निगरानी किसी भी प्रणाली में मूलभूत कार्यों में से एक है। यह हमें समस्याओं का पता लगाने और कार्रवाई करने में मदद कर सकता है, या बस हमारे सिस्टम की वर्तमान स्थिति को जानने में मदद कर सकता है। दृश्य प्रदर्शन का उपयोग हमें अधिक प्रभावी बना सकता है क्योंकि हम प्रदर्शन समस्याओं का आसानी से पता लगा सकते हैं।
इस ब्लॉग में, हम देखेंगे कि हमारे PostgreSQL डेटाबेस की निगरानी के लिए SCUMM का उपयोग कैसे करें और इस कार्य के लिए हम किन मीट्रिक का उपयोग कर सकते हैं। हम उपलब्ध डैशबोर्ड का भी अध्ययन करेंगे, ताकि आप आसानी से पता लगा सकें कि आपके PostgreSQL इंस्टेंस के साथ वास्तव में क्या हो रहा है।
SCUMM क्या है?
सबसे पहले, आइए देखें कि SCUMM (Severalnines ClusterControl Unified Monitoring and Management) क्या है।
यह डेटाबेस नोड्स पर स्थापित एजेंटों के साथ एक नया एजेंट-आधारित समाधान है।
SCUMM एजेंट प्रोमेथियस निर्यातक हैं जो प्रोमेथियस मेट्रिक्स के रूप में PostgreSQL जैसी सेवाओं से मीट्रिक निर्यात करते हैं।
SCUMM एजेंटों से समय श्रृंखला डेटा को परिमार्जन और संग्रहीत करने के लिए एक प्रोमेथियस सर्वर का उपयोग किया जाता है।
प्रोमेथियस एक ओपन-सोर्स सिस्टम मॉनिटरिंग और अलर्ट टूलकिट है जो मूल रूप से साउंडक्लाउड पर बनाया गया था। यह अब एक स्टैंडअलोन ओपन सोर्स प्रोजेक्ट है और स्वतंत्र रूप से बनाए रखा गया है।
प्रोमेथियस को विश्वसनीयता के लिए डिज़ाइन किया गया है, ताकि आप एक आउटेज के दौरान जिस सिस्टम पर जाते हैं, वह आपको समस्याओं का शीघ्र निदान करने की अनुमति देता है।
SCUMM का उपयोग कैसे करें?
ClusterControl का उपयोग करते समय, जब हम एक क्लस्टर का चयन करते हैं, तो हम अपने डेटाबेस का एक सिंहावलोकन देख सकते हैं, साथ ही कुछ बुनियादी मैट्रिक्स भी देख सकते हैं जिनका उपयोग किसी समस्या की पहचान करने के लिए किया जा सकता है। नीचे दिए गए डैशबोर्ड में, हम HAProxy और Keepalived के साथ एक मास्टर और 2 स्लेव के साथ एक मास्टर-स्लेव सेटअप देख सकते हैं।
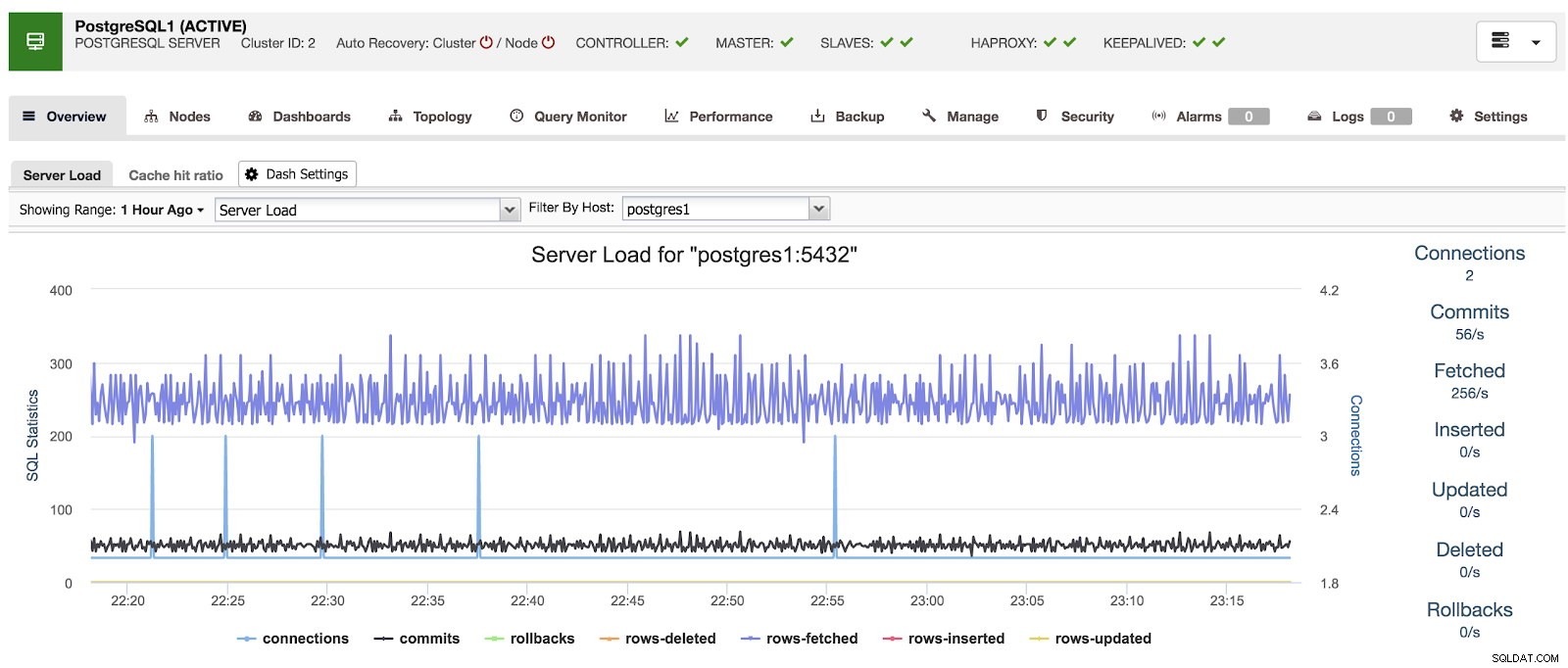 ClusterControl अवलोकन
ClusterControl अवलोकन यदि हम "डैशबोर्ड" विकल्प पर जाते हैं, तो हम निम्न जैसा संदेश देख सकते हैं।
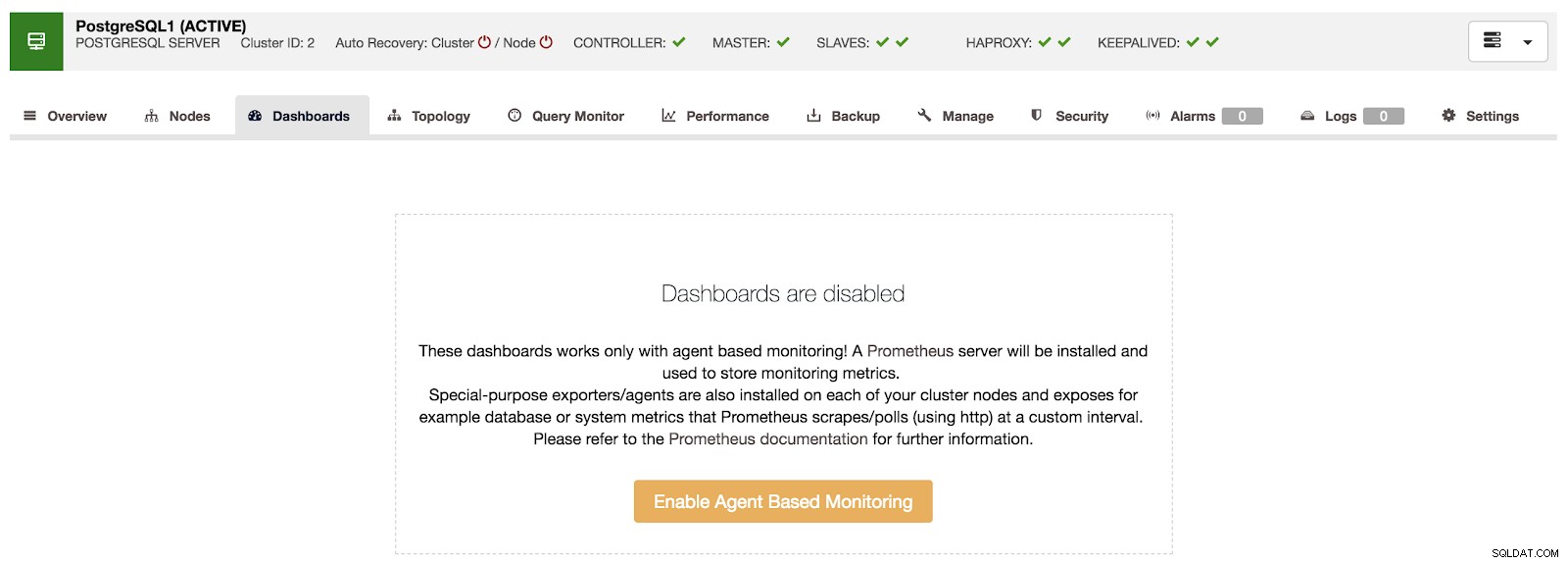 ClusterControl डैशबोर्ड अक्षम
ClusterControl डैशबोर्ड अक्षम इस सुविधा का उपयोग करने के लिए, हमें ऊपर उल्लिखित एजेंट को सक्षम करना होगा। इसके लिए हमें केवल इस खंड में "एजेंट आधारित निगरानी सक्षम करें" बटन पर प्रेस करना होगा।
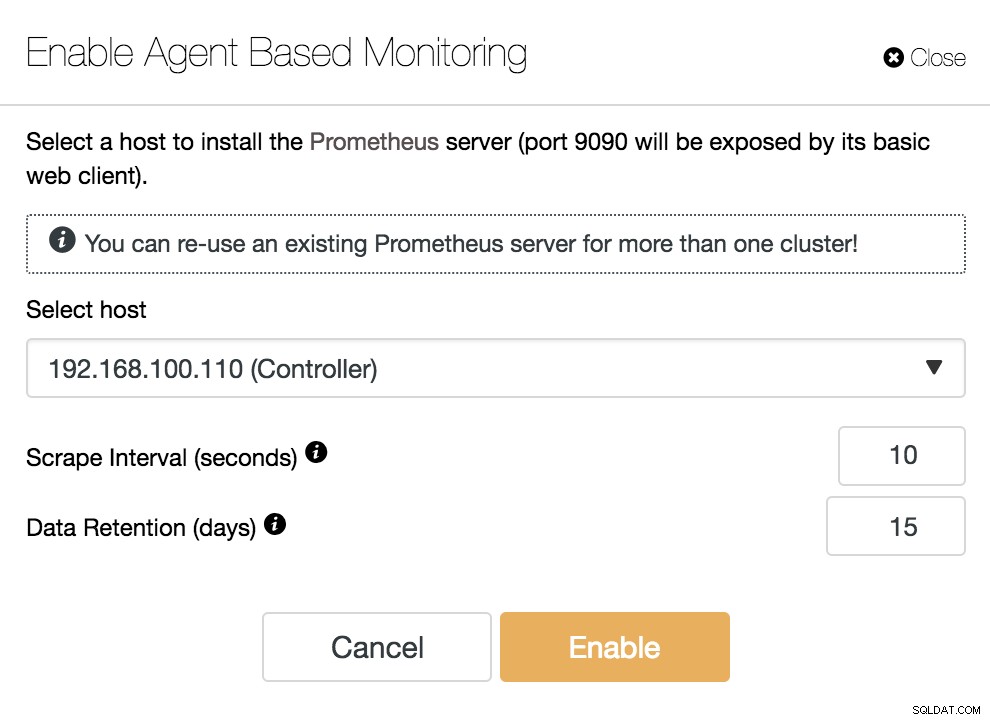 ClusterControl एजेंट आधारित निगरानी सक्षम करें
ClusterControl एजेंट आधारित निगरानी सक्षम करें हमारे एजेंट को सक्षम करने के लिए, हमें उस होस्ट को निर्दिष्ट करना होगा जहां हम अपना प्रोमेथियस सर्वर स्थापित करेंगे, जैसा कि हम उदाहरण में देख सकते हैं, हमारा क्लस्टर कंट्रोल सर्वर हो सकता है।
हमें यह भी निर्दिष्ट करना होगा:
- स्क्रैप अंतराल (सेकंड):सेट करें कि मीट्रिक के लिए नोड्स कितनी बार स्क्रैप किए जाते हैं। डिफ़ॉल्ट 10 सेकंड है।
- डेटा प्रतिधारण (दिन):सेट करें कि हटाए जाने से पहले मीट्रिक कितने समय तक रखे जाते हैं। डिफ़ॉल्ट 15 दिन है।
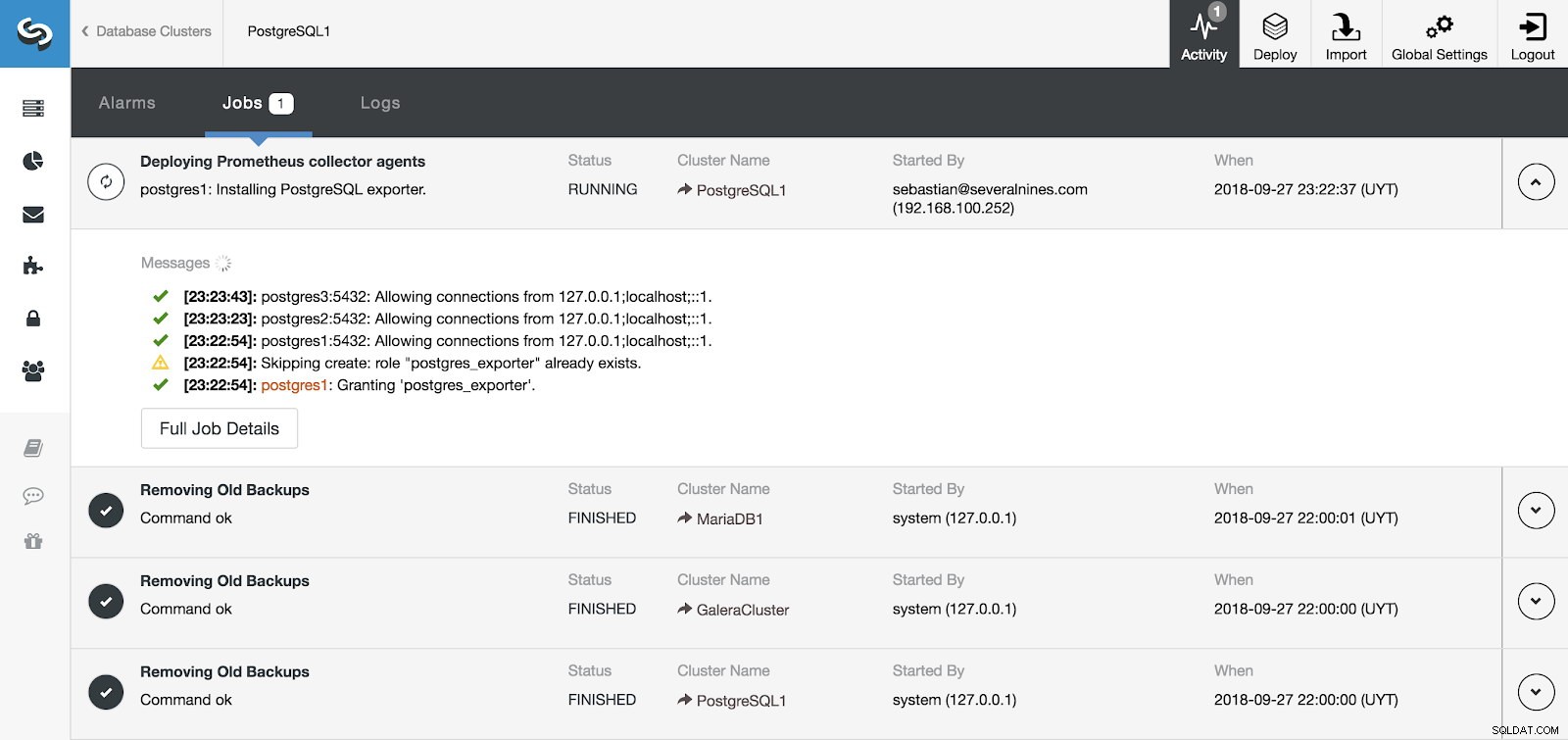 ClusterControl गतिविधि अनुभाग
ClusterControl गतिविधि अनुभाग हम ClusterControl में गतिविधि अनुभाग से अपने सर्वर और एजेंटों की स्थापना की निगरानी कर सकते हैं और, एक बार यह समाप्त हो जाने के बाद, हम अपने क्लस्टर को मुख्य ClusterControl स्क्रीन से सक्षम एजेंटों के साथ देख सकते हैं।
 ClusterControl एजेंट सक्षम
ClusterControl एजेंट सक्षम डैशबोर्ड
हमारे एजेंट सक्षम होने पर, यदि हम डैशबोर्ड अनुभाग में जाते हैं, तो हमें कुछ ऐसा दिखाई देगा:
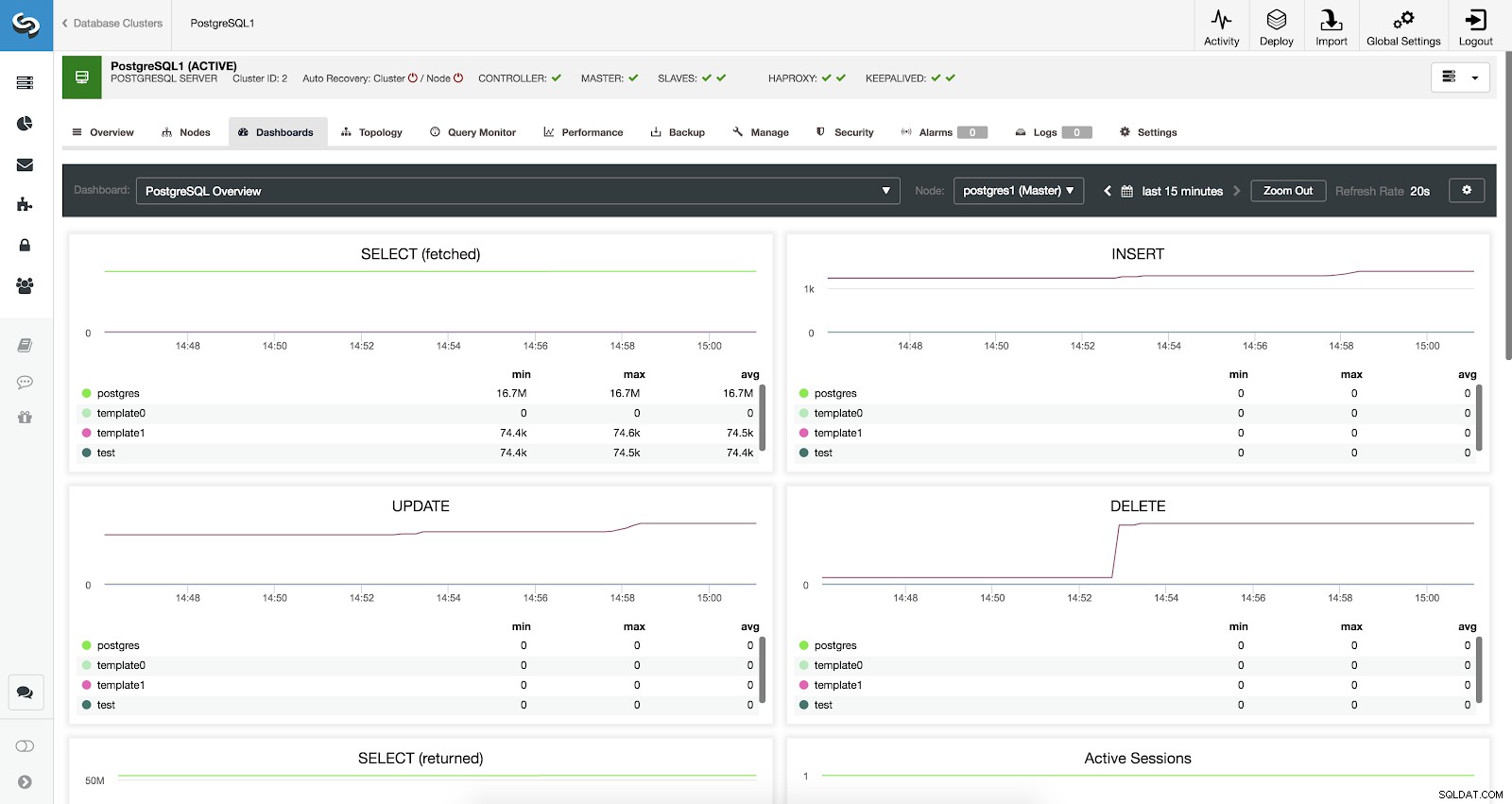 ClusterControl डैशबोर्ड सक्षम
ClusterControl डैशबोर्ड सक्षम हमारे पास तीन अलग-अलग प्रकार के डैशबोर्ड उपलब्ध हैं, सिस्टम ओवरव्यू, क्रॉस सर्वर ग्राफ़ और पोस्टग्रेएसक्यूएल ओवरव्यू। आखिरी वह है जो हम इस अनुभाग में प्रवेश करते समय डिफ़ॉल्ट रूप से देखते हैं।
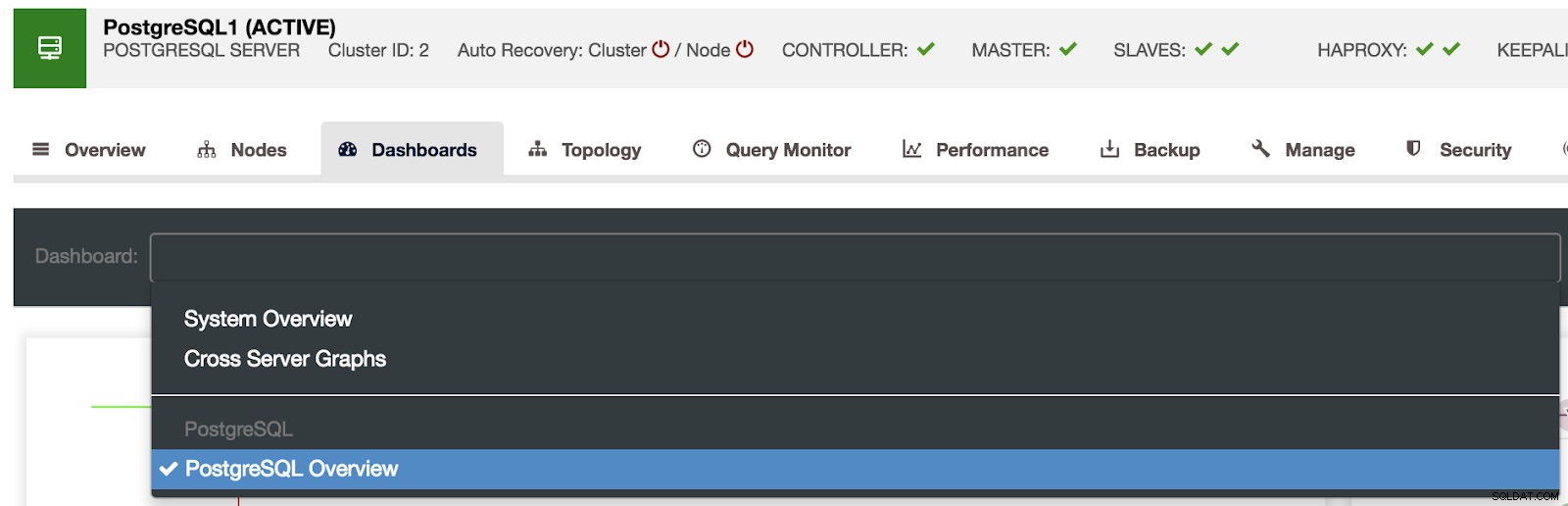 ClusterControl डैशबोर्ड चयन
ClusterControl डैशबोर्ड चयन यहां हम यह भी निर्दिष्ट कर सकते हैं कि किस नोड को मॉनिटर करना है, समय सीमा और ताज़ा दर।
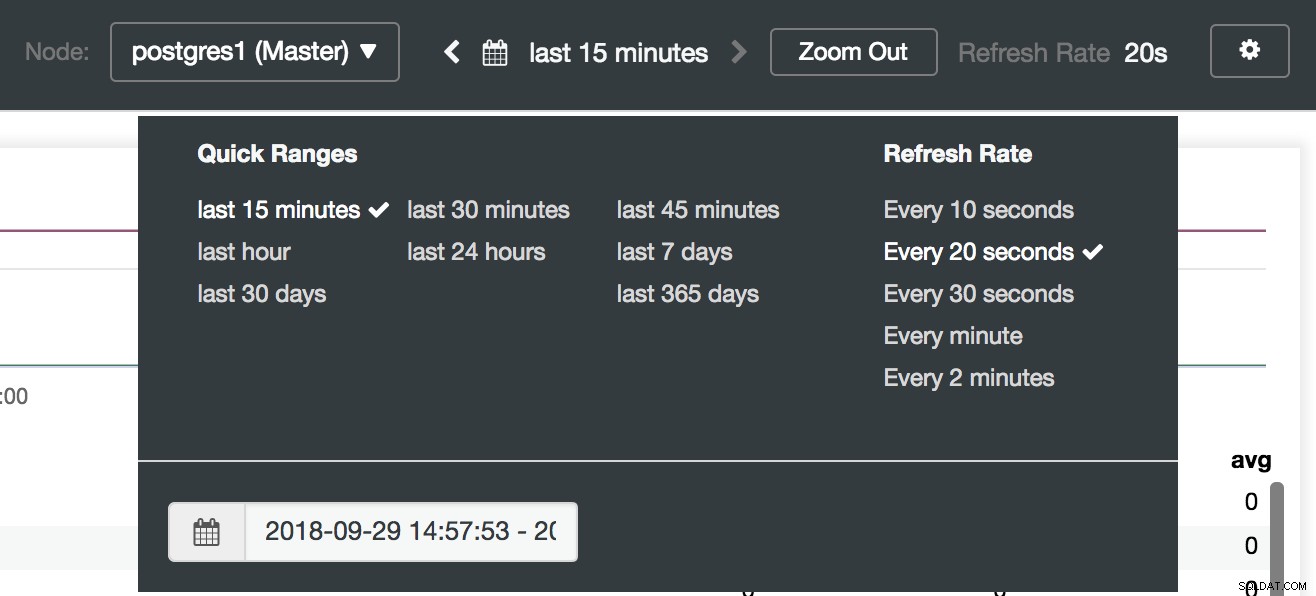 ClusterControl डैशबोर्ड विकल्प
ClusterControl डैशबोर्ड विकल्प कॉन्फ़िगरेशन अनुभाग में, हम अपने एजेंटों (निर्यातकों) को सक्षम या अक्षम कर सकते हैं, एजेंटों की स्थिति की जांच कर सकते हैं और हमारे प्रोमेथियस सर्वर के संस्करण को सत्यापित कर सकते हैं।
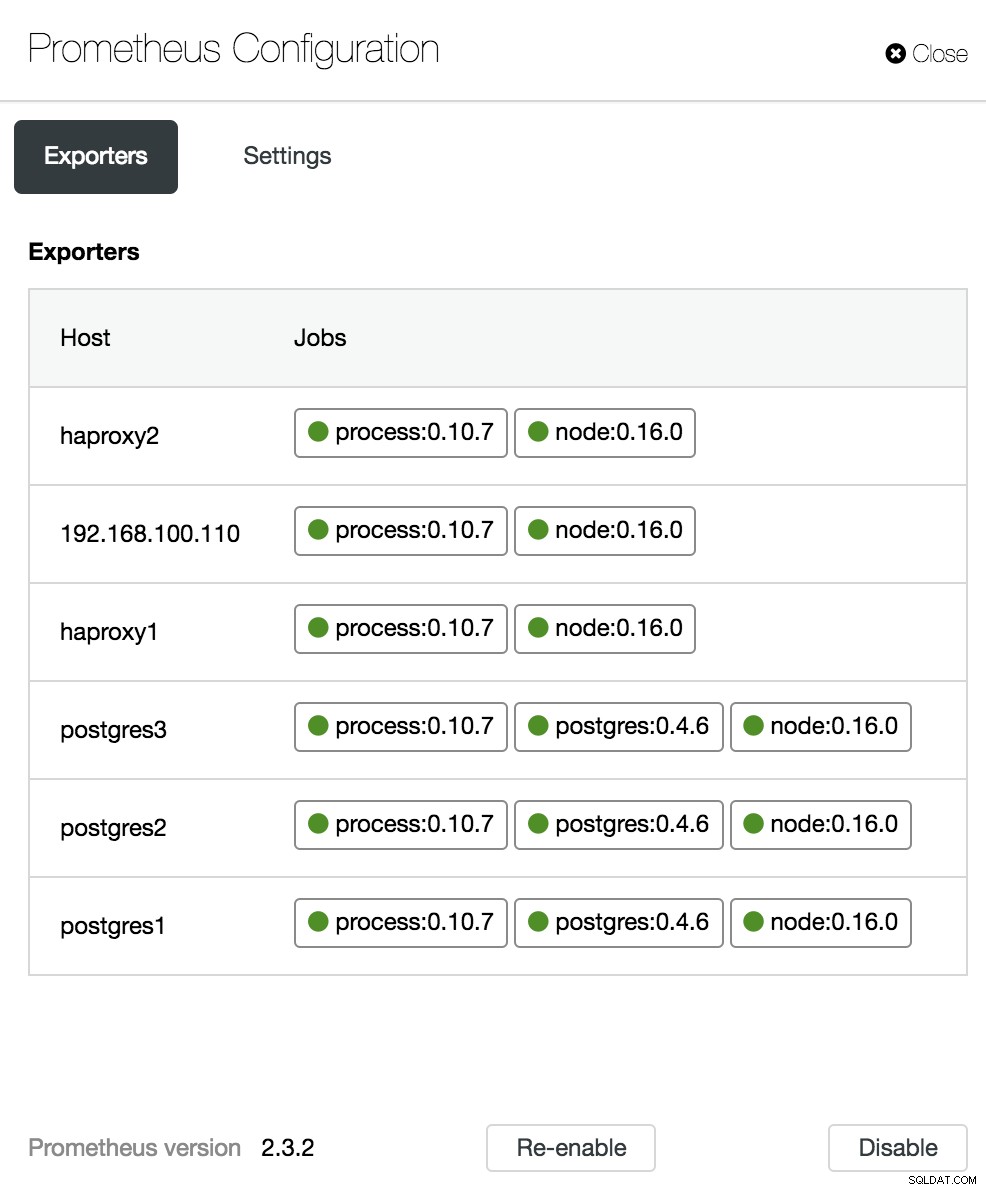 ClusterControl डैशबोर्ड कॉन्फ़िगरेशन
ClusterControl डैशबोर्ड कॉन्फ़िगरेशन PostgreSQL अवलोकन मीट्रिक
आइए अब देखें कि हमारे प्रत्येक PostgreSQL डेटाबेस के लिए हमारे पास कौन-से मेट्रिक्स उपलब्ध हैं (वे सभी चयनित नोड के लिए)।
- चुनें (लाया गया):प्रत्येक डेटाबेस के लिए चयनित (प्राप्त) पंक्तियों की मात्रा। प्राप्त की गई पंक्तियाँ तालिका से प्राप्त लाइव पंक्तियों को संदर्भित करती हैं।
- चुनें (लौटाएं):प्रत्येक डेटाबेस के लिए चयनित (लौटाई गई) पंक्तियों की मात्रा। लौटाई गई पंक्तियाँ तालिका से पढ़ी गई सभी पंक्तियों को संदर्भित करती हैं, जिसमें मृत पंक्तियाँ शामिल हैं और नहीं - अभी तक प्रतिबद्ध पंक्तियाँ (प्राप्त पंक्तियों के विपरीत जो केवल जीवित टुपल्स की गणना करती हैं)।
- INSERT:प्रत्येक डेटाबेस के लिए सम्मिलित पंक्तियों की मात्रा।
- अद्यतन:प्रत्येक डेटाबेस के लिए अद्यतन पंक्तियों की मात्रा।
- हटाएं:प्रत्येक डेटाबेस के लिए हटाई गई पंक्तियों की मात्रा।
- सक्रिय सत्र:प्रत्येक डेटाबेस के लिए सक्रिय सत्रों की संख्या (न्यूनतम, अधिकतम और औसत)।
- निष्क्रिय सत्र:प्रत्येक डेटाबेस के लिए निष्क्रिय सत्रों की संख्या (न्यूनतम, अधिकतम और औसत)।
- लॉक टेबल:प्रत्येक डेटाबेस के लिए लॉक की मात्रा (न्यूनतम, अधिकतम और औसत) प्रकार के आधार पर अलग की जाती है।
- डिस्क IO उपयोग:सर्वर डिस्क IO उपयोग।
- डिस्क उपयोग:प्रतिशत सर्वर डिस्क उपयोग (न्यूनतम, अधिकतम और औसत)।
- डिस्क विलंबता:सर्वर डिस्क विलंबता.
ClusterControl PostgreSQL ओवरव्यू मेट्रिक्स सिस्टम अवलोकन मीट्रिक
हमारे सिस्टम की निगरानी के लिए, हमारे पास प्रत्येक सर्वर के लिए निम्नलिखित मेट्रिक्स उपलब्ध हैं (सभी चयनित नोड के लिए):
- सिस्टम अपटाइम:सर्वर के चालू होने का समय।
- सीपीयू:सीपीयू की मात्रा।
- RAM:RAM मेमोरी की मात्रा।
- स्मृति उपलब्ध:उपलब्ध RAM स्मृति का प्रतिशत।
- लोड औसत:न्यूनतम, अधिकतम और औसत सर्वर लोड।
- स्मृति:उपलब्ध, कुल और प्रयुक्त सर्वर स्मृति।
- CPU उपयोग:न्यूनतम, अधिकतम और औसत सर्वर CPU उपयोग जानकारी।
- स्मृति वितरण:चयनित नोड पर स्मृति वितरण (बफर, कैशे, निःशुल्क और प्रयुक्त)।
- संतृप्ति मीट्रिक:चयनित नोड पर आईओ लोड और सीपीयू लोड का न्यूनतम, अधिकतम और औसत।
- मेमोरी उन्नत विवरण:चयनित नोड पर मेमोरी उपयोग विवरण जैसे पेज, बफर और बहुत कुछ।
- फोर्क्स:फोर्क्स प्रक्रियाओं की मात्रा। कांटा एक ऑपरेशन है जिसके द्वारा एक प्रक्रिया स्वयं की एक प्रति बनाती है। यह आमतौर पर एक सिस्टम कॉल होता है, जिसे कर्नेल में लागू किया जाता है।
- प्रक्रियाएं:ऑपरेटिंग सिस्टम पर चल रही या प्रतीक्षारत प्रक्रियाओं की मात्रा।
- संदर्भ स्विच:एक संदर्भ स्विच एक प्रक्रिया या धागे की स्थिति को संग्रहीत करने की क्रिया है।
- व्यवधान:व्यवधानों की मात्रा। इंटरप्ट एक ऐसी घटना है जो किसी प्रोग्राम के सामान्य निष्पादन प्रवाह को बदल देती है और इसे हार्डवेयर डिवाइस या स्वयं सीपीयू द्वारा भी उत्पन्न किया जा सकता है।
- नेटवर्क ट्रैफ़िक:चयनित नोड पर KBytes प्रति सेकंड में इनबाउंड और आउटबाउंड नेटवर्क ट्रैफ़िक।
- नेटवर्क उपयोग प्रति घंटा:अंतिम दिन में भेजा और प्राप्त किया गया ट्रैफ़िक।
- स्वैप:चयनित नोड पर उपयोग (निःशुल्क और प्रयुक्त) स्वैप करें।
- स्वैप गतिविधि:स्वैप पर डेटा पढ़ता और लिखता है।
- I/O गतिविधि:IO पर पेज इन और पेज आउट।
- फाइल डिस्क्रिप्टर:फाइल डिस्क्रिप्टर आवंटित और सीमित करें।
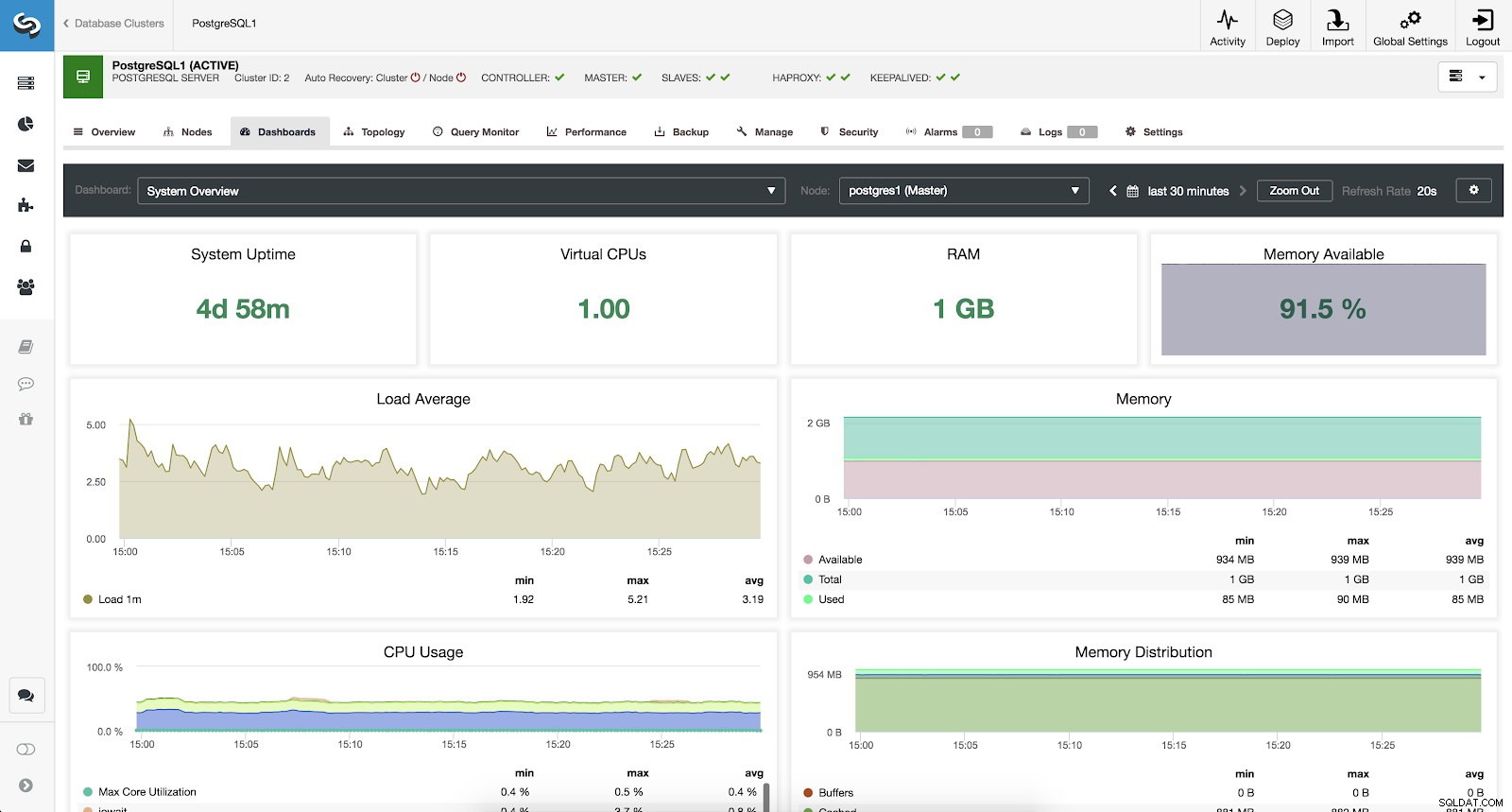 ClusterControl सिस्टम ओवरव्यू मेट्रिक्स
ClusterControl सिस्टम ओवरव्यू मेट्रिक्स क्रॉस सर्वर ग्राफ़ मेट्रिक्स
यदि हम अपने सभी सर्वरों की सामान्य स्थिति देखना चाहते हैं तो हम इस डैशबोर्ड का उपयोग निम्नलिखित मैट्रिक्स के साथ कर सकते हैं:
- लोड औसत:सर्वर प्रत्येक सर्वर के लिए औसत लोड करते हैं।
- स्मृति उपयोग:प्रत्येक सर्वर के लिए स्मृति उपयोग का प्रतिशत।
- नेटवर्क ट्रैफ़िक:प्रति सेकंड नेटवर्क ट्रैफ़िक का न्यूनतम, अधिकतम और औसत kBytes।
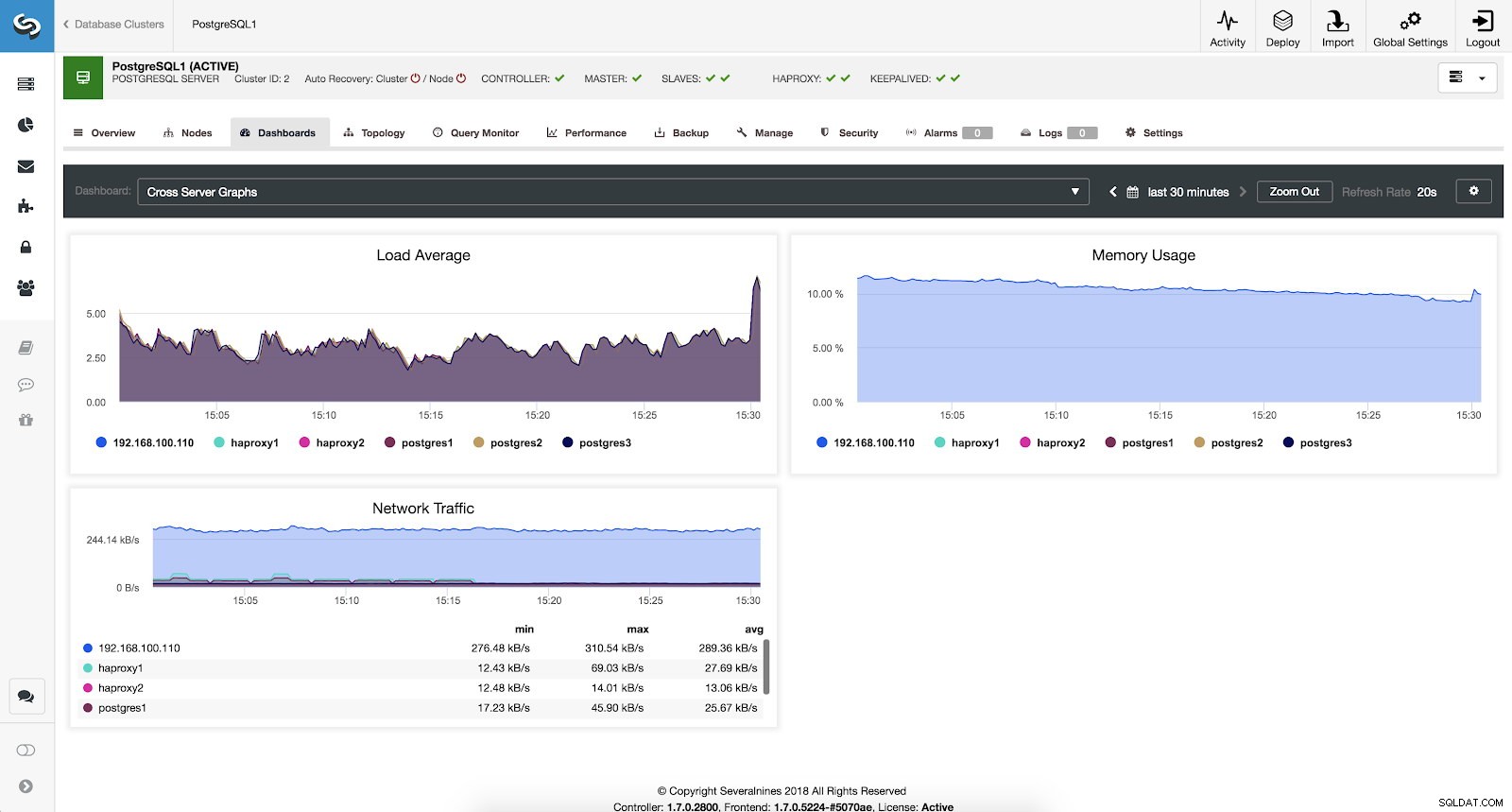 ClusterControl क्रॉस सर्वर ग्राफ़ मेट्रिक्स
ClusterControl क्रॉस सर्वर ग्राफ़ मेट्रिक्स निष्कर्ष
PostgreSQL की निगरानी के कई तरीके हैं। ClusterControl प्रोमेथियस के माध्यम से एजेंट रहित और अब एजेंट-आधारित निगरानी दोनों प्रदान करता है। यह डेटाबेस के प्रदर्शन को समझने के लिए उच्च रिज़ॉल्यूशन मॉनिटरिंग डेटा, साथ ही विभिन्न डैशबोर्ड प्रदान करता है। ClusterControl अलर्ट करने के लिए Slack या PagerDuty जैसे बाहरी टूल के साथ भी एकीकृत हो सकता है।