हालांकि भविष्य में अधिकांश डेटाबेस सर्वर (विशेष रूप से ओएलटीपी जैसे वर्कलोड को संभालने वाले) फ्लैश-आधारित स्टोरेज का उपयोग करेंगे, हम अभी तक वहां नहीं हैं - फ्लैश स्टोरेज अभी भी पारंपरिक हार्ड ड्राइव की तुलना में काफी अधिक महंगा है, और कई सिस्टम एक मिश्रण का उपयोग करते हैं। SSD और HDD ड्राइव की। हालांकि इसका मतलब है कि हमें यह तय करने की आवश्यकता है कि डेटाबेस को कैसे विभाजित किया जाए - कताई जंग (एचडीडी) में क्या जाना चाहिए और फ्लैश स्टोरेज के लिए एक अच्छा उम्मीदवार क्या है जो अधिक महंगा है लेकिन यादृच्छिक I/O को संभालने में बेहतर है।
ऐसे समाधान हैं जो एसएसडी को कैश के रूप में स्वचालित रूप से उपयोग करके भंडारण स्तर पर स्वचालित रूप से इसे संभालने का प्रयास करते हैं, स्वचालित रूप से एसएसडी पर डेटा के सक्रिय भाग को रखते हैं। भंडारण उपकरण / SAN अक्सर आंतरिक रूप से ऐसा करते हैं, एक ही पैकेज में बड़े HDD और छोटे SSD के साथ हाइब्रिड SATA/SAS ड्राइव होते हैं, और निश्चित रूप से सीधे होस्ट पर ऐसा करने के लिए समाधान हैं - उदाहरण के लिए Linux, LVM में dm-cache है 2014 में भी ऐसी क्षमता (डीएम-कैश के शीर्ष पर निर्मित) मिली, और निश्चित रूप से ZFS के पास L2ARC है।
लेकिन आइए उन सभी स्वचालित विकल्पों को अनदेखा करें, और मान लें कि हमारे पास सिस्टम से सीधे जुड़े दो डिवाइस हैं - एक एचडीडी पर आधारित, दूसरा फ्लैश-आधारित। महंगे फ्लैश का अधिकतम लाभ उठाने के लिए आपको डेटाबेस को कैसे विभाजित करना चाहिए? एक आमतौर पर इस्तेमाल किया जाने वाला पैटर्न ऑब्जेक्ट प्रकार, विशेष रूप से टेबल बनाम इंडेक्स द्वारा ऐसा करना है। जो सामान्य रूप से समझ में आता है, लेकिन हम अक्सर लोगों को एसएसडी स्टोरेज पर इंडेक्स रखते हुए देखते हैं, क्योंकि इंडेक्स यादृच्छिक I/O से जुड़े होते हैं। हालांकि यह उचित लग सकता है, यह पता चलता है कि यह बिल्कुल विपरीत है जो आपको करना चाहिए।
मैं आपको एक बेंचमार्क दिखाता हूं ...
मुझे इसे HDD स्टोरेज (RAID10 4x 10k SAS ड्राइव से निर्मित) और एक SSD डिवाइस (Intel S3700) दोनों के साथ एक सिस्टम पर प्रदर्शित करने दें। सिस्टम में 16GB RAM है, तो चलिए 300 (=4.5GB) और 3000 (=45GB) स्केल के साथ pgbench का उपयोग करते हैं, यानी एक जो आसानी से RAM और कई RAM में फिट हो जाता है। फिर टेबल और इंडेक्स को अलग-अलग स्टोरेज सिस्टम (टेबलस्पेस का उपयोग करके) पर रखें और प्रदर्शन को मापें। हार्डवेयर संसाधनों के संबंध में डेटाबेस क्लस्टर यथोचित रूप से कॉन्फ़िगर किया गया था (साझा बफर, वाल सीमा आदि)। WAL को एक अलग SSD डिवाइस पर रखा गया था, जिसे SAS ड्राइव के साथ साझा किए गए RAID नियंत्रक से जोड़ा गया था।
छोटे (4.5GB) डेटा सेट पर, परिणाम इस तरह दिखते हैं (ध्यान दें कि y-अक्ष 3000 tps पर शुरू होता है):
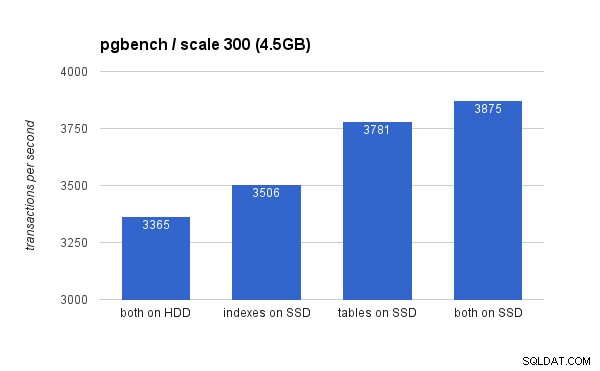
स्पष्ट रूप से, SSD पर अनुक्रमणिका रखने से तालिकाओं के लिए SSD का उपयोग करने की तुलना में कम लाभ मिलता है। जबकि डेटासेट आसानी से रैम में फिट हो जाता है, परिवर्तनों को अंततः डिस्क पर लिखने की आवश्यकता होती है, और जबकि RAID नियंत्रक के पास एक कैश होता है, यह वास्तव में फ्लैश स्टोरेज के साथ प्रतिस्पर्धा नहीं कर सकता है। नए RAID नियंत्रक शायद थोड़ा बेहतर प्रदर्शन करेंगे, लेकिन ऐसा ही नए SSD ड्राइव करेंगे।
बड़े डेटा सेट पर, अंतर बहुत अधिक महत्वपूर्ण हैं (इस बार y-अक्ष 0 से शुरू होता है):
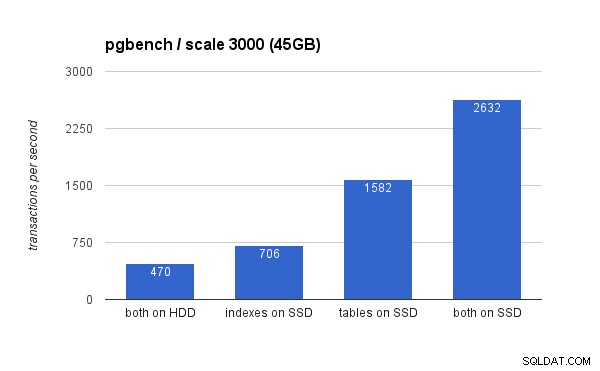
एसएसडी पर इंडेक्स रखने से महत्वपूर्ण प्रदर्शन लाभ होता है (लगभग 50%, एचडीडी स्टोरेज को बेसलाइन के रूप में लेते हुए), लेकिन एसएसडी में टेबल को स्थानांतरित करने से 200% से अधिक प्राप्त करके आसानी से हरा दिया जाता है। बेशक, यदि आप SSDs पर टेबल और इंडेक्स दोनों रखते हैं, तो आपको प्रदर्शन में और सुधार होगा - लेकिन यदि आप ऐसा कर सकते हैं, तो आपको अन्य मामलों के बारे में चिंता करने की आवश्यकता नहीं है।
लेकिन क्यों?
एसएसडी पर टेबल रखने से बेहतर प्रदर्शन प्राप्त करना थोड़ा सहज ज्ञान युक्त लग सकता है, तो यह ऐसा व्यवहार क्यों करता है? खैर, यह शायद कई कारकों का संयोजन है:
- सूचकांक आमतौर पर तालिकाओं की तुलना में बहुत छोटे होते हैं, और इस प्रकार स्मृति में अधिक आसानी से फिट हो जाते हैं
- अनुक्रमणिका के स्तर वाले पृष्ठ (पेड़ में) आमतौर पर काफी गर्म होते हैं, और इस प्रकार स्मृति में बने रहते हैं
- स्कैनिंग और इंडेक्स करते समय, वास्तविक I/O का अधिकांश भाग अनुक्रमिक प्रकृति का होता है (विशेषकर लीफ पेजों के लिए)
इसका परिणाम यह है कि इंडेक्स के खिलाफ I/O की आश्चर्यजनक मात्रा या तो बिल्कुल नहीं होती है (कैशिंग के लिए धन्यवाद) या अनुक्रमिक है। दूसरी ओर, अनुक्रमणिका तालिकाओं के विरुद्ध यादृच्छिक I/O का एक बड़ा स्रोत हैं।
हालांकि यह अधिक जटिल है...
बेशक, यह एक साधारण उदाहरण था, और उदाहरण के लिए, काफी भिन्न कार्यभार के लिए निष्कर्ष भिन्न हो सकते हैं। इसी तरह, चूंकि एसएसडी अधिक महंगे हैं, सिस्टम में एसएसडी ड्राइव की तुलना में एचडीडी ड्राइव पर अधिक डिस्क स्थान होता है, इसलिए टेबल एसएसडी पर फिट नहीं हो सकते हैं जबकि इंडेक्स होंगे। उन मामलों में एक अधिक विस्तृत प्लेसमेंट आवश्यक है - उदाहरण के लिए न केवल वस्तु के प्रकार पर विचार करना, बल्कि यह भी कि यह कितनी बार उपयोग किया जाता है (और केवल भारी उपयोग की गई तालिकाओं को SSDs में स्थानांतरित करना), या यहां तक कि तालिकाओं के सबसेट (जैसे धीरे-धीरे पुराने को स्थानांतरित करना) SSD से HDD तक का डेटा)।