Hadoop की वास्तुकला का अन्वेषण करें, जो बड़े पैमाने पर डेटा को संग्रहीत और संसाधित करने के लिए सबसे अधिक अपनाया जाने वाला ढांचा है।
इस लेख में, हम Hadoop आर्किटेक्चर का अध्ययन करेंगे। लेख Hadoop आर्किटेक्चर और Hadoop आर्किटेक्चर के घटकों की व्याख्या करता है जो HDFS, MapReduce और YARN हैं। लेख में, हम Hadoop आर्किटेक्चर आरेख के साथ-साथ Hadoop आर्किटेक्चर के बारे में विस्तार से जानेंगे।
आइए अब Hadoop आर्किटेक्चर से शुरुआत करते हैं।
Hadoop आर्किटेक्चर
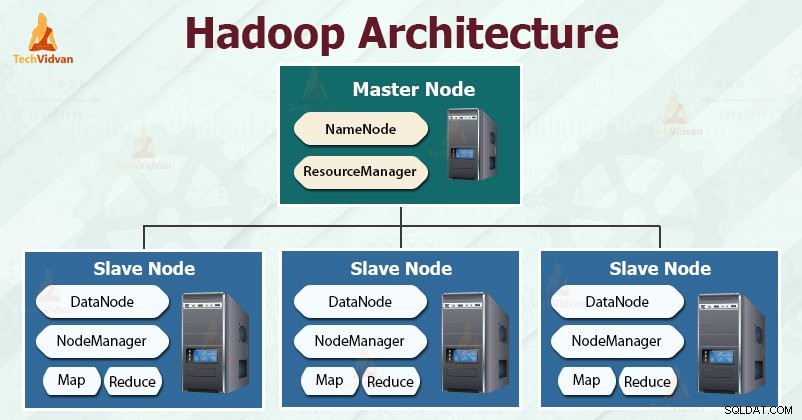
Hadoop को डिजाइन करने का लक्ष्य एक सस्ता, विश्वसनीय और स्केलेबल ढांचा विकसित करना है जो बढ़ते बड़े डेटा को संग्रहीत और विश्लेषण करता है।
Apache Hadoop एक सॉफ्टवेयर फ्रेमवर्क है जिसे Apache Software Foundation द्वारा विभिन्न आकारों और प्रारूपों के बड़े डेटासेट को संग्रहीत और संसाधित करने के लिए डिज़ाइन किया गया है।
Hadoop मास्टर-दास . का अनुसरण करता है बड़ी मात्रा में डेटा को प्रभावी ढंग से संग्रहीत और संसाधित करने के लिए वास्तुकला। मास्टर नोड्स स्लेव नोड्स को कार्य सौंपते हैं।
दास नोड्स वास्तविक डेटा को संग्रहीत करने और वास्तविक गणना/प्रसंस्करण करने के लिए ज़िम्मेदार हैं। मास्टर नोड मेटाडेटा को संग्रहीत करने और क्लस्टर में संसाधनों के प्रबंधन के लिए जिम्मेदार हैं।
स्लेव नोड वास्तविक व्यावसायिक डेटा संग्रहीत करते हैं, जबकि मास्टर मेटाडेटा संग्रहीत करता है।
Hadoop आर्किटेक्चर में तीन परतें शामिल हैं। वे हैं:
- भंडारण परत (HDFS)
- संसाधन प्रबंधन परत (YARN)
- प्रसंस्करण परत (MapReduce)
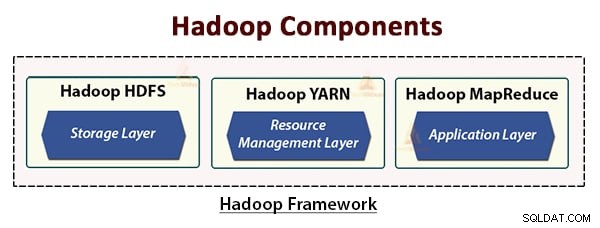
HDFS, YARN और MapReduce Hadoop फ्रेमवर्क के मुख्य घटक हैं।
आइए अब इन तीन मुख्य घटकों का विस्तार से अध्ययन करें।
<एच4>1. एचडीएफएस
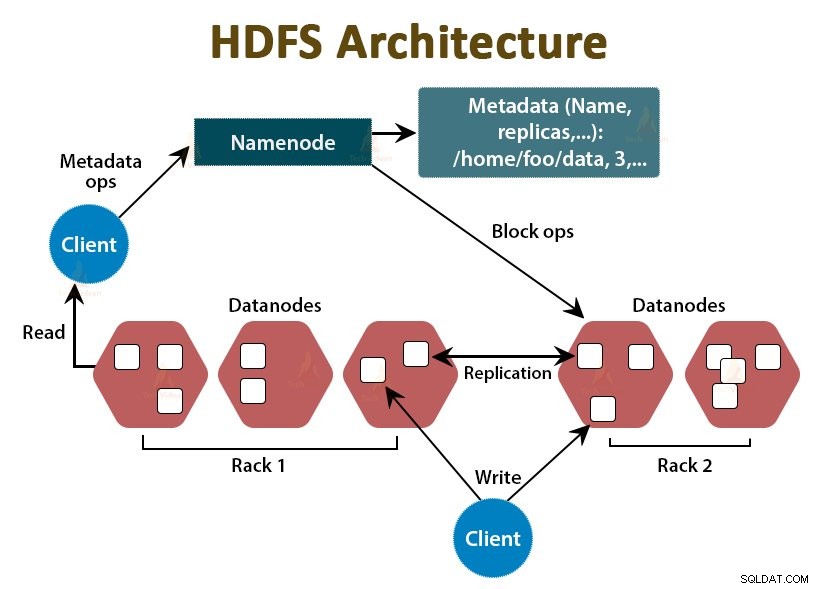
HDFS Hadoop डिस्ट्रिब्यूटेड फाइल सिस्टम है , जो सस्ते कमोडिटी हार्डवेयर पर चलता है। यह Hadoop के लिए स्टोरेज लेयर है। HDFS में फ़ाइलें ब्लॉक-आकार के टुकड़ों में विभाजित होती हैं जिन्हें डेटा ब्लॉक कहा जाता है।
इन ब्लॉकों को तब क्लस्टर में स्लेव नोड्स पर संग्रहीत किया जाता है। ब्लॉक का आकार डिफ़ॉल्ट रूप से 128 एमबी है, जिसे हम अपनी आवश्यकताओं के अनुसार कॉन्फ़िगर कर सकते हैं।
Hadoop की तरह, HDFS भी मास्टर-स्लेव आर्किटेक्चर का अनुसरण करता है। इसमें दो डेमॉन शामिल हैं- NameNode और DataNode। NameNode मास्टर डेमॉन है जो मास्टर नोड पर चलता है। DataNodes स्लेव डेमॉन है जो स्लेव नोड्स पर चलता है।
नामनोड
NameNode फाइल सिस्टम मेटाडेटा को स्टोर करता है, यानी फाइलों के नाम, फाइल के ब्लॉक के बारे में जानकारी, ब्लॉक लोकेशन, परमिशन आदि। यह डेटानोड्स को मैनेज करता है।
डेटानोड
DataNodes दास नोड हैं जो वास्तविक व्यावसायिक डेटा संग्रहीत करते हैं। यह NameNode निर्देशों के आधार पर क्लाइंट को पढ़ने/लिखने के अनुरोधों को पूरा करता है।
DataNodes फ़ाइलों के ब्लॉक को संग्रहीत करता है, और NameNode मेटाडेटा जैसे ब्लॉक स्थान, अनुमति, आदि को संग्रहीत करता है।
<एच4>2. MapReduce
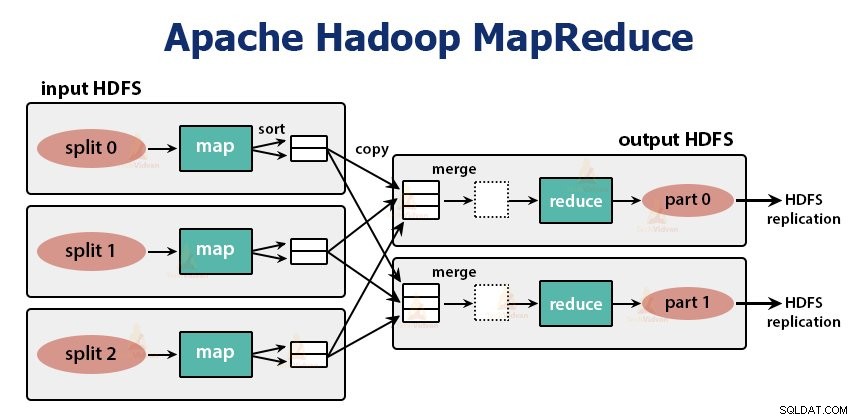
यह Hadoop की डेटा प्रोसेसिंग लेयर है। यह अनुप्रयोगों को लिखने के लिए एक सॉफ्टवेयर ढांचा है जो कमोडिटी हार्डवेयर के क्लस्टर पर समानांतर में बड़ी मात्रा में डेटा (टेराबाइट्स से पेटाबाइट्स रेंज में) को संसाधित करता है।
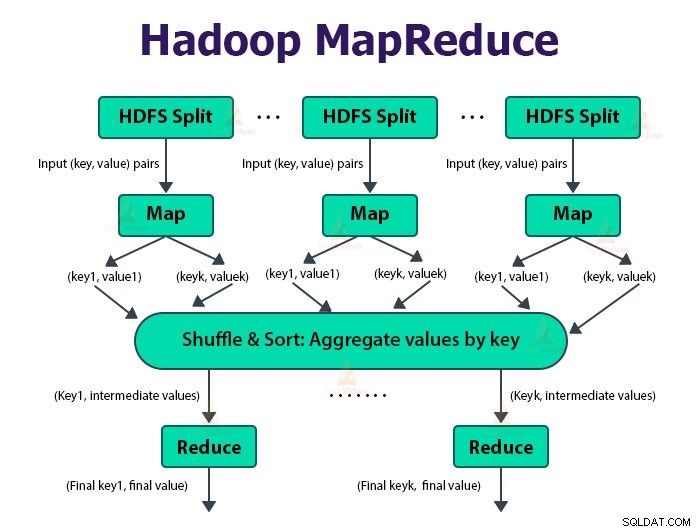
MapReduce ढांचा <कुंजी, मान> जोड़े पर काम करता है।
MapReduce जॉब उस कार्य की इकाई है जिसे क्लाइंट करना चाहता है। MapReduce जॉब में मुख्य रूप से इनपुट डेटा, MapReduce प्रोग्राम और कॉन्फ़िगरेशन जानकारी शामिल होती है। Hadoop MapReduce नौकरियों को दो प्रकार के कार्यों में विभाजित करके चलाता है जो कि मानचित्र कार्य . हैं और कार्यों को कम करें . Hadoop YARN ने इन कार्यों को निर्धारित किया है और क्लस्टर में नोड्स पर चलाए जा रहे हैं।
कुछ प्रतिकूल परिस्थितियों के कारण, यदि कार्य विफल हो जाते हैं, तो वे स्वचालित रूप से एक अलग नोड पर पुनर्निर्धारित हो जाएंगे।
उपयोगकर्ता मानचित्र फ़ंक्शन को परिभाषित करता है और फ़ंक्शन कम करें MapReduce कार्य करने के लिए।
मैप फंक्शन का इनपुट और रिड्यूस फंक्शन से आउटपुट की, वैल्यू पेयर है।
मानचित्र कार्यों का कार्य डेटा को लोड, पार्स, फ़िल्टर और रूपांतरित करना है। मानचित्र कार्य का आउटपुट कार्य को कम करने के लिए इनपुट है। कार्य को कम करें फिर मानचित्र कार्य के आउटपुट पर समूहीकरण और एकत्रीकरण करता है।
MapReduce कार्य दो चरणों में किया जाता है-
<एच5>1. मानचित्र चरण<मजबूत>ए. रिकॉर्ड रीडर
Hadoop MapReduce जॉब में इनपुट को निश्चित आकार के स्प्लिट्स में विभाजित करता है जिसे इनपुट स्प्लिट्स कहा जाता है या बंट जाता है। RecordReader इन विभाजनों को रिकॉर्ड में बदल देता है और डेटा को रिकॉर्ड में पार्स करता है लेकिन यह रिकॉर्ड को स्वयं पार्स नहीं करता है। रिकॉर्ड रीडर मैपर फ़ंक्शन को की-वैल्यू पेयर में डेटा प्रदान करता है।
<मजबूत>बी. नक्शा
मानचित्र चरण में, Hadoop एक मानचित्र कार्य बनाता है जो इनपुट विभाजन में प्रत्येक रिकॉर्ड के लिए मानचित्र फ़ंक्शन नामक एक उपयोगकर्ता-परिभाषित फ़ंक्शन चलाता है। यह मानचित्र कार्य आउटपुट के रूप में शून्य या एकाधिक मध्यवर्ती कुंजी-मान जोड़े उत्पन्न करता है।
नक्शा कार्य अपने आउटपुट को स्थानीय डिस्क पर लिखता है। यह मध्यवर्ती आउटपुट तब कम कार्यों द्वारा संसाधित किया जाता है जो अंतिम आउटपुट का उत्पादन करने के लिए उपयोगकर्ता द्वारा परिभाषित कम फ़ंक्शन चलाते हैं। एक बार कार्य पूरा हो जाने पर, मानचित्र आउटपुट फ़्लश आउट हो जाता है।
<मजबूत>सी. संयोजक
सिंगल रिड्यूस टास्क का इनपुट सभी मैपर का आउटपुट है जो सभी मैप टास्क से आउटपुट होता है। Hadoop उपयोगकर्ता को एक संयोजन फ़ंक्शन को परिभाषित करने की अनुमति देता है जो मानचित्र आउटपुट पर चलता है।
संयोजक रेड्यूसर को पास करने से पहले डेटा को मानचित्र चरण में समूहित करता है। यह मैप फंक्शन के आउटपुट को जोड़ती है जिसे बाद में रिड्यूस फंक्शन के इनपुट के रूप में पास किया जाता है।
<मजबूत>डी. विभाजनकर्ता
जब कई रिड्यूसर होते हैं तो मैप कार्य उनके आउटपुट को विभाजित करता है, प्रत्येक प्रत्येक कम करने वाले कार्य के लिए एक विभाजन बनाता है। प्रत्येक विभाजन में, कई कुंजियाँ और उनके संबद्ध मान हो सकते हैं लेकिन किसी भी कुंजी के रिकॉर्ड सभी एक ही विभाजन में होते हैं।
Hadoop उपयोगकर्ताओं को उपयोगकर्ता-परिभाषित विभाजन फ़ंक्शन निर्दिष्ट करके विभाजन को नियंत्रित करने की अनुमति देता है। आम तौर पर, एक डिफ़ॉल्ट पार्टिशनर होता है जो हैश फ़ंक्शन का उपयोग करके कुंजियों को बकेट करता है।
2. चरण कम करें:
कार्य को कम करने के विभिन्न चरण इस प्रकार हैं:
<मजबूत>ए. क्रमबद्ध करें और शफल करें:
रेड्यूसर कार्य एक फेरबदल और क्रमबद्ध कदम से शुरू होता है। इस चरण का मुख्य उद्देश्य समान कुंजियों को एक साथ एकत्रित करना है। सॉर्ट और शफल चरण उस डेटा को डाउनलोड करता है जो विभाजनकर्ता द्वारा उस नोड पर लिखा जाता है जहां रेड्यूसर चल रहा है।
यह प्रत्येक डेटा टुकड़े को एक बड़ी डेटा सूची में सॉर्ट करता है। MapReduce ढांचा इस प्रकार का प्रदर्शन करता है और फेरबदल करता है ताकि हम इसे कम करने के कार्य में आसानी से पुनरावृति कर सकें।
क्रमबद्ध और फेरबदल ढांचे द्वारा स्वचालित रूप से किया जाता है। तुलनित्र वस्तु के माध्यम से डेवलपर इस पर नियंत्रण कर सकता है कि कुंजियाँ कैसे क्रमबद्ध और समूहीकृत होती हैं।
<मजबूत>बी. कम करें:
रेड्यूसर जो उपयोगकर्ता द्वारा परिभाषित कम करने का कार्य है, प्रति कुंजी समूह में एक बार प्रदर्शन करता है। रेड्यूसर डेटा को कई अलग-अलग तरीकों से फ़िल्टर, एकत्र और संयोजित करता है। एक बार कम करने का कार्य पूरा हो जाने के बाद, यह OutputFormat को शून्य या अधिक कुंजी-मूल्य जोड़े देता है। रिड्यूस टास्क आउटपुट को Hadoop HDFS में स्टोर किया जाता है।
<मजबूत>सी. आउटपुटफ़ॉर्मेट
यह रेड्यूसर आउटपुट लेता है और इसे रिकॉर्डवाइटर द्वारा एचडीएफएस फाइल में लिखता है। डिफ़ॉल्ट रूप से, यह कुंजी, मान को एक टैब और प्रत्येक रिकॉर्ड को एक न्यूलाइन वर्ण द्वारा अलग करता है।
YARN का अर्थ है फिर भी एक अन्य संसाधन वार्ताकार . यह Hadoop की संसाधन प्रबंधन परत है। इसे Hadoop 2 में पेश किया गया था।
YARN को कार्य शेड्यूलिंग और संसाधन प्रबंधन की कार्यात्मकताओं को अलग-अलग डेमॉन में विभाजित करने के विचार के साथ डिज़ाइन किया गया है। मूल विचार यह है कि प्रति आवेदन एक वैश्विक संसाधन प्रबंधक और एप्लिकेशन मास्टर होना चाहिए जहां आवेदन एक ही नौकरी या नौकरियों का डीएजी हो सकता है।
YARN में रिसोर्समैनेजर, NodeManager, और प्रति-एप्लिकेशन एप्लिकेशनमास्टर शामिल हैं।
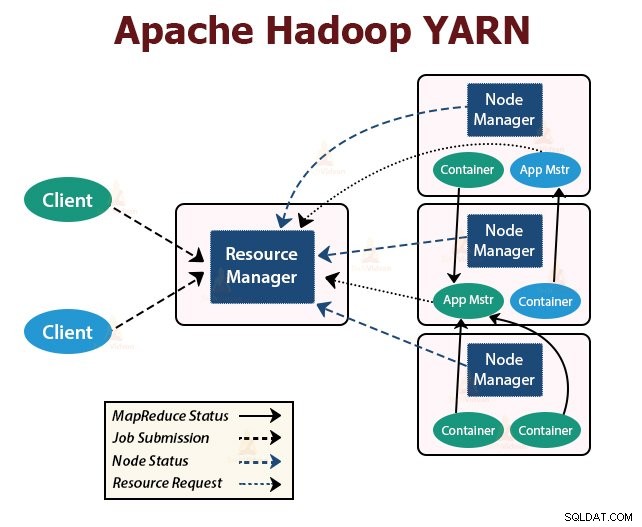
यह क्लस्टर में सभी अनुप्रयोगों के बीच संसाधनों की मध्यस्थता करता है।
इसके दो मुख्य घटक हैं जो शेड्यूलर और एप्लिकेशन मैनेजर हैं।
<मजबूत>ए. अनुसूचक
- अनुसूचक क्षमता, कतार आदि को ध्यान में रखते हुए क्लस्टर में चल रहे विभिन्न अनुप्रयोगों के लिए संसाधन आवंटित करता है।
- यह एक शुद्ध अनुसूचक है। यह एप्लिकेशन की स्थिति की निगरानी या ट्रैक नहीं करता है।
- अनुसूचक विफल कार्यों के पुनरारंभ होने की गारंटी नहीं देता है जो या तो एप्लिकेशन विफलता या हार्डवेयर विफलता के कारण विफल हो गए हैं।
- यह अनुप्रयोगों की संसाधन आवश्यकताओं के आधार पर शेड्यूलिंग करता है।
<मजबूत>बी. एप्लिकेशन मैनेजर
- जॉब सबमिशन स्वीकार करने के लिए वे जिम्मेदार हैं।
- एप्लिकेशन प्रबंधक एप्लिकेशन-विशिष्ट एप्लिकेशनमास्टर को निष्पादित करने के लिए पहले कंटेनर पर बातचीत करता है।
- वे विफलता पर एप्लिकेशनमास्टर कंटेनर को पुनरारंभ करने के लिए सेवा प्रदान करते हैं।
- प्रति-आवेदन ApplicationMaster शेड्यूलर से कंटेनरों पर बातचीत करने के लिए जिम्मेदार है। यह उनकी स्थिति और प्रगति को ट्रैक और मॉनिटर करता है।
2. नोड प्रबंधक:
NodeManager दास नोड्स पर चलता है। यह कंटेनरों के लिए ज़िम्मेदार है, मशीन संसाधन उपयोग की निगरानी करना जो सीपीयू, मेमोरी, डिस्क, नेटवर्क उपयोग है, और संसाधन प्रबंधक या शेड्यूलर को इसकी रिपोर्ट करना है।
<एच4>3. एप्लिकेशनमास्टर:प्रति-आवेदन ApplicationMaster एक ढांचा-विशिष्ट पुस्तकालय है। यह संसाधन प्रबंधक से संसाधनों पर बातचीत करने के लिए जिम्मेदार है। यह कार्यों के निष्पादन और निगरानी के लिए NodeManager(s) के साथ काम करता है।
सारांश
इस लेख में, हमने Hadoop आर्किटेक्चर का अध्ययन किया है। Hadoop मास्टर-स्लेव टोपोलॉजी का अनुसरण करता है। मास्टर नोड्स दास नोड्स को कार्य सौंपते हैं। आर्किटेक्चर में तीन परतें शामिल हैं जो HDFS, YARN और MapReduce हैं।
HDFS बड़े डेटा को संग्रहीत करने के लिए Hadoop में वितरित फ़ाइल सिस्टम है। MapReduce एक वितरित तरीके से Hadoop क्लस्टर में विशाल डेटा को संसाधित करने के लिए प्रसंस्करण ढांचा है। YARN क्लस्टर में अनुप्रयोगों के बीच संसाधनों के प्रबंधन के लिए जिम्मेदार है।
HDFS डेमॉन NameNode और YARN डेमॉन रिसोर्समैनेजर Hadoop क्लस्टर में मास्टर नोड पर चलते हैं। HDFS डेमॉन DataNode और YARN NodeManager स्लेव नोड्स पर चलते हैं।
HDFS और MapReduce फ्रेमवर्क नोड्स के एक ही सेट पर चलते हैं, जिसके परिणामस्वरूप क्लस्टर में बहुत अधिक समग्र बैंडविड्थ होती है।
सीखते रहें!!



