उत्पादन में जाना एक बहुत ही महत्वपूर्ण कार्य है जिसे पहले से सावधानीपूर्वक सोचा और नियोजित किया जाना चाहिए। कुछ इतने अच्छे निर्णय बाद में आसानी से ठीक नहीं किए जा सकते हैं, लेकिन कुछ अन्य नहीं। इसलिए बाद में पछताने के बजाय दूसरों द्वारा किए गए आधिकारिक दस्तावेज़ों, पुस्तकों और शोध को जल्दी पढ़ने में उस अतिरिक्त समय को खर्च करना हमेशा बेहतर होता है। यह अधिकांश कंप्यूटर सिस्टम परिनियोजन के लिए सही है, और PostgreSQL कोई अपवाद नहीं है।
सिस्टम की प्रारंभिक योजना
सिस्टम के लाइव होने से पहले कुछ निर्णय जल्दी लिए जाने चाहिए। PostgreSQL DBA को कई सवालों के जवाब देने चाहिए:क्या DB नंगे धातु, VMs या यहां तक कि कंटेनरीकृत पर भी चलेगा? यह संगठन के परिसर में चलेगा या बादल में? कौन सा ओएस इस्तेमाल किया जाएगा? क्या भंडारण कताई डिस्क प्रकार या एसएसडी का होने वाला है? प्रत्येक परिदृश्य या निर्णय के लिए, पेशेवरों और विपक्ष हैं और अंतिम कॉल संगठन की आवश्यकताओं के अनुसार हितधारकों के सहयोग से किया जाएगा। परंपरागत रूप से लोग पोस्टग्रेएसक्यूएल को नंगे धातु पर चलाते थे, लेकिन हाल के वर्षों में यह नाटकीय रूप से बदल गया है क्योंकि अधिक से अधिक क्लाउड प्रदाता पोस्टग्रेएसक्यूएल को एक मानक विकल्प के रूप में पेश करते हैं, जो व्यापक रूप से अपनाने का संकेत है और पोस्टग्रेएसक्यूएल की बढ़ती लोकप्रियता का परिणाम है। विशिष्ट समाधान के स्वतंत्र रूप से, डीबीए को यह सुनिश्चित करना चाहिए कि डेटा सुरक्षित रहेगा, जिसका अर्थ है कि डेटाबेस क्रैश से बचने में सक्षम होगा, और हार्डवेयर और भंडारण के बारे में निर्णय लेते समय यह नंबर 1 मानदंड है। तो यह हमें पहली युक्ति पर लाता है!
टिप 1
कोई फर्क नहीं पड़ता कि डिस्क नियंत्रक या डिस्क निर्माता या क्लाउड स्टोरेज प्रदाता क्या विज्ञापित करता है, आपको हमेशा यह सुनिश्चित करना चाहिए कि भंडारण fsync के बारे में झूठ नहीं है। एक बार fsync के ठीक हो जाने पर, डेटा माध्यम पर सुरक्षित होना चाहिए, चाहे बाद में कुछ भी हो (दुर्घटना, बिजली की विफलता, आदि)। एक अच्छा टूल जो आपके डिस्क के राइट-बैक कैश की विश्वसनीयता का परीक्षण करने में आपकी सहायता करेगा, वह है diskchecker.pl।
बस नोट्स पढ़ें:https://brad.livejournal.com/2116715.html और परीक्षण करें।
घटनाओं को सुनने के लिए एक मशीन और परीक्षण करने के लिए वास्तविक मशीन का उपयोग करें। आपको देखना चाहिए:
verifying: 0.00%
verifying: 10.65%
…..
verifying: 100.00%
Total errors: 0परीक्षण मशीन पर रिपोर्ट के अंत में।
विश्वसनीयता के बाद दूसरी चिंता प्रदर्शन के बारे में होनी चाहिए। सिस्टम (सीपीयू, मेमोरी) के बारे में निर्णय बहुत अधिक महत्वपूर्ण हुआ करते थे क्योंकि बाद में उन्हें बदलना काफी कठिन था। लेकिन आज के क्लाउड युग में, हम उन प्रणालियों के बारे में अधिक लचीले हो सकते हैं जिन पर DB चलता है। भंडारण के लिए भी यही सच है, विशेष रूप से सिस्टम के प्रारंभिक जीवन में और जबकि आकार अभी भी छोटे हैं। जब DB आकार में टीबी के आंकड़े से आगे निकल जाता है, तो डेटाबेस को पूरी तरह से कॉपी करने की आवश्यकता के बिना बुनियादी भंडारण मापदंडों को बदलना कठिन और कठिन हो जाता है - या इससे भी बदतर, एक pg_dump, pg_restore करने के लिए। दूसरी युक्ति सिस्टम प्रदर्शन के बारे में है।
टिप 2
इसी तरह हमेशा विश्वसनीयता के संबंध में निर्माताओं के वादों का परीक्षण करने के लिए, वही आपको हार्डवेयर प्रदर्शन के बारे में करना चाहिए। बोनी ++ यूनिक्स जैसी प्रणालियों के लिए सबसे लोकप्रिय भंडारण प्रदर्शन बेंचमार्क है। समग्र सिस्टम परीक्षण (सीपीयू, मेमोरी और स्टोरेज) के लिए डीबी के प्रदर्शन से ज्यादा प्रतिनिधि कुछ भी नहीं है। तो आपके नए सिस्टम पर बुनियादी प्रदर्शन परीक्षण, टीसीपी-बी पर आधारित आधिकारिक पोस्टग्रेएसक्यूएल बेंचमार्क सूट, पीजीबेंच चल रहा होगा।
पीजीबेंच के साथ शुरुआत करना काफी आसान है, आपको बस इतना करना है:
example@sqldat.com:~$ createdb pgbench
example@sqldat.com:~$ pgbench -i pgbench
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 100000 tuples (100%) done (elapsed 0.12 s, remaining 0.00 s)
vacuum...
set primary keys...
done.
example@sqldat.com:~$ pgbench pgbench
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
number of transactions per client: 10
number of transactions actually processed: 10/10
latency average = 2.038 ms
tps = 490.748098 (including connections establishing)
tps = 642.100047 (excluding connections establishing)
example@sqldat.com:~$किसी भी महत्वपूर्ण बदलाव के बाद आपको हमेशा pgbench से परामर्श लेना चाहिए, जिसका आप मूल्यांकन करना चाहते हैं और परिणामों की तुलना करना चाहते हैं।
सिस्टम परिनियोजन, स्वचालन और निगरानी
एक बार जब आप लाइव हो जाते हैं तो आपके मुख्य सिस्टम घटकों का दस्तावेजीकरण और प्रतिलिपि प्रस्तुत करने योग्य होना, सेवाओं को बनाने और पुनरावर्ती कार्यों के लिए स्वचालित प्रक्रियाओं के लिए और निरंतर निगरानी करने के लिए उपकरण भी होना बहुत महत्वपूर्ण है।
टिप 3
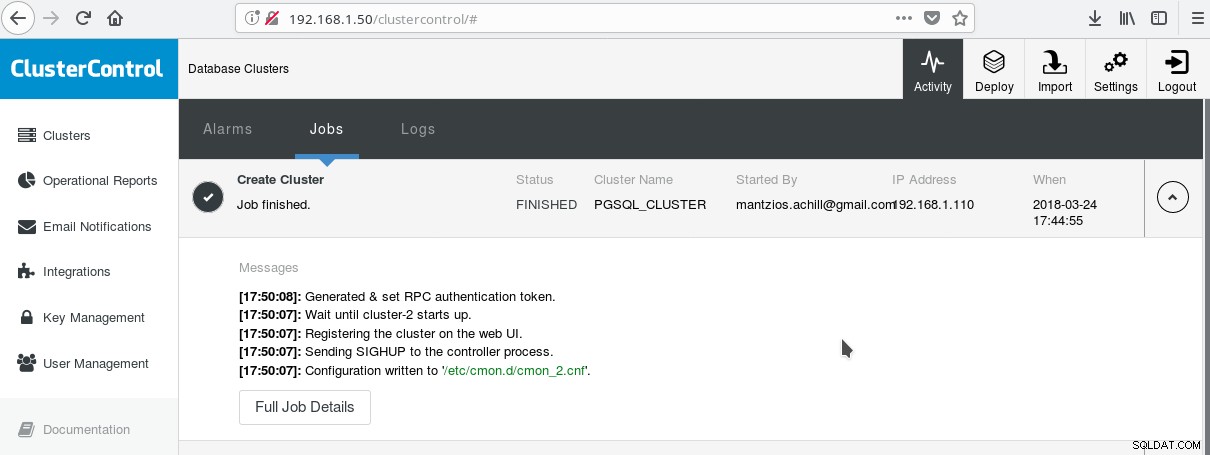
अपनी सभी उन्नत एंटरप्राइज़ सुविधाओं के साथ PostgreSQL का उपयोग शुरू करने का एक आसान तरीका ClusterControl by Manynines है। बस कुछ ही क्लिक करके, एक एंटरप्राइज़-क्लास PostgreSQL क्लस्टर हो सकता है। ClusterControl उपरोक्त सभी सेवाएँ और बहुत कुछ प्रदान करता है। ClusterControl सेट करना काफी आसान है, बस आधिकारिक दस्तावेज़ीकरण के निर्देशों का पालन करें। एक बार जब आप अपना सिस्टम तैयार कर लेते हैं (आमतौर पर एक सीसी चलाने के लिए और एक मूल सेटअप के लिए पोस्टग्रेएसक्यूएल के लिए) और एसएसएच सेटअप किया है, तो आपको मूल पैरामीटर (आईपी, पोर्ट नंबर, आदि) दर्ज करना होगा, और यदि सब ठीक हो जाता है तो आपको चाहिए निम्न जैसा आउटपुट देखें:
और मुख्य क्लस्टर स्क्रीन में:
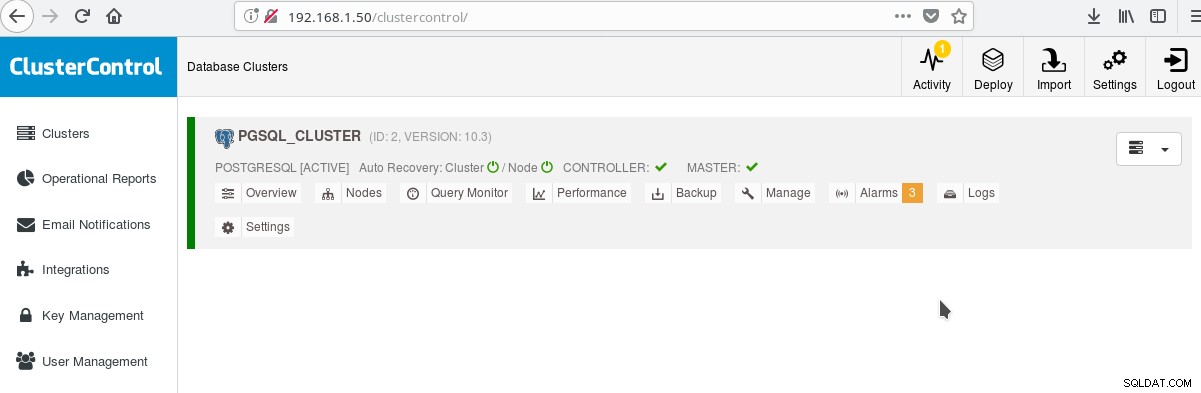
आप अपने मास्टर सर्वर में लॉग इन कर सकते हैं और अपनी स्कीमा बनाना शुरू कर सकते हैं! बेशक आप अपने बुनियादी ढांचे (टोपोलॉजी) को और अधिक बनाने के लिए आपके द्वारा अभी बनाए गए क्लस्टर के आधार के रूप में उपयोग कर सकते हैं। आपके द्वारा अभी-अभी बनाए गए नए सर्वर के आधार पर क्लोन और स्टैंडबाय (दास) बनाना शुरू करने से पहले आपके PostgreSQL सर्वर और उपयोगकर्ता/ऐप डेटाबेस पर एक स्थिर सर्वर फ़ाइल सिस्टम लेआउट और एक अंतिम कॉन्फ़िगरेशन होना आम तौर पर एक अच्छा विचार है।
PostgreSQL लेआउट, पैरामीटर और सेटिंग्स
क्लस्टर आरंभीकरण चरण में सबसे महत्वपूर्ण निर्णय यह है कि डेटा पृष्ठों पर डेटा चेकसम का उपयोग करना है या नहीं। यदि आप अपने मूल्यवान (भविष्य) डेटा के लिए अधिकतम डेटा सुरक्षा चाहते हैं, तो यह ऐसा करने का समय है। यदि ऐसा मौका है कि आप भविष्य में इस सुविधा को चाहते हैं और आप इसे इस स्तर पर करने की उपेक्षा करते हैं, तो आप इसे बाद में नहीं बदल पाएंगे (बिना pg_dump/pg_restore के)। यह अगली युक्ति है:
टिप 4
डेटा चेकसम को सक्षम करने के लिए निम्न प्रकार से initdb चलाएं:
$ /usr/lib/postgresql/10/bin/initdb --data-checksums <DATADIR>ध्यान दें कि यह ऊपर वर्णित टिप 3 के समय किया जाना चाहिए। यदि आपने पहले ही ClusterControl के साथ क्लस्टर बना लिया है तो आपको pg_createcluster को हाथ से फिर से चलाना होगा, क्योंकि इस लेखन के समय सिस्टम या CC को इस विकल्प को शामिल करने के लिए कहने का कोई तरीका नहीं है।
उत्पादन में जाने से पहले एक और बहुत महत्वपूर्ण कदम सर्वर फाइल सिस्टम लेआउट की योजना बना रहा है। अधिकांश आधुनिक लिनक्स डिस्ट्रोस (कम से कम डेबियन-आधारित वाले) सब कुछ माउंट करते हैं / लेकिन PostgreSQL के साथ आमतौर पर आप ऐसा नहीं चाहते हैं। अपने टेबलस्पेस को अलग वॉल्यूम पर रखना फायदेमंद है, एक वॉल्यूम वाल फाइलों के लिए समर्पित है और दूसरा पीजी लॉग के लिए है। लेकिन सबसे महत्वपूर्ण है वाल को अपनी डिस्क पर ले जाना। यह हमें अगले टिप पर लाता है।
टिप 5
डेबियन स्ट्रेच पर PostgreSQL 10 के साथ, आप अपने WAL को निम्न कमांड के साथ एक नई डिस्क पर ले जा सकते हैं (मान लीजिए कि नई डिस्क का नाम /dev/sdb है):
# mkfs.ext4 /dev/sdb
# mount /dev/sdb /pgsql_wal
# mkdir /pgsql_wal/pgsql
# chown postgres:postgres /pgsql_wal/pgsql
# systemctl stop postgresql
# su postgres
$ cd /var/lib/postgresql/10/main/
$ mv pg_wal /pgsql_wal/pgsql/.
$ ln -s /pgsql_wal/pgsql/pg_wal
$ exit
# systemctl start postgresqlअपने डेटाबेस के स्थान और एन्कोडिंग को सही ढंग से सेटअप करना अत्यंत महत्वपूर्ण है। इसे बनाए गए चरण में देखें और आपको इसका बहुत पछतावा होगा, क्योंकि आपका ऐप/डीबी i18n, l10n क्षेत्रों में चला जाता है। अगली युक्ति यह बताती है कि यह कैसे करना है।
टिप 6
आपको आधिकारिक दस्तावेज़ पढ़ना चाहिए और अपनी COLLATE और CTYPE (createdb --locale=) सेटिंग्स (सॉर्ट ऑर्डर और कैरेक्टर वर्गीकरण के लिए जिम्मेदार) के साथ-साथ चारसेट (createdb --encoding=) सेटिंग पर निर्णय लेना चाहिए। UTF8 को एन्कोडिंग के रूप में निर्दिष्ट करने से आपका डेटाबेस बहु-भाषा पाठ संग्रहीत करने में सक्षम हो जाएगा।
आज श्वेतपत्र डाउनलोड करें क्लस्टर नियंत्रण के साथ पोस्टग्रेएसक्यूएल प्रबंधन और स्वचालन इस बारे में जानें कि पोस्टग्रेएसक्यूएल को तैनात करने, निगरानी करने, प्रबंधित करने और स्केल करने के लिए आपको क्या जानना चाहिए। श्वेतपत्र डाउनलोड करेंPostgreSQL उच्च उपलब्धता
PostgreSQL 9.0 के बाद से, जब स्ट्रीमिंग प्रतिकृति एक मानक विशेषता बन गई, तो एक या अधिक रीड ओनली हॉट स्टैंडबाय होना संभव हो गया, इस प्रकार किसी भी उपलब्ध दास को केवल-पढ़ने के लिए ट्रैफ़िक को निर्देशित करने की संभावना को सक्षम किया गया। मल्टीमास्टर प्रतिकृति के लिए नई योजनाएं मौजूद हैं लेकिन इस लेखन के समय (10.3) केवल एक ही पढ़ने-लिखने वाले मास्टर का होना संभव है, कम से कम आधिकारिक ओपन सोर्स उत्पाद में। अगले टिप के लिए जो वास्तव में इसी से संबंधित है।
टिप 7
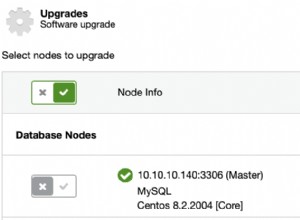
हम टिप 3 में बनाए गए हमारे ClusterControl PGSQL_CLUSTER का उपयोग करेंगे। पहले हम एक दूसरी मशीन बनाते हैं जो हमारे रीड ओनली स्लेव (पोस्टग्रेएसक्यूएल शब्दावली में हॉट स्टैंडबाय) के रूप में कार्य करेगी। फिर हम Add प्रतिकृति स्लेव पर क्लिक करते हैं, और हमारे मास्टर और नए दास का चयन करते हैं। कार्य समाप्त होने के बाद आपको यह आउटपुट देखना चाहिए:
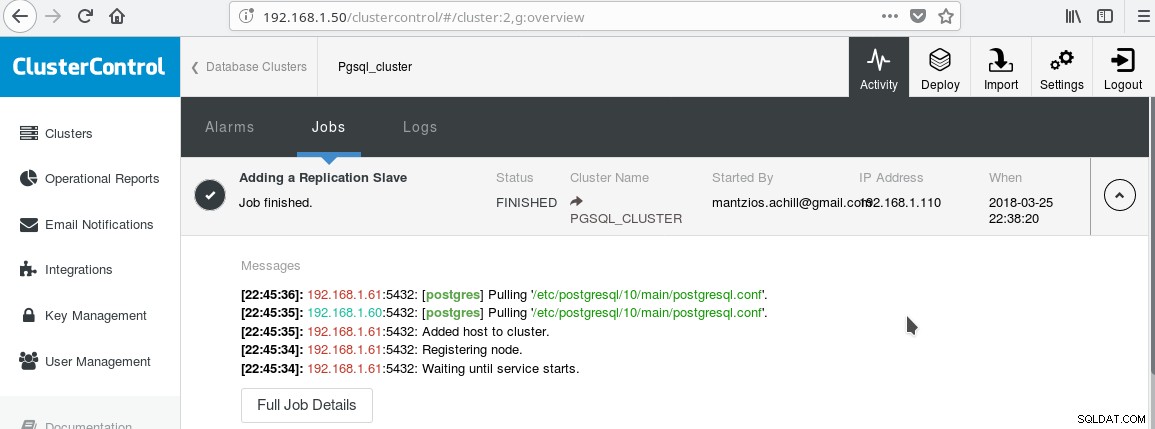
और क्लस्टर अब इस तरह दिखना चाहिए:
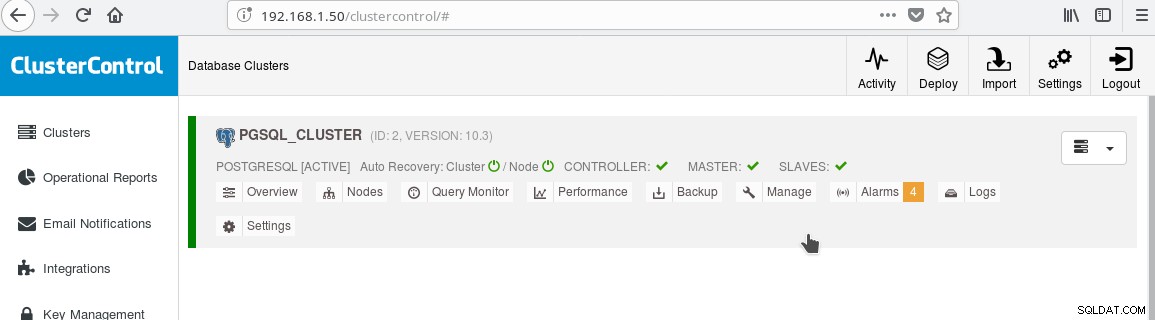
"मास्टर" के बगल में "दास" लेबल पर हरे "चिह्नित" आइकन पर ध्यान दें। आप यह सत्यापित कर सकते हैं कि स्ट्रीमिंग प्रतिकृति काम करती है, डेटाबेस ऑब्जेक्ट (डेटाबेस, टेबल, आदि) बनाकर या मास्टर पर एक टेबल में कुछ पंक्तियों को सम्मिलित करके और स्टैंडबाय पर परिवर्तन देखें।
केवल-पढ़ने के लिए स्टैंडबाय की उपस्थिति हमें उपलब्ध दो सर्वरों, मास्टर और स्लेव के बीच केवल-चयन क्वेरी करने वाले ग्राहकों के लिए लोड संतुलन करने में सक्षम बनाती है। यह हमें टिप 8 पर ले जाता है।
टिप 8
आप HAProxy का उपयोग करके दो सर्वरों के बीच लोड संतुलन को सक्षम कर सकते हैं। ClusterControl के साथ यह करना काफी आसान है। आप मैनेज करने के लिए क्लिक करें-> लोड बैलेंसर। अपना HAProxy सर्वर चुनने के बाद, ClusterControl आपके लिए सब कुछ स्थापित करेगा:आपके द्वारा निर्दिष्ट सभी उदाहरणों पर xinetd और आपके HAProxy नामित सर्वर पर HAProxy। कार्य सफलतापूर्वक पूरा होने के बाद आपको यह देखना चाहिए:
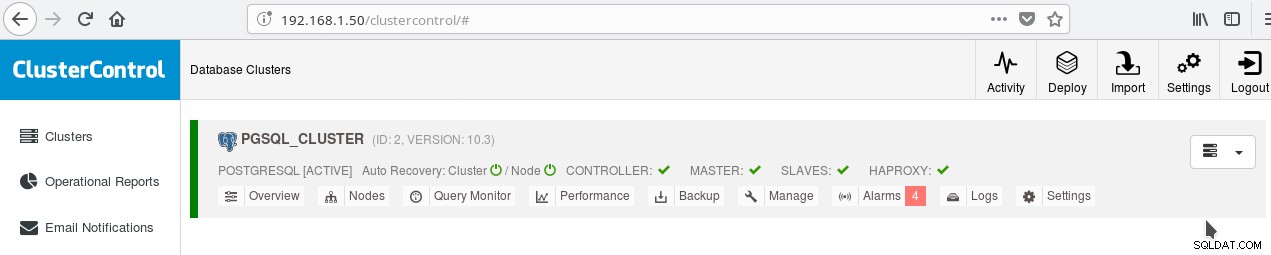
SLAVES के आगे HAPROXY हरी टिक पर ध्यान दें। अब आप परीक्षण कर सकते हैं कि HAProxy काम करता है:
example@sqldat.com:~$ psql -h localhost -p 5434
psql (10.3 (Debian 10.3-1.pgdg90+1))
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.61
(1 row)
--
-- HERE STOP PGSQL SERVER AT 192.168.1.61
--
postgres=# select inet_server_addr();
FATAL: terminating connection due to administrator command
SSL connection has been closed unexpectedly
The connection to the server was lost. Attempting reset: Succeeded.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.60
(1 row)
postgres=#टिप 9
HA और लोड संतुलन के लिए कॉन्फ़िगर करने के अलावा, PostgreSQL सर्वर के सामने किसी प्रकार का कनेक्शन पूल होना हमेशा फायदेमंद होता है। Pgpool और Pgbouncer PostgreSQL समुदाय से आने वाली दो परियोजनाएँ हैं। कई एंटरप्राइज़ एप्लिकेशन सर्वर अपने स्वयं के पूल भी प्रदान करते हैं। Pgbouncer अपनी सादगी, गति और "लेन-देन पूलिंग" सुविधा के कारण बहुत लोकप्रिय रहा है, जिसके द्वारा, लेन-देन समाप्त होने के बाद सर्वर से कनेक्शन मुक्त हो जाता है, जिससे बाद के लेनदेन के लिए इसे पुन:प्रयोज्य बना दिया जाता है जो एक ही सत्र या एक अलग से आ सकता है। . लेन-देन पूलिंग सेटिंग कुछ सत्र पूलिंग सुविधाओं को तोड़ती है, लेकिन सामान्य तौर पर "लेन-देन पूलिंग" में रूपांतरण -रेडी सेटअप आसान होता है और सामान्य मामले में विपक्ष इतना महत्वपूर्ण नहीं होता है। ऐप सर्वर के पूल को सेमी-पर्सिस्टेंट कनेक्शन के साथ कॉन्फ़िगर करने के लिए एक सामान्य सेटअप है:लंबे निष्क्रिय टाइमआउट के साथ प्रति उपयोगकर्ता या प्रति ऐप (जो pgbouncer से कनेक्ट होता है) कनेक्शन का एक बड़ा पूल। इस तरह ऐप से कनेक्शन का समय न्यूनतम है जबकि pgbouncer सर्वर से कनेक्शन को यथासंभव कम रखने में मदद करेगा।
एक बार जब आप PostgreSQL के साथ लाइव हो जाते हैं तो एक बात जो शायद सबसे अधिक चिंता का विषय होगी, वह है धीमे प्रश्नों को समझना और ठीक करना। पिछले ब्लॉग में हमने जिन निगरानी उपकरणों का उल्लेख किया है जैसे pg_stat_statements और साथ ही ClusterControl जैसे टूल की स्क्रीन धीमी क्वेरी को ठीक करने के लिए आपको पहचानने और संभवतः सुझाव देने में मदद करेगी। हालाँकि एक बार जब आप धीमी क्वेरी की पहचान कर लेते हैं, तो आपको क्वेरी योजना में शामिल लागतों और समय को ठीक से देखने के लिए EXPLAIN या EXPLAIN ANALYZE चलाने की आवश्यकता होगी। अगला टिप ऐसा करने के लिए एक बहुत ही उपयोगी टूल के बारे में है।
टिप 10
आपको अपने डेटाबेस पर अपना EXPLAIN ANALYZE चलाना होगा, और फिर आउटपुट को कॉपी करना होगा और इसे depesz's व्याख्या विश्लेषण ऑनलाइन टूल पर पेस्ट करना होगा और सबमिट पर क्लिक करना होगा। फिर आपको तीन टैब दिखाई देंगे:HTML, TEXT और STATS। HTML में योजना में प्रत्येक नोड के लिए लागत, समय और लूप की संख्या होती है। STATS टैब प्रति नोड प्रकार के आँकड़े दिखाता है। आपको "क्वेरी का%" कॉलम देखना चाहिए, ताकि आप जान सकें कि आपकी क्वेरी में वास्तव में कहां कमी है।
जैसे-जैसे आप PostgreSQL से और अधिक परिचित होते जाएंगे, आपको अपने आप और भी कई टिप्स मिलेंगे!