एक डेवलपर के रूप में मेरी सबसे बड़ी खुशी यह सीख रही है कि विभिन्न प्रौद्योगिकियां कैसे प्रतिच्छेद करती हैं।
इन वर्षों में मुझे विभिन्न प्रकार के सॉफ़्टवेयर और टूल के साथ काम करने का अवसर मिला है। मेरे द्वारा उपयोग किए गए कई टूल में से, पायथन और स्ट्रक्चर्ड क्वेरी लैंग्वेज (एसक्यूएल) मेरे पसंदीदा में से दो हैं।
इस लेख में मैं आपके साथ साझा करने जा रहा हूं कि पायथन और विभिन्न SQL डेटाबेस कैसे इंटरैक्ट करते हैं।
मैं सबसे लोकप्रिय डेटाबेस, SQLite, MySQL और PostgreSQL के बारे में बात करूँगा। मैं प्रत्येक डेटाबेस और संबंधित उपयोग के मामलों के प्रमुख अंतरों की व्याख्या करूँगा। और मैं लेख को कुछ पायथन कोड के साथ समाप्त करूंगा।
कोड आपको दिखाएगा कि PostgreSQL डेटाबेस से डेटा खींचने के लिए SQL क्वेरी कैसे लिखें और डेटा को पांडा डेटा फ़्रेम में संग्रहीत करें।
यदि आप रिलेशनल डेटाबेस (आरडीबीएमएस) से परिचित नहीं हैं, तो मेरा सुझाव है कि आप मूल आरडीबीएमएस शब्दावली पर समीर का लेख यहां देखें। शेष लेख समीर के लेख में संदर्भित शब्दों का उपयोग करेगा।
लोकप्रिय SQL डेटाबेस
SQLite
SQLite एक एकीकृत डेटाबेस होने के लिए सबसे अच्छी तरह से जाना जाता है। इसका मतलब है कि आपको डेटाबेस चलाने के लिए एक अतिरिक्त एप्लिकेशन इंस्टॉल करने या एक अलग सर्वर का उपयोग करने की आवश्यकता नहीं है।
यदि आप एक एमवीपी बना रहे हैं या आपको एक टन डेटा संग्रहण स्थान की आवश्यकता नहीं है, तो आप SQLite डेटाबेस के साथ जाना चाहेंगे।
पेशेवर यह है कि आप MySQL और PostgreSQL के सापेक्ष SQLite डेटाबेस के साथ तेज़ी से आगे बढ़ सकते हैं। उस ने कहा, आप सीमित कार्यक्षमता के साथ फंस जाएंगे। आप सुविधाओं को अनुकूलित करने या बहु-उपयोगकर्ता कार्यक्षमता का एक टन जोड़ने में सक्षम नहीं होंगे।
MySQL/PostgreSQL
MySQL और PostgreSQL के बीच अलग अंतर हैं। उस ने कहा, लेख के संदर्भ को देखते हुए, वे एक समान श्रेणी में फिट होते हैं।
एंटरप्राइज़ समाधान के लिए दोनों डेटाबेस प्रकार महान हैं। यदि आपको तेजी से स्केल करने की आवश्यकता है, तो MySQL और PostgreSQL आपकी सबसे अच्छी शर्त है। वे लंबी अवधि के बुनियादी ढांचे प्रदान करेंगे और आपकी सुरक्षा को मजबूत करेंगे।
उद्यमों के लिए उनके महान होने का एक और कारण यह है कि वे उच्च प्रदर्शन गतिविधियों को संभाल सकते हैं। लंबे समय तक डालने, अपडेट करने और बयानों का चयन करने के लिए बहुत अधिक कंप्यूटिंग शक्ति की आवश्यकता होती है। आप SQLite डेटाबेस की तुलना में कम विलंबता के साथ उन कथनों को लिखने में सक्षम होंगे।
पायथन और SQL डेटाबेस को क्यों कनेक्ट करें?
आप सोच रहे होंगे, "मुझे पायथन और SQL डेटाबेस को जोड़ने की परवाह क्यों करनी चाहिए?"
जब कोई पाइथन को SQL डेटाबेस से कनेक्ट करना चाहेगा तो कई उपयोग के मामले हैं। जैसा कि मैंने पहले उल्लेख किया है, हो सकता है कि आप एक वेब एप्लिकेशन पर काम कर रहे हों। इस मामले में, आपको एक SQL डेटाबेस कनेक्ट करना होगा ताकि आप वेब एप्लिकेशन से आने वाले डेटा को स्टोर कर सकें।
शायद आप डेटा इंजीनियरिंग में काम करते हैं और आपको एक स्वचालित ईटीएल पाइपलाइन बनाने की जरूरत है। पायथन को SQL डेटाबेस से कनेक्ट करने से आप इसकी स्वचालन क्षमताओं के लिए पायथन का उपयोग कर सकेंगे। आप विभिन्न डेटा स्रोतों के बीच संवाद करने में भी सक्षम होंगे। आपको विभिन्न प्रोग्रामिंग भाषाओं के बीच स्विच करने की आवश्यकता नहीं होगी।
पायथन और एक SQL डेटाबेस को जोड़ने से आपका डेटा विज्ञान कार्य अधिक सुविधाजनक हो जाएगा। आप SQL डेटाबेस से डेटा में हेरफेर करने के लिए अपने पायथन कौशल का उपयोग करने में सक्षम होंगे। आपको CSV फ़ाइल की आवश्यकता नहीं होगी।
पायथन और SQL डेटाबेस कैसे कनेक्ट होते हैं

पायथन और एसक्यूएल डेटाबेस कस्टम पायथन पुस्तकालयों के माध्यम से जुड़ते हैं। आप इन पुस्तकालयों को अपनी पायथन लिपि में आयात कर सकते हैं।
डेटाबेस-विशिष्ट पायथन पुस्तकालय पूरक निर्देशों के रूप में कार्य करते हैं। ये निर्देश आपके कंप्यूटर का मार्गदर्शन करते हैं कि यह आपके SQL डेटाबेस के साथ कैसे इंटरैक्ट कर सकता है। अन्यथा, आपका पायथन कोड उस डेटाबेस के लिए एक विदेशी भाषा होगा जिसे आप कनेक्ट करने का प्रयास कर रहे हैं।
प्रोजेक्ट कैसे सेटअप करें
उदाहरण के लिए, एक PostgreSQL डेटाबेस, AWS Redshift को लेते हैं। सबसे पहले, आप psycopg पुस्तकालय आयात करना चाहेंगे। यह PostgreSQL डेटाबेस के लिए एक सार्वभौमिक पायथन पुस्तकालय है।
#Library for connecting to AWS Redshift
import psycopg
#Library for reading the config file, which is in JSON
import json
#Data manipulation library
import pandas as pdआप देखेंगे कि हमने JSON और पांडा पुस्तकालयों को भी आयात किया है। हमने JSON आयात किया क्योंकि JSON कॉन्फ़िग फ़ाइल बनाना आपके डेटाबेस क्रेडेंशियल्स को संग्रहीत करने का एक सुरक्षित तरीका है। हम नहीं चाहते कि कोई और उन पर नज़र रखे!
पांडा पुस्तकालय आपको अपनी पायथन लिपि के लिए सभी पांडा की सांख्यिकीय क्षमताओं का उपयोग करने में सक्षम करेगा। इस उदाहरण में, लाइब्रेरी पायथन को आपकी SQL क्वेरी द्वारा लौटाए गए डेटा को डेटा फ़्रेम में संग्रहीत करने में सक्षम बनाएगी।
इसके बाद, आप अपनी कॉन्फ़िग फ़ाइल को एक्सेस करना चाहेंगे। json.load() फ़ंक्शन JSON फ़ाइल को पढ़ता है ताकि आप अगले चरण में अपने डेटाबेस क्रेडेंशियल तक पहुंच सकें।
config_file = open(r"C:\Users\yourname\config.json")
config = json.load(config_file)
अब जब आपकी पायथन स्क्रिप्ट आपकी JSON कॉन्फ़िग फ़ाइल तक पहुँच सकती है, तो आप एक डेटाबेस कनेक्शन बनाना चाहेंगे। आपको अपनी कॉन्फ़िग फ़ाइल के क्रेडेंशियल्स को पढ़ना और उनका उपयोग करना होगा:
con = psycopg2.connect(dbname= "db_name", host=config[hostname], port = config["port"],user=config["user_id"], password=config["password_key"])
cur = con.cursor()आपने अभी-अभी एक डेटाबेस कनेक्शन बनाया है! जब आपने psycopg लाइब्रेरी को इंपोर्ट किया था, तो आपने ऊपर लिखे गए पायथन कोड का अनुवाद PostgreSQL डेटाबेस (AWS Redshift) से करने के लिए किया था।
अपने आप में, AWS Redshift उपरोक्त कोड को नहीं समझेगा। लेकिन चूँकि आपने psycopg पुस्तकालय आयात किया है, अब आप एक ऐसी भाषा बोलते हैं जिसे AWS Redshift समझ सकता है।
पायथन के बारे में अच्छी बात यह है कि इसमें SQLite, MySQL और PostgreSQL के लिए पुस्तकालय हैं। आप तकनीकों को आसानी से एकीकृत करने में सक्षम होंगे।
SQL क्वेरी कैसे लिखें
बेझिझक यूरोपीय फ़ुटबॉल डेटा को अपने PostgreSQL डेटाबेस में डाउनलोड करें। मैं इस उदाहरण के लिए इसके डेटा का उपयोग करूँगा।
अंतिम चरण में आपके द्वारा बनाया गया डेटाबेस कनेक्शन आपको SQL लिखने देता है और फिर डेटा को पायथन के अनुकूल डेटा संरचना में संग्रहीत करता है। अब जब आपने डेटाबेस कनेक्शन स्थापित कर लिया है, तो आप डेटा खींचना शुरू करने के लिए एक SQL क्वेरी लिख सकते हैं:
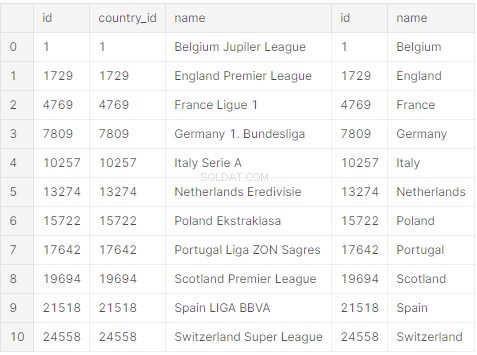
query = "SELECT *
FROM League
JOIN Country ON Country.id = League.country_id;"हालांकि अभी काम नहीं हुआ है। आपको कुछ अतिरिक्त पायथन कोड लिखने की आवश्यकता है जो SQL क्वेरी को निष्पादित करता है:
#Runs your SQL query
execute1 = cur.execute(query)
result = cur.fetchall()फिर आपको लौटाए गए डेटा को पांडा डेटा फ़्रेम में संग्रहीत करने की आवश्यकता है:
#Create initial dataframe from SQL data
raw_initial_df = pd.read_sql_query(query, con)
print(raw_initial_df)आपको एक पांडा डेटा फ्रेम (raw_initial_df) मिलना चाहिए जो कुछ इस तरह दिखता है:
हर किसी के लिए एक डेटाबेस है

SQLite, MySQL और PostgreSQL सभी के अपने फायदे और नुकसान हैं। जिसे आप चुनते हैं वह आपकी परियोजना या कंपनी की जरूरतों पर निर्भर होना चाहिए। आपको यह भी विचार करना चाहिए कि सड़क के नीचे कई वर्षों के मुकाबले आपको अभी क्या चाहिए।
याद रखने वाली महत्वपूर्ण बात यह है कि पायथन प्रत्येक डेटाबेस प्रकार के साथ एकीकृत हो सकता है।
यह आलेख पाइथन को SQL डेटाबेस से कनेक्ट करने के साथ क्या संभव है, इसके लिए सतह को खरोंचता है। मुझे अविश्वसनीय मूल्य जोड़ने के लिए सॉफ़्टवेयर इंटरसेक्ट और गठबंधन करने के तरीकों को देखना अच्छा लगता है।
यदि आप इस प्रकार की और अधिक सामग्री चाहते हैं, तो आप मुझे कोर्स टू हायर पर पा सकते हैं! मैं अधिक लोगों को यह सीखने में मदद करना चाहता हूं कि तकनीक में नौकरी कैसे कोडित और लैंड करना है। कृपया किसी भी प्रश्न के लिए संपर्क करें या यदि आप केवल नमस्ते कहना चाहते हैं :)