postgresql.conf में बदलाव करते समय , आपने देखा होगा कि full_page_writes . नामक एक विकल्प है . इसके आगे की टिप्पणी आंशिक पृष्ठ के बारे में कुछ कहती है, और लोग आमतौर पर इसे on . पर सेट कर देते हैं - जो अच्छी बात है, जैसा कि मैं इस पोस्ट में बाद में बताऊंगा। हालांकि यह समझना उपयोगी है कि पूरा पृष्ठ क्या लिखता है, क्योंकि प्रदर्शन पर प्रभाव काफी महत्वपूर्ण हो सकता है।
चेकपॉइंट ट्यूनिंग पर मेरी पिछली पोस्ट के विपरीत, यह एक गाइड नहीं है कि सर्वर को कैसे ट्यून किया जाए। आप वास्तव में बहुत कुछ नहीं बदल सकते हैं, लेकिन मैं आपको दिखाऊंगा कि कैसे कुछ एप्लिकेशन-स्तरीय निर्णय (जैसे डेटा प्रकारों की पसंद) पूरे पेज राइट्स के साथ इंटरैक्ट कर सकते हैं।
आंशिक लेखन / फटे पृष्ठ
तो फुल पेज किस बारे में लिखता है? postgresql.conf में टिप्पणी के रूप में कहते हैं कि यह आंशिक पृष्ठ से पुनर्प्राप्त करने का एक तरीका है लिखता है - PostgreSQL 8kB पृष्ठों (डिफ़ॉल्ट रूप से) का उपयोग करता है, लेकिन स्टैक के अन्य भाग विभिन्न चंक आकारों का उपयोग करते हैं। लिनक्स फाइल सिस्टम आमतौर पर 4kB पृष्ठों का उपयोग करते हैं (छोटे पृष्ठों का उपयोग करना संभव है, लेकिन 4kB x86 पर अधिकतम है), और हार्डवेयर स्तर पर पुराने ड्राइव 512B सेक्टर का उपयोग करते हैं जबकि नए डिवाइस अक्सर बड़े हिस्से में डेटा लिखते हैं (अक्सर 4kB या यहां तक कि 8kB) ।
इसलिए जब PostgreSQL 8kB पेज लिखता है, तो स्टोरेज स्टैक की अन्य परतें इसे छोटे टुकड़ों में तोड़ सकती हैं, जिन्हें अलग से प्रबंधित किया जाता है। यह परमाणुता लिखने के संबंध में एक समस्या प्रस्तुत करता है। 8kB PostgreSQL पेज को दो 4kB फाइल सिस्टम पेजों में और फिर 512B सेक्टरों में विभाजित किया जा सकता है। अब, क्या होगा यदि सर्वर क्रैश हो जाता है (बिजली की विफलता, कर्नेल बग,…)?
भले ही सर्वर ऐसी विफलताओं से निपटने के लिए डिज़ाइन किए गए स्टोरेज सिस्टम का उपयोग करता है (कैपेसिटर के साथ एसएसडी, बैटरी के साथ RAID नियंत्रक, ...), कर्नेल पहले से ही डेटा को 4kB पृष्ठों में विभाजित कर देता है। इसलिए यह संभव है कि डेटाबेस ने 8kB डेटा पेज लिखा हो, लेकिन क्रैश से पहले इसका केवल एक हिस्सा डिस्क पर बना था।
इस बिंदु पर अब आप शायद सोच रहे हैं कि यही कारण है कि हमारे पास लेनदेन लॉग (वाल) है, और आप सही हैं! तो सर्वर शुरू करने के बाद, डेटाबेस WAL (अंतिम पूर्ण चेकपॉइंट के बाद से) पढ़ेगा, और यह सुनिश्चित करने के लिए कि डेटा फ़ाइलें पूर्ण हैं, परिवर्तनों को फिर से लागू करें। सरल।
लेकिन एक पकड़ है - पुनर्प्राप्ति अंधाधुंध रूप से परिवर्तनों को लागू नहीं करती है, इसे अक्सर डेटा पृष्ठों आदि को पढ़ने की आवश्यकता होती है। जो मानता है कि पृष्ठ पहले से ही किसी तरह से बोर्क नहीं है, उदाहरण के लिए आंशिक लेखन के कारण। जो थोड़ा विरोधाभासी लगता है, क्योंकि डेटा भ्रष्टाचार को ठीक करने के लिए हम मानते हैं कि कोई डेटा भ्रष्टाचार नहीं है।
पूर्ण पृष्ठ लेखन इस पहेली को हल करने का एक तरीका है - जब किसी चेकपॉइंट के बाद पहली बार किसी पृष्ठ को संशोधित किया जाता है, तो पूरा पृष्ठ WAL में लिखा जाता है। यह गारंटी देता है कि पुनर्प्राप्ति के दौरान, किसी पृष्ठ को छूने वाले पहले WAL रिकॉर्ड में संपूर्ण पृष्ठ होता है, जिससे डेटा फ़ाइल से - संभवतः टूटे हुए - पृष्ठ को पढ़ने की आवश्यकता समाप्त हो जाती है।
प्रवर्धन लिखें
बेशक, इसका नकारात्मक परिणाम WAL आकार में वृद्धि है - 8kB पृष्ठ पर एक बाइट को बदलने से पूरा WAL में लॉग हो जाएगा। पूर्ण पृष्ठ लेखन केवल चेकपॉइंट के बाद पहली बार लिखने पर होता है, इसलिए चौकियों को कम बार-बार बनाना स्थिति को सुधारने का एक तरीका है - आम तौर पर, चेकपॉइंट के बाद पूर्ण पृष्ठ लिखने का एक छोटा "विस्फोट" होता है, और फिर अपेक्षाकृत कुछ पूर्ण पृष्ठ लिखते हैं चौकी के अंत तक।
UUID बनाम BIGSERIAL कुंजियाँ
लेकिन एप्लिकेशन स्तर पर किए गए डिज़ाइन निर्णयों के साथ कुछ अनपेक्षित इंटरैक्शन हैं। आइए मान लें कि हमारे पास प्राथमिक कुंजी के साथ एक साधारण तालिका है, या तो BIGSERIAL या UUID , और हम इसमें डेटा डालते हैं। क्या उत्पन्न WAL की मात्रा में कोई अंतर होगा (यह मानते हुए कि हम समान पंक्तियों को सम्मिलित करते हैं)?
दोनों मामलों में WAL की समान मात्रा के उत्पादन की अपेक्षा करना उचित प्रतीत होता है, लेकिन जैसा कि निम्नलिखित चार्ट बताते हैं, व्यवहार में बहुत बड़ा अंतर है।
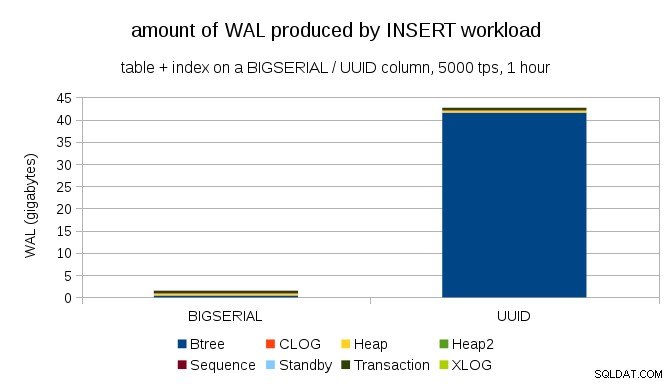
यह 1h बेंचमार्क के दौरान उत्पादित WAL की मात्रा को दर्शाता है, जो प्रति सेकंड 5000 इंसर्ट तक सीमित है। BIGSERIAL के साथ प्राथमिक कुंजी यह ~2GB WAL उत्पन्न करती है, जबकि UUID . के साथ यह 40GB से अधिक है। यह काफी महत्वपूर्ण अंतर है, और स्पष्ट रूप से अधिकांश WAL प्राथमिक कुंजी का समर्थन करने वाले सूचकांक से जुड़ा है। आइए WAL रिकॉर्ड के प्रकार देखें।
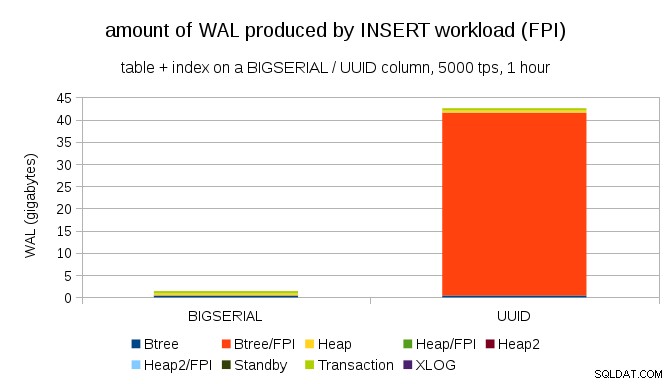
स्पष्ट रूप से, अधिकांश रिकॉर्ड पूर्ण-पृष्ठ चित्र (FPI) हैं, अर्थात पूर्ण-पृष्ठ लेखन का परिणाम है। लेकिन ऐसा क्यों हो रहा है?
बेशक, यह अंतर्निहित UUID . के कारण है यादृच्छिकता। BIGSERIAL के साथ नए अनुक्रमिक हैं, और इसलिए btree अनुक्रमणिका में एक ही पत्ते के पृष्ठों में सम्मिलित हो जाते हैं। चूंकि किसी पृष्ठ में केवल पहला संशोधन पूर्ण-पृष्ठ लेखन को ट्रिगर करता है, WAL रिकॉर्ड का केवल एक छोटा अंश FPI है। UUID के साथ यह पूरी तरह से अलग मामला है, क्योंकि मान बिल्कुल भी अनुक्रमिक नहीं हैं, वास्तव में प्रत्येक इंसर्ट के पूरी तरह से नए लीफ इंडेक्स लीफ पेज को छूने की संभावना है (यह मानते हुए कि इंडेक्स काफी बड़ा है)।
डेटाबेस बहुत कुछ नहीं कर सकता है - कार्यभार प्रकृति में बस यादृच्छिक है, कई पूर्ण-पृष्ठ लेखन को ट्रिगर करता है।
BIGSERIAL . के साथ भी समान लेखन प्रवर्धन प्राप्त करना कठिन नहीं है चाबियाँ, बिल्कुल। इसके लिए केवल अलग कार्यभार की आवश्यकता होती है - उदाहरण के लिए UPDATE . के साथ कार्यभार, एकसमान वितरण के साथ बेतरतीब ढंग से रिकॉर्ड अपडेट करना, चार्ट इस तरह दिखता है:
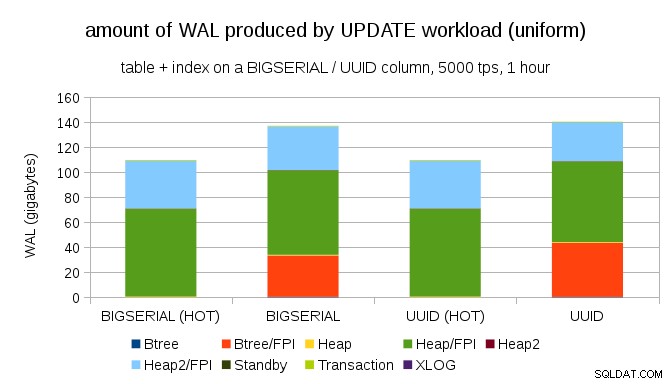
अचानक, डेटा प्रकारों के बीच अंतर समाप्त हो गया है - दोनों मामलों में पहुंच यादृच्छिक है, जिसके परिणामस्वरूप लगभग समान मात्रा में WAL का उत्पादन होता है। एक और अंतर यह है कि अधिकांश वाल "हीप" से जुड़ा है, यानी टेबल, और इंडेक्स नहीं। "HOT" मामलों को HOT UPDATE ऑप्टिमाइज़ेशन (यानी किसी इंडेक्स को छुए बिना अपडेट) की अनुमति देने के लिए डिज़ाइन किया गया था, जो सभी इंडेक्स-संबंधित WAL ट्रैफ़िक को काफी हद तक समाप्त कर देता है।
लेकिन आप यह तर्क दे सकते हैं कि अधिकांश एप्लिकेशन संपूर्ण डेटा सेट को अपडेट नहीं करते हैं। आमतौर पर, डेटा का केवल एक छोटा सा उपसमूह ही "सक्रिय" होता है - लोग केवल चर्चा मंच पर पिछले कुछ दिनों की पोस्ट, ई-शॉप में अनसुलझे ऑर्डर आदि तक पहुंचते हैं। यह परिणाम कैसे बदलता है?
शुक्र है, पीजीबेंच गैर-समान वितरण का समर्थन करता है, और उदाहरण के लिए डेटा के 1% सबसेट को छूने वाले घातीय वितरण के साथ ~ 25%, चार्ट इस तरह दिखता है:
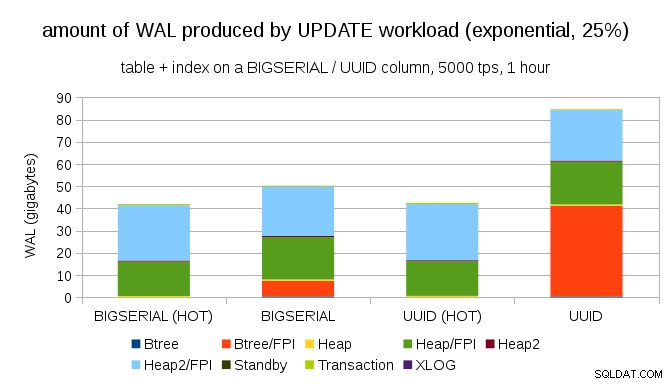
और वितरण को और अधिक विषम बनाने के बाद, 1% उपसमुच्चय ~75% समय को छूते हुए:
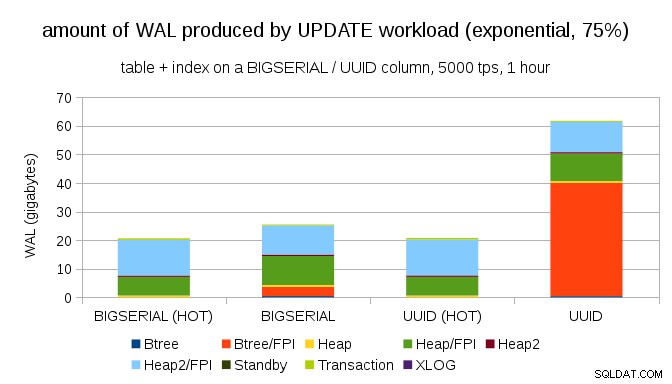
यह फिर से दिखाता है कि डेटा प्रकारों की पसंद में कितना बड़ा अंतर हो सकता है, और HOT अपडेट के लिए ट्यूनिंग का महत्व भी।
8kB और 4kB पेज
एक दिलचस्प सवाल यह है कि हम PostgreSQL में छोटे पृष्ठों का उपयोग करके कितना WAL ट्रैफ़िक बचा सकते हैं (जिसमें एक कस्टम पैकेज संकलित करने की आवश्यकता होती है)। सबसे अच्छे मामले में, यह 50% तक WAL बचा सकता है, धन्यवाद 8kB पृष्ठों के बजाय केवल 4kB लॉगिंग के लिए। समान रूप से वितरित अद्यतन के साथ कार्यभार के लिए यह इस तरह दिखता है:
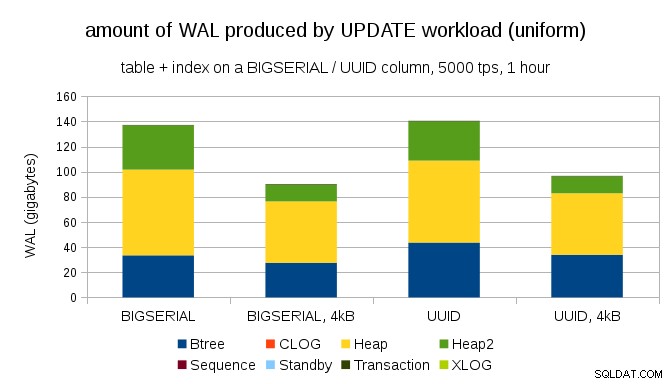
तो बचत बिल्कुल 50% नहीं है, लेकिन ~140GB से ~90GB तक की कमी अभी भी काफी महत्वपूर्ण है।
क्या हमें अभी भी पूर्ण-पृष्ठ लेखन की आवश्यकता है?
आंशिक लेखन के खतरे की व्याख्या करने के बाद यह हास्यास्पद लग सकता है, लेकिन हो सकता है कि पूर्ण पृष्ठ लेखन को अक्षम करना कम से कम कुछ मामलों में एक व्यवहार्य विकल्प हो।
सबसे पहले, मुझे आश्चर्य है कि क्या आधुनिक लिनक्स फाइल सिस्टम अभी भी आंशिक लेखन के लिए कमजोर हैं? पैरामीटर को 2005 में जारी PostgreSQL 8.1 में पेश किया गया था, इसलिए शायद तब से पेश किए गए कई फाइल सिस्टम सुधारों में से कुछ इसे एक गैर-मुद्दा बनाते हैं। संभवतः मनमाने ढंग से कार्यभार के लिए सार्वभौमिक रूप से नहीं, लेकिन हो सकता है कि कुछ अतिरिक्त शर्त (जैसे PostgreSQL में 4kB पृष्ठ आकार का उपयोग करना) पर्याप्त होगा? साथ ही, PostgreSQL कभी भी 8kB पृष्ठ के केवल एक उपसमुच्चय को अधिलेखित नहीं करता है - पूरा पृष्ठ हमेशा लिखा जाता है।
मैंने हाल ही में आंशिक लेखन को ट्रिगर करने की कोशिश में बहुत सारे परीक्षण किए हैं, और मैं अभी तक एक भी मामला पैदा करने में कामयाब नहीं हुआ हूं। बेशक, यह वास्तव में प्रमाण नहीं है कि समस्या मौजूद नहीं है। लेकिन अगर यह अभी भी एक समस्या है, तो डेटा चेकसम पर्याप्त सुरक्षा हो सकता है (यह समस्या को ठीक नहीं करेगा, लेकिन कम से कम आपको बताएगा कि एक टूटा हुआ पृष्ठ है)।
दूसरे, आजकल कई प्रणालियाँ प्रतिकृति प्रतिकृतियों को स्ट्रीमिंग पर निर्भर करती हैं - हार्डवेयर समस्या (जिसमें काफी लंबा समय लग सकता है) के बाद सर्वर के रीबूट होने की प्रतीक्षा करने के बजाय और फिर पुनर्प्राप्ति करने में अधिक समय व्यतीत करने के बजाय, सिस्टम बस एक हॉट स्टैंडबाय पर स्विच हो जाता है। यदि विफल प्राथमिक पर डेटाबेस हटा दिया जाता है (और फिर नए प्राथमिक से क्लोन किया जाता है), तो आंशिक लेखन एक गैर-मुद्दा है।
लेकिन मुझे लगता है कि अगर हमने इसकी सिफारिश करना शुरू कर दिया, तो "मुझे नहीं पता कि डेटा कैसे दूषित हो गया, मैंने सिस्टम पर अभी-अभी full_page_writes=off सेट किया है!" डीबीए के लिए मृत्यु से ठीक पहले सबसे आम वाक्यों में से एक बन जाएगा (साथ में "मैंने इस सांप को रेडिट पर देखा है, यह जहरीला नहीं है।")।
सारांश
पूर्ण-पृष्ठ लेखन को सीधे ट्यून करने के लिए आप बहुत कुछ नहीं कर सकते। अधिकांश कार्यभार के लिए, अधिकांश पूर्ण-पृष्ठ लेखन एक चेकपॉइंट के ठीक बाद होते हैं, और फिर अगले चेकपॉइंट तक गायब हो जाते हैं। इसलिए यह महत्वपूर्ण है कि चौकियों को ट्यून किया जाए ताकि बार-बार ऐसा न हो।
कुछ एप्लिकेशन-स्तरीय निर्णय टेबल और इंडेक्स में लिखने की यादृच्छिकता को बढ़ा सकते हैं - उदाहरण के लिए यूयूआईडी मान स्वाभाविक रूप से यादृच्छिक होते हैं, यहां तक कि साधारण INSERT वर्कलोड को यादृच्छिक इंडेक्स अपडेट में बदल देते हैं। उदाहरणों में इस्तेमाल किया गया स्कीमा बल्कि तुच्छ था - व्यवहार में द्वितीयक अनुक्रमणिका, विदेशी कुंजी आदि होंगे। लेकिन आंतरिक रूप से BIGSERIAL प्राथमिक कुंजियों का उपयोग करना (और UUID को सरोगेट कुंजियों के रूप में रखना) कम से कम लेखन प्रवर्धन को कम करेगा।
मुझे वर्तमान कर्नेल / फाइल सिस्टम पर पूर्ण-पृष्ठ लिखने की आवश्यकता के बारे में चर्चा करने में वास्तव में दिलचस्पी है। दुख की बात है कि मुझे कई संसाधन नहीं मिले, इसलिए यदि आपके पास प्रासंगिक जानकारी है, तो मुझे बताएं।