IGNORE_DUP_KEY अद्वितीय अनुक्रमणिका के लिए विकल्प निर्दिष्ट करता है कि SQL सर्वर INSERT के प्रयास के प्रति कैसे प्रतिक्रिया करता है डुप्लिकेट मान:यह केवल तालिकाओं पर लागू होता है (विचारों पर नहीं) और केवल इन्सर्ट पर लागू होता है। MERGE . का कोई भी सम्मिलित भाग कथन किसी भी IGNORE_DUP_KEY की उपेक्षा करता है अनुक्रमणिका सेटिंग.
जब IGNORE_DUP_KEY OFF है , पहले डुप्लीकेट का सामना एक त्रुटि में होता है , और नई पंक्तियों में से कोई भी सम्मिलित नहीं किया गया है।
जब IGNORE_DUP_KEY ON है , सम्मिलित पंक्तियाँ जो विशिष्टता का उल्लंघन करती हैं, उन्हें छोड़ दिया जाता है। शेष पंक्तियों को सफलतापूर्वक सम्मिलित किया गया है। एक चेतावनी त्रुटि के बजाय संदेश उत्सर्जित होता है:
अनुच्छेद सारांश
IGNORE_DUP_KEY अनुक्रमणिका विकल्प को संकुल और गैर-संकुल अद्वितीय अनुक्रमणिका दोनों के लिए निर्दिष्ट किया जा सकता है। क्लस्टर्ड इंडेक्स पर इसका उपयोग करने से बहुत खराब प्रदर्शन . हो सकता है एक गैर-संकुल अद्वितीय अनुक्रमणिका की तुलना में।
प्रदर्शन अंतर का आकार इस बात पर निर्भर करता है कि INSERT . के दौरान कितने विशिष्टता उल्लंघनों का सामना करना पड़ा है कार्यवाही। जितने अधिक उल्लंघन होंगे, क्लस्टर्ड यूनीक इंडेक्स तुलनात्मक रूप से उतना ही खराब प्रदर्शन करेगा। अगर कोई उल्लंघन नहीं है, तो क्लस्टर इंडेक्स इंसर्ट और भी बेहतर प्रदर्शन कर सकता है।
क्लस्टर किए गए अद्वितीय इंडेक्स इंसर्ट
IGNORE_DUP_KEY . के साथ संकुल अद्वितीय अनुक्रमणिका के लिए सेट, डुप्लिकेट को स्टोरेज इंजन . द्वारा नियंत्रित किया जाता है ।
प्रत्येक पंक्ति को सम्मिलित करने में शामिल अधिकांश कार्य डुप्लिकेट का पता लगाने से पहले किया जाता है। उदाहरण के लिए, एक संकुल अनुक्रमणिका सम्मिलित करें डुप्लिकेट कुंजी का पता लगाने से पहले, ऑपरेटर क्लस्टर इंडेक्स बी-ट्री को उस बिंदु तक नेविगेट करता है जहां नई पंक्ति जाएगी, पेज लैच और तालों के सामान्य पदानुक्रम को लेकर।
जब डुप्लीकेट कुंजी की स्थिति का पता चलता है, तो एक त्रुटि उठाया है। निष्पादन को रद्द करने और क्लाइंट को त्रुटि वापस करने के बजाय, त्रुटि को आंतरिक रूप से नियंत्रित किया जाता है। समस्याग्रस्त पंक्ति सम्मिलित नहीं है, और निष्पादन जारी है, सम्मिलित करने के लिए अगली पंक्ति की तलाश में। यदि उस पंक्ति में एक डुप्लीकेट कुंजी मिलती है, तो एक और त्रुटि उठाई जाती है और उसे संभाला जाता है, और इसी तरह।
अपवाद फेंकना और पकड़ना बहुत महंगा है। डुप्लीकेट की एक बड़ी संख्या निष्पादन को बहुत ही धीमा कर देगी।
गैर-क्लस्टर किए गए यूनीक इंडेक्स इंसर्ट
IGNORE_DUP_KEY . के साथ एक गैर-संकुल अद्वितीय अनुक्रमणिका के लिए सेट, डुप्लिकेट को क्वेरी प्रोसेसर द्वारा नियंत्रित किया जाता है . प्रत्येक डालने का प्रयास करने से पहले डुप्लिकेट का पता लगाया जाता है, और एक चेतावनी उत्सर्जित की जाती है।
क्वेरी प्रोसेसर इन्सर्ट स्ट्रीम से डुप्लिकेट को हटाता है, यह सुनिश्चित करता है कि स्टोरेज इंजन द्वारा कोई डुप्लिकेट नहीं देखा जाता है। परिणामस्वरूप, कोई अद्वितीय कुंजी उल्लंघन त्रुटियाँ आंतरिक रूप से नहीं उठाई जाती हैं या उन्हें नियंत्रित नहीं किया जाता है।
व्यापार बंद
निष्पादन योजना में डुप्लिकेट कुंजियों का पता लगाने और हटाने की लागत, महत्वपूर्ण सम्मिलन-संबंधित कार्य करने की लागत और डुप्लिकेट मिलने पर त्रुटियों को फेंकने और पकड़ने की लागत के बीच एक व्यापार-बंद है।
यदि डुप्लिकेट बहुत दुर्लभ होने की उम्मीद है , भंडारण इंजन समाधान (संकुल सूचकांक) अधिक कुशल हो सकता है। जब डुप्लिकेट कम दुर्लभ होते हैं, तो क्वेरी प्रोसेसर दृष्टिकोण संभावित रूप से लाभांश का भुगतान करेगा। सटीक क्रॉसओवर बिंदु डुप्लिकेट का पता लगाने और निकालने के लिए उपयोग किए जाने वाले निष्पादन योजना घटकों की रनटाइम दक्षता जैसे कारकों पर निर्भर करेगा।
इस लेख का शेष भाग एक डेमो प्रदान करता है और अधिक विस्तार से देखता है कि स्टोरेज इंजन दृष्टिकोण इतना खराब प्रदर्शन क्यों कर सकता है।
डेमो
निम्न स्क्रिप्ट एक लाख पंक्तियों के साथ एक अस्थायी तालिका बनाता है। इसमें प्रत्येक अद्वितीय मूल्य के लिए 1,000 अद्वितीय मान और 1,000 पंक्तियाँ हैं। इस डेटा सेट का उपयोग विभिन्न इंडेक्स कॉन्फ़िगरेशन वाली तालिकाओं में सम्मिलित करने के लिए डेटा स्रोत के रूप में किया जाएगा।
DROP TABLE IF EXISTS #Data;
GO
CREATE TABLE #Data (c1 integer NOT NULL);
GO
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE
@Loop integer = 1,
@N integer = 1;
WHILE @N <= 1000
BEGIN
SET @Loop = 1;
BEGIN TRANSACTION;
-- Add 1,000 copies of the current loop value
WHILE @Loop <= 50
BEGIN
INSERT #Data
(c1)
VALUES
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N);
SET @Loop += 1;
END;
COMMIT TRANSACTION;
SET @N += 1;
END;
CREATE CLUSTERED INDEX cx
ON #Data (c1)
WITH (MAXDOP = 1); के साथ क्लस्टर इंडेक्स cx बनाएं आधारभूत
एक गैर-अद्वितीय क्लस्टर अनुक्रमणिका वाले तालिका चर में निम्नलिखित सम्मिलन में लगभग 900ms का समय लगता है :
DECLARE @T table
(
c1 integer NOT NULL
INDEX cuq CLUSTERED (c1)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D;
IGNORE_DUP_KEY की कमी पर ध्यान दें लक्ष्य तालिका चर पर।
संकुल अद्वितीय अनुक्रमणिका
एक ही डेटा को एक अद्वितीय क्लस्टर . में सम्मिलित करना IGNORE_DUP_KEY के साथ इंडेक्स करें सेट ON लगभग 15,900ms takes लेता है — लगभग 18 गुना बदतर:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; गैर-संकुल अद्वितीय अनुक्रमणिका
एक अद्वितीय गैर-संकुल . में डेटा सम्मिलित करना IGNORE_DUP_KEY के साथ इंडेक्स करें सेट ON लगभग 700ms . लेता है :
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE NONCLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; प्रदर्शन सारांश
आधारभूत परीक्षण में 900ms लगता है सभी दस लाख पंक्तियों को सम्मिलित करने के लिए। गैर-संकुल अनुक्रमणिका परीक्षण में 700ms लगता है सिर्फ 1,000 अलग-अलग कुंजियाँ डालने के लिए। क्लस्टर इंडेक्स टेस्ट में 15,900ms का समय लगता है वही 1,000 अद्वितीय पंक्तियां सम्मिलित करने के लिए।
यह परीक्षण जानबूझकर भंडारण इंजन कार्यान्वयन के खराब प्रदर्शन को उजागर करने के लिए स्थापित किया गया है, प्रत्येक सफल पंक्ति के लिए 999 यूनिट व्यर्थ कार्य (कुंडी, ताले, त्रुटि प्रबंधन) उत्पन्न करके।
इरादा संदेश यह नहीं है कि IGNORE_DUP_KEY क्लस्टर इंडेक्स पर हमेशा खराब प्रदर्शन करेगा, बस इतना ही हो सकता है, और क्लस्टर्ड और गैर-क्लस्टर इंडेक्स के बीच एक बड़ा अंतर हो सकता है।
संकुल अनुक्रमणिका निष्पादन योजना
क्लस्टर्ड इंडेक्स इंसर्ट प्लान में देखने के लिए बहुत बड़ी राशि नहीं है:
क्लस्टर इंडेक्स इंसर्ट . को 1,000,000 पंक्तियां पास की जा रही हैं ऑपरेटर, जिसे 'रिटर्निंग' 1,000 पंक्तियों के रूप में दिखाया गया है। योजना विवरण में खुदाई करने पर, हम देख सकते हैं:
- 1,244,008 लॉजिकल इन्सर्ट ऑपरेटर पर पढ़ता है।
- निष्पादन समय का बड़ा हिस्सा सम्मिलित करें . पर खर्च होता है ऑपरेटर।
- 11ms
SOS_SCHEDULER_YIELDप्रतीक्षा (अर्थात कोई अन्य प्रतीक्षा नहीं)।
ऐसा कुछ भी नहीं जो वास्तव में 15,900 ms . की व्याख्या करता हो बीता हुआ समय।
प्रदर्शन इतना खराब क्यों है
जाहिर है, इस योजना को प्रत्येक पंक्ति के लिए बहुत काम करना होगा:
- नए रिकॉर्ड के लिए सम्मिलन बिंदु खोजने के लिए, क्लस्टर इंडेक्स बी-ट्री स्तरों को नेविगेट करें, जैसे ही यह जाता है, लॉकिंग और लॉकिंग करें।
- यदि आवश्यक कोई अनुक्रमणिका पृष्ठ स्मृति में नहीं हैं, तो उन्हें डिस्क से लाने की आवश्यकता होगी।
- स्मृति में एक नई बी-ट्री पंक्ति बनाएं।
- लॉग रिकॉर्ड तैयार करें।
- यदि कोई कुंजी डुप्लीकेट मिलता है (जो घोस्ट रिकॉर्ड नहीं है), एक त्रुटि उत्पन्न करें, उस त्रुटि को आंतरिक रूप से संभालें, वर्तमान पंक्ति को छोड़ें, और अगली उम्मीदवार पंक्ति को संसाधित करने के लिए कोड में एक उपयुक्त बिंदु पर फिर से शुरू करें। ली>
यह सब उचित मात्रा में काम है, और याद रखें कि यह सब होता है प्रत्येक पंक्ति के लिए ।
जिस हिस्से पर मैं ध्यान केंद्रित करना चाहता हूं वह है त्रुटि उठाना और संभालना, क्योंकि यह बेहद है महँगा। डेमो में टेबल वेरिएबल और अस्थायी टेबल का उपयोग करके ऊपर बताए गए शेष पहलुओं को पहले से ही जितना संभव हो उतना सस्ता बना दिया गया था।
अपवाद
पहली चीज जो मैं करना चाहता हूं वह यह दिखाना है कि क्लस्टर इंडेक्स इंसर्ट डुप्लिकेट कुंजी मिलने पर ऑपरेटर वास्तव में अपवाद उठाता है।
इसे सीधे दिखाने का एक तरीका है एक डीबगर संलग्न करना और उस बिंदु पर एक स्टैक ट्रेस को कैप्चर करना जहां अपवाद फेंका गया है:
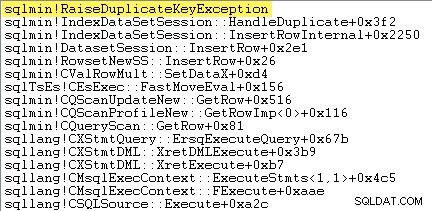
यहां महत्वपूर्ण बात यह है कि अपवादों को फेंकना और पकड़ना बहुत महंगा है।
परीक्षण चल रहा था, जबकि विंडोज प्रदर्शन रिकॉर्डर का उपयोग कर SQL सर्वर की निगरानी करना, और विंडोज़ प्रदर्शन विश्लेषक में परिणामों का विश्लेषण दिखाता है:
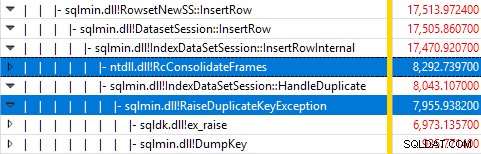
लगभग सभी क्वेरी निष्पादन समय sqlmin!IndexDataSetSession::InsertRowInternal में व्यतीत होता है जैसा कि एक क्वेरी के लिए अपेक्षित होगा जो सम्मिलित पंक्तियों को छोड़कर कुछ और करता है।
आश्चर्य की बात यह है कि उस समय का 45% sqlmin!RaiseDuplicateKeyException के माध्यम से अपवादों को बढ़ाने में व्यतीत होता है। और अन्य 47% संबंधित अपवाद कैच ब्लॉक में खर्च किया जाता है (ntdll!RcConsolidateFrames पदानुक्रम) ।
संक्षेप में:अपवादों को उठाना और पकड़ना निष्पादन समय का 92% है हमारे टेस्ट क्लस्टर इंडेक्स इंसर्ट क्वेरी का।
डेटा संग्रहण समस्याएं
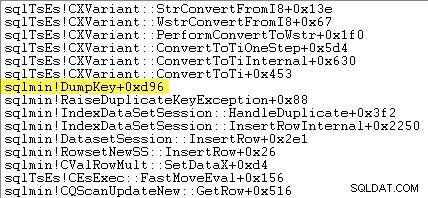
तेज-तर्रार पाठकों को sqlmin!DumpKey में खर्च किए गए अपवाद को बढ़ाने में लगने वाले समय की - लगभग 12% - एक महत्वपूर्ण राशि दिखाई दे सकती है। विंडोज प्रदर्शन विश्लेषक ग्राफिक में। यह कुछ संबंधित वस्तुओं के साथ-साथ शीघ्रता से तलाशने लायक है।
एक अपवाद को बढ़ाने के हिस्से के रूप में, SQL सर्वर को कुछ डेटा एकत्र करना होता है जो केवल त्रुटि के समय उपलब्ध होता है। डुप्लीकेट कुंजी अपवाद से जुड़ी त्रुटि संख्या 2627 है। sys.messages में संदेश टेक्स्ट उस त्रुटि संख्या के लिए है:
उन स्थानों के मार्करों को भरने के लिए जानकारी को उस समय एकत्रित करने की आवश्यकता है जब त्रुटि उठाई जाती है - यह बाद में उपलब्ध नहीं होगी! इसका मतलब है कि बाधा के प्रकार, उसका नाम, लक्ष्य वस्तु का पूरा नाम और विशिष्ट कुंजी मान को देखना और स्वरूपित करना। वह सब जिसमें समय लगता है।
निम्न स्टैक ट्रेस सर्वर को DumpKey के दौरान यूनिकोड स्ट्रिंग के रूप में डुप्लीकेट कुंजी मान को स्वरूपित करते हुए दिखाता है कॉल करें:
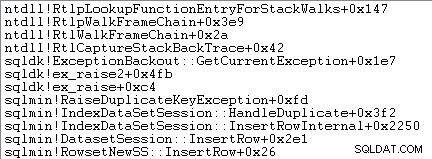
एक्सेप्शन हैंडलिंग में स्टैक ट्रेस को कैप्चर करना भी शामिल है:
SQL सर्वर एक छोटे रिंग बफ़र में अपवादों (स्टैक फ़्रेम सहित) के बारे में जानकारी भी रिकॉर्ड करता है, जैसा कि निम्न दिखाता है:
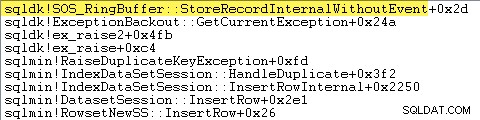
आप उन रिंग बफर प्रविष्टियों को एक कमांड का उपयोग करके देख सकते हैं जैसे:
SELECT TOP (10)
date_time =
DATEADD
(
MILLISECOND,
DORB.[timestamp] - DOSI.ms_ticks,
SYSDATETIME()
),
record = CONVERT(xml, DORB.record)
FROM sys.dm_os_ring_buffers AS DORB
CROSS JOIN sys.dm_os_sys_info AS DOSI
WHERE
DORB.ring_buffer_type = N'RING_BUFFER_EXCEPTION'
ORDER BY
DORB.[timestamp] DESC; डुप्लिकेट कुंजी अपवाद के लिए xml रिकॉर्ड का एक उदाहरण इस प्रकार है। स्टैक फ़्रेम पर ध्यान दें:
<Record id="4611442" type="RING_BUFFER_EXCEPTION" time="93079430">
<Exception>
<Task address="0x00000245B5E1FC28" />
<Error>2627</Error>
<Severity>14</Severity>
<State>1</State>
<UserDefined>0</UserDefined>
<Origin>0</Origin>
</Exception>
<Stack>
<frame id="0">0X00007FFAC659E80A</frame>
<frame id="1">0X00007FFACBAC0EFD</frame>
<frame id="2">0X00007FFACBAA1252</frame>
<frame id="3">0X00007FFACBA9E040</frame>
<frame id="4">0X00007FFACAB55D53</frame>
<frame id="5">0X00007FFACAB55C06</frame>
<frame id="6">0X00007FFACB3E3D0B</frame>
<frame id="7">0X00007FFAC92020EC</frame>
<frame id="8">0X00007FFACAB5B2FA</frame>
<frame id="9">0X00007FFACABA3B9B</frame>
<frame id="10">0X00007FFACAB3D89F</frame>
<frame id="11">0X00007FFAC6A9D108</frame>
<frame id="12">0X00007FFAC6AB2BBF</frame>
<frame id="13">0X00007FFAC6AB296F</frame>
<frame id="14">0X00007FFAC6A9B7D0</frame>
<frame id="15">0X00007FFAC6A9B233</frame>
</Stack>
</Record> यह सारा बैकग्राउंड वर्क हर अपवाद के लिए होता है। हमारे परीक्षण में, इसका मतलब है कि यह 999,000 बार होता है - प्रत्येक पंक्ति के लिए एक बार जो डुप्लिकेट कुंजी उल्लंघन का सामना करती है।
इसे देखने के कई तरीके हैं, उदाहरण के लिए अपवाद . का उपयोग करके प्रोफाइलर ट्रेस चलाकर त्रुटियों और चेतावनियों में घटना कक्षा। हमारे परीक्षण मामले में, यह अंततः होगा TextData . के साथ 999,000 पंक्तियां बनाएं इस तरह के तत्व:
UNIQUE KEY बाधा का उल्लंघन 'UQ__#AC166DE__3213663B8B6E2E0E'ऑब्जेक्ट 'dbo.@T' में डुप्लिकेट कुंजी नहीं डाल सकता।
डुप्लिकेट कुंजी मान (173) है।
प्रोफाइलर संलग्न करने का अर्थ है कि प्रत्येक अपवाद हैंडलिंग घटना अतिरिक्त ओवरहेड का एक बड़ा सौदा प्राप्त करती है, क्योंकि आवश्यक अतिरिक्त डेटा एकत्र और स्वरूपित किया जाता है। पहले उल्लेख किया गया डिफ़ॉल्ट डेटा हमेशा एकत्र किया जाता है, भले ही कोई भी सक्रिय रूप से जानकारी का उपभोग न कर रहा हो।
स्पष्ट होने के लिए:इस आलेख में रिपोर्ट की गई प्रदर्शन संख्याएं सभी डीबगर संलग्न किए बिना प्राप्त की गई थीं, और कोई अन्य निगरानी सक्रिय नहीं थी।
गैर-संकुल अनुक्रमणिका निष्पादन योजना
इतना तेज़ होने के बावजूद, गैर-संकुलित अनुक्रमणिका सम्मिलित योजना कुछ अधिक जटिल है, इसलिए मैं इसे दो भागों में विभाजित करूँगा।
सामान्य विषय यह है कि यह योजना तेज़ है क्योंकि यह डुप्लिकेट को पहले . हटा देती है उन्हें लक्ष्य तालिका में सम्मिलित करने का प्रयास कर रहा है।
भाग 1
सबसे पहले, गैर-संकुल अनुक्रमणिका योजना का दाहिना भाग:
योजना का यह भाग लक्षित तालिका में महत्वपूर्ण मिलान वाली किसी भी पंक्ति को अस्वीकार करता है IGNORE_DUP_KEY . के साथ अद्वितीय अनुक्रमणिका के लिए सेट ON ।
आप शायद एक एंटी सेमी जॉइन देखने की उम्मीद कर रहे होंगे यहां, लेकिन SQL सर्वर के पास आवश्यक डुप्लिकेट कुंजी चेतावनी को एंटी सेमी जॉइन के साथ उत्सर्जित करने के लिए आवश्यक आधारभूत संरचना नहीं है। ऑपरेटर। (यदि इसका पहले से कोई मतलब नहीं है, तो यह शीघ्र ही होना चाहिए।)
इसके बजाय, हमें कई दिलचस्प विशेषताओं वाला एक प्लान मिलता है:
- संकुल अनुक्रमणिका स्कैन
Ordered:Trueबाएं सेमी जॉइन मर्ज करें . को इनपुट प्रदान करने के लिए कॉलमc1. द्वारा क्रमबद्ध#Data. में टेबल. - द इंडेक्स स्कैन तालिका चर का
Ordered:False - क्रमबद्ध करें कॉलम
c1. द्वारा पंक्तियों को ऑर्डर करें तालिका चर में। यह आदेश आदेश . द्वारा प्रदान किया जा सकता थाc1. पर टेबल वैरिएबल इंडेक्स का स्कैन , लेकिन अनुकूलक क्रमबद्ध करें . का निर्णय करता है हैलोवीन सुरक्षा का आवश्यक स्तर प्रदान करने का सबसे सस्ता तरीका है। - टेबल वैरिएबल इंडेक्स स्कैन आंतरिक
UPDLOCKहै औरSERIALIZABLEयोजना निष्पादन के दौरान लक्ष्य स्थिरता सुनिश्चित करने के लिए संकेत लागू किए गए। - द लेफ्ट सेमी जॉइन मर्ज करें
c1. के प्रत्येक मान के लिए तालिका चर में मैचों की जांच करता है#Data. से लौटाया गया टेबल। नियमित सेमी जॉइन के विपरीत, यह अपने ऊपरी इनपुट पर प्राप्त प्रत्येक पंक्ति को उत्सर्जित करता है। यह एक जांच कॉलम . में एक ध्वज सेट करता है यह इंगित करने के लिए कि वर्तमान पंक्ति को एक मैच मिला या नहीं। जांच कॉलम लेफ्ट सेमी जॉइन मर्ज करें . से उत्सर्जित होता हैExpr1012. नामक व्यंजक के रूप में । - द जोर ऑपरेटर जांच कॉलम के मान की जांच करता है
Expr1012. पहली बार जब यह एक गैर-नल जांच कॉलम मान के साथ एक पंक्ति देखता है (यह दर्शाता है कि एक इंडेक्स कुंजी मिलान पाया गया था), यह एक "डुप्लिकेट कुंजी को अनदेखा किया गया था" उत्सर्जित करता है संदेश। - द जोर केवल उन पंक्तियों पर गुजरता है जहां जांच स्तंभ शून्य है। यह आने वाली पंक्तियों को हटा देता है जो डुप्लीकेट कुंजी त्रुटि उत्पन्न करती हैं।
यह सब जटिल लग सकता है, लेकिन यह अनिवार्य रूप से उतना ही सरल है जितना कि एक मैच मिलने पर ध्वज सेट करना, पहली बार ध्वज सेट होने पर चेतावनी देना, और केवल उन पंक्तियों को सम्मिलित करना जो लक्ष्य तालिका में पहले से मौजूद नहीं हैं ।
भाग 2
योजना का दूसरा भाग जोर का अनुसरण करता है ऑपरेटर:
योजना के पिछले भाग ने उन पंक्तियों को हटा दिया जिनका लक्ष्य तालिका में मिलान था। योजना का यह भाग सम्मिलित सेट के भीतर डुप्लीकेट हटा देता है ।
उदाहरण के लिए, कल्पना करें कि लक्ष्य तालिका में ऐसी कोई पंक्तियाँ नहीं हैं जहाँ c1 = 1 . यदि हम c1 = 1 . के साथ दो पंक्तियों को सम्मिलित करने का प्रयास करते हैं, तब भी हम डुप्लीकेट कुंजी त्रुटि उत्पन्न कर सकते हैं स्रोत तालिका से। IGNORE_DUP_KEY = ON . के शब्दार्थ का सम्मान करने के लिए हमें इससे बचने की आवश्यकता है ।
यह पहलू सेगमेंट . द्वारा नियंत्रित किया जाता है और शीर्ष ऑपरेटरों।
सेगमेंट ऑपरेटर एक नया ध्वज सेट करता है (लेबल Segment1015 ) जब यह c1 . के लिए एक नए मान के साथ एक पंक्ति का सामना करता है . चूँकि पंक्तियाँ c1 . में प्रस्तुत की जाती हैं आदेश (आदेश-संरक्षण के लिए धन्यवाद मर्ज करें ), योजना समान c1 . के साथ सभी पंक्तियों पर भरोसा कर सकती है एक सन्निहित धारा में आने वाला मूल्य।
शीर्ष जैसा कि सेगमेंट . द्वारा दर्शाया गया है, ऑपरेटर डुप्लिकेट के प्रत्येक समूह के लिए एक पंक्ति में पास करता है झंडा। अगर शीर्ष ऑपरेटर को एक ही सेगमेंट . के लिए एक से अधिक पंक्तियों का सामना करना पड़ता है समूह (c1 value), यह एक “डुप्लीकेट कुंजी को नज़रअंदाज़ किया गया” . का उत्सर्जन करता है चेतावनी, अगर यह पहली बार है कि योजना को उस स्थिति का सामना करना पड़ा है।
इन सबका कुल प्रभाव यह है कि c1 के प्रत्येक अद्वितीय मान के लिए केवल एक पंक्ति इन्सर्ट ऑपरेटरों को पास की जाती है , और यदि आवश्यक हो तो एक चेतावनी उत्पन्न की जाती है।
निष्पादन योजना ने अब सभी संभावित डुप्लिकेट कुंजी उल्लंघनों को समाप्त कर दिया है, इसलिए शेष टेबल इंसर्ट और इंडेक्स इंसर्ट ऑपरेटर डुप्लिकेट कुंजी त्रुटि के डर के बिना हीप और गैर-संकुल अनुक्रमणिका में पंक्तियों को सुरक्षित रूप से सम्मिलित कर सकते हैं।
याद रखें कि UPDLOCK और SERIALIZABLE लक्ष्य तालिका पर लागू संकेत यह सुनिश्चित करते हैं कि निष्पादन के दौरान सेट नहीं बदल सकता है। दूसरे शब्दों में, एक समवर्ती कथन लक्ष्य तालिका को इस प्रकार नहीं बदल सकता है कि एक डुप्लिकेट कुंजी त्रुटि सम्मिलित करें पर हो। ऑपरेटरों। यह यहाँ कोई चिंता की बात नहीं है क्योंकि हम एक निजी तालिका चर का उपयोग कर रहे हैं, लेकिन SQL सर्वर अभी भी एक सामान्य सुरक्षा उपाय के रूप में संकेत जोड़ता है।
उन संकेतों के बिना, एक समवर्ती प्रक्रिया लक्ष्य तालिका में एक पंक्ति जोड़ सकती है जो योजना के भाग 1 द्वारा किए गए चेक के बावजूद डुप्लिकेट कुंजी उल्लंघन उत्पन्न करेगी। SQL सर्वर को यह सुनिश्चित करने की आवश्यकता है कि अस्तित्व की जाँच के परिणाम मान्य रहें।
जिज्ञासु पाठक ऑप्टिमाइज़र आउटपुट ट्री देखने के लिए ट्रेस फ़्लैग्स 3604 और 8607 को सक्षम करके ऊपर वर्णित कुछ विशेषताओं को देख सकता है:
PhyOp_RestrRemap
PhyOp_StreamUpdate(INS TBL: @T, iid 0x2 as IDX, Sort(QCOL: .c1, )), {
- COL: Bmk10001013 = COL: Bmk1000
- COL: c11014 = QCOL: .c1}
PhyOp_StreamUpdate(INS TBL: @T, iid 0x0 as TBLInsLocator(COL: Bmk1000 ) REPORT-COUNT), {
- QCOL: .c1= QCOL: [D].c1}
PhyOp_GbTop Group(QCOL: [D].c1,) WARN-DUP
PhyOp_StreamCheck (WarnIgnoreDuplicate TABLE)
PhyOp_MergeJoin x_jtLeftSemi M-M, Probe COL: Expr1012 ( QCOL: [D].c1) = ( QCOL: .c1)
PhyOp_Range TBL: #Data(alias TBL: D)(1) ASC
PhyOp_Sort +s -d QCOL: .c1
PhyOp_Range TBL: @T(2) ASC Hints( UPDLOCK SERIALIZABLE FORCEDINDEX )
ScaOp_Comp x_cmpIs
ScaOp_Identifier QCOL: [D].c1
ScaOp_Identifier QCOL: .c1
ScaOp_Logical x_lopIsNotNull
ScaOp_Identifier COL: Expr1012
अंतिम विचार
IGNORE_DUP_KEY अनुक्रमणिका विकल्प ऐसा कुछ नहीं है जिसका अधिकांश लोग बहुत बार उपयोग करेंगे। फिर भी, यह देखना दिलचस्प है कि यह कार्यक्षमता कैसे कार्यान्वित की जाती है, और IGNORE_DUP_KEY के बीच बड़े प्रदर्शन अंतर क्यों हो सकते हैं क्लस्टर्ड और नॉनक्लस्टर इंडेक्स पर।
कई मामलों में, यह क्वेरी प्रोसेसर के नेतृत्व का पालन करने के लिए भुगतान करेगा और IGNORE_DUP_KEY पर निर्भर होने के बजाय स्पष्ट रूप से डुप्लिकेट को समाप्त करने वाले प्रश्नों को लिखने की तलाश करेगा। . हमारे उदाहरण में, इसका मतलब होगा लिखना:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED -- no IGNORE_DUP_KEY!
);
INSERT @T
(c1)
SELECT DISTINCT -- Remove duplicates
D.c1
FROM #Data AS D; यह लगभग 400ms . में निष्पादित होता है , केवल रिकॉर्ड के लिए।



