बेंचमार्किंग प्रबंधित PostgreSQL क्लाउड सॉल्यूशंस . के इस तीसरे भाग में , मैंने Google की GCP मुक्त स्तरीय पेशकश का लाभ उठाया। यह एक सार्थक अनुभव रहा है और एक सिसडमिन के रूप में जो अपना अधिकांश समय कंसोल पर बिताता है, मैं क्लाउड शेल को आज़माने का अवसर नहीं चूक सकता, कंसोल सुविधाओं में से एक जो Google को क्लाउड प्रदाता से अलग करता है जिससे मैं अधिक परिचित हूँ , अमेज़न वेब सेवाएँ।
जल्दी से पुनर्कथन करने के लिए, भाग 1 में मैंने उपलब्ध बेंचमार्क टूल को देखा और समझाया कि मैंने AWS बेंचमार्क प्रक्रिया को Aurora के लिए क्यों चुना। मैंने PostgreSQL संस्करण 10.6.8 के लिए Amazon Aurora को भी बेंचमार्क किया है। भाग 2 में मैंने PostgreSQL संस्करण 11.1 के लिए AWS RDS की समीक्षा की।
इस दौर के दौरान, ऑरोरा के लिए AWS बेंचमार्क प्रक्रिया पर आधारित परीक्षण PostgreSQL 9.6 के लिए Google क्लाउड SQL के विरुद्ध चलाए जाएंगे क्योंकि संस्करण 11.1 अभी भी बीटा में है।
क्लाउड इंस्टेंस
आवश्यकताएं
जैसा कि पिछले दो लेखों में बताया गया है, मैंने PostgreSQL सेटिंग्स को उनके क्लाउड GUC डिफॉल्ट्स पर छोड़ने का विकल्प चुना, जब तक कि वे परीक्षणों को चलने से रोकते हैं (नीचे और नीचे देखें)। पिछले लेखों से याद करें कि यह धारणा रही है कि उचित प्रदर्शन प्रदान करने के लिए क्लाउड प्रदाता के पास डेटाबेस इंस्टेंस कॉन्फ़िगर होना चाहिए।
PostgreSQL 9.6.5 के लिए AWS pgbench टाइमिंग पैच PostgreSQL 9.6.10 के Google क्लाउड संस्करण पर स्पष्ट रूप से लागू हुआ।
Google ने अपने ब्लॉग Google क्लाउड में AWS पेशेवरों के लिए जो जानकारी दी है, उसका उपयोग करके मैंने क्लाइंट के लिए विशिष्टताओं और कंप्यूट, स्टोरेज और नेटवर्किंग घटकों के संबंध में लक्ष्य उदाहरणों का मिलान किया। उदाहरण के लिए, एडब्ल्यूएस एन्हांस्ड नेटवर्किंग के समकक्ष Google क्लाउड सूत्र के आधार पर गणना नोड को आकार देकर प्राप्त किया जाता है:
max( [vCPUs x 2Gbps/vCPU], 16Gbps)जब लक्ष्य डेटाबेस इंस्टेंस को सेट करने की बात आती है, तो एडब्ल्यूएस के समान, Google क्लाउड किसी भी प्रतिकृति की अनुमति नहीं देता है, हालांकि, भंडारण आराम से एन्क्रिप्ट किया गया है और इसे अक्षम करने का कोई विकल्प नहीं है।
अंत में, सर्वोत्तम नेटवर्क प्रदर्शन प्राप्त करने के लिए, क्लाइंट और लक्ष्य उदाहरण समान उपलब्धता क्षेत्र में स्थित होने चाहिए।
ग्राहक
एडब्ल्यूएस इंस्टेंस के निकटतम से मेल खाने वाले क्लाइंट इंस्टेंस स्पेक्स हैं:
- vCPU:32 (16 करोड़ x 2 थ्रेड/कोर)
- RAM:208 GiB (32 vCPU इंस्टेंस के लिए अधिकतम)
- स्टोरेज:कंप्यूट इंजन परसिस्टेंट डिस्क
- नेटवर्क:16 जीबीपीएस (अधिकतम [32 वीसीपीयू x 2 जीबीपीएस/वीसीपीयू] और 16 जीबीपीएस)
आरंभीकरण के बाद उदाहरण विवरण:
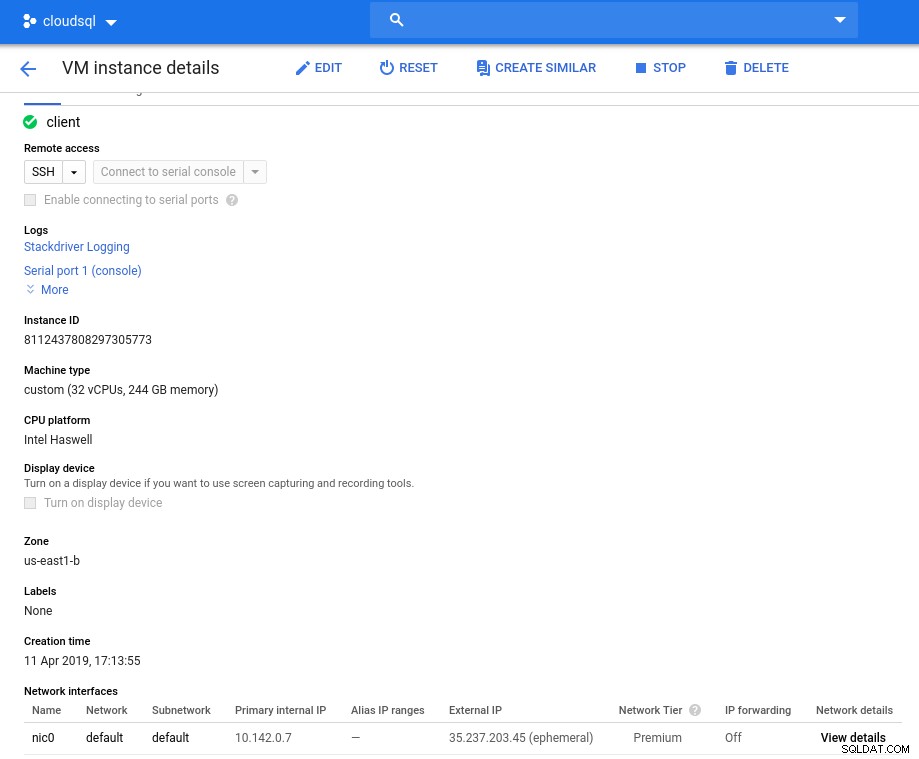 क्लाइंट इंस्टेंस:कंप्यूट और नेटवर्क
क्लाइंट इंस्टेंस:कंप्यूट और नेटवर्क नोट:इंस्टेंस डिफ़ॉल्ट रूप से 24 वीसीपीयू तक सीमित होते हैं। Google तकनीकी सहायता को प्रति उदाहरण 32 वीसीपीयू तक कोटा बढ़ाने की स्वीकृति देनी होगी।

हालांकि इस तरह के अनुरोध आमतौर पर 2 व्यावसायिक दिनों के भीतर संभाले जाते हैं, मुझे केवल 2 घंटों में अपना अनुरोध पूरा करने के लिए Google सहायता सेवाओं को एक अंगूठा देना होगा।
जिज्ञासु के लिए, नेटवर्क गति सूत्र इस GCP ब्लॉग में संदर्भित कंप्यूट इंजन दस्तावेज़ीकरण पर आधारित है।
डीबी क्लस्टर
नीचे डेटाबेस इंस्टेंस स्पेक्स हैं:
- vCPU:8
- RAM:52 GiB (अधिकतम)
- संग्रहण:144 एमबी/एस, 9,000 आईओपीएस
- नेटवर्क:2,000 एमबी/एस
ध्यान दें कि 8 वीसीपीयू इंस्टेंस के लिए अधिकतम उपलब्ध मेमोरी 52 जीबी है। एक बड़े उदाहरण (अधिक वीसीपीयू) का चयन करके अधिक मेमोरी आवंटित की जा सकती है:
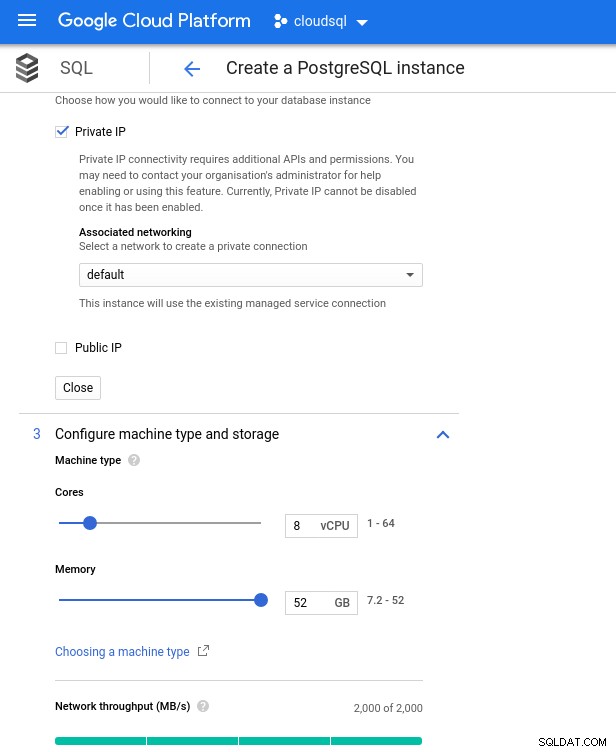 डेटाबेस CPU और मेमोरी साइज़िंग
डेटाबेस CPU और मेमोरी साइज़िंग जबकि Google SQL स्वचालित रूप से अंतर्निहित संग्रहण का विस्तार कर सकता है, जो कि वास्तव में एक अच्छी सुविधा है, मैंने AWS सुविधा सेट के अनुरूप होने के लिए विकल्प को अक्षम करना चुना, और आकार बदलने के संचालन के दौरान संभावित I/O प्रभाव से बचने के लिए चुना। ("संभावित", क्योंकि इसका कोई नकारात्मक प्रभाव नहीं होना चाहिए, हालांकि मेरे अनुभव में किसी भी प्रकार के अंतर्निहित भंडारण का आकार बदलने से I/O बढ़ जाता है, भले ही कुछ सेकंड के लिए)।
याद रखें कि एडब्ल्यूएस डेटाबेस इंस्टेंस को एक अनुकूलित ईबीएस स्टोरेज द्वारा समर्थित किया गया था जो अधिकतम प्रदान करता था:
- 1,700 एमबीपीएस बैंडविड्थ
- 212.5 एमबी/एस थ्रूपुट
- 12,000 आईओपीएस
Google क्लाउड के साथ हम vCPU की संख्या (ऊपर देखें) और संग्रहण क्षमता को समायोजित करके एक समान कॉन्फ़िगरेशन प्राप्त करते हैं:
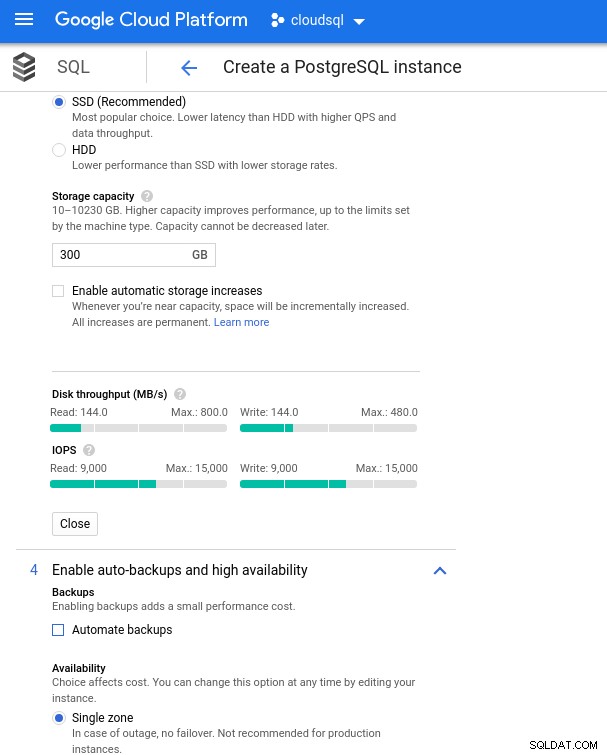 डेटाबेस स्टोरेज कॉन्फ़िगरेशन और बैकअप सेटिंग्स
डेटाबेस स्टोरेज कॉन्फ़िगरेशन और बैकअप सेटिंग्स बेंचमार्क चलाना
सेटअप
इसके बाद, PostgreSQL संस्करण 9.6.10 के लिए अनुकूलित Amazon मार्गदर्शिका में दिए गए निर्देशों का पालन करके बेंचमार्क टूल, pgbench और sysbench इंस्टॉल करें।
PostgreSQL पर्यावरण चर को .bashrc में प्रारंभ करें और PostgreSQL बायनेरिज़ और लाइब्रेरी के लिए पथ सेट करें:
export PGHOST=10.101.208.7
export PGUSER=postgres
export PGPASSWORD=postgres
export PGDATABASE=postgres
export PGPORT=5432
export PATH=$PATH:/usr/local/pgsql/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/libप्रीफ्लाइट चेकलिस्ट:
[example@sqldat.com ~]# psql --version
psql (PostgreSQL) 9.6.10
[example@sqldat.com ~]# pgbench --version
pgbench (PostgreSQL) 9.6.10
[example@sqldat.com ~]# sysbench --version
sysbench 0.5
postgres=> select version();
version
---------------------------------------------------------------------------------------------------------
PostgreSQL 9.6.10 on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 4.8.4-2ubuntu1~14.04.3) 4.8.4, 64-bit
(1 row)और हम टेकऑफ़ के लिए तैयार हैं:
पीजीबेंच
pgbench डेटाबेस को इनिशियलाइज़ करें।
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000...और कई मिनट बाद:
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 1000000000 tuples (0%) done (elapsed 0.09 s, remaining 872.42 s)
200000 of 1000000000 tuples (0%) done (elapsed 0.19 s, remaining 955.00 s)
300000 of 1000000000 tuples (0%) done (elapsed 0.33 s, remaining 1105.08 s)
400000 of 1000000000 tuples (0%) done (elapsed 0.53 s, remaining 1317.56 s)
500000 of 1000000000 tuples (0%) done (elapsed 0.63 s, remaining 1258.72 s)
...
500000000 of 1000000000 tuples (50%) done (elapsed 943.93 s, remaining 943.93 s)
500100000 of 1000000000 tuples (50%) done (elapsed 944.08 s, remaining 943.71 s)
500200000 of 1000000000 tuples (50%) done (elapsed 944.22 s, remaining 943.46 s)
500300000 of 1000000000 tuples (50%) done (elapsed 944.33 s, remaining 943.20 s)
500400000 of 1000000000 tuples (50%) done (elapsed 944.47 s, remaining 942.96 s)
500500000 of 1000000000 tuples (50%) done (elapsed 944.59 s, remaining 942.70 s)
500600000 of 1000000000 tuples (50%) done (elapsed 944.73 s, remaining 942.47 s)
...
999600000 of 1000000000 tuples (99%) done (elapsed 1878.28 s, remaining 0.75 s)
999700000 of 1000000000 tuples (99%) done (elapsed 1878.41 s, remaining 0.56 s)
999800000 of 1000000000 tuples (99%) done (elapsed 1878.58 s, remaining 0.38 s)
999900000 of 1000000000 tuples (99%) done (elapsed 1878.70 s, remaining 0.19 s)
1000000000 of 1000000000 tuples (100%) done (elapsed 1878.83 s, remaining 0.00 s)
vacuum...
set primary keys...
total time: 5978.44 s (insert 1878.90 s, commit 0.04 s, vacuum 2484.96 s, index 1614.54 s)
done.जैसा कि अब हम अभ्यस्त हैं, डेटाबेस का आकार 160GB होना चाहिए। आइए सत्यापित करें कि:
postgres=> SELECT
postgres-> d.datname AS Name,
postgres-> pg_catalog.pg_get_userbyid(d.datdba) AS Owner,
postgres-> pg_catalog.pg_size_pretty(pg_catalog.pg_database_size(d.datname)) AS SIZE
postgres-> FROM pg_catalog.pg_database d
postgres-> WHERE d.datname = 'postgres';
name | owner | size
----------+-------------------+--------
postgres | cloudsqlsuperuser | 160 GB
(1 row)सभी तैयारी पूरी होने के साथ ही पढ़ने/लिखने की परीक्षा शुरू करें:
[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048
starting vacuum...end.
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: remaining connection slots are reserved for non-replication superuser connectionsउफ़! अधिकतम क्या है?
postgres=> show max_connections ;
max_connections
-----------------
600
(1 row)इसलिए, जबकि AWS काफी हद तक पर्याप्त max_connections सेट करता है क्योंकि मुझे उस समस्या का सामना नहीं करना पड़ा, Google क्लाउड को एक छोटे से बदलाव की आवश्यकता है...क्लाउड कंसोल पर वापस जाएं, डेटाबेस पैरामीटर अपडेट करें, कुछ मिनट प्रतीक्षा करें और फिर जांचें:
postgres=> show max_connections ;
max_connections
-----------------
1005
(1 row)परीक्षण को फिर से शुरू करना सब कुछ ठीक काम कर रहा प्रतीत होता है:
starting vacuum...end.
progress: 60.0 s, 5461.7 tps, lat 172.821 ms stddev 251.666
progress: 120.0 s, 4444.5 tps, lat 225.162 ms stddev 365.695
progress: 180.0 s, 4338.5 tps, lat 230.484 ms stddev 373.998...लेकिन एक और पकड़ है। कनेक्शनों की संख्या गिनने के लिए एक नया psql सत्र खोलने का प्रयास करते समय मुझे आश्चर्य हुआ:
psql: FATAL: remaining connection slots are reserved for non-replication superuser connectionsक्या ऐसा हो सकता है कि superuser_reserved_connections अपने डिफ़ॉल्ट पर न हो?
postgres=> show superuser_reserved_connections ;
superuser_reserved_connections
--------------------------------
3
(1 row)वह डिफ़ॉल्ट है, तो और क्या हो सकता है?
postgres=> select usename from pg_stat_activity ;
usename
---------------
cloudsqladmin
cloudsqlagent
postgres
(3 rows)बिंगो! max_connections का एक और टक्कर इसका ख्याल रखता है, हालांकि, यह आवश्यक है कि मैं pgbench परीक्षण को पुनरारंभ करूं। और यही लोग नीचे दिए गए ग्राफ़ में स्पष्ट डुप्लिकेट रन के पीछे की कहानी है।
और अंत में, परिणाम इस प्रकार हैं:
progress: 60.0 s, 4553.6 tps, lat 194.696 ms stddev 250.663
progress: 120.0 s, 3646.5 tps, lat 278.793 ms stddev 434.459
progress: 180.0 s, 3130.4 tps, lat 332.936 ms stddev 711.377
progress: 240.0 s, 3998.3 tps, lat 250.136 ms stddev 319.215
progress: 300.0 s, 3305.3 tps, lat 293.250 ms stddev 549.216
progress: 360.0 s, 3547.9 tps, lat 289.526 ms stddev 454.484
progress: 420.0 s, 3770.5 tps, lat 265.977 ms stddev 470.451
progress: 480.0 s, 3050.5 tps, lat 327.917 ms stddev 643.983
progress: 540.0 s, 3591.7 tps, lat 273.906 ms stddev 482.020
progress: 600.0 s, 3350.9 tps, lat 296.303 ms stddev 566.792
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10000
query mode: prepared
number of clients: 1000
number of threads: 1000
duration: 600 s
number of transactions actually processed: 2157735
latency average = 278.149 ms
latency stddev = 503.396 ms
tps = 3573.331659 (including connections establishing)
tps = 3591.759513 (excluding connections establishing)सिसबेंच
डेटाबेस को पॉप्युलेट करें:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250\
--oltp-table-size=450000 \
prepareआउटपुट:
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
Inserting 450000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Inserting 450000 records into 'sbtest2'
...
Creating table 'sbtest249'...
Inserting 450000 records into 'sbtest249'
Creating secondary indexes on 'sbtest249'...
Creating table 'sbtest250'...
Inserting 450000 records into 'sbtest250'
Creating secondary indexes on 'sbtest250'...और अब परीक्षण चलाएँ:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250 \
--oltp-table-size=450000 \
--max-requests=0 \
--forced-shutdown \
--report-interval=60 \
--oltp_simple_ranges=0 \
--oltp-distinct-ranges=0 \
--oltp-sum-ranges=0 \
--oltp-order-ranges=0 \
--oltp-point-selects=0 \
--rand-type=uniform \
--max-time=600 \
--num-threads=1000 \
runऔर परिणाम:
sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options:
Number of threads: 1000
Report intermediate results every 60 second(s)
Random number generator seed is 0 and will be ignored
Forcing shutdown in 630 seconds
Initializing worker threads...
Threads started!
[ 60s] threads: 1000, tps: 1320.25, reads: 0.00, writes: 5312.62, response time: 1484.54ms (95%), errors: 0.00, reconnects: 0.00
[ 120s] threads: 1000, tps: 1486.77, reads: 0.00, writes: 5944.30, response time: 1290.87ms (95%), errors: 0.00, reconnects: 0.00
[ 180s] threads: 1000, tps: 1143.62, reads: 0.00, writes: 4585.67, response time: 1649.50ms (95%), errors: 0.02, reconnects: 0.00
[ 240s] threads: 1000, tps: 1498.23, reads: 0.00, writes: 5993.06, response time: 1269.03ms (95%), errors: 0.00, reconnects: 0.00
[ 300s] threads: 1000, tps: 1520.53, reads: 0.00, writes: 6058.57, response time: 1439.90ms (95%), errors: 0.02, reconnects: 0.00
[ 360s] threads: 1000, tps: 1234.57, reads: 0.00, writes: 4958.08, response time: 1550.39ms (95%), errors: 0.02, reconnects: 0.00
[ 420s] threads: 1000, tps: 1722.25, reads: 0.00, writes: 6890.98, response time: 1132.25ms (95%), errors: 0.00, reconnects: 0.00
[ 480s] threads: 1000, tps: 2306.25, reads: 0.00, writes: 9233.84, response time: 842.11ms (95%), errors: 0.00, reconnects: 0.00
[ 540s] threads: 1000, tps: 1432.85, reads: 0.00, writes: 5720.15, response time: 1709.83ms (95%), errors: 0.02, reconnects: 0.00
[ 600s] threads: 1000, tps: 1332.93, reads: 0.00, writes: 5347.10, response time: 1443.78ms (95%), errors: 0.02, reconnects: 0.00
OLTP test statistics:
queries performed:
read: 0
write: 3603595
other: 1801795
total: 5405390
transactions: 900895 (1500.68 per sec.)
read/write requests: 3603595 (6002.76 per sec.)
other operations: 1801795 (3001.38 per sec.)
ignored errors: 5 (0.01 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 600.3231s
total number of events: 900895
total time taken by event execution: 600164.2510s
response time:
min: 6.78ms
avg: 666.19ms
max: 4218.55ms
approx. 95 percentile: 1397.02ms
Threads fairness:
events (avg/stddev): 900.8950/14.19
execution time (avg/stddev): 600.1643/0.10बेंचमार्क मेट्रिक्स
स्टैकड्राइवर के लिए पोस्टग्रेएसक्यूएल प्लगइन 28 फरवरी, 2019 से बहिष्कृत कर दिया गया है। जबकि Google ब्लू मेडोरा की सिफारिश करता है, इस लेख के उद्देश्य के लिए मैंने एक खाता बनाने और उपलब्ध स्टैकड्राइवर मेट्रिक्स पर भरोसा करने के लिए चुना है।
- सीपीयू उपयोग:
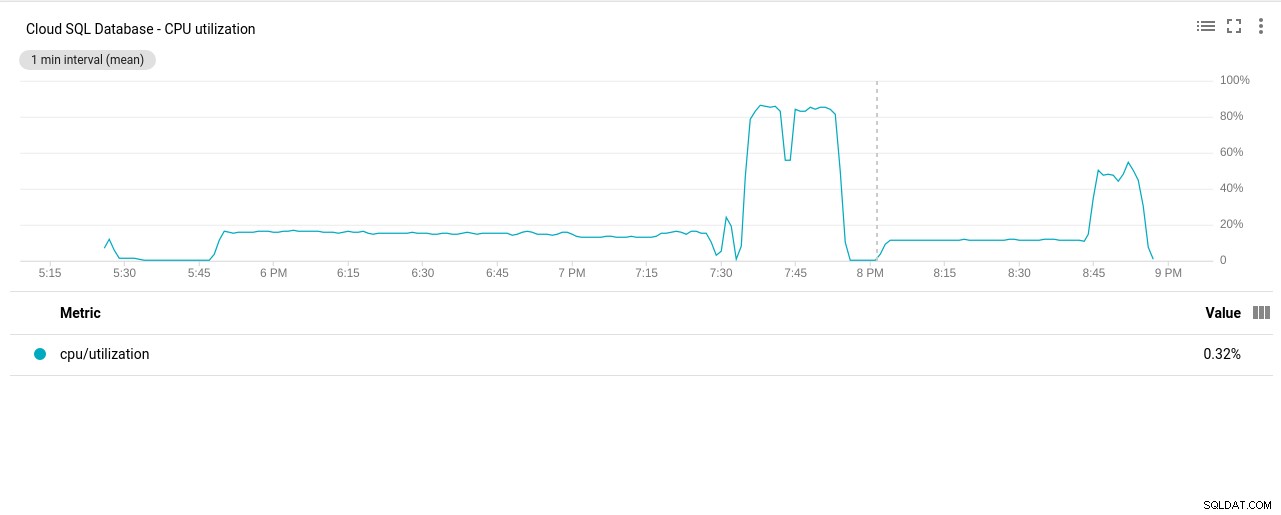 फ़ोटो लेखक Google Cloud SQL:PostgreSQL CPU उपयोग
फ़ोटो लेखक Google Cloud SQL:PostgreSQL CPU उपयोग - डिस्क रीड/राइट ऑपरेशंस:
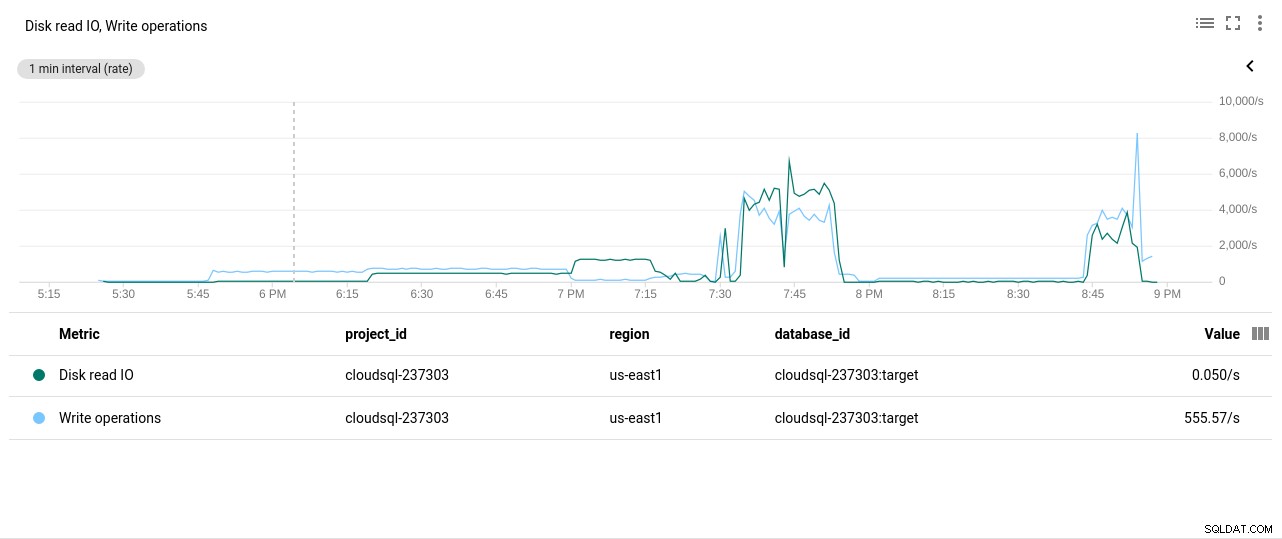 फ़ोटो लेखक Google Cloud SQL:PostgreSQL डिस्क रीड/राइट ऑपरेशन
फ़ोटो लेखक Google Cloud SQL:PostgreSQL डिस्क रीड/राइट ऑपरेशन - नेटवर्क भेजा/प्राप्त बाइट्स:
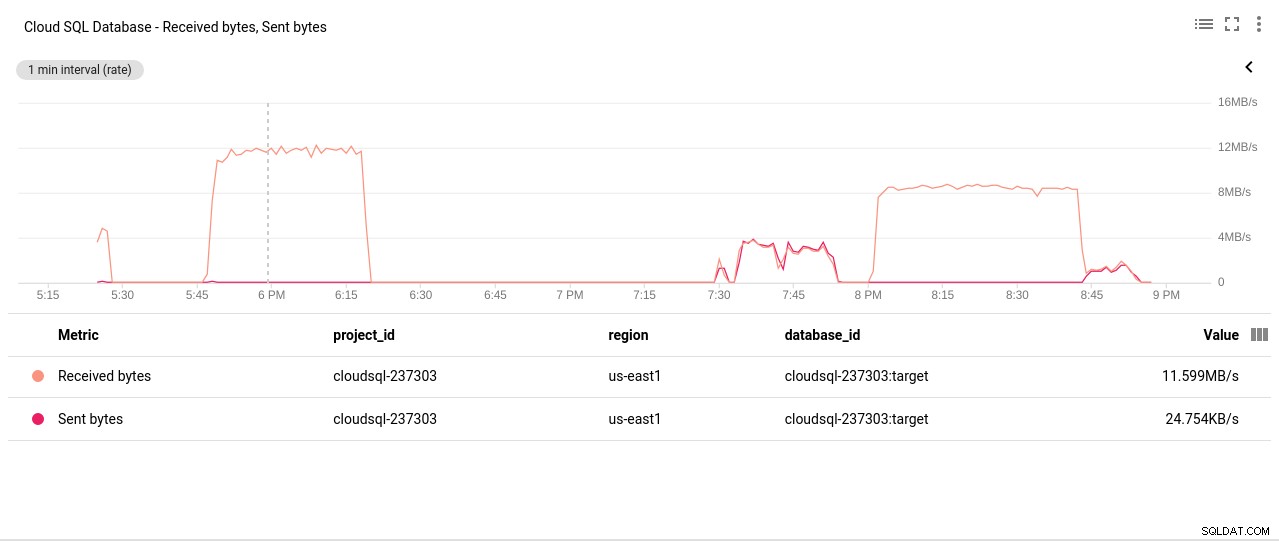 फ़ोटो लेखक Google Cloud SQL:PostgreSQL नेटवर्क भेजा/प्राप्त बाइट्स
फ़ोटो लेखक Google Cloud SQL:PostgreSQL नेटवर्क भेजा/प्राप्त बाइट्स - PostgreSQL कनेक्शनों की संख्या:
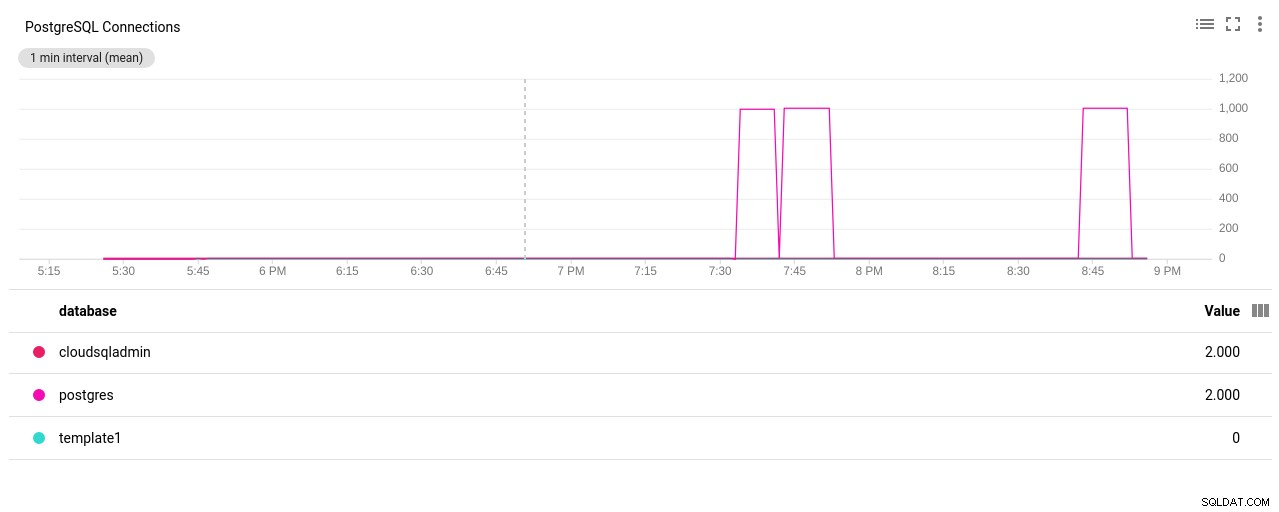 फ़ोटो लेखक Google क्लाउड SQL:PostgreSQL कनेक्शन गणना
फ़ोटो लेखक Google क्लाउड SQL:PostgreSQL कनेक्शन गणना
बेंचमार्क परिणाम
pgbench इनिशियलाइज़ेशन
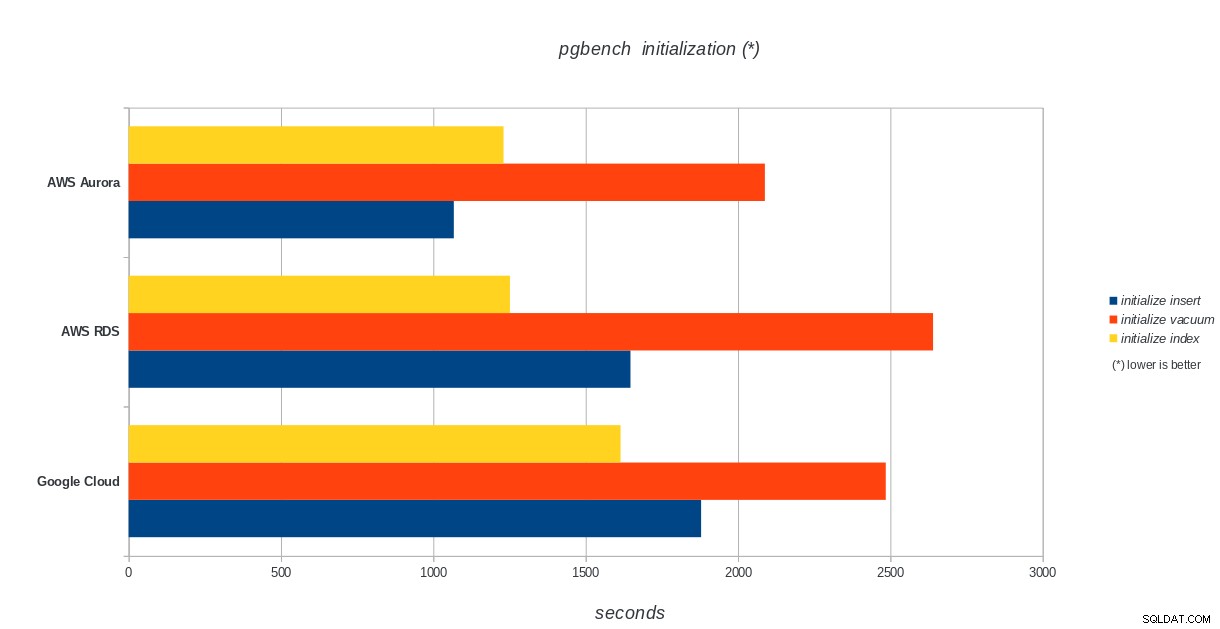 AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL pgbench आरंभीकरण परिणाम
AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL pgbench आरंभीकरण परिणाम पीजीबेंच रन
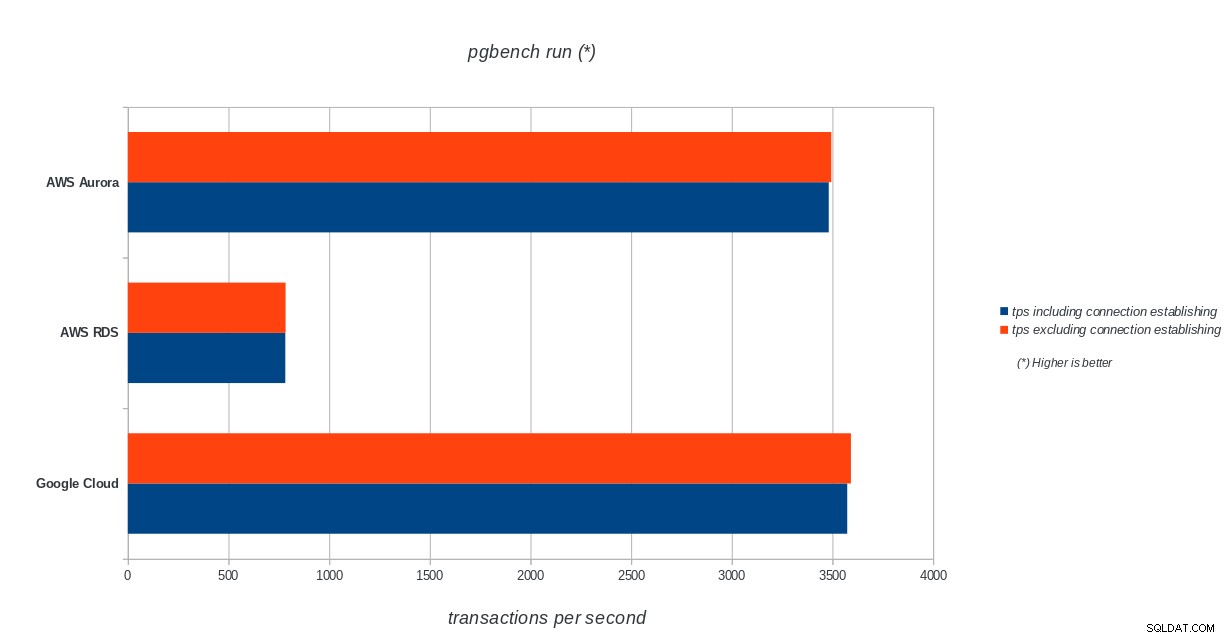 AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL pgbench रन परिणाम
AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL pgbench रन परिणाम सिसबेंच
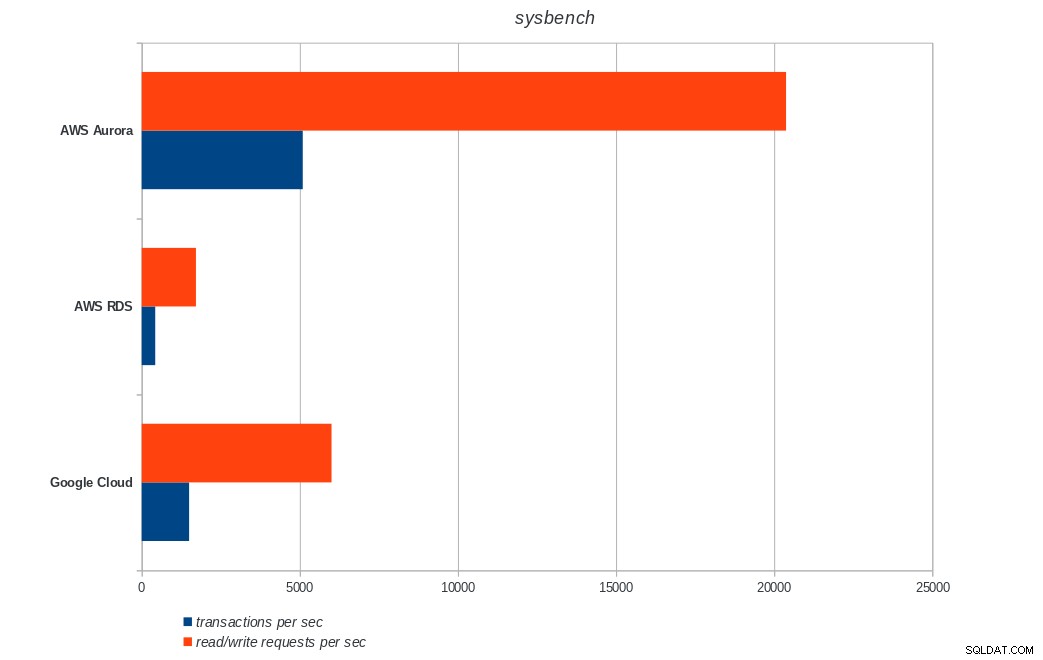 AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL sysbench परिणाम
AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL sysbench परिणाम निष्कर्ष
अमेज़ॅन ऑरोरा अब तक भारी (सिसबेंच) परीक्षण लिखने में सबसे पहले आता है, जबकि पीजीबेंच पढ़ने/लिखने के परीक्षणों में Google क्लाउड एसक्यूएल के बराबर है। लोड टेस्ट (pgbench इनिशियलाइज़ेशन) Google क्लाउड SQL को पहले स्थान पर रखता है, उसके बाद Amazon RDS। एडब्ल्यूएस ऑरोरा और गूगल क्लाउड एसक्यूएल के लिए मूल्य निर्धारण मॉडल पर एक सरसरी नजर के आधार पर, मुझे यह कहने में खतरा होगा कि बॉक्स के बाहर Google क्लाउड औसत उपयोगकर्ता के लिए एक बेहतर विकल्प है, जबकि एडब्ल्यूएस ऑरोरा उच्च प्रदर्शन वातावरण के लिए बेहतर अनुकूल है। सभी बेंचमार्क पूरा करने के बाद और विश्लेषण किया जाएगा।
इस बेंचमार्क श्रृंखला का अगला और अंतिम भाग Microsoft Azure PostgreSQL पर होगा।
पढ़ने के लिए धन्यवाद और अगर आपके पास प्रतिक्रिया है तो कृपया नीचे टिप्पणी करें।