डेटाबेस के साथ व्यवहार और प्रबंधन करते समय सबसे बड़ी चिंताओं में से एक इसकी डेटा और आकार जटिलता है। अक्सर, संगठन इस बात को लेकर चिंतित रहते हैं कि विकास से कैसे निपटा जाए और विकास के प्रभाव का प्रबंधन कैसे किया जाए क्योंकि डेटाबेस प्रबंधन विफल हो जाता है। जटिलता उन चिंताओं के साथ आती है जिन्हें शुरू में संबोधित नहीं किया गया था और जिन्हें देखा नहीं गया था, या जिन्हें अनदेखा किया जा सकता था क्योंकि वर्तमान में उपयोग की जा रही तकनीक स्वयं को संभालने में सक्षम होगी। एक जटिल और बड़े डेटाबेस के प्रबंधन की योजना उसी के अनुसार बनाई जानी चाहिए, खासकर जब आप जिस प्रकार के डेटा का प्रबंधन या प्रबंधन कर रहे हैं, उसके बड़े पैमाने पर या तो प्रत्याशित या अप्रत्याशित तरीके से बढ़ने की उम्मीद है। नियोजन का मुख्य लक्ष्य अवांछित आपदाओं से बचना है, या हम कहें कि धुएं में ऊपर जाने से बचें! इस ब्लॉग में हम बड़े डेटाबेस को कुशलतापूर्वक प्रबंधित करने के तरीके को कवर करेंगे।
डेटा आकार मायने रखता है
डेटाबेस का आकार मायने रखता है क्योंकि इसका प्रदर्शन और इसकी प्रबंधन पद्धति पर प्रभाव पड़ता है। डेटा को कैसे संसाधित और संग्रहीत किया जाता है, यह योगदान देगा कि डेटाबेस कैसे प्रबंधित किया जाएगा, जो पारगमन और बाकी डेटा दोनों पर लागू होता है। कई बड़े संगठनों के लिए, डेटा सोना है, और डेटा में वृद्धि प्रक्रिया में भारी बदलाव ला सकती है। इसलिए, डेटाबेस में बढ़ते डेटा को संभालने के लिए पहले से योजना बनाना महत्वपूर्ण है।
डेटाबेस के साथ काम करने के अपने अनुभव में, मैंने देखा है कि ग्राहकों को प्रदर्शन दंड से निपटने और अत्यधिक डेटा वृद्धि का प्रबंधन करने में समस्याएं आ रही हैं। प्रश्न उठते हैं कि क्या तालिकाओं को सामान्य बनाना बनाम तालिकाओं को सामान्य बनाना है।
तालिकाओं को सामान्य करना
तालिकाओं का सामान्यीकरण डेटा अखंडता को बनाए रखता है, अतिरेक को कम करता है, और डेटा को प्रबंधित करने, विश्लेषण करने और निकालने के लिए अधिक कुशल तरीके से व्यवस्थित करना आसान बनाता है। सामान्यीकृत तालिकाओं के साथ कार्य करने से दक्षता प्राप्त होती है, विशेष रूप से डेटा प्रवाह का विश्लेषण करते समय और SQL कथनों द्वारा डेटा पुनर्प्राप्त करते समय या प्रोग्रामिंग भाषाओं जैसे C/C++, Java, Go, Ruby, PHP, या Python इंटरफेस के साथ MySQL Connectors के साथ काम करते समय।
हालांकि सामान्यीकृत तालिकाओं के साथ चिंताओं में प्रदर्शन दंड होता है और डेटा पुनर्प्राप्त करते समय जुड़ने की श्रृंखला के कारण प्रश्नों को धीमा कर सकता है। जबकि डीनॉर्मलाइज्ड टेबल, ऑप्टिमाइज़ेशन के लिए आपको केवल इंडेक्स या प्राथमिक कुंजी पर निर्भर करता है ताकि डेटा को बफर में स्टोर करने के लिए कई डिस्क की तुलना में त्वरित पुनर्प्राप्ति के लिए स्टोर किया जा सके। असामान्य तालिकाओं के लिए किसी जोड़ की आवश्यकता नहीं होती है, लेकिन यह डेटा अखंडता को त्याग देता है, और डेटाबेस का आकार बड़ा और बड़ा होता जाता है।
जब आपका डेटाबेस बड़ा हो तो MySQL/MariaDB में अपने डेटाबेस टेबल के लिए DDL (डेटा डेफिनिशन लैंग्वेज) रखने पर विचार करें। अपनी तालिका के लिए प्राथमिक या अनन्य कुंजी जोड़ने के लिए तालिका पुनर्निर्माण की आवश्यकता होती है। कॉलम डेटा प्रकार को बदलने के लिए एक टेबल पुनर्निर्माण की भी आवश्यकता होती है क्योंकि लागू होने वाला एल्गोरिदम केवल ALGORITHM=COPY है।
यदि आप इसे अपने उत्पादन परिवेश में कर रहे हैं, तो यह चुनौतीपूर्ण हो सकता है। यदि आपकी तालिका बहुत बड़ी है तो चुनौती को दोगुना करें। एक लाख या एक अरब पंक्तियों की कल्पना करें। आप तालिका में कोई परिवर्तन सीधे अपनी तालिका में लागू नहीं कर सकते। यह आने वाले सभी ट्रैफ़िक को ब्लॉक कर सकता है, जिसे उस तालिका तक पहुँचने की आवश्यकता होगी जिसे आप वर्तमान में DDL लागू कर रहे हैं। हालांकि, इसे पीटी-ऑनलाइन-स्कीमा-परिवर्तन या महान जीएच-ओस्ट का उपयोग करके कम किया जा सकता है। फिर भी, डीडीएल की प्रक्रिया करते समय इसे निगरानी और रखरखाव की आवश्यकता होती है।
शेयरिंग और पार्टिशनिंग
शार्डिंग और विभाजन के साथ, यह डेटा को उनकी तार्किक पहचान के अनुसार अलग या विभाजित करने में मदद करता है। उदाहरण के लिए, दी गई श्रेणी के आधार पर दिनांक, वर्णानुक्रम, देश, राज्य या प्राथमिक कुंजी के आधार पर अलग करके। यह आपके डेटाबेस आकार को प्रबंधनीय बनाने में मदद करता है। अपने डेटाबेस का आकार उस सीमा तक रखें जो आपके संगठन और आपकी टीम के लिए प्रबंधनीय हो। जरूरत पड़ने पर स्केल करना आसान या प्रबंधन में आसान, खासकर जब कोई आपदा आती है।
जब हम प्रबंधनीय कहते हैं, तो अपने सर्वर और अपनी इंजीनियरिंग टीम के क्षमता संसाधनों पर भी विचार करें। आप कुछ इंजीनियरों के साथ बड़े और बड़े डेटा के साथ काम नहीं कर सकते। बड़ी संख्या में डेटा सेट वाले 1000 डेटाबेस जैसे बड़े डेटा के साथ काम करने के लिए समय की भारी मांग की आवश्यकता होती है। कौशल के अनुसार और विशेषज्ञता एक जरूरी है। यदि लागत एक मुद्दा है, तो यही वह समय है जब आप तृतीय पक्ष सेवाओं का लाभ उठा सकते हैं जो प्रबंधित सेवाओं या भुगतान परामर्श या ऐसे किसी भी इंजीनियरिंग कार्य को पूरा करने के लिए समर्थन प्रदान करती हैं।
चरित्र सेट और संयोजन
चरित्र सेट और संयोजन डेटा संग्रहण और प्रदर्शन को प्रभावित करते हैं, विशेष रूप से दिए गए वर्ण सेट और चयनित कोलाज पर। प्रत्येक वर्ण सेट और संयोजनों का अपना उद्देश्य होता है और अधिकतर अलग-अलग लंबाई की आवश्यकता होती है। यदि आपके पास वर्ण एन्कोडिंग के कारण अन्य वर्ण सेट और कॉलेशन की आवश्यकता वाली तालिकाएं हैं, तो डेटा को आपके डेटाबेस और तालिकाओं या यहां तक कि स्तंभों के लिए संग्रहीत और संसाधित किया जाना है।
यह आपके डेटाबेस को प्रभावी ढंग से प्रबंधित करने के तरीके को प्रभावित करता है। यह आपके डेटा संग्रहण और साथ ही साथ पहले बताए गए प्रदर्शन को प्रभावित करता है। यदि आप अपने आवेदन द्वारा संसाधित किए जाने वाले वर्णों के प्रकारों को समझ गए हैं, तो उपयोग किए जाने वाले वर्ण सेट और संयोजनों पर ध्यान दें। अल्फ़ान्यूमेरिक प्रकार के वर्णों को संग्रहीत और संसाधित करने के लिए लैटिन प्रकार के वर्ण सेट अधिकतर पर्याप्त होंगे।
यदि यह अपरिहार्य है, तो शार्डिंग और विभाजन आपके डेटाबेस सर्वर में बहुत अधिक डेटा को फूलने से बचाने के लिए डेटा को कम से कम कम करने और सीमित करने में मदद करता है। एकल डेटाबेस सर्वर पर बहुत बड़े डेटा का प्रबंधन दक्षता को प्रभावित कर सकता है, विशेष रूप से बैकअप उद्देश्यों, आपदा और पुनर्प्राप्ति, या डेटा पुनर्प्राप्ति के साथ-साथ डेटा भ्रष्टाचार या डेटा खो जाने की स्थिति में।
डेटाबेस जटिलता प्रदर्शन को प्रभावित करती है
प्रदर्शन दंड की बात आती है तो एक बड़े और जटिल डेटाबेस में एक कारक होता है। जटिल, इस मामले में, इसका अर्थ है कि आपके डेटाबेस की सामग्री में गणितीय समीकरण, निर्देशांक, या संख्यात्मक और वित्तीय रिकॉर्ड शामिल हैं। अब इन अभिलेखों को उन प्रश्नों के साथ मिला दिया गया है जो आक्रामक रूप से इसके डेटाबेस के मूल गणितीय कार्यों का उपयोग कर रहे हैं। नीचे दिए गए उदाहरण SQL (MySQL/MariaDB संगत) क्वेरी पर एक नज़र डालें,
SELECT
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) a,
ATAN2( PI(),
SQRT(
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) -
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) -
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) b,
ATAN2( PI(),
SQRT(
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) *
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) /
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) c
FROM
a
LEFT JOIN `a`.`pk`=`b`.`pk`
LEFT JOIN `a`.`pk`=`c`.`pk`
WHERE
((`a`.`col1` * `c`.`col1` + `a`.`col1` * `b`.`col1`)/ (`a`.`col2`))
between 0 and 100
AND
SQRT(((
(0 + (
(((`a`.`col3` * `a`.`col4` + `b`.`col3` * `b`.`col4` + `c`.`col3` + `c`.`col4`)-(PI()))/(`a`.`col2`)) *
`b`.`col2`)) -
`c`.`col2) *
((0 + (
((( `a`.`col5`* `b`.`col3`+ `b`.`col4` * `b`.`col5` + `c`.`col2` `c`.`col3`)-(0))/( `c`.`col5`)) *
`b`.`col3`)) -
`a`.`col5`)) +
((
(0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * PI() + `c`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `b`.`col5`)) -
`b`.`col5` ) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `c`.`col2` + `b`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * -20.90625)) - `b`.`col5`)) +
(((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2` +`a`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2`5 + `c`.`col3` / `c`.`col2`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`
))) <=600
ORDER BY
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) DESC
विचार करें कि यह क्वेरी एक लाख पंक्तियों से लेकर तालिका पर लागू होती है। इस बात की बहुत अधिक संभावना है कि यह सर्वर को रोक सकता है, और यह संसाधन गहन हो सकता है जिससे आपके उत्पादन डेटाबेस क्लस्टर की स्थिरता को खतरा हो सकता है। शामिल कॉलम को इस क्वेरी को ऑप्टिमाइज़ करने और बेहतर बनाने के लिए अनुक्रमित किया जाता है। हालांकि, इष्टतम प्रदर्शन के लिए संदर्भित कॉलम में इंडेक्स जोड़ना आपके बड़े डेटाबेस के प्रबंधन की दक्षता की गारंटी नहीं देता है।
जटिलता को संभालते समय, जटिल गणितीय समीकरणों के कठोर उपयोग और इस अंतर्निहित जटिल कम्प्यूटेशनल क्षमता के आक्रामक उपयोग से बचने के लिए अधिक कुशल तरीका है। इसे डेटाबेस का उपयोग करने के बजाय बैकएंड प्रोग्रामिंग भाषाओं का उपयोग करके जटिल संगणनाओं के माध्यम से संचालित और परिवहन किया जा सकता है। यदि आपके पास जटिल संगणनाएं हैं, तो क्यों न इन समीकरणों को डेटाबेस में संग्रहीत किया जाए, प्रश्नों को पुनः प्राप्त किया जाए, इसे और अधिक आसान विश्लेषण में व्यवस्थित किया जाए या आवश्यकता पड़ने पर डिबग किया जाए।
क्या आप सही डेटाबेस इंजन का उपयोग कर रहे हैं?
डेटा संरचना दी गई क्वेरी और तालिका से पढ़े या पुनर्प्राप्त किए गए रिकॉर्ड के संयोजन के आधार पर डेटाबेस सर्वर के प्रदर्शन को प्रभावित करती है। MySQL/MariaDB के भीतर डेटाबेस इंजन InnoDB और MyISAM का समर्थन करते हैं जो B-Tree का उपयोग करते हैं, जबकि NDB या मेमोरी डेटाबेस इंजन हैश मैपिंग का उपयोग करते हैं। इन डेटा संरचनाओं में इसके स्पर्शोन्मुख संकेतन होते हैं जो बाद वाले इन डेटा संरचनाओं द्वारा उपयोग किए जाने वाले एल्गोरिदम के प्रदर्शन को व्यक्त करते हैं। हम इन्हें कंप्यूटर साइंस में बिग ओ नोटेशन कहते हैं जो एक एल्गोरिथम के प्रदर्शन या जटिलता का वर्णन करता है। यह देखते हुए कि InnoDB और MyISAM B-Tree का उपयोग करते हैं, यह खोज के लिए O(log n) का उपयोग करता है। जबकि, हैश टेबल्स या हैश मैप्स O(n) का उपयोग करते हैं। दोनों अपने प्रदर्शन के लिए औसत और सबसे खराब स्थिति को इसके अंकन के साथ साझा करते हैं।
अब विशिष्ट इंजन पर वापस, इंजन की डेटा संरचना को देखते हुए, लक्ष्य डेटा के आधार पर लागू की जाने वाली क्वेरी निश्चित रूप से आपके डेटाबेस सर्वर के प्रदर्शन को प्रभावित करती है। हैश टेबल रेंज रिट्रीवल नहीं कर सकते हैं, जबकि बी-ट्री इस प्रकार की खोजों को करने के लिए बहुत कुशल हैं और साथ ही यह बड़ी मात्रा में डेटा को संभाल सकते हैं।
आपके द्वारा संग्रहीत डेटा के लिए सही इंजन का उपयोग करके, आपको यह पहचानने की आवश्यकता है कि आप अपने द्वारा संग्रहीत इन विशिष्ट डेटा के लिए किस प्रकार की क्वेरी लागू करते हैं। किस प्रकार का तर्क है कि ये डेटा व्यावसायिक तर्क में परिवर्तित होने पर तैयार होगा।
1000 या हजारों डेटाबेस के साथ काम करते हुए, अपने प्रश्नों और डेटा के संयोजन में सही इंजन का उपयोग करके जिसे आप पुनर्प्राप्त और संग्रहीत करना चाहते हैं, अच्छा प्रदर्शन प्रदान करेगा। यह देखते हुए कि आपने सही डेटाबेस वातावरण के उद्देश्य के लिए अपनी आवश्यकताओं को पूर्वनिर्धारित और विश्लेषण किया है।
बड़े डेटाबेस को प्रबंधित करने के लिए सही उपकरण
एक ठोस प्लेटफॉर्म के बिना एक बहुत बड़े डेटाबेस को प्रबंधित करना बहुत कठिन और कठिन है जिस पर आप भरोसा कर सकते हैं। यहां तक कि अच्छे और कुशल डेटाबेस इंजीनियरों के साथ भी, तकनीकी रूप से आप जिस डेटाबेस सर्वर का उपयोग कर रहे हैं, वह मानवीय त्रुटि के लिए प्रवण है। आपके कॉन्फ़िगरेशन पैरामीटर और वेरिएबल में किसी भी परिवर्तन की एक गलती के परिणामस्वरूप सर्वर के प्रदर्शन में भारी परिवर्तन हो सकता है।
एक बहुत बड़े डेटाबेस पर अपने डेटाबेस का बैकअप करना कई बार चुनौतीपूर्ण हो सकता है। ऐसी घटनाएं होती हैं कि कुछ अजीब कारणों से बैकअप विफल हो सकता है। आमतौर पर, क्वेरीज़ जो सर्वर को रोक सकती हैं जहाँ बैकअप चल रहा है, विफल होने का कारण बनता है। अन्यथा, आपको इसके कारणों की जांच करनी होगी।
शेफ, कठपुतली, Ansible, टेराफॉर्म, या साल्टस्टैक जैसे स्वचालन का उपयोग आपके IaC के रूप में प्रदर्शन करने के लिए त्वरित कार्य प्रदान करने के लिए किया जा सकता है। अन्य तृतीय-पक्ष टूल का उपयोग करने के साथ-साथ उच्च गुणवत्ता वाले ग्राफ़ छवियों की निगरानी और प्रदान करने में आपकी सहायता करने के लिए। चेतावनी से लेकर गंभीर स्थिति स्तर तक होने वाली समस्याओं से आपको सूचित करने के लिए अलर्ट और अलार्म नोटिफिकेशन सिस्टम भी बहुत महत्वपूर्ण हैं। इस तरह की स्थिति में ClusterControl बहुत उपयोगी होता है।
ClusterControl बड़ी संख्या में डेटाबेस या यहां तक कि शार्प प्रकार के वातावरण के साथ प्रबंधन करने में आसानी प्रदान करता है। यह एक हजार बार परीक्षण और स्थापित किया गया है और डेटाबेस वातावरण को संचालित करने वाले DBA, इंजीनियरों या DevOps को अलार्म और सूचनाएं प्रदान करने वाली प्रस्तुतियों में चल रहा है। मंचन या विकास से लेकर, क्यूए, उत्पादन परिवेश तक।
ClusterControl भी बैकअप कर सकता है और पुनर्स्थापित कर सकता है। बड़े डेटाबेस के साथ भी, यह कुशल और प्रबंधन में आसान हो सकता है क्योंकि UI शेड्यूलिंग प्रदान करता है और इसे क्लाउड (AWS, Google क्लाउड और Azure) पर अपलोड करने के विकल्प भी हैं।
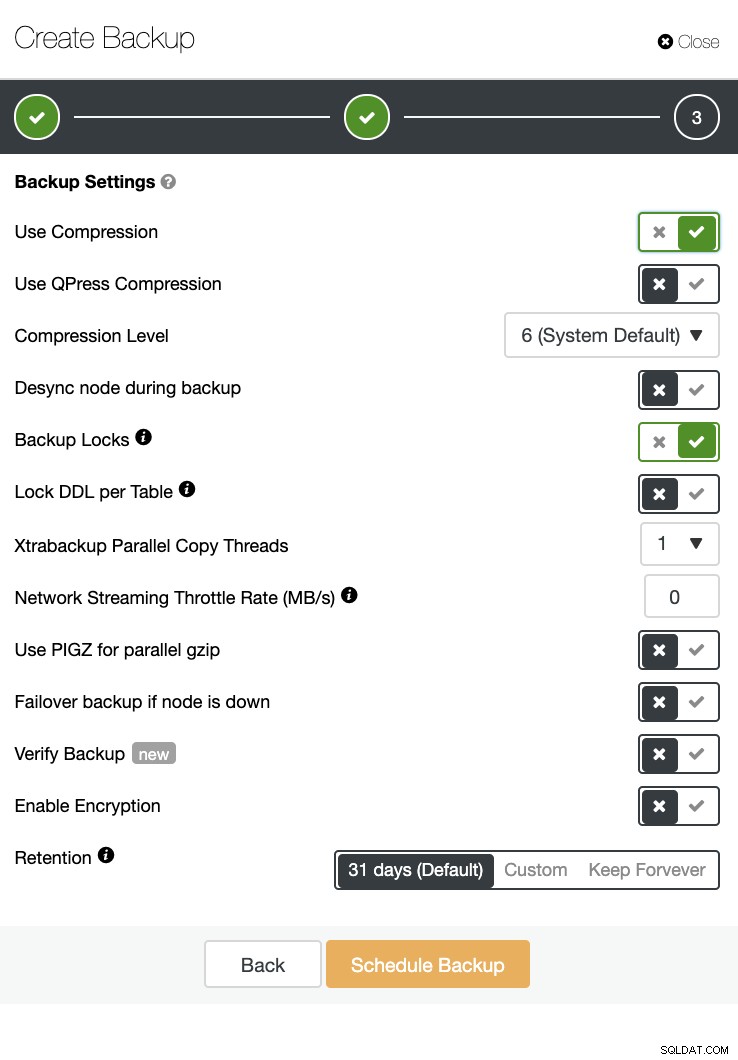
एक बैकअप सत्यापन और एन्क्रिप्शन और संपीड़न जैसे कई विकल्प भी हैं। उदाहरण के लिए नीचे स्क्रीनशॉट देखें (Xtrabackup का उपयोग करके MySQL के लिए बैकअप बनाना):
निष्कर्ष
एक हजार या अधिक जैसे बड़े डेटाबेस का प्रबंधन कुशलता से किया जा सकता है, लेकिन इसे पहले से निर्धारित और तैयार किया जाना चाहिए। ऑटोमेशन या यहां तक कि प्रबंधित सेवाओं की सदस्यता लेने जैसे सही टूल का उपयोग करने से काफी मदद मिलती है। हालांकि इसमें लागत लगती है, सेवा का टर्नअराउंड और कुशल इंजीनियरों को प्राप्त करने के लिए खर्च किए जाने वाले बजट को तब तक कम किया जा सकता है जब तक कि सही उपकरण उपलब्ध हों।



