विभिन्न सर्वरों में डेटाबेस क्लस्टर को तैनात करते समय आपने डेटा उपलब्धता में सुधार के प्रतिकृति लाभ प्राप्त किया होगा। हालांकि प्रक्रियाओं का ट्रैक रखने की जरूरत है, और देखें कि वे चल रही हैं या नहीं। इस प्रक्रिया में उपयोग किए जाने वाले कार्यक्रमों में से एक हार्टबीट है जो किसी दिए गए क्लस्टर में एक या अधिक सिस्टम पर संसाधनों की उपस्थिति की जांच और सत्यापन करने की क्षमता रखता है। PostgreSQL और फाइल सिस्टम के अलावा, जिसके लिए PostgreSQL डेटा संग्रहीत किया जाता है, DRBD उन संसाधनों में से एक है, जिन पर हम इस लेख में चर्चा करने जा रहे हैं कि हार्टबीट प्रोग्राम का उपयोग कैसे किया जा सकता है।
हा हार्टबीट
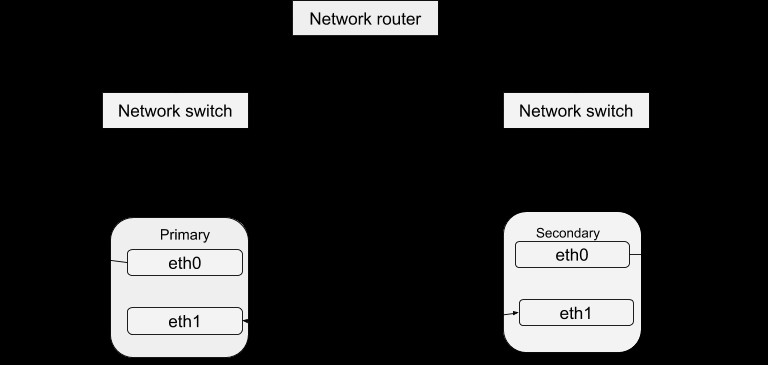
जैसा कि पहले DRBD ब्लॉग में चर्चा की गई थी, सर्वर के विभिन्न उदाहरणों को चलाकर लेकिन समान डेटा की सेवा के माध्यम से डेटा की उच्च उपलब्धता प्राप्त की जाती है। इन चल रहे सर्वर इंस्टेंस को हार्टबीट के संबंध में क्लस्टर के रूप में परिभाषित किया जा सकता है। मूल रूप से, प्रत्येक सर्वर इंस्टेंस उस क्लस्टर के भीतर अन्य लोगों के समान सेवा प्रदान करने में शारीरिक रूप से सक्षम है। हालांकि, डेटा की उच्च उपलब्धता सुनिश्चित करने के उद्देश्य से एक समय में केवल एक उदाहरण सक्रिय रूप से सेवा प्रदान कर सकता है। इसलिए हम अन्य उदाहरणों को 'हॉट-स्पेयर' के रूप में परिभाषित कर सकते हैं जिन्हें मास्टर की विफलता की स्थिति में सेवा में लाया जा सकता है। हार्टबीट पैकेज को इस लिंक से डाउनलोड किया जा सकता है। इस पैकेज को स्थापित करने के बाद, आप इसे नीचे की प्रक्रिया के साथ अपने सिस्टम के साथ काम करने के लिए कॉन्फ़िगर कर सकते हैं। हार्टबीट कॉन्फ़िगरेशन की एक सरल संरचना है:
दिल की धड़कन का विन्यास
इस निर्देशिका /etc/ha.d में देखने पर आपको कुछ फाइलें मिलेंगी जो विन्यास प्रक्रिया में उपयोग की जाती हैं। Ha.cf फ़ाइल मुख्य दिल की धड़कन कॉन्फ़िगरेशन बनाती है। इसमें दिल की धड़कन को किस प्रकार के मीडिया पथों का उपयोग करना है और उन्हें कैसे कॉन्फ़िगर करना है, को निर्देशित करने के अलावा विफलता की पहचान करने के लिए सभी नोड्स और समय की सूची शामिल है। क्लस्टर के लिए सुरक्षा जानकारी authkeys फ़ाइल में दर्ज की जाती है। इन फाइलों में दर्ज की गई जानकारी क्लस्टर में सभी मेजबानों के लिए समान होनी चाहिए और इसे सभी मेजबानों में समन्वयन के माध्यम से आसानी से प्राप्त किया जा सकता है। कहने का तात्पर्य यह है कि एक होस्ट में जानकारी के किसी भी परिवर्तन को अन्य सभी को कॉपी किया जाना चाहिए।
Ha.cf फ़ाइल
Ha.cf फ़ाइल की मूल रूपरेखा है
logfacility local0
keepalive 3
Deadtime 7
warntime 3
initdead 30
mcast eth0 225.0.0.1 694 2 0
mcast eth1 225.0.0.2 694 1 0
auto_failback off
node drbd1
node drbd2
node drbd3-
लॉग फैसिलिटी:इसका उपयोग हार्टबीट को निर्देशित करने के लिए किया जाता है जिस पर संदेशों को रिकॉर्ड करने के लिए syslog लॉगिंग सुविधा का उपयोग करना चाहिए। सबसे अधिक इस्तेमाल किया जाने वाला मान ऑथ, ऑथप्रिव, यूजर, लोकल0, सिसलॉग और डेमन हैं। आप यह भी तय कर सकते हैं कि कोई लॉग न हो ताकि आप मान को कोई नहीं पर सेट कर सकें। यानी
logfacility none - Kepalive:यह दिल की धड़कन के बीच का समय है, यानी वह आवृत्ति जिसके साथ दिल की धड़कन का संकेत अन्य मेजबानों को भेजा जाता है। उपरोक्त नमूना कोड में इसे 3 सेकंड पर सेट किया गया है।
- डेडटाइम:यह सेकंड में देरी है जिसके बाद एक नोड के विफल होने का उच्चारण किया जाता है।
- चेतावनी:सेकंड में देरी है जिसके बाद एक लॉग में एक चेतावनी रिकॉर्ड की जाती है जो दर्शाती है कि नोड से अब संपर्क नहीं किया जा सकता है।
- Initdead:यह सिस्टम स्टार्टअप के दौरान सेकंड में प्रतीक्षा करने का समय है, इससे पहले कि दूसरे होस्ट को डाउन माना जाए।
- Mcast:यह दिल की धड़कन के संकेत भेजने के लिए एक परिभाषित विधि प्रक्रिया है। उपरोक्त नमूना कोड के लिए, मल्टीकास्ट नेटवर्क पते का उपयोग बाउंडेड नेटवर्क डिवाइस पर किया जा रहा है। एक से अधिक क्लस्टर के लिए, प्रत्येक क्लस्टर के लिए मल्टीकास्ट पता अद्वितीय होना चाहिए। आप मल्टीकास्ट पर एक सीरियल कनेक्शन भी चुन सकते हैं या यदि आप सेट अप इस तरह से हैं कि कई नेटवर्क इंटरफेस हैं, उदाहरण के लिए दोनों दिल की धड़कन कनेक्शन के लिए उपयोग करें। दोनों का उपयोग करने का लाभ क्षणिक विफलता की संभावना को दूर करना है जिसके परिणामस्वरूप एक अमान्य विफलता घटना हो सकती है।
- Auto_failback:यह एक सर्वर को फिर से जोड़ता है जो क्लस्टर में वापस विफल हो गया था यदि यह उपलब्ध हो जाता है। हालाँकि, यह एक भ्रम पैदा कर सकता है यदि सर्वर चालू है और फिर एक अलग समय पर ऑनलाइन आता है। DRBD के संबंध में, यदि यह अच्छी तरह से कॉन्फ़िगर नहीं है, तो आप एक ही सर्वर में एक से अधिक डेटा सेट के साथ समाप्त हो सकते हैं। इसलिए, इसे हमेशा बंद करने की सलाह दी जाती है।
- नोड:हार्टबीट क्लस्टर समूह के भीतर नोड की रूपरेखा। आपके पास प्रत्येक के लिए कम से कम 1 नोड होना चाहिए।
अतिरिक्त कॉन्फ़िगरेशन
आप अतिरिक्त कॉन्फ़िगरेशन जानकारी भी सेट कर सकते हैं जैसे:
ping 10.0.0.1
respawn hacluster /usr/lib64/heartbeat/ipfail
apiauth ipfail gid=haclient uid=hacluster
deadping 5- पिंग:यह सुनिश्चित करने में महत्वपूर्ण है कि आपके पास सर्वर के लिए सार्वजनिक इंटरफ़ेस पर कनेक्टिविटी है और किसी अन्य होस्ट से कनेक्शन है। गंतव्य मशीन के लिए होस्ट नाम के बजाय आईपी पते पर विचार करना महत्वपूर्ण है।
- प्रतिक्रिया:विफलता होने पर चलाने के लिए यह आदेश है।
- अपियाथ:विफलता के लिए प्राधिकरण है। आपको उपयोगकर्ता और समूह आईडी को कॉन्फ़िगर करने की आवश्यकता है जिसके साथ आदेश निष्पादित किया जाएगा। authkeys फ़ाइल हार्टबीट क्लस्टर के लिए प्राधिकरण जानकारी रखती है और यह कुंजी किसी दिए गए हार्टबीट क्लस्टर के भीतर मशीनों को सत्यापित करने के लिए बहुत ही अद्वितीय है।
- डेडपिंग:गैर-प्रतिक्रिया विफलता को ट्रिगर करने से पहले टाइमआउट को परिभाषित करता है।
पोस्टग्रेज और DRBD के साथ हार्टबीट का एकीकरण
जैसा कि पहले उल्लेख किया गया है, जब एक मास्टर सर्वर विफल हो जाता है, तो दिए गए क्लस्टर वाला दूसरा सर्वर उसी सेवा को प्रदान करने के लिए कार्रवाई में कूद जाएगा। हार्टबीट उन संसाधनों के विन्यास में मदद करता है जो विफलता की स्थिति में सर्वर के चयन को बढ़ाते हैं। उदाहरण के लिए यह परिभाषित करता है कि विफलता की स्थिति में कौन से व्यक्तिगत सर्वरों को लाया जाना चाहिए या त्याग दिया जाना चाहिए। /etc/ha.d निर्देशिका में haresources फ़ाइल में जाँच करने पर, हमें उन संसाधनों की रूपरेखा मिलती है जिन्हें प्रबंधित किया जा सकता है। संसाधन फ़ाइल पथ /etc/ha.d/resource.d है और संसाधन परिभाषा एक पंक्ति में है जो है:
drbd1 drbddisk Filesystem::/dev/drbd0::/drbd::ext3 postgres 10.0.0.1(व्हाट्सएप पर ध्यान दें)।
- Drbd1:सर्वर से अधिक सुरक्षित होने के लिए पसंदीदा होस्ट के नाम को संदर्भित करता है जो सामान्य रूप से सेवा को संभालने के लिए डिफ़ॉल्ट मास्टर के रूप में उपयोग किया जाता है। जैसा कि DRBD ब्लॉग में उल्लेख किया गया है, हमें अपने सर्वर के लिए संसाधनों की आवश्यकता है और इन्हें लाइन में drbddisk, फाइल सिस्टम और पोस्टग्रेज के रूप में परिभाषित किया गया है। अंतिम फ़ील्ड एक वर्चुअल आईपी एड्रेस है जिसका उपयोग सेवा को साझा करने के लिए किया जाना चाहिए यानी पोस्टग्रेज सर्वर से कनेक्ट करना। डिफ़ॉल्ट रूप से, यह उस सर्वर को आवंटित किया जाएगा जो हार्टबीट शुरू होने पर सक्रिय होता है। जब कोई विफलता होती है, तो इन संसाधनों को बैकअप सर्वर पर व्यवस्था के क्रम में शुरू किया जाएगा जब संवाददाता स्क्रिप्ट को कॉल किया जाता है। सेटिंग में, स्क्रिप्ट DRBD डिस्क को सेकेंडरी होस्ट पर प्राथमिक मोड में स्विच कर देगी, जिससे डिवाइस रीड/राइट हो जाएगा।
- फाइल सिस्टम:यह फाइल सिस्टम संसाधनों का प्रबंधन करेगा और इस मामले में DRBD का चयन किया गया है, इसलिए इसे संसाधन स्क्रिप्ट की कॉल के दौरान माउंट किया जाएगा।
- पोस्टग्रेज:यह पोस्टग्रेज सर्वर को शुरू करेगा या प्रबंधित करेगा
कभी-कभी आप ईमेल के माध्यम से सूचनाएं प्राप्त करना चाहेंगे। ऐसा करने के लिए, चेतावनी पाठ प्राप्त करने के लिए इस पंक्ति को अपने ईमेल के साथ संसाधन फ़ाइल में जोड़ें:
MailTo:: example@sqldat.com::DRBDFailureदिल की धड़कन शुरू करने के लिए, आप कमांड चला सकते हैं
/etc/ha.d/heartbeat startया प्राथमिक और द्वितीयक सर्वर दोनों को रीबूट करें। अब अगर आप कमांड चलाते हैं
$ /usr/lib64/heartbeat/hb_standbyमौजूदा नोड को अपने संसाधनों को दूसरे नोड में साफ-साफ छोड़ने के लिए ट्रिगर किया जाएगा।
आज श्वेतपत्र डाउनलोड करें क्लस्टरकंट्रोल के साथ पोस्टग्रेएसक्यूएल प्रबंधन और स्वचालन इस बारे में जानें कि पोस्टग्रेएसक्यूएल को तैनात करने, मॉनिटर करने, प्रबंधित करने और स्केल करने के लिए आपको क्या जानना चाहिए। श्वेतपत्र डाउनलोड करेंसिस्टम स्तर की त्रुटियों को संभालना
कभी-कभी सर्वर कर्नेल दूषित हो सकता है इसलिए आपके सर्वर के साथ संभावित समस्या का संकेत देता है। किसी समस्या की स्थिति में आपको क्लस्टर से स्वयं को निकालने के लिए सर्वर को कॉन्फ़िगर करने की आवश्यकता होगी। इस समस्या को अक्सर कर्नेल पैनिक के रूप में जाना जाता है और इसके परिणामस्वरूप यह आपकी मशीन पर एक हार्ड रिबूट को ट्रिगर करता है। आप कर्नेल नियंत्रण फ़ाइल /etc/sysctl.conf के kernel.panic और kernel.panic_on_oop को सेट करके रिबूट को बाध्य कर सकते हैं। यानी
kernel.panic_on_oops = 1
kernel.panic = 1एक अन्य विकल्प यह है कि इसे sysctl कमांड का उपयोग करके कमांड लाइन से किया जाए:
$ sysctl -w kernel.panic=1आप sysctl.conf फ़ाइल को भी संपादित कर सकते हैं और इस कमांड का उपयोग करके कॉन्फ़िगरेशन जानकारी को पुनः लोड कर सकते हैं।
sysctl -pमान रीबूट करने से पहले प्रतीक्षा करने के लिए सेकंड की संख्या को इंगित करता है। दूसरे दिल की धड़कन नोड को तब पता लगाना चाहिए कि सर्वर डाउन है और फिर फ़ेलओवर होस्ट पर स्विच करें।
निष्कर्ष
हार्टबीट एक सबसिस्टम है जो एक सक्रिय सर्वर के विफल होने पर सेकेंडरी सर्वर को प्राइमरी और बैक-अप सिस्टम में चुनने की अनुमति देता है। यह भी निर्धारित करता है कि अन्य सभी सर्वर जीवित हैं या नहीं। यह नए प्राथमिक नोड में संसाधनों का हस्तांतरण भी सुनिश्चित करता है