चूंकि आप वसंत का उपयोग कर रहे हैं। आप MultipartFile . का उपयोग कर सकते हैं फ़ाइल को अपने नियंत्रक में प्राप्त करने के लिए और फिर Binary . का उपयोग करें का org.bson फ़ाइल को MongoDB में संग्रहीत करने के लिए, यदि आपकी छवि का आकार <16MB (यदि छवि का आकार> 16 एमबी है तो आप ग्रिडएफ
)।
आपको अपने प्रोजेक्ट में केवल एक निर्भरता जोड़ने की आवश्यकता है - spring-data-mongoDB
आइए एक उपयोगकर्ता संग्रह का उदाहरण लेते हैं जो इस तरह दिखता है:
@Document
public class User {
@Id
private String id;
private String name;
private Binary image;
// getters and setters
}
यहां आप Binary image देख सकते हैं जो आपकी छवि फ़ाइल का प्रतिनिधित्व करता है।
अब MongoRepository . का उपयोग करके इस उपयोगकर्ता संग्रह के लिए एक रिपॉजिटरी बनाएं
public interface UserRepository extends MongoRepository<User, String>{
}
डेमो उद्देश्य के लिए एक नियंत्रक बनाएँ। @RequestParam MultipartFile file . का उपयोग करें अपने नियंत्रक को फ़ाइल प्राप्त करने के लिए, फ़ाइल से बाइट प्राप्त करें और इसे उपयोगकर्ता ऑब्जेक्ट पर सेट करें user.setImage(new Binary(file.getBytes())); पूरा उदाहरण नीचे है:
@RestController
public class UserController {
@Autowired
private UserRepository userRepository;
@PostMapping("/users")
User createUser(@RequestParam String name, @RequestParam MultipartFile file) throws IOException {
User user = new User();
user.setName(name);
user.setImage(new Binary(file.getBytes()));
return userRepository.save(user);
}
@GetMapping("/users")
String getImage(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
Encoder encoder = Base64.getEncoder();
return encoder.encodeToString(user.get().getImage().getData());
}
}
सर्वर प्रारंभ करें और अंत बिंदु को हिट करें जैसा कि नीचे पोस्टमैन स्क्रीनशॉट में दिखाया गया है
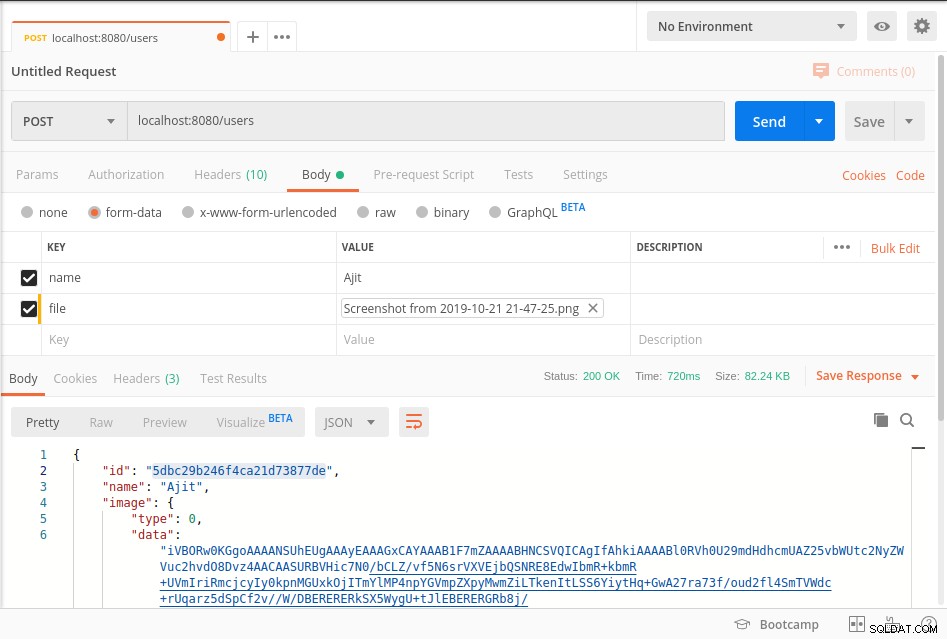
आपका डेटा mongoDb में BinData . में संग्रहीत है प्रारूप और डेटाबेस से डेटा प्राप्त करने के लिए कृपया देखें getImage उपरोक्त कोड की विधि।
संपादित करें:
प्रश्न पूछने वाला tess4j . का उपयोग कर रहा है छवि से पाठ निकालने के लिए पुस्तकालय और doOCR इस पुस्तकालय में एक विधि है। मैंने अपने स्प्रिंग बूट एप्लिकेशन में इमेज से टेक्स्ट निकालने के लिए इन चरणों का पालन किया है।
-
tesseract-ocrइंस्टॉल करें आपके सिस्टम में:sudo apt-get install tesseract-ocr -
डाउनलोड करें
eng.traineddatahttps://github.com/tesseract-ocr/tessdata से प्रशिक्षण डेटा और इसे प्रोजेक्ट रूट फ़ोल्डर में ले जाएँ। -
अपने प्रोजेक्ट में नीचे निर्भरता जोड़ें:
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>3.2.1</version>
</dependency>
- नीचे दिए गए कोड को मौजूदा प्रोजेक्ट में जोड़ें:
@GetMapping("/image-text")
String getImageText(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
ITesseract instance = new Tesseract();
try {
ByteArrayInputStream bais = new ByteArrayInputStream(user.get().getImage().getData());
BufferedImage bufferImg = ImageIO.read(bais);
String imgText = instance.doOCR(bufferImg);
return imgText;
} catch (Exception e) {
return "Error while reading image";
}
}