परिचालन रिपोर्टिंग दिन-प्रतिदिन उद्यम गतिविधि की निगरानी और नियंत्रण के लिए सहायता प्रदान करती है। इस ब्लॉग आलेख का उद्देश्य आपको ClusterControl में उपलब्ध परिचालन रिपोर्ट से अधिक परिचित कराना है।
ClusterControl परिचालन रिपोर्ट आपको आपके डेटाबेस अवसंरचना की स्थिति के बारे में जानकारी प्रदान करती है, जिसका उपयोग आप अपने पर्यावरण या परिचालन समर्थन के हिस्से के रूप में ऑडिट करने के लिए कर सकते हैं। इन रिपोर्टों में विभिन्न जांच शामिल हैं और विभिन्न दिन-प्रतिदिन के डीबीए कार्यों को संबोधित करते हैं। ClusterControl परिचालन रिपोर्टिंग के पीछे का विचार सभी सबसे प्रासंगिक डेटा को एक एकल दस्तावेज़ में रखना है, जिसका डेटाबेस और इसकी प्रक्रियाओं की स्थिति की स्पष्ट समझ प्राप्त करने के लिए त्वरित रूप से विश्लेषण किया जा सकता है।
ClusterControl के साथ आप "दैनिक सिस्टम रिपोर्ट," "पैकेज अपग्रेड रिपोर्ट," "स्कीमा परिवर्तन रिपोर्ट" के साथ-साथ "बैकअप" और "उपलब्धता" जैसी क्रॉस एनवायरनमेंट रिपोर्ट शेड्यूल कर सकते हैं। ये रिपोर्टें आपके पर्यावरण को सुरक्षित और परिचालन में रखने में आपकी मदद करेंगी। आप अंतरालों को ठीक करने के तरीके के बारे में सिफारिशें भी देखेंगे। रिपोर्ट को SysOps, DevOps या यहां तक कि प्रबंधकों को संबोधित किया जा सकता है जो किसी सिस्टम के स्वास्थ्य के बारे में नियमित स्थिति अपडेट प्राप्त करना चाहते हैं।
मुझे ऑपरेशनल रिपोर्ट की आवश्यकता क्यों है?
आपके पास पहले से ही सभी संभावित मेट्रिक्स/ग्राफ के साथ एक उत्कृष्ट निगरानी उपकरण हो सकता है और आपने शायद मेट्रिक्स और थ्रेसहोल्ड के आधार पर अलर्ट भी सेट किए हैं (कुछ में स्वचालित सलाहकार भी होंगे जो उन्हें सिफारिशें प्रदान करेंगे या चीजों को स्वचालित रूप से ठीक करेंगे।) यह अच्छा है - आपकी दृश्यता में प्रणाली महत्वपूर्ण है; फिर भी, आपको बहुत सारी जानकारी संसाधित करने में सक्षम होने की आवश्यकता है। ClusterControl जैसे एकीकृत टूल का एक फायदा यह है कि सूचना के सभी अलग-अलग बिट्स एक ही स्थान पर स्थित होते हैं।
छोटे सिस्टम पर, आप कुछ मैन्युअल जांच करना चाह सकते हैं, लेकिन बड़े वातावरण में, वास्तविक समय में सब कुछ का विश्लेषण करना असंभव है। यह भी समय की बर्बादी की तरह लगता है। यह सुनिश्चित करने के लिए कि आपके सिस्टम अच्छे आकार में हैं, आपको बहुत सारी जानकारी से गुजरना होगा। आमतौर पर, इसमें होस्ट आँकड़े, डेटाबेस आँकड़े, बैकअप की स्थिति, लॉग आदि शामिल होते हैं।
क्या मॉनिटर करना है और कितनी बार करना है?
एक बार जब आप अपने सभी डेटाबेस निगरानी/प्रबंधन उपकरण सेटअप कर लेते हैं, तो आपको डेटाबेस के स्वास्थ्य की जांच करने के लिए एक रूटीन स्थापित करने की आवश्यकता होती है। आप इसे कितनी बार करना चाहते हैं यह आप पर निर्भर है और यह आपके पर्यावरण के आकार/कार्यभार या आपकी कंपनी या उद्योग अनुपालन मानकों पर आधारित होना चाहिए। छोटे सेटअप के लिए, दैनिक जांच काम करेगी। बड़े कॉन्फ़िगरेशन के लिए, आपको शायद इसे हर हफ्ते करना होगा। इसके पीछे तर्क यह है कि नियमित परीक्षण आपको सक्रिय रूप से कार्य करने और किसी भी मुद्दे के होने या गंभीर होने से पहले उसे ठीक करने में सक्षम बनाते हैं। बेशक, आप अंततः अपना पैटर्न विकसित कर लेंगे, लेकिन यहां कुछ सुझाव दिए गए हैं कि आप क्या देखना चाहते हैं।
मॉनिटर करने के लिए संभवतः आपके आईटी संगठन में आपके द्वारा निभाई जाने वाली भूमिका से संबंधित होगा। DBA, DevOps, डेवलपर्स या IT प्रबंधन की प्रत्येक की अलग-अलग ज़रूरतें होंगी।
 ClusterControl परिचालन रिपोर्ट
ClusterControl परिचालन रिपोर्ट ऑपरेशन रिपोर्ट शेड्यूलर
इससे पहले कि हम विशेष परिचालन रिपोर्ट का वर्णन करना शुरू करें, आइए रिपोर्ट शेड्यूलर पर एक त्वरित नज़र डालें। आप अपने क्लस्टर नाम के आधार पर आवर्ती स्वचालित रिपोर्ट सेट कर सकते हैं। उत्पादन दर को दैनिक, साप्ताहिक, मासिक प्रकार में विभाजित किया गया है। यदि आप साप्ताहिक रिपोर्ट चुनते हैं तो उनमें से प्रत्येक आपको मासिक प्रकार के लिए महीने के प्रत्येक 5वें दिन या प्रत्येक मंगलवार की तरह आवश्यकतानुसार रिपोर्ट सेटअप करने का विकल्प देगा।
 ClusterControl ऑपरेशनल रिपोर्ट शेड्यूलर
ClusterControl ऑपरेशनल रिपोर्ट शेड्यूलर रिपोर्ट शेड्यूलर के दूसरे खंड में, आप प्राप्तकर्ताओं को चुन सकते हैं। यह प्रबंधन टीम के लिए कुछ अलर्ट सेट करने का एक अच्छा अवसर है, फिर आईटी समर्थन के लिए अधिक तकनीकी अलर्ट। इसे सही ढंग से शेड्यूल करने से आईटी से कार्य बहुत दूर हो सकते हैं, अर्थात, जब प्रबंधन उपलब्धता रिपोर्ट मांग रहा हो या सुरक्षा टीम को पैकेज संस्करण और स्कीमा परिवर्तन जानने की आवश्यकता हो।
बैकअप रिपोर्ट
साप्ताहिक बैकअप रिपोर्ट एक HTML रिपोर्ट है जो सभी प्रबंधित क्लस्टर के लिए रिपोर्टिंग अवधि के लिए बैकअप का अवलोकन प्रदान करती है। बैकअप रिपोर्ट दो खंडों में विभाजित है; बैकअप सारांश और बैकअप विवरण।
रिपोर्ट के मुख्य भाग में आप क्लस्टर प्रकार, अंतिम बैकअप, विफल और सफल बैकअप, सफलता दर और अवधारण अवधि के साथ अपने सभी क्लस्टर का सारांश देख सकते हैं। यह भी महत्वपूर्ण है कि आप बिना बैकअप सेट वाले क्लस्टर के बारे में जानकारी भी देखेंगे। यदि आप बैकअप सेट करना भूल जाते हैं या किसी कारण से बैकअप काम करना बंद कर देते हैं तो यह बहुत मददगार होता है।
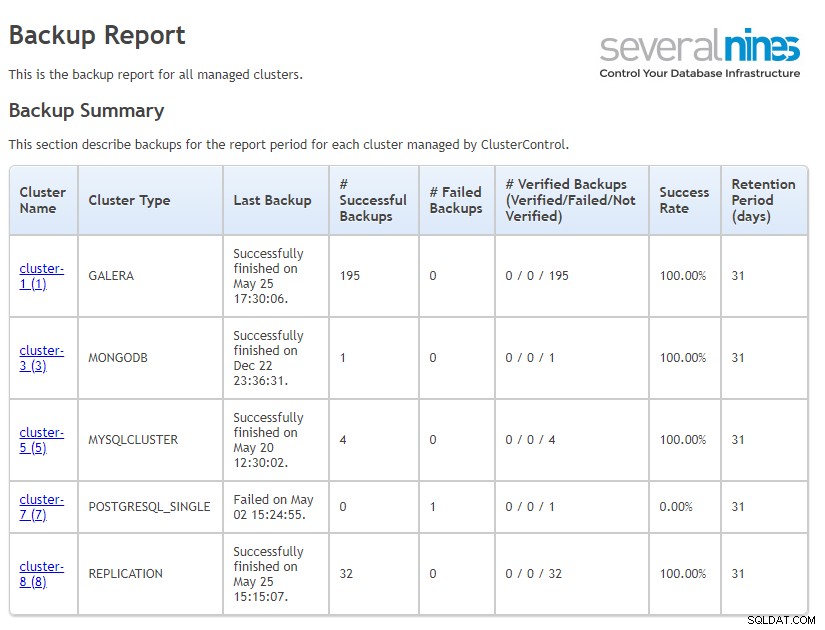 ClusterControl बैकअप सारांश ऑपरेशनल रिपोर्ट
ClusterControl बैकअप सारांश ऑपरेशनल रिपोर्ट बैकअप विवरण में, आप स्थान, आकार, समय और विधि के बारे में विस्तृत जानकारी के साथ किसी विशेष बैकअप आईडी को ट्रैक कर सकते हैं। हम अलग-अलग डेटाबेस प्रकारों के लिए डेटा के साथ एक ही टेम्प्लेट का उपयोग करते हैं, इसलिए जब आप अपने मिश्रित वातावरण का प्रबंधन करते हैं, तो आपको वही अनुभव और लुक मिलेगा। यह विभिन्न डेटाबेस बैकअप को बेहतर ढंग से प्रबंधित करने में मदद करता है।
यह समाधान कैसे काम करता है? जब बैकअप कार्य चालू हो जाता है, तो हम बैकअप प्रक्रिया, सिस्टम, प्लेटफ़ॉर्म और बैकअप अवसंरचना में उपकरणों के बारे में जानकारी एकत्र करते हैं। वह सारी जानकारी एक सीएमओएन (क्लस्टरकंट्रोल रिपोजिटरी डेटाबेस) में एकत्रित और संग्रहीत की जाती है, इसलिए विशेष डेटाबेस को अतिरिक्त रूप से पूछने की कोई आवश्यकता नहीं है।
डिफ़ॉल्ट क्लस्टर रिपोर्ट
डिफ़ॉल्ट क्लस्टर रिपोर्ट में किसी विशेष क्लस्टर के बारे में सभी विस्तृत जानकारी होती है। यह विभिन्न चेतावनियों की समीक्षा के साथ शुरू होता है जो क्लस्टर समूह से संबंधित हैं।
 ClusterControl डिफ़ॉल्ट क्लस्टर रिपोर्ट
ClusterControl डिफ़ॉल्ट क्लस्टर रिपोर्ट अगला खंड उन नोड्स की स्थिति के बारे में है जो क्लस्टर का हिस्सा हैं। आपके पास क्लस्टर में नोड्स, उनके प्रकार, भूमिका (मास्टर या स्लेव), नोड की स्थिति, अपटाइम और OS की एक सूची है।
 ClusterControl डिफ़ॉल्ट क्लस्टर रिपोर्ट नोड अपटाइम और भूमिकाएं
ClusterControl डिफ़ॉल्ट क्लस्टर रिपोर्ट नोड अपटाइम और भूमिकाएं रिपोर्ट का एक अन्य भाग बैकअप सारांश है, जैसा कि हमने ऊपर चर्चा की थी।
 ClusterControl डिफ़ॉल्ट क्लस्टर रिपोर्ट बैकअप विवरण
ClusterControl डिफ़ॉल्ट क्लस्टर रिपोर्ट बैकअप विवरण अगला क्लस्टर में शीर्ष प्रश्नों की समीक्षा प्रस्तुत करता है। अंत में, हम एक "नोड स्थिति अवलोकन" देखते हैं जिसमें आपको प्रत्येक नोड के लिए OS और MySQL मेट्रिक्स से संबंधित ग्राफ़ दिए जाएंगे।

 ClusterControl डिफ़ॉल्ट क्लस्टर ओवरव्यू नोड स्थिति
ClusterControl डिफ़ॉल्ट क्लस्टर ओवरव्यू नोड स्थिति अपग्रेड रिपोर्ट
यह क्लस्टर रिपोर्ट आपको अपने पैकेज को अप-टू-डेट और सुरक्षित रखने में मदद करेगी। अपग्रेड रिपोर्ट ऑपरेटिंग सिस्टम से जानकारी एकत्र करती है और उनकी तुलना रिपॉजिटरी में उपलब्ध पैकेजों से करती है।
रिपोर्ट को चार खंडों में बांटा गया है; अपग्रेड सारांश, डेटाबेस पैकेज, सुरक्षा पैकेज और अन्य पैकेज। आपने अपने सिस्टम पर जो इंस्टाल किया है उसकी तुलना आप तुरंत कर सकते हैं और एक अनुशंसित अपग्रेड या पैच ढूंढ सकते हैं।



स्कीमा चेंज डिटेक्शन रिपोर्ट
स्कीमा चेंज डिटेक्शन रिपोर्ट आपके डेटाबेस पर किसी भी डीडीएल परिवर्तन को दिखाती है। सही ढंग से काम करने के लिए इसे ClusterControl कॉन्फ़िगरेशन फ़ाइल में एक अतिरिक्त पैरामीटर की आवश्यकता होती है। यदि यह सेट नहीं है तो आपको निम्नलिखित जानकारी दिखाई देगी:schema_change_detection_address /etc/cmon.d/cmon_1.cnf में सेट नहीं है। एक बार ऐसा हो जाने पर एक उदाहरण आउटपुट नीचे जैसा हो सकता है:
 ClusterControl स्कीमा परिवर्तन रिपोर्ट
ClusterControl स्कीमा परिवर्तन रिपोर्ट उपलब्धता रिपोर्ट
अंतिम लेकिन कम से कम उपलब्धता रिपोर्ट नहीं है। उपलब्धता को मापना और उस पर रिपोर्ट करना बेहद कठिन है, हालांकि यह आपके और आपके ग्राहक के बीच किसी भी SLA में एक महत्वपूर्ण KPI है। इसे ध्यान में रखते हुए, हमने एक रिपोर्ट बनाई है जो आपके डेटाबेस अपटाइम को माप सकती है। स्क्रिप्ट आपके खाते में नियोजित रखरखाव के दौरान डाली जाती है जिसे आप ClusterControl में सेट कर सकते हैं। रिपोर्ट की जानकारी के आधार पर आप देख सकते हैं कि क्या आप अपने आंतरिक या बाहरी SLA के अनुरूप हैं और अपनी नियोजित नौ को बनाए रखने के लिए डेटाबेस के बुनियादी ढांचे में बदलाव की योजना बना रहे हैं।
 ClusterControl स्कीमा परिवर्तन रिपोर्ट
ClusterControl स्कीमा परिवर्तन रिपोर्ट रिपोर्ट का मुख्य भाग क्लस्टरकंट्रोल द्वारा प्रबंधित प्रत्येक क्लस्टर के लिए अपटाइम/डाउनटाइम और रिपोर्टिंग अवधि के लिए उपलब्धता का वर्णन करता है। जानकारी क्लस्टर प्रकार की परवाह किए बिना सभी क्लस्टर के लिए संयुक्त है।
 ClusterControl उपलब्धता रिपोर्ट क्लस्टर स्थिति इतिहास
ClusterControl उपलब्धता रिपोर्ट क्लस्टर स्थिति इतिहास नीचे विवरण में आप देख सकते हैं कि रिपोर्टिंग अवधि के भीतर महत्वपूर्ण राज्य परिवर्तन हुए, साथ ही नियंत्रक पुनरारंभ भी हुआ। नियंत्रक पुनरारंभ अपटाइम या डाउनटाइम को प्रभावित नहीं करता है और नियोजित रखरखाव को रिपोर्ट में नहीं गिना जाएगा।
 ClusterControl उपलब्धता रिपोर्ट नोड इतिहास
ClusterControl उपलब्धता रिपोर्ट नोड इतिहास निष्कर्ष
कईनाइन क्लस्टरकंट्रोल आपके डेटाबेस सिस्टम अनुपालन के कई पहलुओं को कवर करने में आपकी मदद कर सकता है। बैकअप इतिहास विवरण के साथ शुरू करना, जिसका उपयोग आप पुराने सिस्टम पैकेज और स्कीमा परिवर्तनों के साथ अपग्रेड रिपोर्ट को पैकेज करने के लिए उचित बैकअप नीति के बिना बैकअप पूर्णता, इतिहास और सर्वर जैसी चीजों को ट्रैक करने के लिए उपयोग कर सकते हैं। कुछ चरणों के साथ, आप अपने ओपन सोर्स डेटाबेस पर एंटरप्राइज़ स्तर की जाँच शेड्यूल कर सकते हैं। यह सब आपके प्रबंधन और सहायता टीमों को आपके DB संचालन के बारे में बेहतर जानकारी देगा।



