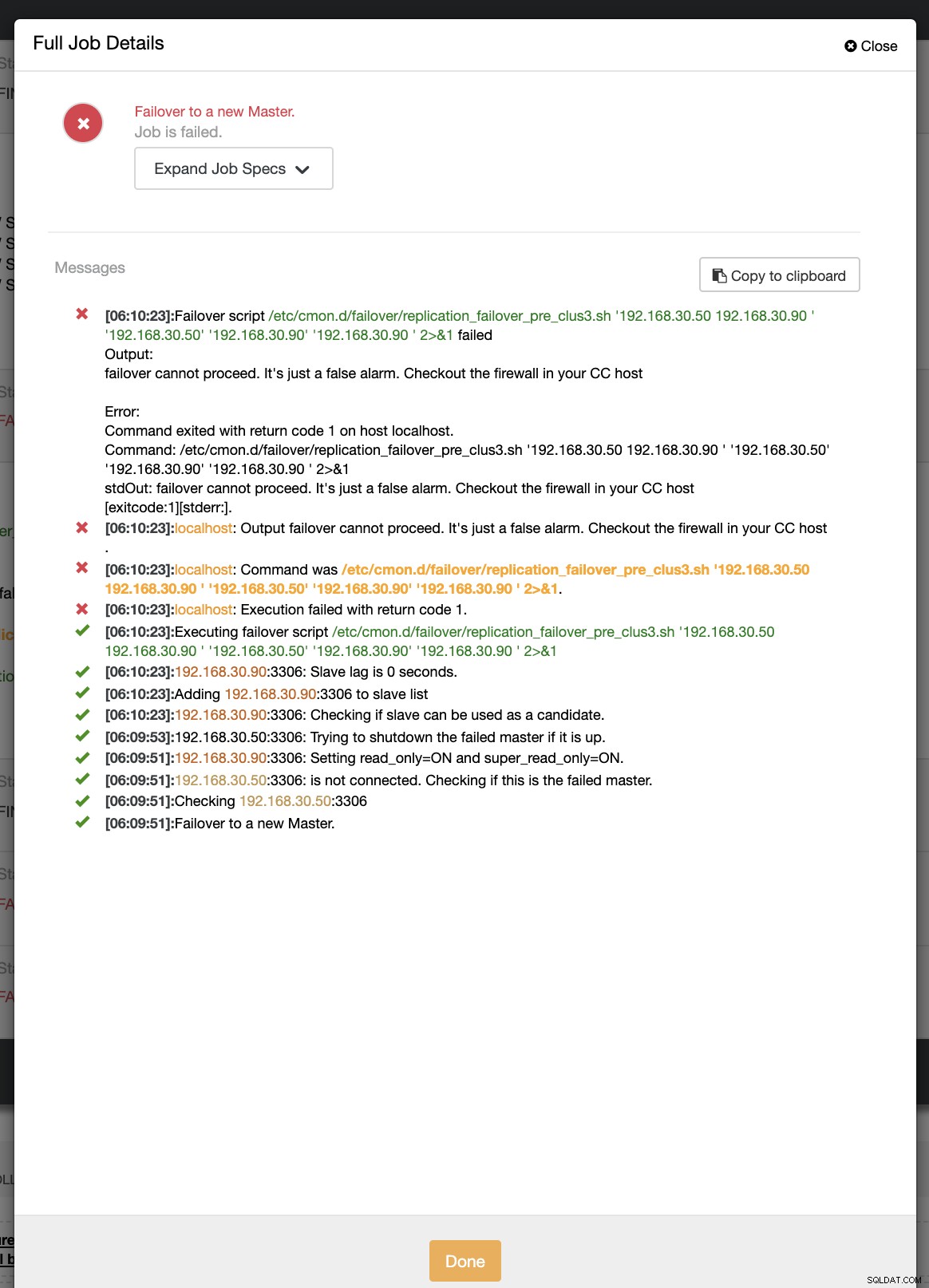
[example@sqldat.com tmp]# cat /tmp/post_failover_script_cid3.txt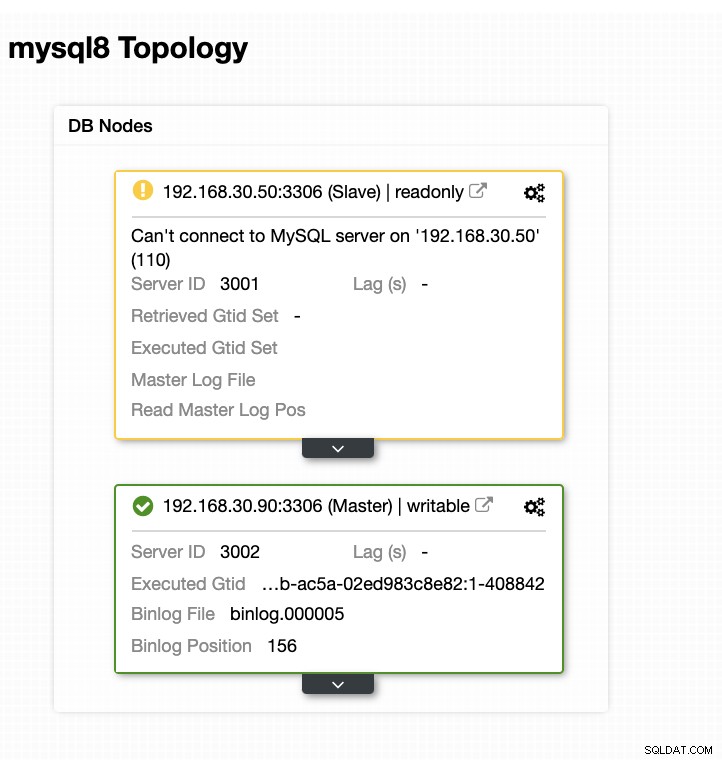
निष्कर्ष