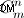यह मानते हुए कि सभी जोड़े उनके प्रतिबिंबित संयोजन में भी मौजूद हैं (4,5) और (5,4) . लेकिन निम्नलिखित समाधान मिरर किए गए डुप्ली के बिना भी काम करते हैं।
साधारण मामला
सभी कनेक्शनों को एकल आरोही क्रम . में पंक्तिबद्ध किया जा सकता है और जटिलताएं जैसे मैंने fiddle में जोड़ी हैं संभव नहीं हैं, हम आरसीटीई में डुप्लीकेट के बिना इस समाधान का उपयोग कर सकते हैं:
मैं न्यूनतम a_sno . प्राप्त करके प्रारंभ करता हूं प्रति समूह, न्यूनतम संबद्ध b_sno . के साथ :
SELECT row_number() OVER (ORDER BY a_sno) AS grp
, a_sno, min(b_sno) AS b_sno
FROM data d
WHERE a_sno < b_sno
AND NOT EXISTS (
SELECT 1 FROM data
WHERE b_sno = d.a_sno
AND a_sno < b_sno
)
GROUP BY a_sno;
इसके लिए केवल एक क्वेरी स्तर की आवश्यकता है क्योंकि एक विंडो फ़ंक्शन को समग्र पर बनाया जा सकता है:
परिणाम:
grp a_sno b_sno
1 4 5
2 9 10
3 11 15
मैं शाखाओं और डुप्लिकेट (गुणा) पंक्तियों से बचता हूं - संभावित रूप से बहुत लंबी श्रृंखलाओं के साथ अधिक महंगा। मैं ORDER BY b_sno LIMIT 1 . का उपयोग करता हूं इस मक्खी को पुनरावर्ती CTE में बनाने के लिए एक सहसंबद्ध उपश्रेणी में।
प्रदर्शन की कुंजी एक मेल खाने वाली अनुक्रमणिका है, जो पहले से ही पीके बाधा PRIMARY KEY (a_sno,b_sno) द्वारा प्रदान की गई है। :दूसरे तरीके से नहीं <स्ट्राइक>(b_sno, a_sno) :
WITH RECURSIVE t AS (
SELECT row_number() OVER (ORDER BY d.a_sno) AS grp
, a_sno, min(b_sno) AS b_sno -- the smallest one
FROM data d
WHERE a_sno < b_sno
AND NOT EXISTS (
SELECT 1 FROM data
WHERE b_sno = d.a_sno
AND a_sno < b_sno
)
GROUP BY a_sno
)
, cte AS (
SELECT grp, b_sno AS sno FROM t
UNION ALL
SELECT c.grp
, (SELECT b_sno -- correlated subquery
FROM data
WHERE a_sno = c.sno
AND a_sno < b_sno
ORDER BY b_sno
LIMIT 1)
FROM cte c
WHERE c.sno IS NOT NULL
)
SELECT * FROM cte
WHERE sno IS NOT NULL -- eliminate row with NULL
UNION ALL -- no duplicates
SELECT grp, a_sno FROM t
ORDER BY grp, sno;
कम सरल मामला
सभी नोड्स को जड़ से एक या अधिक शाखाओं के साथ आरोही क्रम में पहुँचा जा सकता है (सबसे छोटा sno )।
इस बार, सभी प्राप्त करें ग्रेटर sno और डी-डुप्लिकेट नोड्स जिन्हें UNION . के साथ कई बार देखा जा सकता है अंत में:
WITH RECURSIVE t AS (
SELECT rank() OVER (ORDER BY d.a_sno) AS grp
, a_sno, b_sno -- get all rows for smallest a_sno
FROM data d
WHERE a_sno < b_sno
AND NOT EXISTS (
SELECT 1 FROM data
WHERE b_sno = d.a_sno
AND a_sno < b_sno
)
)
, cte AS (
SELECT grp, b_sno AS sno FROM t
UNION ALL
SELECT c.grp, d.b_sno
FROM cte c
JOIN data d ON d.a_sno = c.sno
AND d.a_sno < d.b_sno -- join to all connected rows
)
SELECT grp, sno FROM cte
UNION -- eliminate duplicates
SELECT grp, a_sno FROM t -- add first rows
ORDER BY grp, sno;
पहले समाधान के विपरीत, हमें यहां NULL के साथ अंतिम पंक्ति नहीं मिलती है (सहसंबद्ध सबक्वेरी के कारण)।
दोनों को बहुत अच्छा प्रदर्शन करना चाहिए - खासकर लंबी जंजीरों/कई शाखाओं के साथ। वांछित परिणाम:
SQL Fiddle (कठिनाई प्रदर्शित करने के लिए अतिरिक्त पंक्तियों के साथ)।
अप्रत्यक्ष ग्राफ़
यदि स्थानीय मिनीमा हैं जो आरोही ट्रैवर्सल के साथ रूट से नहीं पहुंचा जा सकता है, तो उपरोक्त समाधान काम नहीं करेंगे। Farhęg's Solution पर विचार करें इस मामले में।