ठीक है, पहली चीज जो मैं करूँगा वह है icky स्ट्रिंग पार्सिंग को हर जगह छोड़ना और इसे PostgreSQL देशी प्रकारों से बदलना। अपने वर्तमान समाधान के समान प्रत्येक रिकॉर्ड पर प्रतिकृति स्थिति संग्रहीत करने के लिए:
CREATE TYPE replication_status AS ENUM (
'no_action',
'replicate_record',
'record_replicated',
'error_1',
'error_2',
'error_3'
);
ALTER TABLE t ADD COLUMN rep_status_array replication_status[];
इससे आपको थोड़ा अधिक संग्रहण स्थान खर्च होता है - एनम मान 1 के बजाय 4 बाइट्स होते हैं और सरणियों में कुछ ओवरहेड होता है। हालाँकि, डेटाबेस को अपनी अवधारणाओं को छिपाने के बजाय सिखाकर, आप इस तरह की चीजें लिख सकते हैं:
-- find all records that need to be replicated to host 4
SELECT * FROM t WHERE rep_status_array[4] = 'replicate_record';
-- find all records that contain any error status
SELECT * FROM t WHERE rep_status_array &&
ARRAY['error_1', 'error_2', 'error_3']::replication_status[];
आप सीधे rep_status_array . पर GIN इंडेक्स डाल सकते हैं यदि यह आपके उपयोग के मामले में मदद करता है, लेकिन अपने प्रश्नों को देखना और विशेष रूप से आपके द्वारा उपयोग की जाने वाली अनुक्रमणिका बनाना बेहतर है:
CREATE INDEX t_replication_host_4_key ON t ((rep_status_array[4]));
CREATE INDEX t_replication_error_key ON t (id)
WHERE rep_status_array && ARRAY['error_1', 'error_2', 'error_3']::replication_status[];
उस ने कहा, 200 टेबल दिए गए हैं, मैं इसे एक प्रतिकृति स्थिति तालिका में विभाजित करने का लुत्फ उठाऊंगा - या तो एक पंक्ति की स्थिति या प्रति पंक्ति एक पंक्ति, इस पर निर्भर करता है कि शेष प्रतिकृति तर्क कैसे काम करता है। मैं अब भी उस गणना का उपयोग करूंगा:
CREATE TABLE adhoc_replication (
record_id bigint not null,
table_oid oid not null,
host_id integer not null,
replication_status status not null default 'no_action',
primary key (record_id,table_oid,host_id)
);
PostgreSQL आंतरिक रूप से प्रत्येक तालिका को एक OID निर्दिष्ट करता है (कोशिश करें SELECT *, tableoid FROM t LIMIT 1 ), जो एक एकल डेटाबेस सिस्टम के भीतर एक सुविधाजनक स्थिर संख्यात्मक पहचानकर्ता है। एक और तरीका रखो, यह बदल जाता है यदि तालिका को गिरा दिया जाता है और फिर से बनाया जाता है (जो तब हो सकता है जब आप डेटाबेस को डंप और पुनर्स्थापित करते हैं), और इसी कारण से यह विकास और उत्पादन के बीच बहुत भिन्न होता है। यदि आप चाहते हैं कि ये स्थितियां किसी तालिका को जोड़ने या उसका नाम बदलने पर टूटने के बदले काम करें, तो OID के बजाय गणना का उपयोग करें।
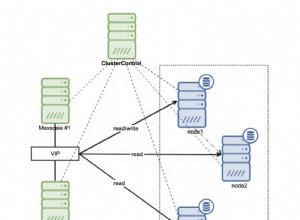
सभी प्रतिकृति के लिए एकल तालिका का उपयोग करने से आप आसानी से ट्रिगर और प्रश्नों का पुन:उपयोग कर सकते हैं और इस तरह, डेटा की प्रतिकृति से अधिकांश प्रतिकृति तर्क को अलग कर सकते हैं। यह आपको किसी एकल अनुक्रमणिका का संदर्भ देकर किसी दिए गए होस्ट की स्थिति के आधार पर आपके सभी मूल तालिकाओं में क्वेरी करने की अनुमति देता है, जो महत्वपूर्ण हो सकता है।
तालिका आकार के लिए, PostgreSQL निश्चित रूप से एक ही तालिका में 10 मिलियन पंक्तियों को संभाल सकता है। यदि आप एक समर्पित प्रतिकृति-संबंधित तालिका के साथ गए हैं, तो आप हमेशा विभाजन कर सकते हैं। प्रति मेजबान। (तालिका द्वारा विभाजन मेरे लिए थोड़ा मायने रखता है; यह प्रत्येक अपस्ट्रीम पंक्ति पर प्रतिकृति स्थिति को संग्रहीत करने से भी बदतर लगता है।) विभाजन का कौन सा तरीका है या यह बिल्कुल उपयुक्त है या नहीं, यह पूरी तरह से इस बात पर निर्भर करता है कि आप अपने डेटाबेस से किस तरह के प्रश्न पूछना चाहते हैं, और बेस टेबल पर किस तरह की गतिविधि होती है। (विभाजन का अर्थ है कुछ बड़े बूँदों के बजाय कई छोटे बूँदों को बनाए रखना, और संभावित रूप से एकल ऑपरेशन करने के लिए कई छोटे बूँदों तक पहुँच प्राप्त करना।) यह वास्तव में चुनने की बात है कि आप कब चाहते हैं कि आपकी डिस्क हो।