परिचय
अब आपकी मेल खाने वाली शर्तें बहुत व्यापक हो सकती हैं। हालाँकि, आप अपने शब्दों की जाँच करने के लिए दूरी का उपयोग कर सकते हैं। इसके साथ सभी वांछित लक्ष्यों को पूरा करना बहुत आसान नहीं हो सकता है, जैसे ध्वनि समानता। इस प्रकार, मैं आपकी समस्या को कुछ अन्य मुद्दों में विभाजित करने का सुझाव दे रहा हूं।
उदाहरण के लिए, आप कुछ कस्टम चेकर बना सकते हैं जो पास किए गए कॉल करने योग्य इनपुट का उपयोग करेगा जो दो स्ट्रिंग लेता है और फिर प्रश्न का उत्तर देता है कि क्या वे समान हैं (levenshtein के लिए) similar_text . के लिए यह दूरी कुछ मान से कम होगी - कुछ प्रतिशत समानता आदि। - नियमों को परिभाषित करना आप पर निर्भर है)।
समानता, शब्दों पर आधारित
ठीक है, सभी अंतर्निहित फ़ंक्शन विफल हो जाएंगे यदि हम मामले के बारे में बात कर रहे हैं जब आप आंशिक मिलान की तलाश कर रहे हैं - खासकर यदि यह गैर-आदेशित मिलान के बारे में है। इस प्रकार, आपको अधिक जटिल तुलना उपकरण बनाने की आवश्यकता होगी। आपके पास है:
- डेटा स्ट्रिंग (उदाहरण के लिए, डीबी में होगी)। ऐसा लगता है कि डी =डी<उप>0 डी<उप>1 डी<उप>2 ... डी<उप>एन
- खोज स्ट्रिंग (जो उपयोगकर्ता इनपुट होगी)। ऐसा लगता है कि एस =एस<उप>0 स<उप>1 ... एस<उप>एम
यहां अंतरिक्ष प्रतीकों का मतलब बस कोई भी स्थान है (मैं मानता हूं कि अंतरिक्ष प्रतीक समानता को प्रभावित नहीं करेंगे)। साथ ही n > m . इस परिभाषा के साथ आपकी समस्या के बारे में है - m . का सेट ढूंढने के लिए D . में शब्द जो S . के समान होगा . set . द्वारा मेरा मतलब किसी भी अनियंत्रित अनुक्रम से है। इसलिए, अगर हमें ऐसा कोई क्रम मिल जाएगा D . में , फिर S D . के समान है ।
जाहिर है, अगर n < m तब इनपुट में डेटा स्ट्रिंग से अधिक शब्द होते हैं। इस मामले में आप या तो सोच सकते हैं कि वे समान नहीं हैं या ऊपर की तरह कार्य करते हैं, लेकिन डेटा और इनपुट स्विच करें (हालांकि, यह थोड़ा अजीब लगता है, लेकिन कुछ अर्थों में लागू होता है)
कार्यान्वयन
सामान करने के लिए, आपको स्ट्रिंग का सेट बनाने में सक्षम होना चाहिए जो m के भाग हैं D . से शब्द . मेरे इस सवाल
पर आधारित आप इसके साथ ऐसा कर सकते हैं:
protected function nextAssoc($assoc)
{
if(false !== ($pos = strrpos($assoc, '01')))
{
$assoc[$pos] = '1';
$assoc[$pos+1] = '0';
return substr($assoc, 0, $pos+2).
str_repeat('0', substr_count(substr($assoc, $pos+2), '0')).
str_repeat('1', substr_count(substr($assoc, $pos+2), '1'));
}
return false;
}
protected function getAssoc(array $data, $count=2)
{
if(count($data)<$count)
{
return null;
}
$assoc = str_repeat('0', count($data)-$count).str_repeat('1', $count);
$result = [];
do
{
$result[]=array_intersect_key($data, array_filter(str_split($assoc)));
}
while($assoc=$this->nextAssoc($assoc));
return $result;
}
-तो किसी भी सरणी के लिए, getAssoc() m . से युक्त अनियंत्रित चयनों की सरणी लौटाएगा प्रत्येक आइटम।
अगला चरण उत्पादित चयन में आदेश के बारे में है। हमें Niels Andersen दोनों को खोजना चाहिए और Andersen Niels हमारे D . में डोरी। इसलिए, आपको सरणी के लिए क्रमपरिवर्तन बनाने में सक्षम होना चाहिए। यह बहुत ही सामान्य समस्या है, लेकिन मैं अपना संस्करण यहां भी रखूंगा:
protected function getPermutations(array $input)
{
if(count($input)==1)
{
return [$input];
}
$result = [];
foreach($input as $key=>$element)
{
foreach($this->getPermutations(array_diff_key($input, [$key=>0])) as $subarray)
{
$result[] = array_merge([$element], $subarray);
}
}
return $result;
}
इसके बाद आप m . का चयन करने में सक्षम होंगे शब्द और फिर, उनमें से प्रत्येक को क्रमपरिवर्तन करते हुए, खोज स्ट्रिंग के साथ तुलना करने के लिए सभी प्रकार प्राप्त करें S . यह तुलना हर बार कुछ कॉलबैक के माध्यम से की जाएगी, जैसे कि levenshtein . ये रहा नमूना:
public function checkMatch($search, callable $checker=null, array $args=[], $return=false)
{
$data = preg_split('/\s+/', strtolower($this->data), -1, PREG_SPLIT_NO_EMPTY);
$search = trim(preg_replace('/\s+/', ' ', strtolower($search)));
foreach($this->getAssoc($data, substr_count($search, ' ')+1) as $assoc)
{
foreach($this->getPermutations($assoc) as $ordered)
{
$ordered = join(' ', $ordered);
$result = call_user_func_array($checker, array_merge([$ordered, $search], $args));
if($result<=$this->distance)
{
return $return?$ordered:true;
}
}
}
return $return?null:false;
}
यह उपयोगकर्ता कॉलबैक के आधार पर समानता की जांच करेगा, जिसे कम से कम दो पैरामीटर (यानी तुलना किए गए तार) को स्वीकार करना होगा। इसके अलावा, आप उस स्ट्रिंग को वापस करना चाह सकते हैं जिसने कॉलबैक सकारात्मक रिटर्न को ट्रिगर किया। कृपया, ध्यान दें, कि यह कोड अपर और लोअर केस में भिन्न नहीं होगा - लेकिन हो सकता है कि आप ऐसा व्यवहार नहीं चाहते हैं (फिर बस strtolower() बदलें। )।
पूरे कोड का नमूना इस लिस्टिंग में उपलब्ध है (मैंने सैंडबॉक्स का उपयोग नहीं किया क्योंकि मैं इस बारे में निश्चित नहीं हूं कि वहां कितनी देर तक कोड सूची उपलब्ध होगी)। उपयोग के इस नमूने के साथ:
$data = 'Niels Faurskov Andersen';
$search = [
'Niels Andersen',
'Niels Faurskov',
'Niels Faurskov Andersen',
'Nils Faurskov Andersen',
'Nils Andersen',
'niels faurskov',
'niels Faurskov',
'niffddels Faurskovffre'//I've added this crap
];
$checker = new Similarity($data, 2);
echo(sprintf('Testing "%s"'.PHP_EOL.PHP_EOL, $data));
foreach($search as $name)
{
echo(sprintf(
'Name "%s" has %s'.PHP_EOL,
$name,
($result=$checker->checkMatch($name, 'levenshtein', [], 1))
?sprintf('matched with "%s"', $result)
:'mismatched'
)
);
}
आपको ऐसा परिणाम मिलेगा:
Testing "Niels Faurskov Andersen" Name "Niels Andersen" has matched with "niels andersen" Name "Niels Faurskov" has matched with "niels faurskov" Name "Niels Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Andersen" has matched with "niels andersen" Name "niels faurskov" has matched with "niels faurskov" Name "niels Faurskov" has matched with "niels faurskov" Name "niffddels Faurskovffre" has mismatched
-यहां इस कोड के लिए डेमो है, बस मामले में।
जटिलता
चूंकि आप न केवल किसी भी तरीके की परवाह कर रहे हैं, बल्कि इसके बारे में भी - यह कितना अच्छा है, आप देख सकते हैं कि ऐसा कोड काफी अत्यधिक संचालन करेगा। मेरा मतलब है, कम से कम, स्ट्रिंग भागों की पीढ़ी। यहाँ जटिलता में दो भाग होते हैं:
- स्ट्रिंग्स पार्ट्स जनरेशन पार्ट। यदि आप सभी स्ट्रिंग भागों को उत्पन्न करना चाहते हैं - जैसा कि मैंने ऊपर वर्णित किया है, आपको ऐसा करना होगा। सुधार के संभावित बिंदु - अनियंत्रित स्ट्रिंग सेट की पीढ़ी (जो क्रमपरिवर्तन से पहले आती है)। लेकिन फिर भी मुझे संदेह है कि यह किया जा सकता है क्योंकि प्रदान किए गए कोड में विधि उन्हें "जानवर-बल" के साथ उत्पन्न नहीं करेगी, बल्कि गणितीय रूप से गणना की जाती है (कार्डिनालिटी के साथ)
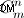 )
) - समानता जाँच भाग। यहां आपकी जटिलता दी गई समानता परीक्षक पर निर्भर करती है। उदाहरण के लिए,
similar_text()ओ (एन) जटिलता है, इस प्रकार बड़े तुलना सेट के साथ यह बेहद धीमा होगा।
लेकिन आप अभी भी मक्खी पर जाँच के साथ वर्तमान समाधान में सुधार कर सकते हैं। अब यह कोड पहले सभी स्ट्रिंग सब-सीक्वेंस जेनरेट करेगा और फिर उन्हें एक-एक करके चेक करना शुरू करेगा। सामान्य स्थिति में आपको ऐसा करने की आवश्यकता नहीं है, इसलिए आप इसे व्यवहार से बदलना चाह सकते हैं, जब अगला अनुक्रम उत्पन्न करने के बाद इसे तुरंत चेक किया जाएगा। फिर आप उन स्ट्रिंग्स के लिए प्रदर्शन बढ़ाएंगे जिनका उत्तर सकारात्मक है (लेकिन उनके लिए नहीं जिनका कोई मेल नहीं है)।