डेटाबेस में ट्रैफ़िक को प्रबंधित करना कठिन और कठिन हो सकता है क्योंकि यह मात्रा में बढ़ता है और डेटाबेस वास्तव में कई सर्वरों में वितरित किया जाता है। PostgreSQL क्लाइंट आमतौर पर एकल समापन बिंदु से बात करते हैं। जब एक प्राथमिक नोड विफल हो जाता है, तो डेटाबेस क्लाइंट उसी आईपी को पुनः प्रयास करते रहेंगे। यदि आप द्वितीयक नोड में विफल हो गए हैं, तो एप्लिकेशन को नए समापन बिंदु के साथ अद्यतन करने की आवश्यकता है। यह वह जगह है जहां आप अनुप्रयोगों और डेटाबेस इंस्टेंस के बीच लोड बैलेंसर रखना चाहेंगे। यह अनुप्रयोगों को उपलब्ध/स्वस्थ डेटाबेस नोड्स और आवश्यकता पड़ने पर विफलता के लिए निर्देशित कर सकता है। प्रतिकृतियों का प्रभावी ढंग से उपयोग करके पढ़ने के प्रदर्शन को बढ़ाने के लिए एक और लाभ होगा। केवल-पढ़ने के लिए पोर्ट बनाना संभव है जो प्रतिकृतियों में संतुलन पढ़ता है। इस ब्लॉग में, हम HAProxy को कवर करेंगे। हम देखेंगे कि यह क्या है, यह कैसे काम करता है और इसे PostgreSQL के लिए कैसे तैनात किया जाए।
HAProxy क्या है?
HAProxy एक खुला स्रोत प्रॉक्सी है जिसका उपयोग TCP और HTTP आधारित अनुप्रयोगों के लिए उच्च उपलब्धता, लोड संतुलन और प्रॉक्सी को लागू करने के लिए किया जा सकता है।
लोड बैलेंसर के रूप में, HAProxy एक मूल से एक या अधिक गंतव्यों तक ट्रैफ़िक वितरित करता है और इस कार्य के लिए विशिष्ट नियमों और/या प्रोटोकॉल को परिभाषित कर सकता है। यदि कोई भी गंतव्य प्रतिसाद देना बंद कर देता है, तो उसे ऑफ़लाइन के रूप में चिह्नित कर दिया जाता है, और ट्रैफ़िक को शेष उपलब्ध गंतव्यों पर भेज दिया जाता है।
HAProxy को मैन्युअल रूप से कैसे स्थापित और कॉन्फ़िगर करें
Linux पर HAProxy स्थापित करने के लिए आप निम्न कमांड का उपयोग कर सकते हैं:
उबंटू/डेबियन ओएस पर:
$ apt-get install haproxy -yCentOS/RedHat OS पर:
$ yum install haproxy -yऔर फिर हमें अपने HAProxy कॉन्फ़िगरेशन को प्रबंधित करने के लिए निम्न कॉन्फ़िगरेशन फ़ाइल को संपादित करने की आवश्यकता है:
$ /etc/haproxy/haproxy.cfgहमारे HAProxy को कॉन्फ़िगर करना जटिल नहीं है, लेकिन हमें यह जानना होगा कि हम क्या कर रहे हैं। हमारे पास कॉन्फ़िगर करने के लिए कई पैरामीटर हैं, यह इस पर निर्भर करता है कि हम HAProxy को कैसे काम करना चाहते हैं। अधिक जानकारी के लिए, हम HAProxy कॉन्फ़िगरेशन के बारे में दस्तावेज़ीकरण का पालन कर सकते हैं।
आइए एक बुनियादी विन्यास उदाहरण देखें। मान लीजिए कि आपके पास निम्न डेटाबेस टोपोलॉजी है:
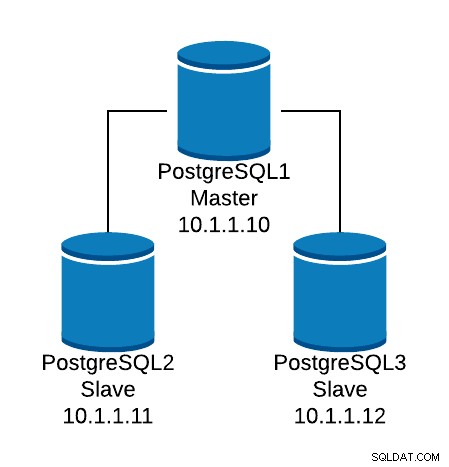 डेटाबेस टोपोलॉजी उदाहरण
डेटाबेस टोपोलॉजी उदाहरण हम तीन नोड्स के बीच पढ़ने वाले ट्रैफ़िक को संतुलित करने के लिए एक HAProxy श्रोता बनाना चाहते हैं।
listen haproxy_read
bind *:5434
balance roundrobin
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkजैसा कि हमने पहले उल्लेख किया है, यहां कॉन्फ़िगर करने के लिए कई पैरामीटर हैं, और यह कॉन्फ़िगरेशन इस बात पर निर्भर करता है कि हम क्या करना चाहते हैं। उदाहरण के लिए:
listen haproxy_read
bind *:5434
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running
balance leastconn
option tcp-check
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkक्लस्टरकंट्रोल पर HAProxy कैसे काम करता है
PostgreSQL के लिए, HAProxy को ClusterControl द्वारा डिफ़ॉल्ट रूप से दो अलग-अलग पोर्ट के साथ कॉन्फ़िगर किया गया है, एक रीड-राइट और एक रीड-ओनली।
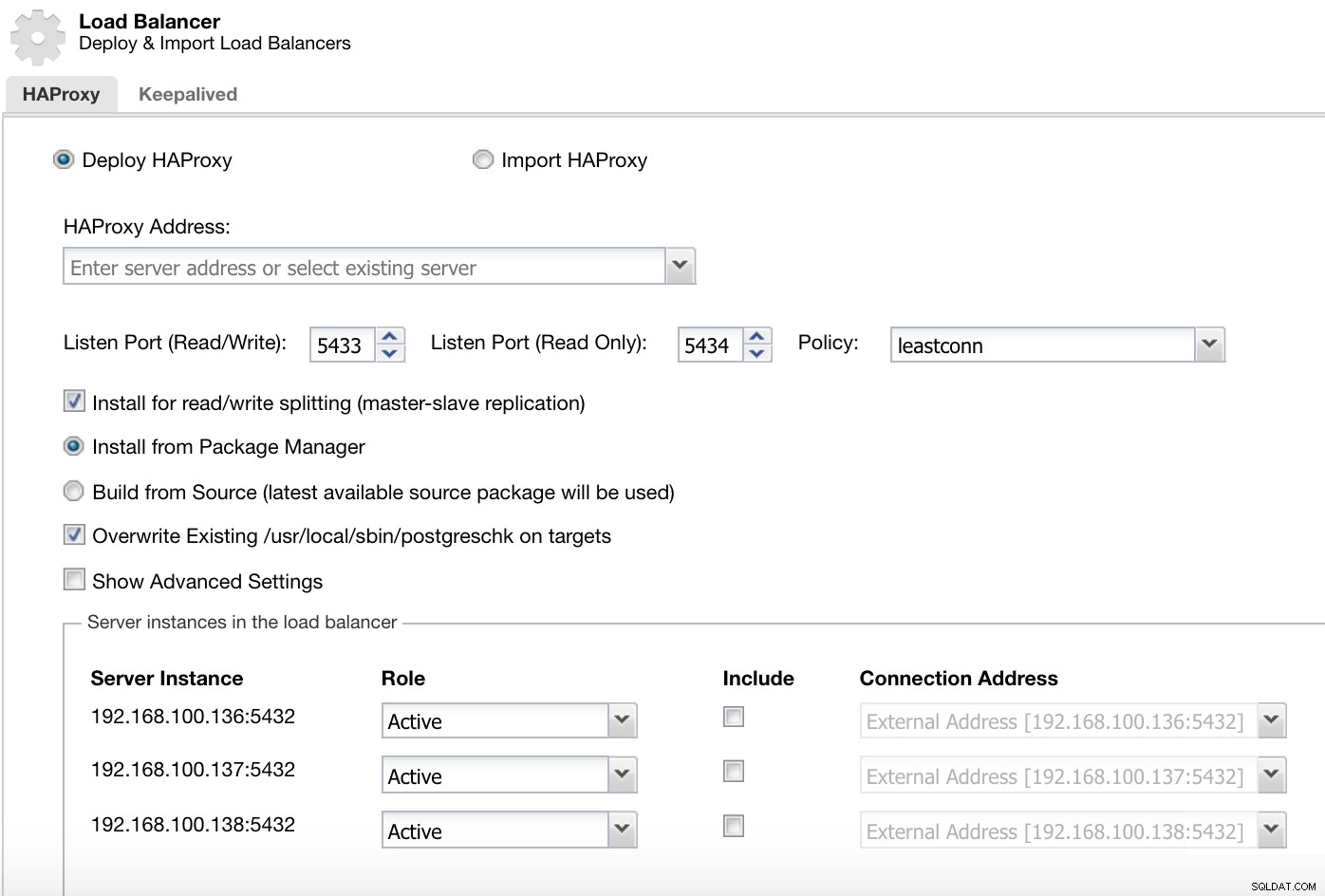 ClusterControl लोड बैलेंसर सूचना 1 तैनात करें
ClusterControl लोड बैलेंसर सूचना 1 तैनात करें हमारे रीड-राइट पोर्ट में, हमारे पास हमारा मास्टर सर्वर ऑनलाइन है और हमारे बाकी नोड्स ऑफ़लाइन हैं, और रीड-ओनली पोर्ट में, हमारे पास मास्टर और स्लेव दोनों ऑनलाइन हैं।
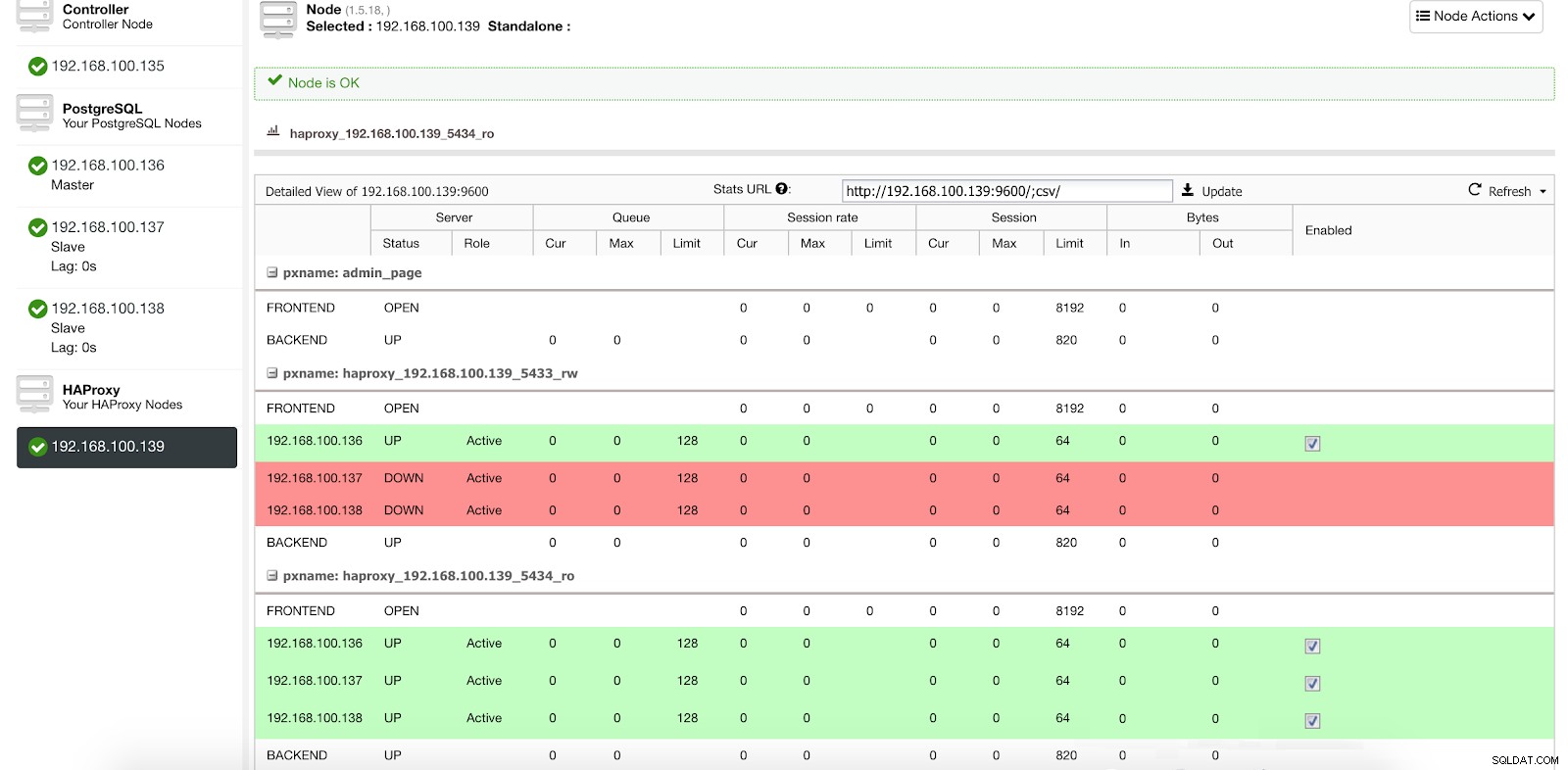 ClusterControl लोड बैलेंसर आँकड़े 1
ClusterControl लोड बैलेंसर आँकड़े 1 जब HAProxy को पता चलता है कि हमारा एक नोड, या तो मास्टर या स्लेव, पहुंच योग्य नहीं है, तो यह स्वचालित रूप से इसे ऑफ़लाइन के रूप में चिह्नित करता है और ट्रैफ़िक भेजते समय इसे ध्यान में नहीं रखता है। जांच स्वास्थ्य जांच स्क्रिप्ट द्वारा की जाती है जिसे परिनियोजन के समय क्लस्टरकंट्रोल द्वारा कॉन्फ़िगर किया जाता है। ये जाँचते हैं कि क्या इंस्टेंस ऊपर हैं, क्या वे ठीक हो रहे हैं, या केवल-पढ़ने के लिए हैं।
जब ClusterControl एक गुलाम को मास्टर करने के लिए बढ़ावा देता है, तो हमारा HAProxy पुराने मास्टर को ऑफ़लाइन (दोनों पोर्ट के लिए) के रूप में चिह्नित करता है और प्रचारित नोड को ऑनलाइन (रीड-राइट पोर्ट में) डालता है।
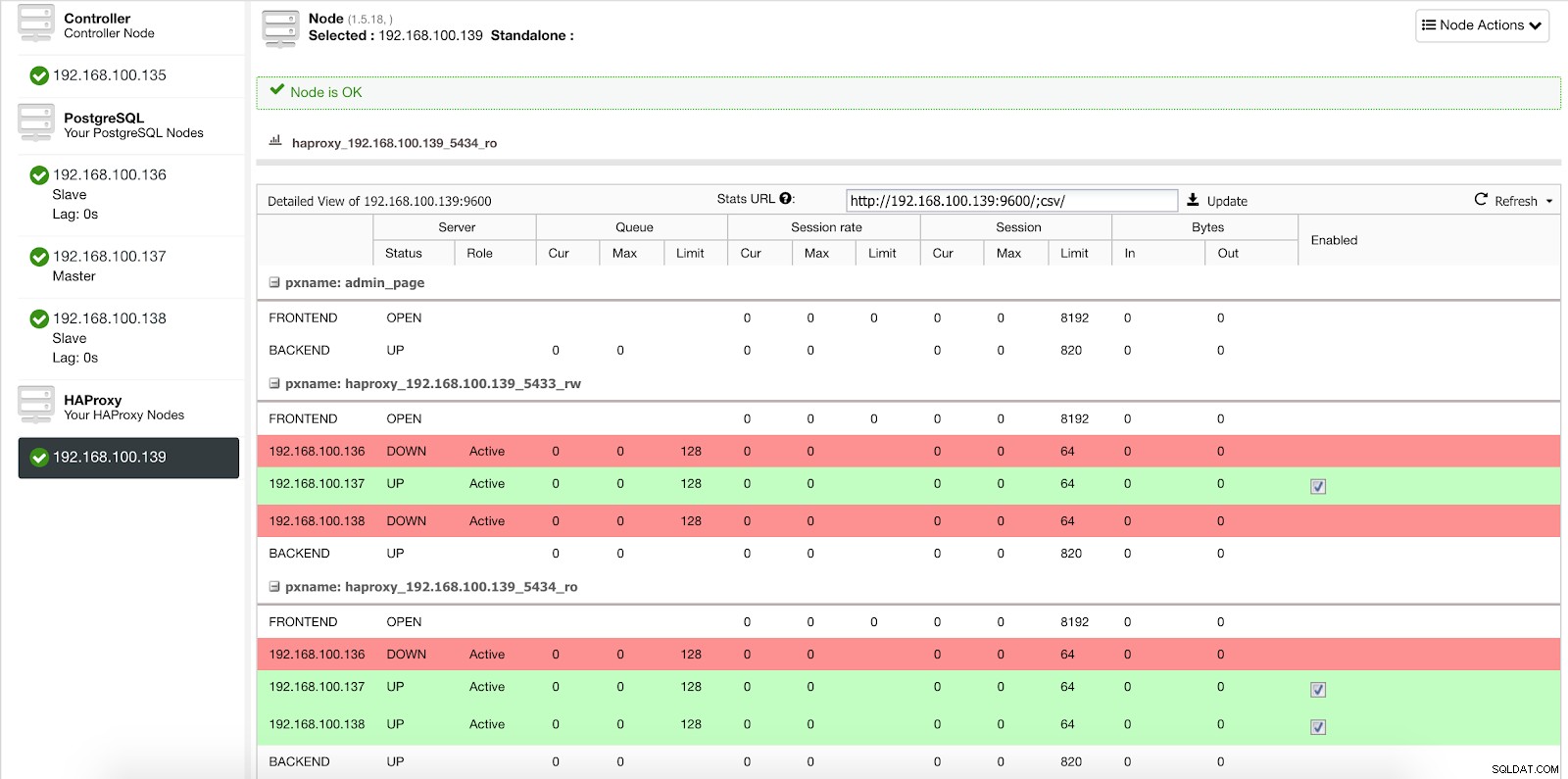 ClusterControl लोड बैलेंसर आँकड़े 2
ClusterControl लोड बैलेंसर आँकड़े 2 इस तरह, हमारे सिस्टम सामान्य रूप से और हमारे हस्तक्षेप के बिना काम करना जारी रखते हैं।
क्लस्टरकंट्रोल के साथ HAProxy को कैसे परिनियोजित करें
हमारे उदाहरण में, हमने 1 मास्टर और 2 दासों के साथ एक वातावरण बनाया - क्लस्टरकंट्रोल में टोपोलॉजी व्यू का एक स्क्रीनशॉट देखें। अब हम अपना HAProxy लोड बैलेंसर जोड़ेंगे।
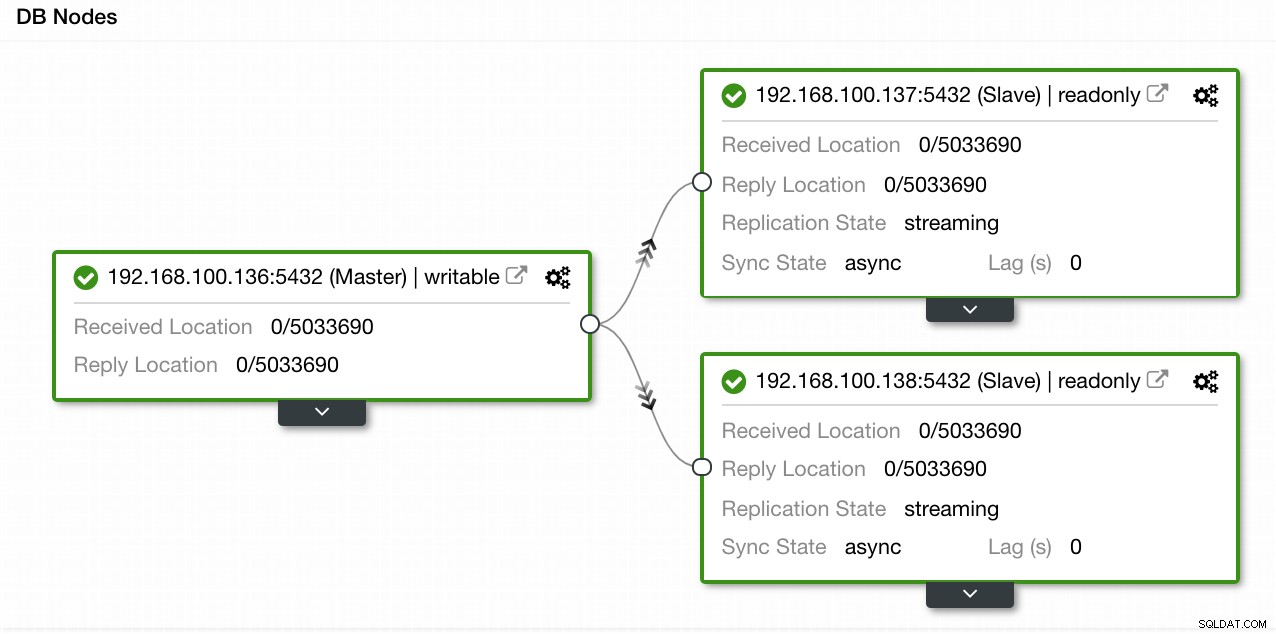 ClusterControl टोपोलॉजी व्यू 1
ClusterControl टोपोलॉजी व्यू 1 इस कार्य के लिए हमें ClusterControl -> PostgreSQL Cluster Actions -> Add Load Balancer
. पर जाना होगा ClusterControl क्लस्टर क्रियाएँ मेनू
ClusterControl क्लस्टर क्रियाएँ मेनू यहां हमें वह जानकारी जोड़नी होगी जिसका उपयोग ClusterControl हमारे HAProxy लोड बैलेंसर को स्थापित और कॉन्फ़िगर करने के लिए करेगा।
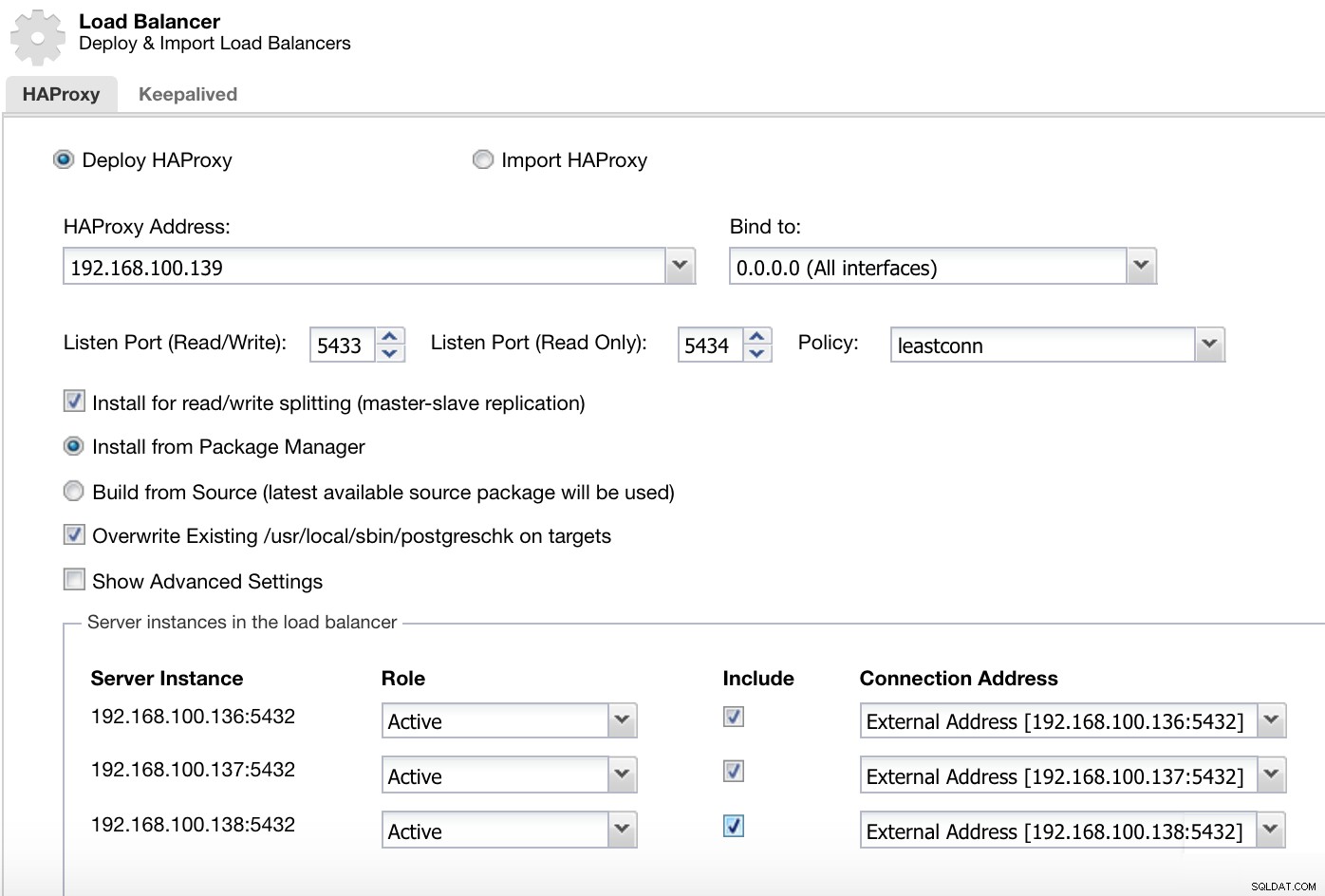 ClusterControl लोड बैलेंसर सूचना 2 तैनात करें
ClusterControl लोड बैलेंसर सूचना 2 तैनात करें हमें जो जानकारी प्रस्तुत करनी है वह है:
क्रिया:तैनात या आयात करें।
HAProxy पता:हमारे HAProxy सर्वर के लिए IP पता।
बाइंड करें:इंटरफ़ेस या IP पता जहां HAProxy सुनेगा।
पोर्ट सुनें (पढ़ें/लिखें):पढ़ने/लिखने के मोड के लिए पोर्ट।
पोर्ट सुनें (केवल पढ़ने के लिए):केवल पढ़ने के लिए पोर्ट।
नीति:यह हो सकता है:
- Leastconn:सबसे कम कनेक्शन वाला सर्वर कनेक्शन प्राप्त करता है।
- राउंडरोबिन:प्रत्येक सर्वर का उपयोग उनके वजन के अनुसार बारी-बारी से किया जाता है।
- स्रोत:स्रोत आईपी पता हैश किया गया है और चल रहे सर्वर के कुल भार से विभाजित किया गया है ताकि यह निर्दिष्ट किया जा सके कि कौन सा सर्वर अनुरोध प्राप्त करेगा।
पढ़ने/लिखने के विभाजन के लिए स्थापित करें:मास्टर-दास प्रतिकृति के लिए।
स्रोत:हम पैकेज मैनेजर से इंस्टॉल या सोर्स से बिल्ड चुन सकते हैं।
लक्ष्य पर मौजूदा पोस्टग्रेस्क को अधिलेखित करें।
और हमें यह चुनने की आवश्यकता है कि आप HAProxy कॉन्फ़िगरेशन में कौन से सर्वर जोड़ना चाहते हैं और कुछ अतिरिक्त जानकारी जैसे:
भूमिका:यह सक्रिय या बैकअप हो सकता है।
शामिल करें:हाँ या नहीं।
कनेक्शन पता जानकारी।
साथ ही, हम व्यवस्थापक उपयोगकर्ता, बैकएंड नाम, टाइमआउट आदि जैसी उन्नत सेटिंग्स को कॉन्फ़िगर कर सकते हैं।
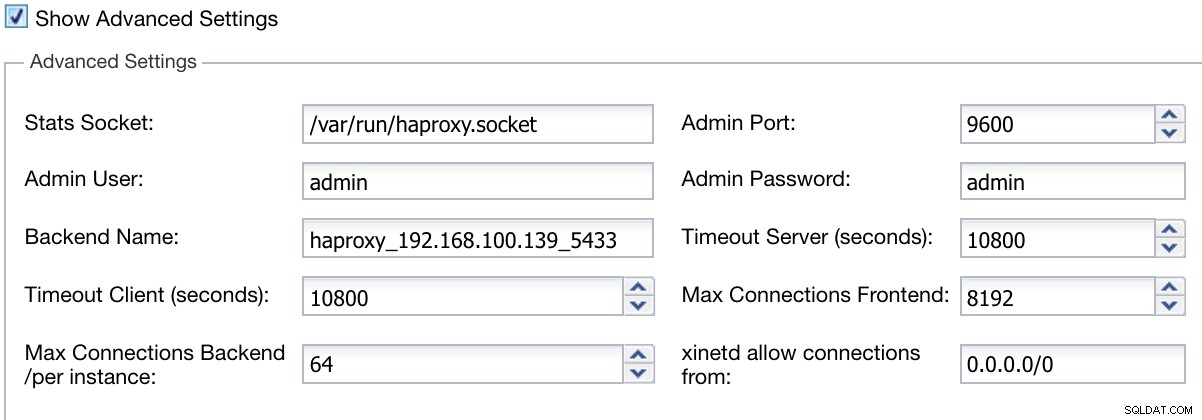 ClusterControl लोड बैलेंसर सूचना उन्नत तैनात करें
ClusterControl लोड बैलेंसर सूचना उन्नत तैनात करें जब आप कॉन्फ़िगरेशन समाप्त कर लें और परिनियोजन की पुष्टि करें, तो हम ClusterControl UI पर गतिविधि अनुभाग में प्रगति का अनुसरण कर सकते हैं।
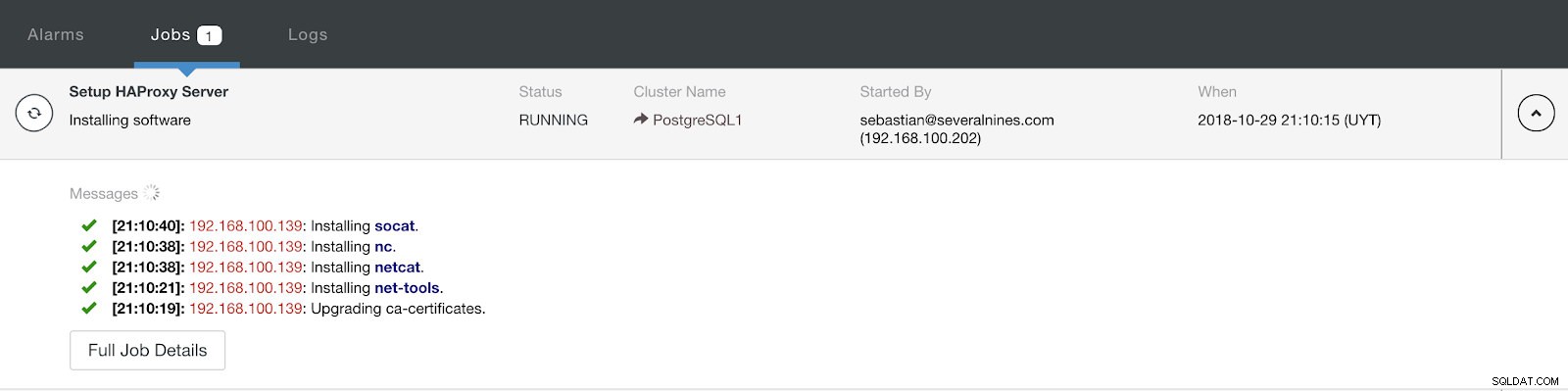 ClusterControl गतिविधि अनुभाग
ClusterControl गतिविधि अनुभाग जब यह समाप्त हो जाए, तो हमारे पास निम्नलिखित टोपोलॉजी होनी चाहिए:
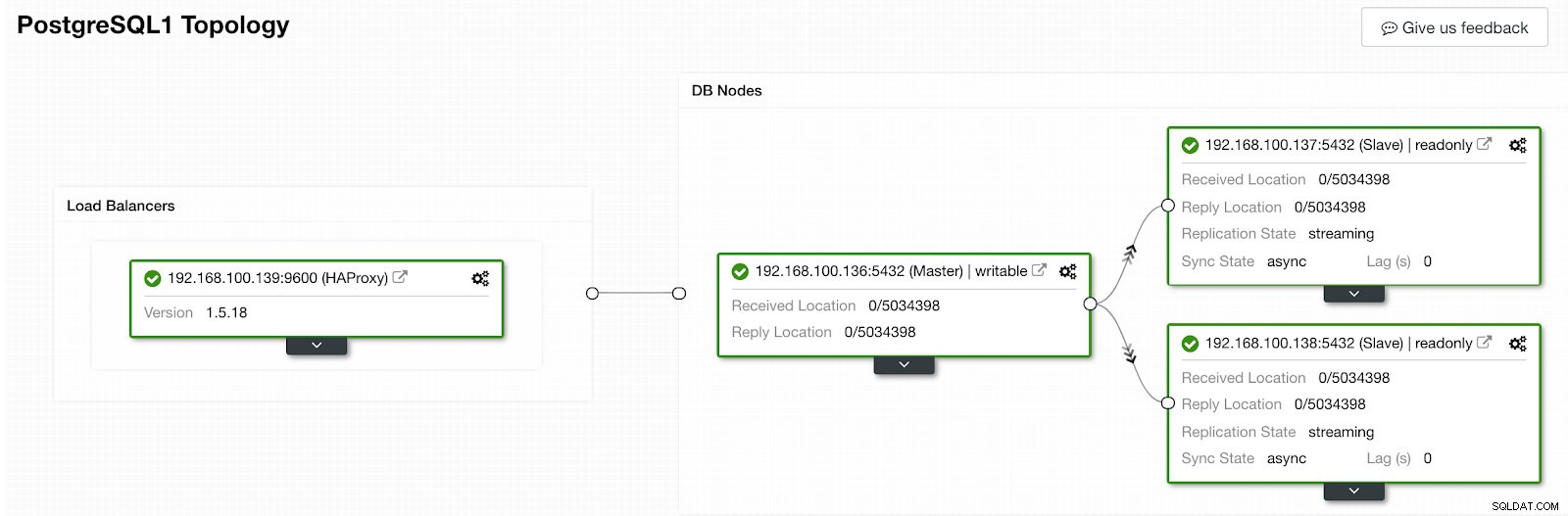 ClusterControl टोपोलॉजी व्यू 2
ClusterControl टोपोलॉजी व्यू 2 हम एक नया HAProxy नोड जोड़कर और उनके बीच Keepalived सेवा को कॉन्फ़िगर करके अपने HA डिज़ाइन में सुधार कर सकते हैं। यह सब ClusterControl द्वारा किया जा सकता है। अधिक जानकारी के लिए, आप हमारे पिछले ब्लॉग को PostgreSQL और HA के बारे में देख सकते हैं।
HAProxy लोड बैलेंसर जोड़ने के लिए ClusterControl CLI का उपयोग करना
s9s-tools के रूप में भी जाना जाता है, यह वैकल्पिक पैकेज ClusterControl संस्करण 1.4.1 में पेश किया गया था, जिसमें s9s नामक एक बाइनरी शामिल है। यह ClusterControl का उपयोग करके आपके डेटाबेस इन्फ्रास्ट्रक्चर को इंटरैक्ट करने, नियंत्रित करने और प्रबंधित करने के लिए एक कमांड लाइन टूल है। S9s कमांड लाइन प्रोजेक्ट ओपन सोर्स है और इसे GitHub पर पाया जा सकता है।
संस्करण 1.4.1 से शुरू होकर, इंस्टॉलर स्क्रिप्ट संकुल नियंत्रण नोड पर पैकेज (s9s-tools) को स्वचालित रूप से स्थापित कर देगी।
ClusterControl CLI क्लस्टर ऑटोमेशन के लिए एक नया द्वार खोलता है जहाँ आप इसे Ansible, Puppet, Chef या Salt जैसे मौजूदा परिनियोजन ऑटोमेशन टूल के साथ आसानी से एकीकृत कर सकते हैं।
आइए एक उदाहरण देखें कि क्लस्टर आईडी 1 पर आईपी एड्रेस 192.168.100.142 के साथ HAProxy लोड बैलेंसर कैसे बनाया जाए:
[example@sqldat.com ~]# s9s cluster --add-node --cluster-id=1 --nodes="haproxy://192.168.100.142" --wait
Add HaProxy to Cluster
/ Job 7 FINISHED [██████████] 100% Job finished.और फिर हम कमांड लाइन से अपने सभी नोड्स की जांच कर सकते हैं:
[example@sqldat.com ~]# s9s node --cluster-id=1 --list --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PostgreSQL1 192.168.100.135 9500 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.136 5432 Up and running.
poM- 10.5 1 PostgreSQL1 192.168.100.137 5432 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.138 5432 Up and running.
ho-- 1.5.18 1 PostgreSQL1 192.168.100.142 9600 Process 'haproxy' is running.
Total: 5S9s के बारे में और इसका उपयोग कैसे करें, इसके बारे में अधिक जानकारी के लिए, आप आधिकारिक दस्तावेज़ीकरण या इस विषय का ब्लॉग कैसे करें देख सकते हैं।
निष्कर्ष
इस ब्लॉग में, हमने समीक्षा की है कि कैसे HAProxy एप्लिकेशन से आने वाले ट्रैफ़िक को हमारे PostgreSQL डेटाबेस में प्रबंधित करने में हमारी मदद कर सकता है। हमने जांच की कि इसे मैन्युअल रूप से कैसे तैनात और कॉन्फ़िगर किया जा सकता है, और फिर देखा कि इसे ClusterControl के साथ कैसे स्वचालित किया जा सकता है। HAProxy को विफलता का एकल बिंदु (SPOF) बनने से बचाने के लिए, सुनिश्चित करें कि आपने कम से कम दो HAProxy इंस्टेंसेस को परिनियोजित किया है और उनके ऊपर Keepalived और Virtual IP जैसी कोई चीज़ लागू की है।