परिचय
आजकल, कई प्रणालियों के लिए उच्च उपलब्धता एक आवश्यकता है, चाहे आप किसी भी तकनीक का उपयोग कर रहे हों। यह डेटाबेस के लिए विशेष रूप से महत्वपूर्ण है, क्योंकि वे डेटा संग्रहीत करते हैं जो महत्वपूर्ण एप्लिकेशन और सिस्टम पर निर्भर करते हैं। उच्च उपलब्धता प्राप्त करने के लिए सबसे आम रणनीति प्रतिकृति है। उदाहरण के लिए, जब कोई प्राथमिक सर्वर प्रत्युत्तर देना बंद कर देता है, तो एकाधिक सर्वरों और फ़ेलओवर ट्रैफ़िक में डेटा को दोहराने के अलग-अलग तरीके हैं।
PostgreSQL के लिए उच्च उपलब्धता आर्किटेक्चर
पोस्टग्रेएसक्यूएल में उच्च उपलब्धता को लागू करने के लिए कई आर्किटेक्चर हैं, लेकिन बुनियादी प्राथमिक-स्टैंडबाय और प्राथमिक-प्राथमिक आर्किटेक्चर हैं।
प्राथमिक-स्टैंडबाय आर्किटेक्चर
प्राथमिक-स्टैंडबाय सबसे बुनियादी HA आर्किटेक्चर हो सकता है जिसे आप सेट अप कर सकते हैं और, अक्सर, लागू करने और बनाए रखने में सबसे आसान। यह एक या अधिक स्टैंडबाय सर्वर वाले एक प्राथमिक डेटाबेस पर आधारित है। ये स्टैंडबाय डेटाबेस प्राथमिक नोड के साथ सिंक्रनाइज़ (या लगभग सिंक्रनाइज़) रहेंगे, यह इस पर निर्भर करता है कि प्रतिकृति सिंक्रोनस या एसिंक्रोनस है या नहीं। यदि प्राथमिक सर्वर विफल हो जाता है, तो स्टैंडबाय सर्वर में लगभग सभी प्राथमिक सर्वर का डेटा होता है और इसे शीघ्र ही नए प्राथमिक डेटाबेस सर्वर में बदला जा सकता है।
प्रतिकृति की प्रकृति के आधार पर आप दो प्रकार के स्टैंडबाय डेटाबेस लागू कर सकते हैं:
- लॉजिकल स्टैंडबाय - प्राथमिक और स्टैंडबाय के बीच प्रतिकृति SQL कथनों के माध्यम से की जाती है।
- भौतिक स्टैंडबाय - प्राथमिक और स्टैंडबाय के बीच प्रतिकृति आंतरिक डेटा संरचना संशोधनों के माध्यम से बनाई जाती है।
PostgreSQL के मामले में, स्टैंडबाय डेटाबेस को सिंक्रोनाइज़ करने के लिए राइट-फ़ॉरवर्ड लॉग (WAL) रिकॉर्ड की एक स्ट्रीम का उपयोग किया जाता है। यह सिंक्रोनस या एसिंक्रोनस हो सकता है, और पूरे डेटाबेस सर्वर को दोहराया जाता है।
संस्करण 10 से, PostgreSQL में तार्किक प्रतिकृति सेट करने के लिए एक अंतर्निहित विकल्प शामिल है, जो आगे लिखने वाले लॉग में जानकारी से तार्किक डेटा संशोधनों की एक धारा का निर्माण करता है। यह प्रतिकृति विधि प्राथमिक सर्वर को निर्दिष्ट करने की आवश्यकता के बिना अलग-अलग तालिकाओं से डेटा परिवर्तनों को दोहराने की अनुमति देती है। यह डेटा को कई दिशाओं में प्रवाहित करने की अनुमति भी देता है।
दुर्भाग्य से, प्राथमिक-स्टैंडबाय सेटअप प्रभावी रूप से उच्च उपलब्धता सुनिश्चित करने के लिए पर्याप्त नहीं है, क्योंकि आपको विफलताओं को संभालने की भी आवश्यकता होती है। विफलताओं को संभालने के लिए, आपको उनका पता लगाने में सक्षम होना चाहिए। एक बार जब आप जानते हैं कि एक विफलता है, उदाहरण के लिए, प्राथमिक नोड पर त्रुटियां या नोड प्रतिक्रिया नहीं दे रहा है, तो आप विफल नोड को कम से कम देरी से बदलने के लिए एक स्टैंडबाय नोड का चयन कर सकते हैं। अनुप्रयोगों के लिए पूर्ण कार्यक्षमता को पुनर्स्थापित करने के लिए यह प्रक्रिया यथासंभव कुशल होनी चाहिए। PostgreSQL में स्वयं एक स्वचालित विफलता तंत्र शामिल नहीं है, इसलिए इस स्वचालन के लिए कुछ कस्टम स्क्रिप्ट या तृतीय-पक्ष टूल की आवश्यकता होगी।
एक विफलता होने के बाद, नए प्राथमिक का उपयोग शुरू करने के लिए आपके आवेदन को तदनुसार अधिसूचित किया जाना चाहिए। विफलता के बाद आपको अपने आर्किटेक्चर की स्थिति का मूल्यांकन करने की भी आवश्यकता है क्योंकि आप ऐसी स्थिति में भाग सकते हैं जहां केवल नया प्राथमिक चल रहा है (उदाहरण के लिए, आपके पास प्राथमिक नोड था और समस्या से पहले केवल एक स्टैंडबाय था)। उस स्थिति में, आपको उच्च उपलब्धता के लिए मूल रूप से आपके पास मौजूद प्राथमिक-स्टैंडबाय सेटअप को फिर से बनाने के लिए एक स्टैंडबाय नोड जोड़ने की आवश्यकता होगी।
प्राथमिक-प्राथमिक वास्तुकला
प्राथमिक-प्राथमिक आर्किटेक्चर किसी एक नोड पर त्रुटि के प्रभाव को कम करने का एक तरीका प्रदान करता है, क्योंकि अन्य नोड सभी ट्रैफ़िक का ख्याल रख सकते हैं, केवल संभावित रूप से प्रदर्शन को थोड़ा प्रभावित कर सकते हैं लेकिन कार्यक्षमता कभी नहीं खोना। प्राथमिक-प्राथमिक वास्तुकला का उपयोग अक्सर उच्च उपलब्धता वातावरण बनाने और क्षैतिज रूप से स्केलिंग के दोहरे उद्देश्य के साथ किया जाता है (जैसा कि ऊर्ध्वाधर स्केलेबिलिटी की अवधारणा की तुलना में जहां आप सर्वर में अधिक संसाधन जोड़ते हैं)।
PostgreSQL अभी तक "मूल रूप से" इस आर्किटेक्चर का समर्थन नहीं करता है, इसलिए आपको तृतीय-पक्ष टूल और कार्यान्वयन का उल्लेख करना होगा। समाधान चुनते समय, आपको यह ध्यान रखना चाहिए कि बहुत सारी परियोजनाएं/उपकरण हैं, लेकिन उनमें से कुछ अब समर्थित नहीं हैं, जबकि अन्य नए हैं और उत्पादन में युद्ध-परीक्षण नहीं हो सकते हैं।
लोड संतुलन
लोड बैलेंसर ऐसे टूल हैं जिनका उपयोग आपके एप्लिकेशन से ट्रैफ़िक को प्रबंधित करने के लिए किया जा सकता है ताकि आपके डेटाबेस आर्किटेक्चर का अधिकतम लाभ उठाया जा सके।
न केवल ये उपकरण आपके डेटाबेस के भार को संतुलित करने में सहायक हैं, बल्कि ये एप्लिकेशन को उपलब्ध/स्वस्थ नोड्स पर पुनर्निर्देशित करने और यहां तक कि विभिन्न भूमिकाओं वाले पोर्ट निर्दिष्ट करने में भी मदद करते हैं।
HAProxy एक लोड बैलेंसर है जो एक मूल से एक या अधिक गंतव्यों तक ट्रैफ़िक वितरित करता है और इस कार्य के लिए विशिष्ट नियमों और/या प्रोटोकॉल को परिभाषित कर सकता है। यदि कोई भी गंतव्य प्रतिसाद देना बंद कर देता है, तो उन्हें ऑफ़लाइन के रूप में चिह्नित कर दिया जाता है, और ट्रैफ़िक को शेष उपलब्ध गंतव्यों पर भेज दिया जाता है।
Kepalived एक ऐसी सेवा है जो आपको सर्वर के एक सक्रिय/निष्क्रिय समूह के भीतर एक वर्चुअल IP पता कॉन्फ़िगर करने की अनुमति देती है। यह वर्चुअल आईपी एड्रेस एक सक्रिय सर्वर को सौंपा गया है। यदि यह सर्वर विफल हो जाता है, तो IP पता स्वचालित रूप से "माध्यमिक" निष्क्रिय सर्वर में माइग्रेट हो जाता है, जिससे यह सिस्टम के लिए पारदर्शी तरीके से समान IP पते के साथ काम करना जारी रखता है।
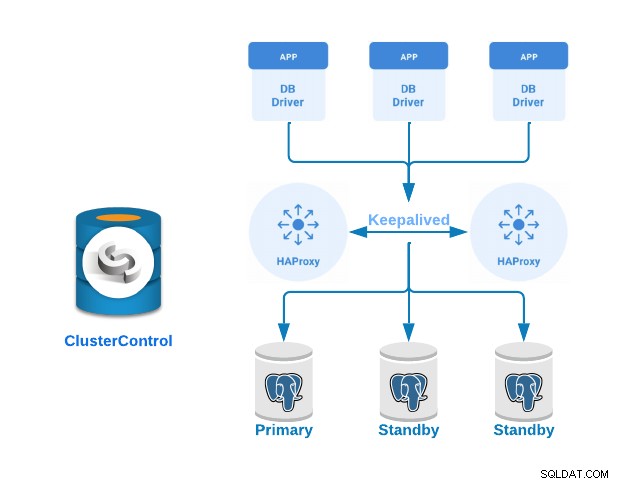
अब देखते हैं कि लोड बैलेंसर सर्वर के साथ प्राइमरी-स्टैंडबाय पोस्टग्रेएसक्यूएल क्लस्टर को कैसे कार्यान्वित किया जाए और उनके बीच कॉन्फ़िगर किया जाए। हम इसे ClusterControl के उपयोग में आसान इंटरफ़ेस का उपयोग करके प्रदर्शित करेंगे।
इस उदाहरण के लिए, हम बनाएंगे:
- 3 PostgreSQL सर्वर (एक प्राथमिक और दो स्टैंडबाय)।
- 2 HAProxy लोड बैलेंसर।
- लोड बैलेंसर सर्वर के बीच कॉन्फ़िगर किया गया।
डेटाबेस परिनियोजन
ClusterControl का उपयोग करके डेटाबेस को परिनियोजित करने के लिए, बस "तैनाती" विकल्प चुनें और दिखाई देने वाले निर्देशों का पालन करें।
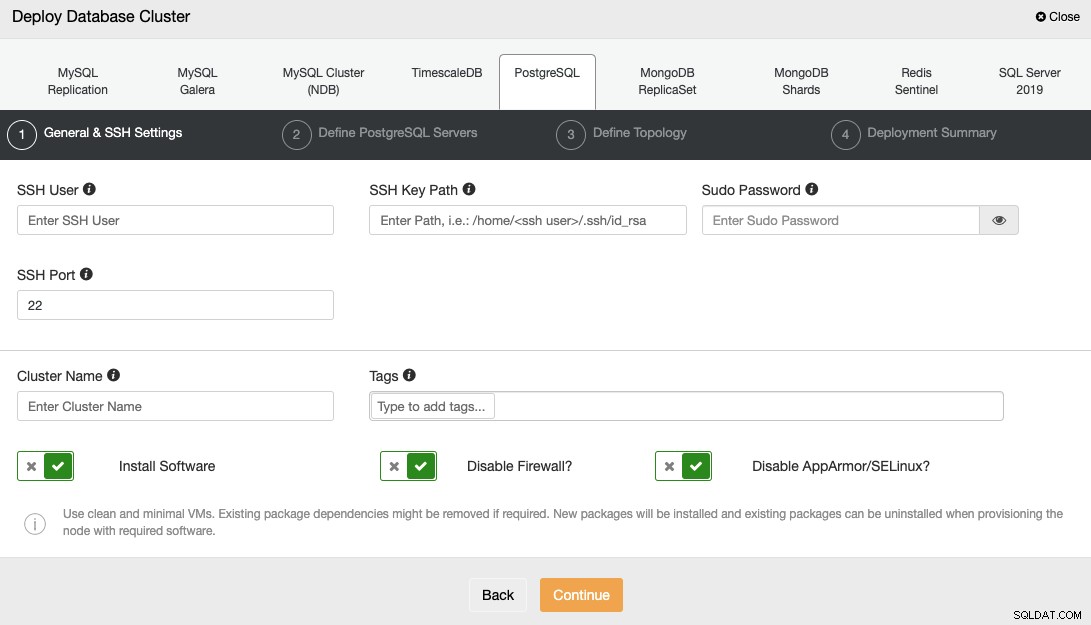
PostgreSQL का चयन करते समय, आपको उपयोगकर्ता, कुंजी या पासवर्ड निर्दिष्ट करना होगा, और SSH द्वारा आपके सर्वर से कनेक्ट करने के लिए पोर्ट। आपको अपने नए क्लस्टर के लिए नाम की भी आवश्यकता है और चुनें कि क्या आप चाहते हैं कि ClusterControl आपके लिए संबंधित सॉफ़्टवेयर और कॉन्फ़िगरेशन स्थापित करे।
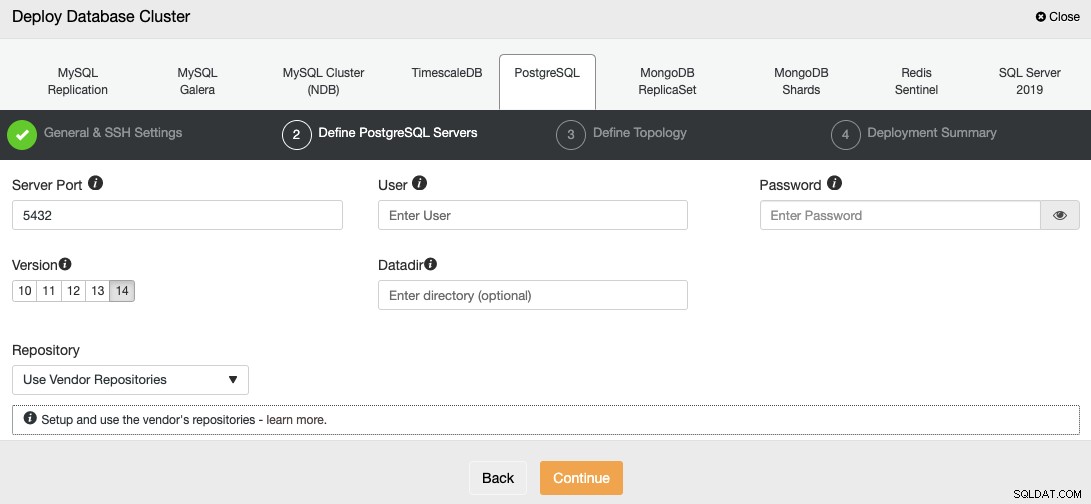
SSH एक्सेस जानकारी सेट करने के बाद, आपको डेटाबेस उपयोगकर्ता को परिभाषित करना होगा, संस्करण, और डेटादिर (वैकल्पिक)। आप यह भी निर्दिष्ट कर सकते हैं कि किस भंडार का उपयोग करना है; आधिकारिक विक्रेता भंडार डिफ़ॉल्ट रूप से उपयोग किया जाएगा।
अगले चरण में, आपको अपने सर्वर को उस क्लस्टर में जोड़ना होगा जो आप बनाएंगे।
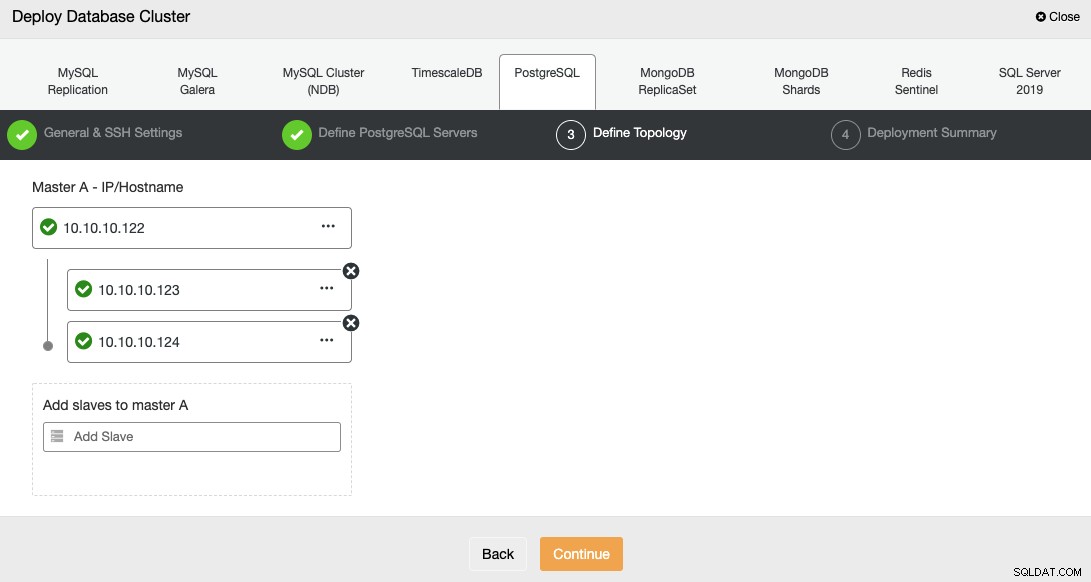
अपने सर्वर जोड़ते समय, आप IP या होस्टनाम दर्ज कर सकते हैं।
आखिरी चरण में, आप चुन सकते हैं कि आपकी प्रतिकृति सिंक्रोनस या एसिंक्रोनस होगी या नहीं।
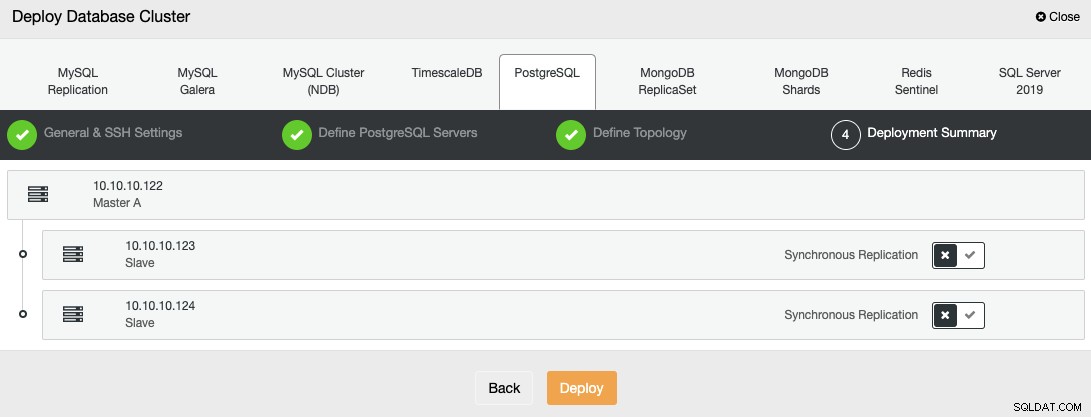
आप ClusterControl से अपने नए क्लस्टर के निर्माण की स्थिति की निगरानी कर सकते हैं गतिविधि मॉनिटर।
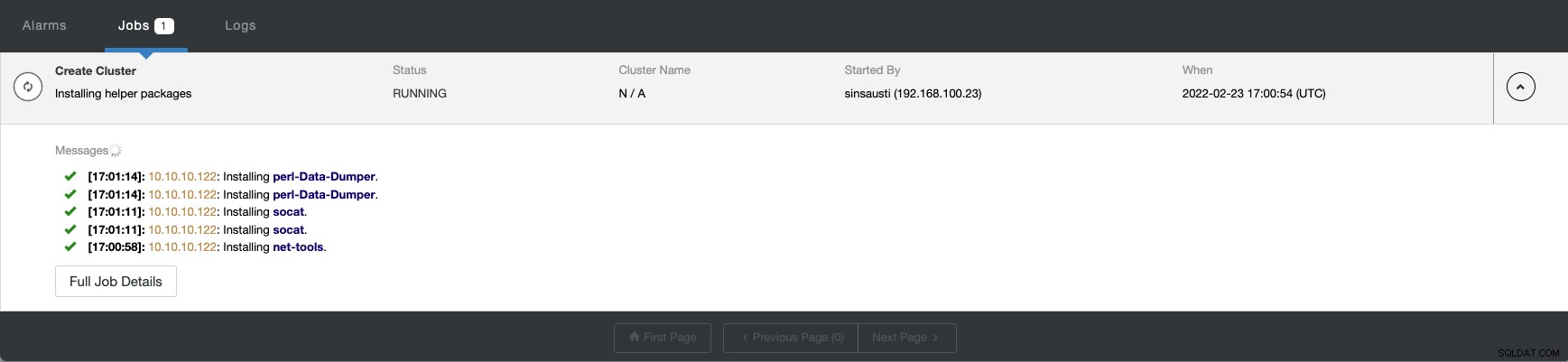
कार्य समाप्त होने के बाद, आप अपने क्लस्टर को मुख्य ClusterControl में देख सकते हैं स्क्रीन।
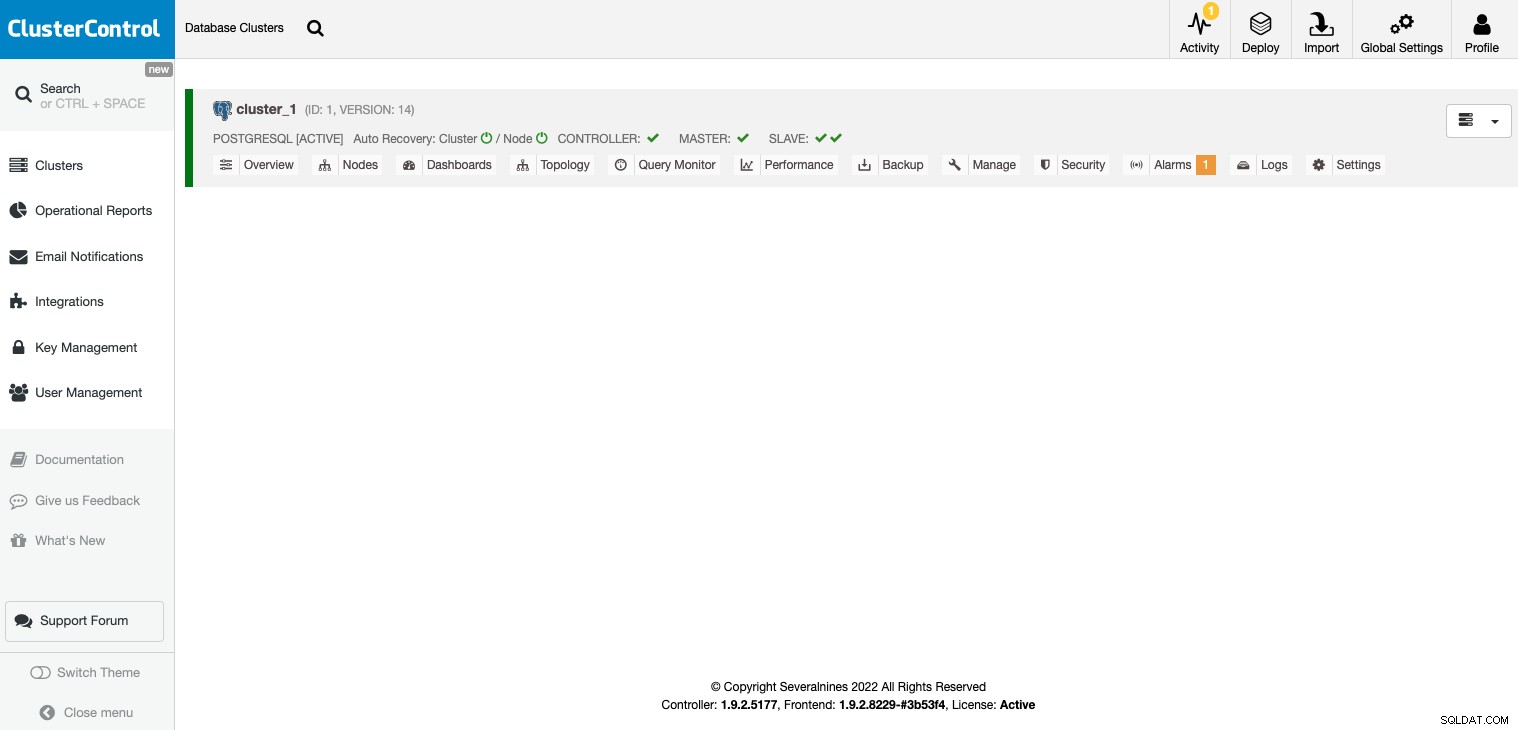
एक बार आपका क्लस्टर बन जाने के बाद, आप कई कार्य कर सकते हैं, जैसे लोड बैलेंसर (HAProxy) या एक नई प्रतिकृति।
बैलेंसर परिनियोजन लोड करें
लोड बैलेंसर परिनियोजन करने के लिए, क्लस्टर क्रियाओं में "लोड बैलेंसर जोड़ें" विकल्प चुनें और अनुरोधित जानकारी भरें।
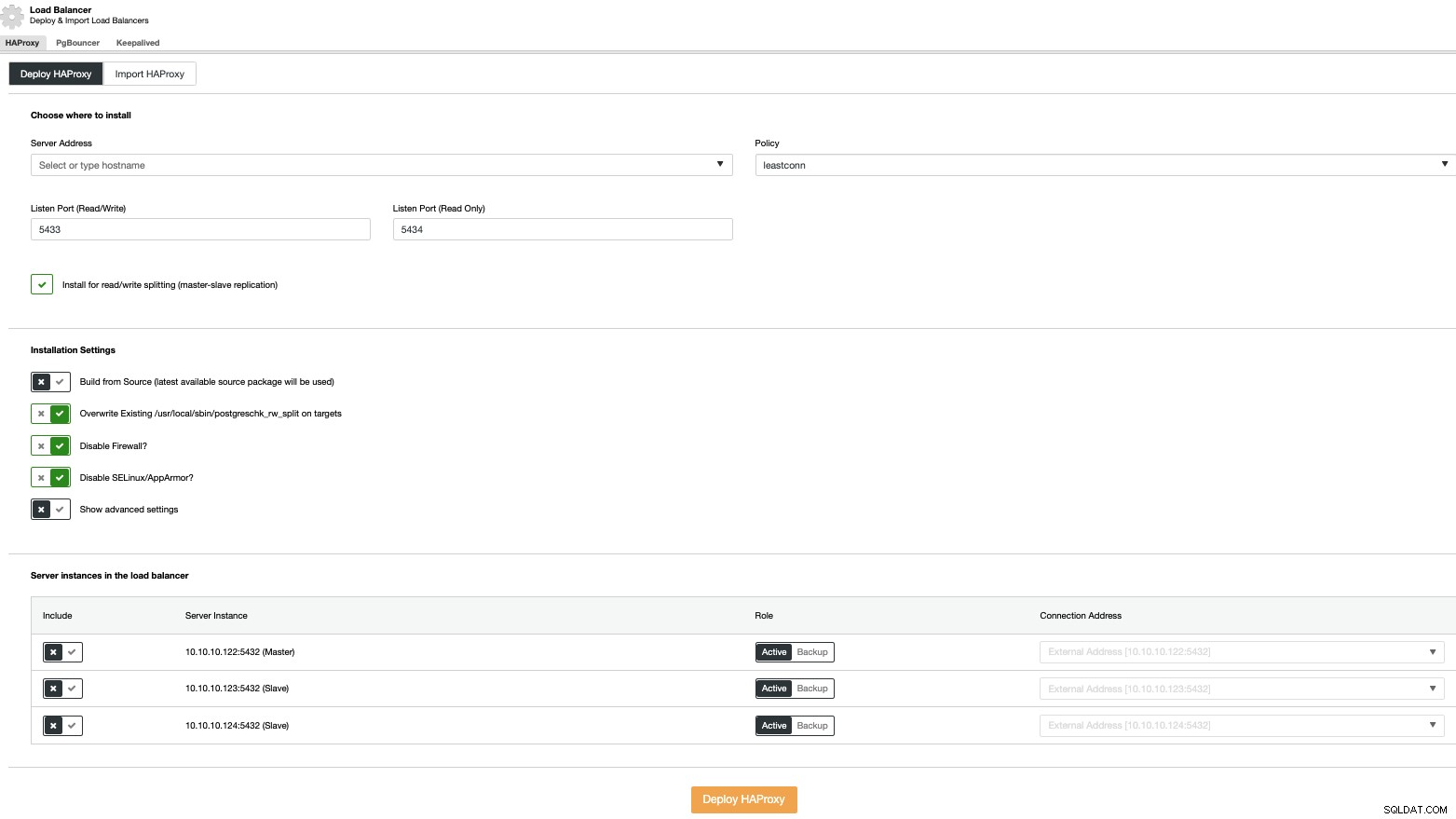
आपको केवल IP पता या होस्टनाम, पोर्ट, नीति जोड़ने की आवश्यकता है, और जिन नोड्स को आप अपने लोड बैलेंसर्स में कॉन्फ़िगर करेंगे।
परिनियोजन बनाए रखा
एक जीवित परिनियोजन करने के लिए, क्लस्टर का चयन करें, "प्रबंधित करें" मेनू पर जाएं और "बैलेंसर लोड करें" अनुभाग पर जाएं, और फिर "रख-रखाव" विकल्प चुनें।
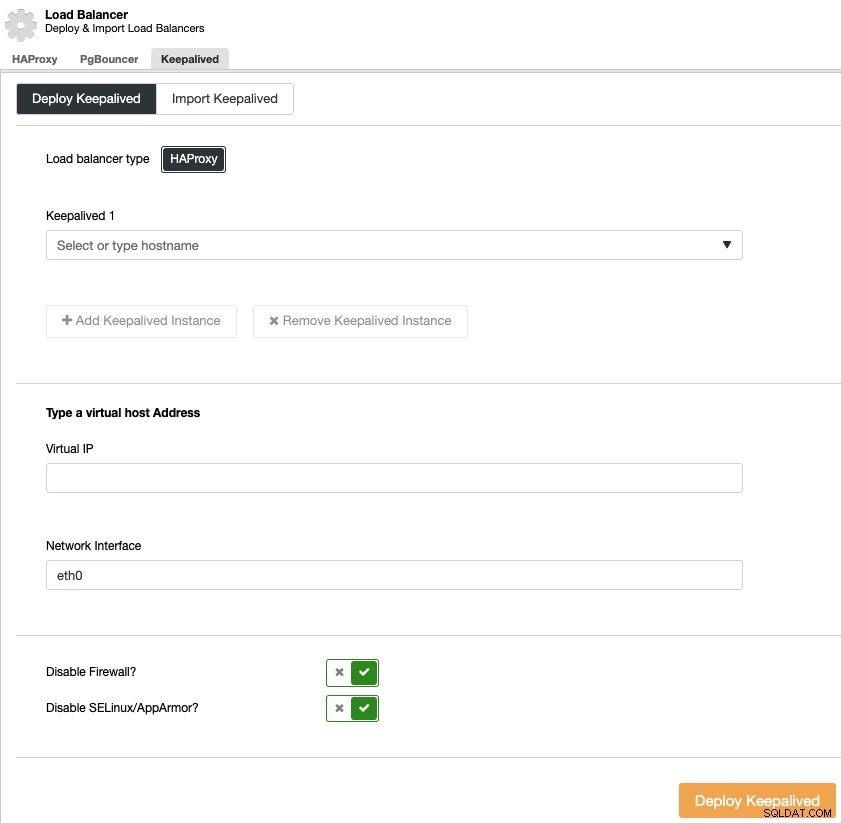
आपको अपने हाई के लिए लोड बैलेंसर सर्वर और वर्चुअल आईपी एड्रेस का चयन करना होगा। उपलब्धता वातावरण।
Kepalived वर्चुअल आईपी पते का उपयोग करता है और विफलता की स्थिति में इसे एक लोड बैलेंसर से दूसरे में माइग्रेट करता है, ताकि आपके सिस्टम सामान्य रूप से कार्य करना जारी रख सकें।
यदि आपने पिछले चरणों का पालन किया है, तो आपके पास निम्न टोपोलॉजी होनी चाहिए:
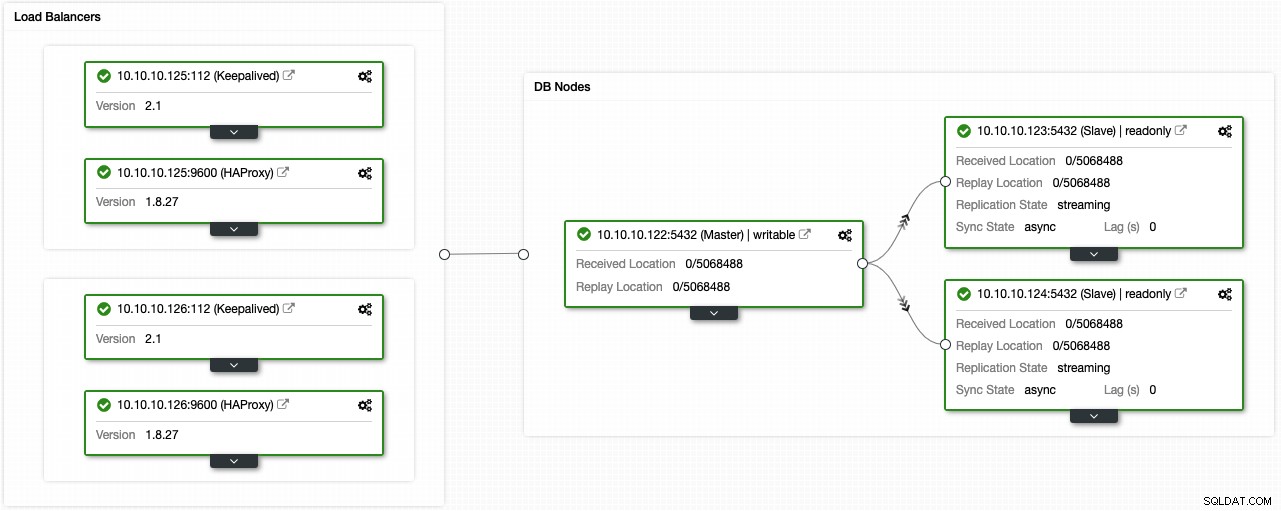
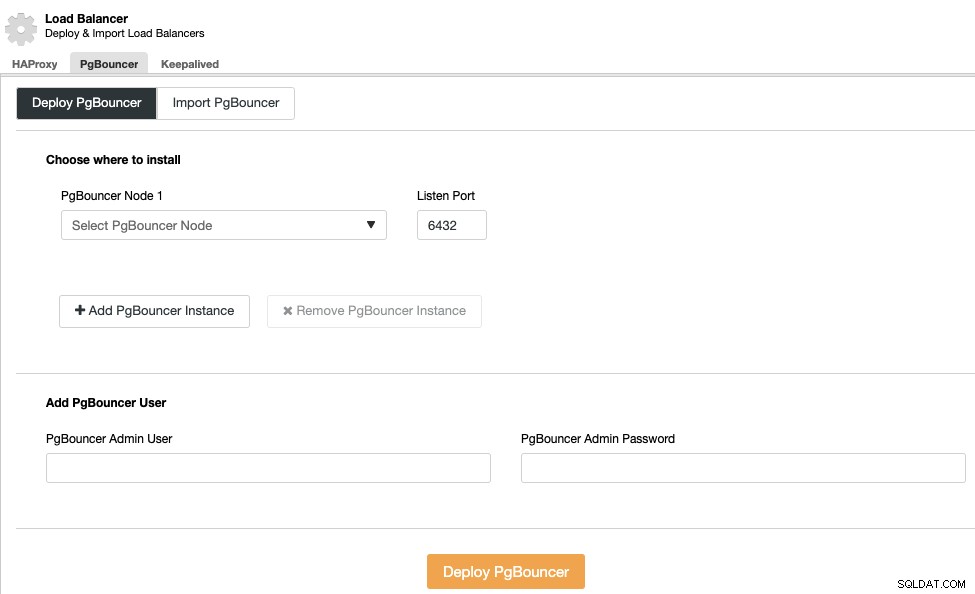
आप PgBouncer जैसे कनेक्शन पूलर को जोड़कर इस उच्च उपलब्धता वातावरण को बेहतर बना सकते हैं। यह जरूरी नहीं है, लेकिन विफलता के मामले में प्रदर्शन को बेहतर बनाने और सक्रिय कनेक्शन को संभालने में मददगार हो सकता है, और सबसे अच्छी बात यह है कि आप इसे ClusterControl का उपयोग करके भी तैनात कर सकते हैं।
ClusterControl विफलता
मान लें कि आपके ClusterControl सर्वर में "स्वतः पुनर्प्राप्ति" विकल्प चालू है। प्राथमिक विफलता के मामले में, ClusterControl सबसे उन्नत स्टैंडबाय (यदि यह काली सूची में नहीं है) को प्राथमिक में बढ़ावा देगा, साथ ही आपको समस्या के बारे में सूचित करेगा। यह नए प्राथमिक से दोहराने के लिए बाकी स्टैंडबाय नोड्स को भी विफल कर देगा।
HAProxy डिफ़ॉल्ट रूप से दो अलग-अलग पोर्ट के साथ कॉन्फ़िगर किया गया है; रीड-राइट और रीड ओनली पोर्ट।
आपके पठन-लेखन पोर्ट में, आपके पास आपका प्राथमिक सर्वर ऑनलाइन है और आपके बाकी नोड ऑफ़लाइन हैं, और केवल-पढ़ने के लिए पोर्ट में, आपके पास प्राथमिक और स्टैंडबाय दोनों ऑनलाइन हैं।
जब HAProxy को पता चलता है कि आपका कोई नोड, प्राथमिक या स्टैंडबाय, पहुंच योग्य नहीं है, तो यह स्वचालित रूप से इसे ऑफ़लाइन के रूप में चिह्नित कर देता है। इसे ट्रैफिक भेजने के लिए इसे ध्यान में नहीं रखा जाता है। जांच स्वास्थ्य जांच स्क्रिप्ट द्वारा की जाती है जिसे ClusterControl परिनियोजन के समय कॉन्फ़िगर करता है। ये जाँचते हैं कि क्या इंस्टेंस ऊपर हैं, क्या वे ठीक हो रहे हैं, या केवल-पढ़ने के लिए हैं।
जब ClusterControl एक स्टैंडबाय को प्राथमिक में बढ़ावा देता है, तो आपका HAProxy पुराने प्राथमिक को दोनों पोर्ट के लिए ऑफ़लाइन के रूप में चिह्नित करता है और प्रचारित नोड को रीड-राइट पोर्ट में ऑनलाइन रखता है।
यदि आपका सक्रिय HAProxy, जिसने आपके सिस्टम से कनेक्ट होने वाला वर्चुअल IP पता निर्दिष्ट किया है, विफल हो जाता है, तो Keepalived इस IP पते को आपके निष्क्रिय HAProxy में स्वचालित रूप से माइग्रेट कर देता है। इसका मतलब है कि आपका सिस्टम तब सामान्य रूप से कार्य करना जारी रखने में सक्षम है।
इस तरह, आपके सिस्टम अपेक्षित रूप से और आपके मैन्युअल हस्तक्षेप के बिना काम करना जारी रखते हैं।
विचारों
यदि आप अपने पुराने विफल प्राथमिक नोड को पुनर्प्राप्त करने का प्रबंधन करते हैं, तो इसे डिफ़ॉल्ट रूप से क्लस्टर में स्वचालित रूप से पुन:पेश नहीं किया जाएगा। आपको इसे मैन्युअल रूप से करने की आवश्यकता है। इसका एक कारण यह है कि यदि विफलता के समय आपकी प्रतिकृति में देरी हुई थी, और ClusterControl पुराने प्राथमिक को क्लस्टर में जोड़ता है, तो इसका मतलब होगा कि सभी नोड्स में जानकारी या डेटा असंगति का नुकसान होगा। आप इस मुद्दे का विस्तार से विश्लेषण करना भी चाह सकते हैं। यदि ClusterControl ने अभी-अभी विफल नोड को क्लस्टर में फिर से पेश किया है, तो संभवतः आप नैदानिक जानकारी खो देंगे।
इसके अलावा, यदि विफलता विफल हो जाती है, तो आगे कोई प्रयास नहीं किया जाता है। समस्या का विश्लेषण करने और संबंधित कार्यों को करने के लिए मैन्युअल हस्तक्षेप की आवश्यकता होती है। यह उस स्थिति से बचने के लिए है जहां ClusterControl, उच्च उपलब्धता प्रबंधक के रूप में, अगले स्टैंडबाय और अगले को बढ़ावा देने का प्रयास करता है। कोई समस्या हो सकती है, और आपको इसकी जांच करनी होगी।
सुरक्षा
एक महत्वपूर्ण बात जिसे आप अपने उच्च उपलब्धता वातावरण के साथ उत्पादन में जाने से पहले नहीं भूल सकते, वह है इसकी सुरक्षा सुनिश्चित करना।
कई सुरक्षा पहलुओं पर विचार करने के लिए एन्क्रिप्शन, भूमिका प्रबंधन, और आईपी पते द्वारा पहुंच प्रतिबंध शामिल हैं, जिन्हें हमने पिछले ब्लॉग में गहराई से कवर किया है।
आपके PostgreSQL डेटाबेस में, आपके पास pg_hba.conf फ़ाइल है, जो क्लाइंट प्रमाणीकरण को संभालती है। आप कनेक्शन के प्रकार, स्रोत आईपी पते या नेटवर्क को सीमित कर सकते हैं कि आप किस डेटाबेस से जुड़ सकते हैं और किन उपयोगकर्ताओं के साथ। इसलिए, यह फ़ाइल PostgreSQL सुरक्षा के लिए एक महत्वपूर्ण हिस्सा है।
आप अपने PostgreSQL डेटाबेस को postgresql.conf फ़ाइल से कॉन्फ़िगर कर सकते हैं, इसलिए यह केवल एक विशिष्ट नेटवर्क इंटरफ़ेस और डिफ़ॉल्ट एक (5432) की तुलना में एक अलग पोर्ट पर सुनता है, इस प्रकार अवांछित स्रोतों से बुनियादी कनेक्शन प्रयासों से बचता है ।
उचित उपयोगकर्ता प्रबंधन, या तो सुरक्षित पासवर्ड का उपयोग करना या पहुंच और विशेषाधिकार सीमित करना, आपकी सुरक्षा सेटिंग्स का एक और महत्वपूर्ण हिस्सा है। यह अनुशंसा की जाती है कि आप सभी उपयोगकर्ताओं को कम से कम विशेषाधिकार प्रदान करें और यदि संभव हो तो, कनेक्शन का स्रोत निर्दिष्ट करें।
आप डेटा एन्क्रिप्शन सक्षम कर सकते हैं, या तो ट्रांज़िट में या आराम से, अनधिकृत व्यक्तियों की जानकारी तक पहुंच से बचने के लिए।
एक ऑडिट लॉग यह समझने में सहायक होता है कि आपके डेटाबेस में क्या हो रहा है या क्या हुआ है। PostgreSQL आपको लॉगिंग के लिए कई पैरामीटर कॉन्फ़िगर करने या यहां तक कि इस कार्य के लिए pgAudit एक्सटेंशन का उपयोग करने की अनुमति देता है।
आखिरी लेकिन कम से कम, सुरक्षा जोखिमों से बचने के लिए अपने डेटाबेस और सर्वर को नवीनतम पैच के साथ अद्यतित रखने की अनुशंसा की जाती है। इसके लिए, ClusterControl आपको यह सत्यापित करने के लिए कि क्या आपके पास अपडेट उपलब्ध हैं और यहां तक कि आपको अपने डेटाबेस सर्वर को अपडेट करने में भी मदद करने के लिए परिचालन रिपोर्ट तैयार करने की अनुमति देता है।
निष्कर्ष
उच्च उपलब्धता परिनियोजन प्राप्त करना कठिन लग सकता है, खासकर जब विभिन्न आर्किटेक्चर और आवश्यक घटकों को सही ढंग से कॉन्फ़िगर करने के लिए समझने की बात आती है।
यदि आप HA को मैन्युअल रूप से प्रबंधित कर रहे हैं, तो PostgreSQL के लिए प्रदर्शन प्रतिकृति टोपोलॉजी परिवर्तन देखना सुनिश्चित करें। कई लोग संपूर्ण उच्च उपलब्धता वातावरण के लिए परिनियोजन, लोड बैलेंसर, फ़ेलओवर, सुरक्षा, और बहुत कुछ प्रबंधित करने में मदद करने के लिए क्लस्टरकंट्रोल जैसे टूल की तलाश करेंगे। आप यह देखने के लिए 30 दिनों के लिए क्लस्टरकंट्रोल मुफ्त में डाउनलोड कर सकते हैं कि यह कैसे उच्च उपलब्धता डेटाबेस इन्फ्रास्ट्रक्चर के प्रबंधन के बोझ को कम कर सकता है।
हालाँकि आप अपने उच्च उपलब्धता वाले PostgreSQL डेटाबेस का प्रबंधन करना चुनते हैं, ट्विटर या लिंक्डइन पर हमारा अनुसरण करना सुनिश्चित करें, या अपने डेटाबेस सेटअप के प्रबंधन के लिए नवीनतम अपडेट और सर्वोत्तम अभ्यास प्राप्त करने के लिए हमारे न्यूज़लेटर की सदस्यता लें।



