MongoDB पाठ खोज स्नोबॉल स्टेमिंग लाइब्रेरी का उपयोग करती है शब्दों को अपेक्षित मूल रूप में कम करने के लिए (या स्टेम ) सामान्य भाषा के नियमों के आधार पर। एल्गोरिथम स्टेमिंग एक त्वरित कमी प्रदान करता है, लेकिन भाषाओं में अपवाद हैं (जैसे अनियमित या विरोधाभासी क्रिया संयुग्मन पैटर्न) जो सटीकता को प्रभावित कर सकते हैं। स्नोबॉल परिचय एल्गोरिथम स्टेमिंग की कुछ सीमाओं का एक अच्छा अवलोकन शामिल है।
walking . का आपका उदाहरण walking . से उपजा है और उम्मीद के मुताबिक मेल खाता है।
हालांकि, trekking . का आपका उदाहरण trekk . से उपजा है इसलिए trekk . के आपके खोज कीवर्ड से मेल नहीं खाता .
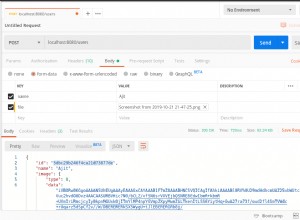
आप अपनी क्वेरी की व्याख्या करके और parsedTextQuery . की समीक्षा करके इसकी पुष्टि कर सकते हैं जानकारी जो उपयोग किए गए उपजी खोज शब्दों को दिखाती है:
db.events.find({$text: {$search: 'Trekking'} }).explain().queryPlanner.winningPlan.parsedTextQuery
{
"terms" : [
"trekk"
],
"negatedTerms" : [ ],
"phrases" : [ ],
"negatedPhrases" : [ ]
}
आप ऑनलाइन स्नोबॉल डेमो का उपयोग करके अपेक्षित स्नोबॉल स्टेमिंग की जांच भी कर सकते हैं। या अपनी पसंदीदा प्रोग्रामिंग भाषा के लिए स्नोबॉल लाइब्रेरी ढूंढकर।
उन अपवादों के आसपास काम करने के लिए जो आमतौर पर आपके उपयोग के मामले को प्रभावित कर सकते हैं, आप खोज परिणामों को प्रभावित करने के लिए कीवर्ड के साथ अपने टेक्स्ट इंडेक्स में एक और फ़ील्ड जोड़ने पर विचार कर सकते हैं। इस उदाहरण के लिए, आप trekk . जोड़ेंगे एक कीवर्ड के रूप में ताकि घटना को trekking . के रूप में वर्णित किया जा सके आपके खोज परिणामों में भी मेल खाता है।
अधिक सटीक विभक्ति के लिए अन्य दृष्टिकोण हैं जिन्हें आम तौर पर lemmatization . के रूप में संदर्भित किया जाता है . Lemmatization एल्गोरिदम अधिक जटिल हैं और प्राकृतिक भाषा संसाधन के डोमेन में जाने लगते हैं। . यदि आप अपने एप्लिकेशन में अधिक उन्नत टेक्स्ट खोज लागू करना चाहते हैं, तो कई ओपन सोर्स (और वाणिज्यिक) टूलकिट हैं जिनका आप लाभ उठा सकते हैं, लेकिन ये MongoDB टेक्स्ट सर्च फीचर के मौजूदा दायरे से बाहर हैं।