MySQL प्रतिकृति के लिए स्वचालित विफलता कई वर्षों से बहस का विषय रही है।
क्या यह अच्छी बात है या बुरी बात?
MySQL की दुनिया में लंबी मेमोरी वाले लोगों के लिए, वे 2012 में GitHub आउटेज को याद कर सकते हैं, जो मुख्य रूप से गलत निर्णय लेने वाले सॉफ़्टवेयर के कारण हुआ था।
GitHub तब MySQL प्रतिकृति, Corosync, Pacemaker और Percona प्रतिकृति प्रबंधक के कॉम्बो में चला गया था। पीआरएम ने मास्टर पर स्वास्थ्य जांच में विफल रहने के बाद एक विफलता करने का फैसला किया, जो एक स्कीमा माइग्रेशन के दौरान अतिभारित था। एक नए मास्टर का चयन किया गया था, लेकिन ठंडे कैश के कारण इसने खराब प्रदर्शन किया। व्यस्त साइट से उच्च क्वेरी लोड के कारण PRM दिल की धड़कन फिर से कोल्ड मास्टर पर विफल हो गई, और PRM ने मूल मास्टर के लिए एक और विफलता को ट्रिगर किया। और समस्याएं बस जारी रहीं, जैसा कि नीचे संक्षेप में बताया गया है।
 स्रोत:पेरकोना लाइव 2013 में हेनरिक इंगो और मासिमो ब्रिग्नोली का
स्रोत:पेरकोना लाइव 2013 में हेनरिक इंगो और मासिमो ब्रिग्नोली का कुछ वर्षों में तेजी से आगे बढ़ें और MySQL प्रतिकृति और स्वचालित विफलता के प्रबंधन के लिए GitHub एक बहुत ही परिष्कृत ढांचे के साथ वापस आ गया है! जैसा कि श्लोमी नोच कहते हैं:
"उस प्रभाव के लिए, हम स्वचालित मास्टर विफलताओं को नियोजित करते हैं। एक असफल मास्टर को जगाने और ठीक करने में एक मानव को लगने वाला समय उपलब्धता की हमारी अपेक्षा से परे है, और इस तरह के फेलओवर को संचालित करना कभी-कभी गैर-तुच्छ होता है। हम उम्मीद करते हैं कि मास्टर विफलताओं का स्वचालित रूप से पता लगाया जाएगा और 30 सेकंड या उससे कम समय में पुनर्प्राप्त किया जाएगा, और हम उम्मीद करते हैं कि विफलता के परिणामस्वरूप उपलब्ध मेजबानों का न्यूनतम नुकसान होगा।"
अधिकांश कंपनियां गिटहब नहीं हैं, लेकिन कोई यह तर्क दे सकता है कि कोई भी कंपनी आउटेज पसंद नहीं करती है। आउटेज किसी भी व्यवसाय के लिए विघटनकारी होते हैं, और उनमें पैसा भी खर्च होता है। मेरा अनुमान है कि ज्यादातर कंपनियां शायद चाहती हैं कि उनके पास किसी प्रकार का स्वचालित विफलता हो, और इसे लागू न करने के कारण शायद मौजूदा समाधानों की जटिलता, ऐसे समाधानों को लागू करने में क्षमता की कमी, या सॉफ़्टवेयर में विश्वास की कमी है। इतना महत्वपूर्ण निर्णय।
MHA, MMM, MRM, mysqlfailover, Orchestrator और ClusterControl सहित (और इन्हीं तक सीमित नहीं) सहित कई स्वचालित फ़ेलओवर समाधान उपलब्ध हैं। उनमें से कुछ कई वर्षों से बाजार में हैं, अन्य हाल ही में हैं। यह एक अच्छा संकेत है, कई समाधानों का मतलब है कि बाजार है और लोग समस्या का समाधान करने की कोशिश कर रहे हैं।
जब हमने ClusterControl में स्वचालित फ़ेलओवर डिज़ाइन किया, तो हमने कुछ मार्गदर्शक सिद्धांतों का उपयोग किया:
-
सुनिश्चित करें कि आपके विफल होने से पहले मास्टर वास्तव में मर चुका है
नेटवर्क विभाजन के मामले में, जहां फ़ेलओवर सॉफ़्टवेयर मास्टर के साथ संपर्क खो देता है, वह इसे देखना बंद कर देगा। लेकिन हो सकता है कि मास्टर अच्छी तरह से काम कर रहा हो और बाकी प्रतिकृति टोपोलॉजी द्वारा देखा जा सकता है।
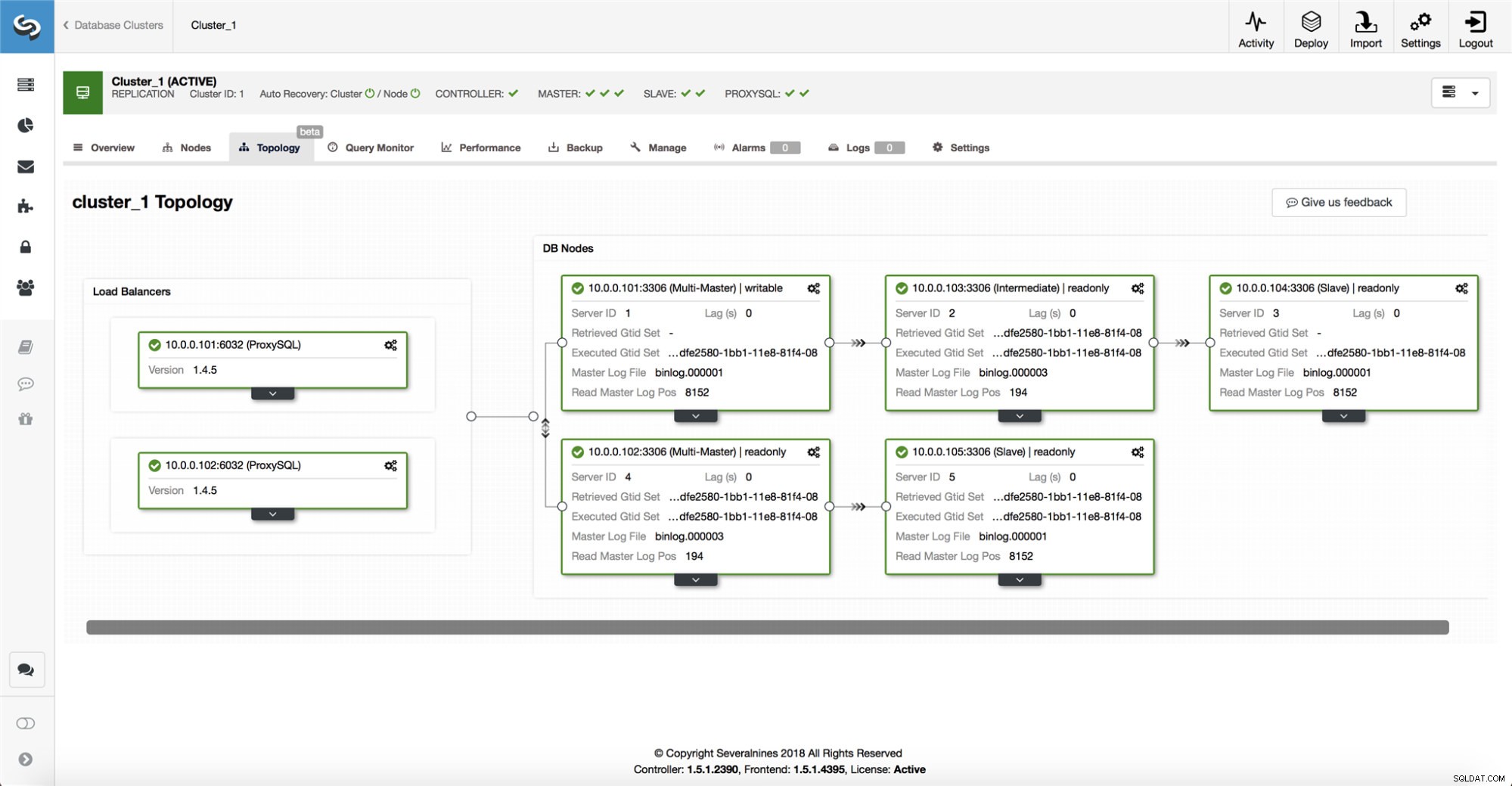
ClusterControl सभी डेटाबेस नोड्स के साथ-साथ उपयोग किए गए किसी भी डेटाबेस प्रॉक्सी/लोड बैलेंसर से जानकारी एकत्र करता है, और फिर टोपोलॉजी का प्रतिनिधित्व बनाता है। यदि दास मास्टर को देख सकते हैं, और न ही क्लस्टर कंट्रोल मास्टर की स्थिति के बारे में 100% सुनिश्चित नहीं है, तो यह विफल होने का प्रयास नहीं करेगा।
ClusterControl सेटअप की टोपोलॉजी के साथ-साथ विभिन्न नोड्स की स्थिति की कल्पना करना भी आसान बनाता है (यह सिस्टम की स्थिति के बारे में क्लस्टरकंट्रोल की समझ है, जो इसके द्वारा एकत्रित की गई जानकारी के आधार पर है)।
-
केवल एक बार विफलता
फड़फड़ाने के बारे में बहुत कुछ लिखा गया है। यदि उपलब्धता उपकरण कई विफलताओं को करने का निर्णय लेता है तो यह बहुत गड़बड़ हो सकता है। यह खतरनाक स्थिति है। चुने गए प्रत्येक मास्टर, चाहे वह मास्टर भूमिका निभाने की अवधि कितनी भी संक्षिप्त क्यों न हो, हो सकता है कि परिवर्तनों के अपने सेट हों जिन्हें किसी भी सर्वर पर कभी दोहराया नहीं गया था। तो हो सकता है कि आप सभी चुने हुए गुरुओं के बीच असंगति के साथ समाप्त हो जाएं।
-
असंगत दास को विफल न करें
स्वामी के रूप में प्रचार करने के लिए दास का चयन करते समय, हम सुनिश्चित करते हैं कि दास में विसंगतियां न हों, उदा। गलत लेनदेन, क्योंकि यह प्रतिकृति को बहुत अच्छी तरह से तोड़ सकता है।
-
केवल मास्टर को लिखें
प्रतिकृति गुरु से दास तक जाती है। एक दास को सीधे लिखने से एक डायवर्जिंग डेटासेट बन जाएगा, और यह समस्या का एक संभावित स्रोत हो सकता है। हम MySQL या MariaDB के हाल के संस्करणों में दासों को केवल read_only, और super_read_only पर सेट करते हैं। हम एक लोड बैलेंसर के उपयोग की भी सलाह देते हैं, जैसे, प्रॉक्सीएसक्यूएल या मैक्सस्केल, अंतर्निहित डेटाबेस टोपोलॉजी और इसमें किसी भी बदलाव से एप्लिकेशन परत को ढालने के लिए। लोड बैलेंसर वर्तमान मास्टर पर लिखने को भी लागू करता है।
-
असफल मास्टर को स्वचालित रूप से पुनर्प्राप्त न करें
यदि मास्टर विफल हो गया है और एक नया मास्टर चुना गया है, तो ClusterControl विफल मास्टर को पुनर्प्राप्त करने का प्रयास नहीं करेगा। क्यों? उस सर्वर में डेटा हो सकता है जिसे अभी तक दोहराया नहीं गया है, और व्यवस्थापक को विफलता में कुछ जांच करने की आवश्यकता होगी। ठीक है, आप अभी भी विफल मास्टर पर डेटा को मिटाने के लिए क्लस्टरकंट्रोल को कॉन्फ़िगर कर सकते हैं और इसे नए मास्टर के दास के रूप में शामिल कर सकते हैं - यदि आप कुछ डेटा खोने के साथ ठीक हैं। लेकिन डिफ़ॉल्ट रूप से, ClusterControl विफल मास्टर को तब तक रहने देगा, जब तक कि कोई इसे देख न ले और इसे टोपोलॉजी में फिर से पेश करने का निर्णय न ले ले।
तो, क्या आपको विफलता को स्वचालित करना चाहिए? यह इस बात पर निर्भर करता है कि आपने प्रतिकृति को कैसे कॉन्फ़िगर किया है। कई लिखने योग्य मास्टर्स या जटिल टोपोलॉजी के साथ सर्कुलर प्रतिकृति सेटअप शायद ऑटो फेलओवर के लिए अच्छे उम्मीदवार नहीं हैं। प्रतिकृति समाधान तैयार करते समय हम उपरोक्त सिद्धांतों पर टिके रहेंगे।
PostgreSQL पर
जब PostgreSQL स्ट्रीमिंग प्रतिकृति की बात आती है, तो ClusterControl विफलता को स्वचालित करने के लिए समान सिद्धांतों का उपयोग करता है। PostgreSQL के लिए, ClusterControl मास्टर और स्लेव के बीच एसिंक्रोनस और सिंक्रोनस प्रतिकृति मॉडल दोनों का समर्थन करता है। दोनों ही मामलों में और विफलता की स्थिति में, सबसे अद्यतित डेटा वाले दास को नए मास्टर के रूप में चुना जाता है। विफल मास्टर्स प्रतिकृति सेटअप में फिर से शामिल होने के लिए स्वचालित रूप से पुनर्प्राप्त/फिक्स नहीं होते हैं।
यह सुनिश्चित करने के लिए कुछ सुरक्षात्मक उपाय किए गए हैं कि असफल मास्टर नीचे है और नीचे रहता है, उदा। इसे प्रॉक्सी में लोड बैलेंसिंग सेट से हटा दिया जाता है और इसे मार दिया जाता है यदि उदा। उपयोगकर्ता इसे मैन्युअल रूप से पुनरारंभ करेगा। क्लस्टरकंट्रोल और मास्टर के बीच नेटवर्क विभाजन का पता लगाना वहां थोड़ा अधिक चुनौतीपूर्ण है, क्योंकि दास उस मास्टर की स्थिति के बारे में कोई जानकारी नहीं देते हैं जिससे वे नकल कर रहे हैं। इसलिए डेटाबेस सेटअप के सामने एक प्रॉक्सी महत्वपूर्ण है क्योंकि यह मास्टर को दूसरा रास्ता प्रदान कर सकता है।
MongoDB पर
ओप्लॉग के माध्यम से एक प्रतिकृति के भीतर मोंगोडीबी प्रतिकृति बिनलॉग प्रतिकृति के समान है, तो मोंगोडीबी स्वचालित रूप से एक असफल मास्टर को कैसे पुनर्प्राप्त करता है? समस्या अभी भी है, और MongoDB पता है कि विफलता के समय दासों को दोहराया नहीं गया किसी भी परिवर्तन को वापस रोल करके। उस डेटा को हटा दिया जाता है और एक 'रोलबैक' फ़ोल्डर में रख दिया जाता है, इसलिए इसे पुनर्स्थापित करना व्यवस्थापक पर निर्भर करता है।
अधिक जानने के लिए, ClusterControl देखें; और नीचे टिप्पणी करने या प्रश्न पूछने के लिए स्वतंत्र महसूस करें।



