पिछले लेख में, हमने SQL सर्वर इंडेक्स की ज़रूरतों और परफ़ॉर्मेंस से जुड़ी बातों की पड़ताल की थी. जब डेटाबेस के प्रदर्शन की बात आती है, तो प्रदर्शन ट्यूनिंग बिना किसी प्रश्न के सबसे महत्वपूर्ण और जटिल कार्यों में से एक है। इसमें SQL क्वेरी ऑप्टिमाइज़ेशन, इंडेक्स ट्यूनिंग और सिस्टम रिसोर्स ट्यूनिंग जैसे कई अलग-अलग क्षेत्र शामिल हैं, जिनमें से सभी को सफलतापूर्वक डेटा को जल्दी से पुनर्प्राप्त करने के लिए सही ढंग से निष्पादित करने की आवश्यकता है।
जब SQL सर्वर अनुक्रमणिका की बात आती है तो विचार करने के लिए कई महत्वपूर्ण क्षेत्र हैं, क्योंकि वे आपके प्रदर्शन ट्यूनिंग प्रयासों और समग्र डेटाबेस प्रदर्शन दोनों पर महत्वपूर्ण प्रभाव डाल सकते हैं। नीचे प्रत्येक और उनके द्वारा निभाई जाने वाली महत्वपूर्ण भूमिकाओं के बारे में कुछ विवरण दिए गए हैं।
SQL सर्वर अनुक्रमणिका सर्वोत्तम अभ्यास
1. समझें कि डेटाबेस डिज़ाइन SQL सर्वर अनुक्रमणिका को कैसे प्रभावित करता है
ऑनलाइन लेनदेन प्रसंस्करण (OLTP) और ऑनलाइन विश्लेषणात्मक प्रसंस्करण (OLAP) डेटाबेस के बीच अनुक्रमण आवश्यकताएं भिन्न होती हैं।
OLTP डेटाबेस में, उपयोगकर्ता बार-बार रीड-राइट ऑपरेशन करते हैं, नया डेटा सम्मिलित करते हैं और मौजूदा डेटा को संशोधित करते हैं। वे डेटा पुनर्प्राप्ति और संशोधनों के लिए चयन कथनों के साथ डेटा हेरफेर भाषा प्रश्नों (सम्मिलित करें, अपडेट करें, हटाएं) का उपयोग करते हैं। OLTP डेटाबेस के लिए, किसी तालिका के चयनित कॉलम पर अनुक्रमणिका बनाना सबसे अच्छा है। एकाधिक अनुक्रमणिका नकारात्मक प्रदर्शन प्रभाव डाल सकती हैं और सिस्टम संसाधनों पर दबाव डाल सकती हैं। इसके बजाय, अनुक्रमणिका की न्यूनतम संख्या बनाने की अनुशंसा की जाती है जो आपकी अनुक्रमण आवश्यकताओं को पूरा कर सके। दूसरी ओर, OLAP डेटाबेस में, आप अधिक विश्लेषणात्मक उद्देश्यों के लिए डेटा को पुनः प्राप्त करने के लिए ज्यादातर सेलेक्ट स्टेटमेंट का उपयोग करते हैं। इस मामले में, आप प्रति अनुक्रमणिका एकाधिक कुंजी कॉलम के साथ अधिक अनुक्रमणिका जोड़ सकते हैं। डेटा वेयरहाउस क्वेरीज़ में तेज़ी से डेटा पुनर्प्राप्ति के लिए आप कॉलमस्टोर इंडेक्स का भी लाभ उठा सकते हैं
2. अपनी कार्यभार आवश्यकताओं के लिए अनुक्रमणिका बनाएं
अपने डेटाबेस में एक नई तालिका बनाते समय, केवल इंडेक्स को आँख बंद करके न जोड़ें। कभी-कभी, डेवलपर्स उन इंडेक्स का उपयोग करने वाले प्रश्नों की तलाश किए बिना उस पर एक क्लस्टर इंडेक्स और कुछ गैर-क्लस्टर इंडेक्स डालते हैं। एक इंडेक्स हो सकता है जो क्वेरी ऑप्टिमाइज़र आवश्यकता को पूरा नहीं करता है; इसलिए, आपको अपने कार्यभार और SQL प्रश्नों (संग्रहीत कार्यविधियों, कार्यों, विचारों और तदर्थ प्रश्नों) का ठीक से विश्लेषण करना चाहिए। आप SQL प्रोफाइलर, विस्तारित ईवेंट और गतिशील प्रबंधन दृश्यों का उपयोग करके कार्यभार को कैप्चर कर सकते हैं, और फिर संसाधन-गहन प्रश्नों को अनुकूलित करने के लिए अनुक्रमणिका बना सकते हैं।
3. सबसे अधिक और अक्सर उपयोग की जाने वाली क्वेरी के लिए अनुक्रमणिका बनाएं
आपके सिस्टम में सबसे अधिक उपयोग की जाने वाली क्वेरी के लिए वर्कलोड को समूहीकृत करना महत्वपूर्ण है। इन प्रश्नों के लिए सर्वोत्तम अनुक्रमणिका बनाकर, यह आपके सिस्टम पर कम से कम दबाव डालेगा।
4. SQL सर्वर अनुक्रमणिका कुंजी स्तंभ सर्वोत्तम अभ्यास लागू करें
चूंकि आपके पास एक टेबल में कई कॉलम हो सकते हैं, इंडेक्स कुंजी कॉलम के लिए यहां कुछ विचार दिए गए हैं।
- पाठ्य, छवि, ntext, varchar(max), nvarchar(max) और varbinary(max) वाले स्तंभों का उपयोग अनुक्रमणिका कुंजी स्तंभों में नहीं किया जा सकता है।
- सूचकांक कुंजी कॉलम में एक पूर्णांक डेटा प्रकार का उपयोग करने की अनुशंसा की जाती है। इसमें कम जगह की आवश्यकता होती है और यह कुशलता से काम करता है। इस वजह से, आप आमतौर पर एक पूर्णांक डेटा प्रकार पर प्राथमिक कुंजी कॉलम बनाना चाहेंगे।
- आप XML डेटा प्रकार का उपयोग केवल XML अनुक्रमणिका में कर सकते हैं।
- आपको अद्वितीय मानों वाले कॉलम के लिए प्राथमिक कुंजी बनाने पर विचार करना चाहिए। यदि किसी तालिका में कोई अद्वितीय मान कॉलम नहीं है, तो आप एक पूर्णांक डेटा प्रकार के लिए एक पहचान कॉलम परिभाषित कर सकते हैं। प्राथमिक कुंजी पंक्ति वितरण के लिए एक संकुल अनुक्रमणिका भी बनाती है।
- आप एक उपयोगी इंडेक्स कुंजी उम्मीदवार के रूप में अद्वितीय और नॉट NULL मानों वाले कॉलम पर विचार कर सकते हैं।
- आपको व्हेयर क्लॉज में विधेय के आधार पर एक इंडेक्स बनाना चाहिए। उदाहरण के लिए, आप व्हेयर क्लॉज में इस्तेमाल किए गए कॉलम पर विचार कर सकते हैं, SQL जॉइन करता है, जैसे, ऑर्डर बाय, ग्रुप बाय प्रेडिकेट्स, और इसी तरह।
- आपको तालिकाओं में इस तरह शामिल होना चाहिए जिससे शेष क्वेरी के लिए पंक्तियों की संख्या कम हो जाए। यह क्वेरी अनुकूलक को न्यूनतम सिस्टम संसाधनों के साथ निष्पादन योजना तैयार करने में मदद करेगा।
- यदि आप अनुक्रमणिका कुंजी के लिए एकाधिक स्तंभों का उपयोग करते हैं, तो अनुक्रमणिका कुंजी में उनकी स्थिति पर विचार करना भी आवश्यक है।
- आपको अपनी अनुक्रमणिका में शामिल किए गए स्तंभों का उपयोग करने पर भी विचार करना चाहिए।
5. अपने SQL सर्वर अनुक्रमणिका स्तंभों के डेटा वितरण का विश्लेषण करें
आपको SQL सर्वर इंडेक्स कुंजी कॉलम में डेटा वितरण की जांच करनी चाहिए। गैर-अद्वितीय मानों वाला कॉलम डेटा पुनर्प्राप्त करने में देरी का कारण बन सकता है और परिणामस्वरूप लंबे समय तक चलने वाला लेनदेन हो सकता है। आप आंकड़ों में हिस्टोग्राम का उपयोग करके डेटा वितरण का विश्लेषण कर सकते हैं।
6. डेटा सॉर्ट क्रम का उपयोग करें
आपको अपने प्रश्नों और इंडेक्स में डेटा सॉर्टिंग आवश्यकताओं पर भी विचार करना चाहिए। डिफ़ॉल्ट रूप से, SQL सर्वर अनुक्रमणिका में डेटा को आरोही क्रम में सॉर्ट करता है। मान लीजिए कि आप आरोही क्रम में एक अनुक्रमणिका बनाते हैं, लेकिन आपके प्रश्न डेटा को अवरोही क्रम में क्रमबद्ध करने के लिए ऑर्डर बाय क्लॉज का उपयोग करते हैं।
उदाहरण के लिए, निम्न क्वेरी की वास्तविक निष्पादन योजना देखें।
चुनें [SalesOrderID],
[UnitPrice]
[AdventureWorks] से।[Sales].[SalesOrderDetail]
Order by UnitPrice DESC,
SalesOrderID ASC;
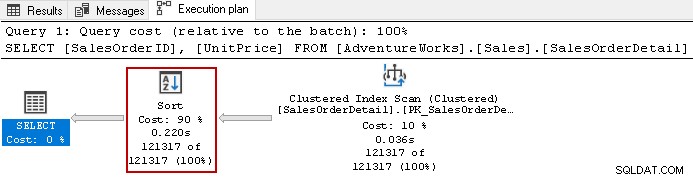
यह इस क्वेरी में कुल 90% लागत के साथ महंगे सॉर्ट ऑपरेटर का उपयोग करता है। हमने [UnitPrice] और [SalesOrderID] पर एक गैर-संकुल सूचकांक बनाने का निर्णय लिया। यह अनुक्रमणिका में दोनों स्तंभों के लिए एक डिफ़ॉल्ट सॉर्ट क्रम का उपयोग करता है।
NONCLUSTERED INDEX बनाएं IX_SalesOrderDetail_Unitprice
ON [AdventureWorks].[Sales].[SalesOrderDetail]
(UnitPrice ASC, SalesOrderID ASC);
हमने सेलेक्ट स्टेटमेंट को फिर से चलाया और क्वेरी ऑप्टिमाइज़र अभी भी सॉर्ट ऑपरेटर का उपयोग करता है। यह गैर-संकुल सूचकांक का उपयोग कर सकता है लेकिन परिणाम तैयार करने के लिए डेटा को सॉर्ट करता है।
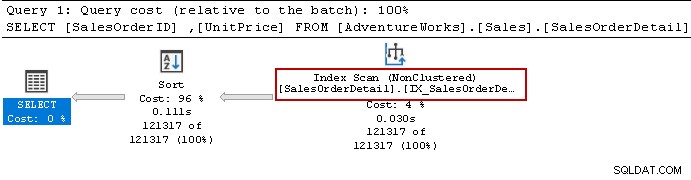
आइए निम्न क्वेरी का उपयोग करके अनुक्रमणिका को फिर से बनाएँ। इस बार यह सूचकांक परिभाषा में [Unitprice] के लिए डेटा को अवरोही क्रम में सॉर्ट करता है।
DROP INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail]; [एडवेंचरवर्क्स] पर
Go
इसे अब किसी सॉर्ट ऑपरेटर की आवश्यकता नहीं है क्योंकि इंडेक्स क्वेरी आवश्यकताओं को पूरा करता है।
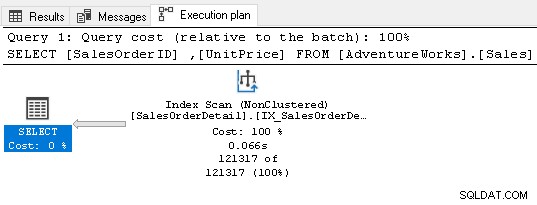
7. अपने SQL सर्वर अनुक्रमणिका के लिए विदेशी कुंजियों का उपयोग करें
आपको विदेशी कुंजी कॉलम पर एक इंडेक्स बनाना चाहिए। क्वेरी प्रदर्शन को बेहतर बनाने के लिए विदेशी कुंजी पर क्लस्टर इंडेक्स बनाने की सलाह दी जाती है।
8. SQL सर्वर अनुक्रमणिका संग्रहण विचारों से सावधान रहें
सूचकांक भंडारण भी विचार करने के लिए एक उपयोगी पहलू है। SQL सर्वर तालिका के एक ही फ़ाइल समूह पर सभी अनुक्रमणिका बनाता है। आप अनुक्रमणिका के लिए एक अलग फ़ाइल समूह पर विचार कर सकते हैं और भौतिक फ़ाइल को एक अलग डिस्क पर अलग कर सकते हैं। यह IO प्रदर्शन और थ्रूपुट को बढ़ाएगा।
इसी तरह, आप कई डिस्क और फ़ाइल समूहों में डेटा को अलग करने के लिए तालिका विभाजन का उपयोग कर सकते हैं। समवर्ती डेटा पहुंच को बेहतर बनाने के लिए आप इन तालिका विभाजनों के लिए विभाजित अनुक्रमणिका डिज़ाइन कर सकते हैं।
एक अन्य विकल्प यह है कि किसी अनुक्रमणिका को बनाते या उसका पुनर्निर्माण करते समय FILLFACTOR को परिभाषित किया जाए। FILLFACTOR लीफ नोड डेटा पेज में खाली जगह को परिभाषित करता है। यह आगे डेटा सम्मिलन के लिए उपयोगी है। यदि आपका डेटा स्थिर है और बार-बार नहीं बदलता है, तो आप FILLFACTOR के उच्च मान पर विचार कर सकते हैं। दूसरी ओर, डेटा को बार-बार बदलने के लिए, आप नए डेटा सम्मिलन के लिए पर्याप्त जगह छोड़ सकते हैं।
9. अनुपलब्ध अनुक्रमणिका खोजें
कभी-कभी, आपको क्वेरी निष्पादन योजना में अनुपलब्ध SQL सर्वर अनुक्रमणिका के बारे में जानकारी मिलती है। आप इन अनुपलब्ध अनुक्रमणिकाओं को खोजने के लिए गतिशील प्रबंधन दृश्य भी चला सकते हैं। आपको इन इंडेक्स को आँख बंद करके नहीं बनाना चाहिए। यह केवल एक प्रश्न अनुकूलक सुझाव है, लेकिन यह मौजूदा सूचकांक या आपकी कार्यभार आवश्यकताओं पर विचार नहीं करता है। इसमें इंडेक्स की परिभाषा में कई कॉलम भी शामिल हो सकते हैं, इसलिए इसे लागू करने से पहले इन सुझावों की समीक्षा करें।
10. हमेशा गैर-संकुल अनुक्रमणिका से पहले एक संकुल अनुक्रमणिका बनाएं
एक सामान्य दिशानिर्देश के रूप में, आपको गैर-संकुल अनुक्रमणिका बनाने से पहले एक संकुल अनुक्रमणिका बनानी चाहिए। यदि किसी तालिका में कोई अनुक्रमणिका नहीं है, तो गैर-संकुल अनुक्रमणिका में पंक्ति पहचानकर्ता होते हैं। एक बार जब आप एक क्लस्टर इंडेक्स बना लेते हैं, तो SQL सर्वर को इन गैर-क्लस्टर इंडेक्स को फिर से बनाने की आवश्यकता होती है ताकि वे पंक्ति पहचानकर्ताओं के बजाय क्लस्टर्ड इंडेक्स कुंजी को इंगित कर सकें।
11. अनुक्रमणिका रखरखाव की निगरानी करें और आंकड़े अपडेट करें
जब SQL सर्वर अनुक्रमणिका की बात आती है तो निगरानी के लिए कई रखरखाव क्षेत्र नीचे दिए गए हैं।
- इंडेक्स फ़्रेग्मेंटेशन हटाएं :आपको नियमित रूप से आंतरिक और बाहरी फ़्रेग्मेंटेशन की समीक्षा करनी चाहिए, विशेष रूप से उच्च लेन-देन तालिकाओं के लिए। आपके प्रश्नों का उत्तर धीरे-धीरे हो सकता है, भले ही आपके पास अपने कार्यभार के लिए उचित अनुक्रमणिका हों। एक भारी खंडित सूचकांक प्रदर्शन को खराब कर सकता है क्योंकि इसके लिए अतिरिक्त IO की आवश्यकता होती है। आप फ़्रेग्मेंटेशन मानों के आधार पर एक पुनर्संरचना कर सकते हैं या किसी अनुक्रमणिका का पुनर्निर्माण कर सकते हैं। आम तौर पर, आपको इंडेक्स को फिर से बनाना चाहिए, अगर उसका विखंडन 30% से अधिक है और अगर उसमें 30% से कम फ़्रेग्मेंटेशन है तो उसे पुनर्गठित करना चाहिए।
- अप्रयुक्त अनुक्रमणिका निकालें: आपको हमेशा अपने डेटाबेस में अप्रयुक्त (निष्क्रिय) इंडेक्स की समीक्षा करनी चाहिए क्योंकि क्वेरी ऑप्टिमाइज़र को प्रत्येक क्वेरी के लिए उन पर विचार करने की आवश्यकता होती है। एक अप्रयुक्त सूचकांक भी भंडारण की खपत करता है और रखरखाव ओवरहेड को बढ़ाता है।
- आंकड़े अपडेट करें: आपको समय-समय पर आंकड़ों को अपडेट करना चाहिए, भले ही आपने अपने डेटाबेस कॉन्फ़िगरेशन में ऑटो-अपडेट आंकड़े सेट किए हों। यदि अनुक्रमणिका आँकड़े अद्यतन नहीं हैं, तो क्वेरी अनुकूलक एक खराब निष्पादन योजना तैयार कर सकता है। आप व्यावसायिक घंटों के बाद पूर्ण स्कैन के साथ SQL सर्वर आँकड़ों को अद्यतन करने के लिए एजेंट की नौकरी शेड्यूल कर सकते हैं।
आप इस विषय पर अधिक जानकारी के लिए SQL अनुक्रमणिका रखरखाव का संदर्भ ले सकते हैं।
SQL सर्वर अनुक्रमणिका सर्वोत्तम प्रथाओं को लागू करना
हालांकि, इष्टतम SQL सर्वर इंडेक्स को डिज़ाइन करने का हमेशा एक सीधा तरीका नहीं होता है, इस पोस्ट में निर्दिष्ट अनुशंसाओं को लागू करने से आपको प्रत्येक डेटाबेस प्रकार और उसके वर्कलोड के साथ आने वाली अलग-अलग इंडेक्सिंग आवश्यकताओं को नेविगेट करने में मदद मिलेगी। ये सर्वोत्तम प्रक्रियाएं डेटाबेस प्रदर्शन को बेहतर बनाने के लिए आपकी अनुक्रमणिका को अनुकूलित करने में मदद करेंगी और रास्ते में एक आसान प्रदर्शन ट्यूनिंग प्रक्रिया सुनिश्चित करेंगी।