स्प्रिंग ट्रांजैक्शन रूटिंग
सबसे पहले, हम एक DataSourceType बनाएंगे Java Enum जो हमारे लेन-देन रूटिंग विकल्पों को परिभाषित करता है:
public enum DataSourceType {
READ_WRITE,
READ_ONLY
}
रीड-राइट ट्रांजैक्शन को प्राइमरी नोड और रीड-ओनली ट्रांजैक्शन को रेप्लिका नोड में रूट करने के लिए, हम एक ReadWriteDataSource को परिभाषित कर सकते हैं। जो प्राथमिक नोड और एक ReadOnlyDataSource . से जुड़ता है जो रेप्लिका नोड से जुड़ते हैं।
रीड-राइट और रीड-ओनली ट्रांजैक्शन रूटिंग स्प्रिंग AbstractRoutingDataSource द्वारा की जाती है एब्स्ट्रैक्शन, जिसे TransactionRoutingDatasource . द्वारा कार्यान्वित किया जाता है , जैसा कि निम्नलिखित आरेख द्वारा दिखाया गया है:
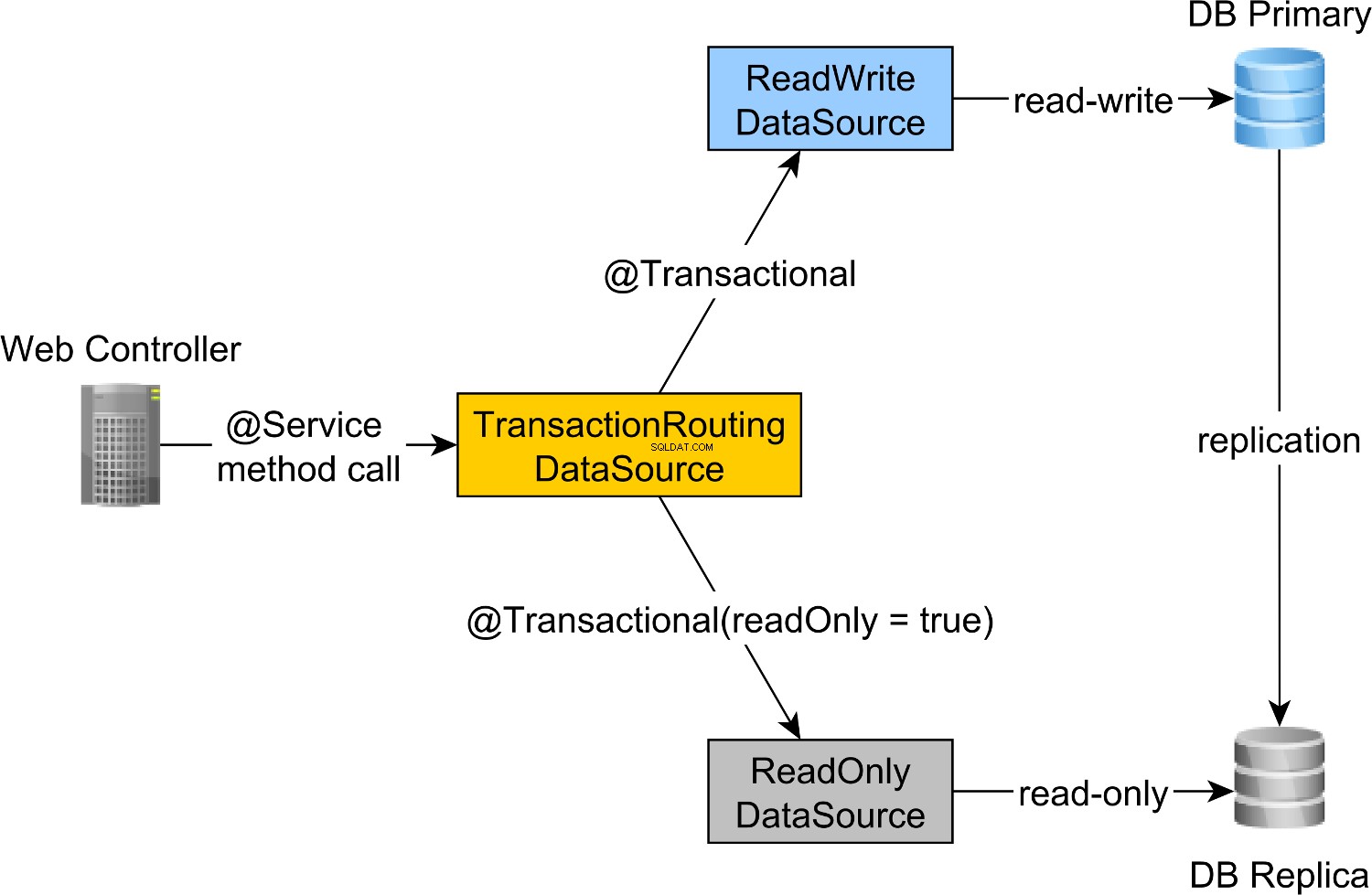
TransactionRoutingDataSource लागू करना बहुत आसान है और इस प्रकार दिखता है:
public class TransactionRoutingDataSource
extends AbstractRoutingDataSource {
@Nullable
@Override
protected Object determineCurrentLookupKey() {
return TransactionSynchronizationManager
.isCurrentTransactionReadOnly() ?
DataSourceType.READ_ONLY :
DataSourceType.READ_WRITE;
}
}
मूल रूप से, हम स्प्रिंग का निरीक्षण करते हैं TransactionSynchronizationManager क्लास जो वर्तमान ट्रांजेक्शनल संदर्भ को स्टोर करती है ताकि यह जांचा जा सके कि वर्तमान में चल रहा स्प्रिंग ट्रांजैक्शन केवल-पढ़ने के लिए है या नहीं।
determineCurrentLookupKey विधि विवेचक मान देता है जिसका उपयोग या तो पढ़ने-लिखने या केवल-पढ़ने के लिए JDBC DataSource को चुनने के लिए किया जाएगा ।
स्प्रिंग रीड-राइट और रीड-ओनली JDBC डेटासोर्स कॉन्फ़िगरेशन
DataSource विन्यास इस प्रकार दिखता है:
@Configuration
@ComponentScan(
basePackages = "com.vladmihalcea.book.hpjp.util.spring.routing"
)
@PropertySource(
"/META-INF/jdbc-postgresql-replication.properties"
)
public class TransactionRoutingConfiguration
extends AbstractJPAConfiguration {
@Value("${jdbc.url.primary}")
private String primaryUrl;
@Value("${jdbc.url.replica}")
private String replicaUrl;
@Value("${jdbc.username}")
private String username;
@Value("${jdbc.password}")
private String password;
@Bean
public DataSource readWriteDataSource() {
PGSimpleDataSource dataSource = new PGSimpleDataSource();
dataSource.setURL(primaryUrl);
dataSource.setUser(username);
dataSource.setPassword(password);
return connectionPoolDataSource(dataSource);
}
@Bean
public DataSource readOnlyDataSource() {
PGSimpleDataSource dataSource = new PGSimpleDataSource();
dataSource.setURL(replicaUrl);
dataSource.setUser(username);
dataSource.setPassword(password);
return connectionPoolDataSource(dataSource);
}
@Bean
public TransactionRoutingDataSource actualDataSource() {
TransactionRoutingDataSource routingDataSource =
new TransactionRoutingDataSource();
Map<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put(
DataSourceType.READ_WRITE,
readWriteDataSource()
);
dataSourceMap.put(
DataSourceType.READ_ONLY,
readOnlyDataSource()
);
routingDataSource.setTargetDataSources(dataSourceMap);
return routingDataSource;
}
@Override
protected Properties additionalProperties() {
Properties properties = super.additionalProperties();
properties.setProperty(
"hibernate.connection.provider_disables_autocommit",
Boolean.TRUE.toString()
);
return properties;
}
@Override
protected String[] packagesToScan() {
return new String[]{
"com.vladmihalcea.book.hpjp.hibernate.transaction.forum"
};
}
@Override
protected String databaseType() {
return Database.POSTGRESQL.name().toLowerCase();
}
protected HikariConfig hikariConfig(
DataSource dataSource) {
HikariConfig hikariConfig = new HikariConfig();
int cpuCores = Runtime.getRuntime().availableProcessors();
hikariConfig.setMaximumPoolSize(cpuCores * 4);
hikariConfig.setDataSource(dataSource);
hikariConfig.setAutoCommit(false);
return hikariConfig;
}
protected HikariDataSource connectionPoolDataSource(
DataSource dataSource) {
return new HikariDataSource(hikariConfig(dataSource));
}
}
/META-INF/jdbc-postgresql-replication.properties संसाधन फ़ाइल रीड-राइट और रीड-ओनली JDBC के लिए कॉन्फ़िगरेशन प्रदान करती है DataSource घटक:
hibernate.dialect=org.hibernate.dialect.PostgreSQL10Dialect
jdbc.url.primary=jdbc:postgresql://localhost:5432/high_performance_java_persistence
jdbc.url.replica=jdbc:postgresql://localhost:5432/high_performance_java_persistence_replica
jdbc.username=postgres
jdbc.password=admin
jdbc.url.primary संपत्ति प्राथमिक नोड के यूआरएल को परिभाषित करती है जबकि jdbc.url.replica रेप्लिका नोड के URL को परिभाषित करता है।
readWriteDataSource स्प्रिंग घटक रीड-राइट JDBC को परिभाषित करता है DataSource जबकि readOnlyDataSource घटक केवल-पढ़ने के लिए JDBC को परिभाषित करता है DataSource ।
ध्यान दें कि रीड-राइट और रीड-ओनली डेटा स्रोत कनेक्शन पूलिंग के लिए HikariCP का उपयोग करते हैं।
actualDataSource रीड-राइट और रीड-ओनली डेटा स्रोतों के लिए एक मुखौटा के रूप में कार्य करता है और इसे TransactionRoutingDataSource का उपयोग करके कार्यान्वित किया जाता है। उपयोगिता।
readWriteDataSource DataSourceType.READ_WRITE . का उपयोग करके पंजीकृत है कुंजी और readOnlyDataSource DataSourceType.READ_ONLY . का उपयोग करके कुंजी।
इसलिए, एक पठन-लेखन @Transactional executing निष्पादित करते समय विधि, readWriteDataSource @Transactional(readOnly = true) . को निष्पादित करते समय उपयोग किया जाएगा विधि, readOnlyDataSource इसके बजाय इस्तेमाल किया जाएगा।
ध्यान दें कि additionalProperties विधि hibernate.connection.provider_disables_autocommit को परिभाषित करती है हाइबरनेट संपत्ति, जिसे मैंने RESOURCE_LOCAL जेपीए लेनदेन के लिए डेटाबेस अधिग्रहण को स्थगित करने के लिए हाइबरनेट में जोड़ा था।
इतना ही नहीं hibernate.connection.provider_disables_autocommit आपको डेटाबेस कनेक्शन का बेहतर उपयोग करने की अनुमति देता है, लेकिन यह एकमात्र तरीका है जिससे हम इस उदाहरण को काम कर सकते हैं, क्योंकि इस कॉन्फ़िगरेशन के बिना, determineCurrentLookupKey को कॉल करने से पहले कनेक्शन प्राप्त कर लिया जाता है। विधि TransactionRoutingDataSource ।
JPA के निर्माण के लिए आवश्यक शेष स्प्रिंग घटक EntityManagerFactory AbstractJPAConfiguration . द्वारा परिभाषित किया गया है बेस क्लास।
मूल रूप से, actualDataSource आगे डेटासोर्स-प्रॉक्सी द्वारा लपेटा गया है और जेपीए को प्रदान किया गया है EntityManagerFactory . अधिक विवरण के लिए आप GitHub पर स्रोत कोड देख सकते हैं।
परीक्षण का समय
लेन-देन रूटिंग काम करता है या नहीं, यह जांचने के लिए, हम postgresql.conf में निम्नलिखित गुणों को सेट करके PostgreSQL क्वेरी लॉग को सक्षम करने जा रहे हैं। कॉन्फ़िगरेशन फ़ाइल:
log_min_duration_statement = 0
log_line_prefix = '[%d] '
log_min_duration_statement प्रॉपर्टी सेटिंग सभी पोस्टग्रेएसक्यूएल स्टेटमेंट्स को लॉग करने के लिए है जबकि दूसरा डेटाबेस नाम को एसक्यूएल लॉग में जोड़ता है।
इसलिए, newPost . को कॉल करते समय और findAllPostsByTitle तरीके, इस तरह:
Post post = forumService.newPost(
"High-Performance Java Persistence",
"JDBC", "JPA", "Hibernate"
);
List<Post> posts = forumService.findAllPostsByTitle(
"High-Performance Java Persistence"
);
हम देख सकते हैं कि PostgreSQL निम्नलिखित संदेशों को लॉग करता है:
[high_performance_java_persistence] LOG: execute <unnamed>:
BEGIN
[high_performance_java_persistence] DETAIL:
parameters: $1 = 'JDBC', $2 = 'JPA', $3 = 'Hibernate'
[high_performance_java_persistence] LOG: execute <unnamed>:
select tag0_.id as id1_4_, tag0_.name as name2_4_
from tag tag0_ where tag0_.name in ($1 , $2 , $3)
[high_performance_java_persistence] LOG: execute <unnamed>:
select nextval ('hibernate_sequence')
[high_performance_java_persistence] DETAIL:
parameters: $1 = 'High-Performance Java Persistence', $2 = '4'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post (title, id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '1'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '2'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] DETAIL:
parameters: $1 = '4', $2 = '3'
[high_performance_java_persistence] LOG: execute <unnamed>:
insert into post_tag (post_id, tag_id) values ($1, $2)
[high_performance_java_persistence] LOG: execute S_3:
COMMIT
[high_performance_java_persistence_replica] LOG: execute <unnamed>:
BEGIN
[high_performance_java_persistence_replica] DETAIL:
parameters: $1 = 'High-Performance Java Persistence'
[high_performance_java_persistence_replica] LOG: execute <unnamed>:
select post0_.id as id1_0_, post0_.title as title2_0_
from post post0_ where post0_.title=$1
[high_performance_java_persistence_replica] LOG: execute S_1:
COMMIT
high_performance_java_persistence . का उपयोग कर लॉग स्टेटमेंट उपसर्ग को प्राथमिक नोड पर निष्पादित किया गया था, जबकि वाले high_performance_java_persistence_replica का उपयोग कर रहे थे प्रतिकृति नोड पर।
तो, सब कुछ एक आकर्षण की तरह काम करता है!
सभी स्रोत कोड मेरे उच्च-प्रदर्शन जावा पर्सिस्टेंस गिटहब भंडार में पाए जा सकते हैं, ताकि आप इसे भी आजमा सकें।
निष्कर्ष
आपको यह सुनिश्चित करने की ज़रूरत है कि आपने अपने कनेक्शन पूल के लिए सही आकार निर्धारित किया है क्योंकि इससे बहुत बड़ा अंतर आ सकता है। इसके लिए, मैं फ्लेक्सी पूल का उपयोग करने की सलाह देता हूं।
आपको बहुत मेहनती होने की आवश्यकता है और सुनिश्चित करें कि आप सभी केवल-पढ़ने के लिए लेनदेन को उसी के अनुसार चिह्नित करते हैं। यह असामान्य है कि आपके केवल 10% लेन-देन केवल-पढ़ने के लिए होते हैं। क्या ऐसा हो सकता है कि आपके पास इतना अधिक लिखने वाला एप्लिकेशन है या आप लिखित लेनदेन का उपयोग कर रहे हैं जहां आप केवल क्वेरी स्टेटमेंट जारी करते हैं?
बैच प्रोसेसिंग के लिए, आपको निश्चित रूप से पढ़ने-लिखने के लेन-देन की आवश्यकता होती है, इसलिए सुनिश्चित करें कि आपने JDBC बैचिंग को इस तरह सक्षम किया है:
<property name="hibernate.order_updates" value="true"/>
<property name="hibernate.order_inserts" value="true"/>
<property name="hibernate.jdbc.batch_size" value="25"/>
बैचिंग के लिए आप एक अलग DataSource . का भी उपयोग कर सकते हैं जो एक अलग कनेक्शन पूल का उपयोग करता है जो प्राथमिक नोड से जुड़ता है।
बस सुनिश्चित करें कि आपके सभी कनेक्शन पूलों का कुल कनेक्शन आकार उन कनेक्शनों की संख्या से कम है जिनके साथ PostgreSQL कॉन्फ़िगर किया गया है।
प्रत्येक बैच कार्य को एक समर्पित लेनदेन का उपयोग करना चाहिए, इसलिए सुनिश्चित करें कि आप उचित बैच आकार का उपयोग करते हैं।
इसके अलावा, आप ताले रखना चाहते हैं और जितनी जल्दी हो सके लेनदेन समाप्त करना चाहते हैं। यदि बैच प्रोसेसर समवर्ती प्रसंस्करण श्रमिकों का उपयोग कर रहा है, तो सुनिश्चित करें कि संबंधित कनेक्शन पूल का आकार श्रमिकों की संख्या के बराबर है, ताकि वे दूसरों के कनेक्शन जारी करने की प्रतीक्षा न करें।