किसी क्वेरी को निष्पादित करने में इतना समय क्यों लगता है? कोई अनुक्रमणिका क्यों नहीं हैं? संभावना है कि आपने PostgreSQL में EXPLAIN के बारे में सुना होगा। हालांकि, अभी भी बहुत से लोग ऐसे हैं जिन्हें यह नहीं पता कि इसका उपयोग कैसे किया जाए। मुझे उम्मीद है कि यह लेख उपयोगकर्ताओं को इस बेहतरीन टूल से निपटने में मदद करेगा।
यह लेख गिलाउम लेलर्ज द्वारा अंडरस्टैंडिंग एक्सप्लेन का लेखक संशोधन है। चूंकि मुझसे कुछ जानकारी छूट गई है, इसलिए मैं आपको मूल जानकारी से परिचित कराने की अत्यधिक अनुशंसा करता हूं।
शैतान उतना काला नहीं है जितना उसे चित्रित किया गया है
प्रश्नों को अनुकूलित करने के लिए PostgreSQL कर्नेल के तर्क को समझना महत्वपूर्ण है। मैं समझाने की कोशिश करूंगा। यह वास्तव में उतना जटिल नहीं है।
EXPLAIN आवश्यक जानकारी प्रदर्शित करता है जो बताता है कि कर्नेल प्रत्येक विशिष्ट क्वेरी के लिए क्या करता है।
आइए एक नज़र डालते हैं कि EXPLAIN कमांड क्या प्रदर्शित करता है और समझें कि PostgreSQL के अंदर वास्तव में क्या होता है। आप इस जानकारी को PostgreSQL 9.2 और उच्चतर संस्करणों पर लागू कर सकते हैं।
हमारे कार्य:
- EXPLAIN कमांड के आउटपुट को पढ़ना और समझना सीखें
- समझें कि क्वेरी निष्पादित होने पर PostgreSQL में क्या होता है
पहले चरण
हम एक टेस्ट टेबल पर लाखों पंक्तियों के साथ अभ्यास करेंगे।
CREATE TABLE foo (c1 integer, c2 text); INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 1000000) AS i;
डेटा पढ़ने की कोशिश करें
EXPLAIN SELECT * FROM foo;
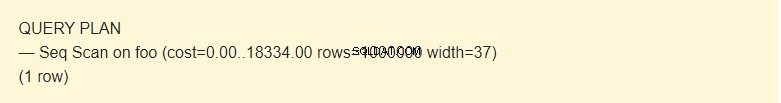
तालिका से डेटा को कई तरीकों से पढ़ना संभव है। हमारे मामले में, EXPLAIN सूचित करता है कि एक Seq स्कैन का उपयोग किया जाता है - एक अनुक्रमिक, ब्लॉक-दर-ब्लॉक, फू टेबल डेटा पढ़ें।
लागत क्या है ?
खैर, यह एक समय नहीं है, बल्कि एक अवधारणा है जिसे एक ऑपरेशन की लागत का अनुमान लगाने के लिए डिज़ाइन किया गया है। पहला मान 0.00 पहली पंक्ति प्राप्त करने की लागत है। दूसरा मान 18334.00 सभी पंक्तियों को प्राप्त करने की लागत है।
पंक्तियां जब एक Seq स्कैन ऑपरेशन किया जाता है, तो पंक्तियों की अनुमानित संख्या वापस आ जाती है। अनुसूचक इस मान को लौटाता है। मेरे मामले में, यह तालिका में पंक्तियों की वास्तविक संख्या से मेल खाता है।
चौड़ाई बाइट्स में एक पंक्ति का औसत आकार है।
आइए 10 पंक्तियों को जोड़ने का प्रयास करें।
INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 10) AS i; EXPLAIN SELECT * FROM foo;

पंक्तियों का मान नहीं बदला गया है। तालिका के आँकड़े पुराने हैं। आँकड़ों को अद्यतन करने के लिए, ANALYZE कमांड को कॉल करें।
अब, पंक्तियाँ पंक्तियों की सही संख्या प्रदर्शित करें।
विश्लेषण करते समय क्या होता है?
- अनियमित रूप से, कई पंक्तियों का चयन किया जाता है और तालिका से पढ़ा जाता है।
- प्रत्येक कॉलम द्वारा मूल्यों के आंकड़े एकत्र किए जाते हैं।
ANALYZE द्वारा पढ़ी गई पंक्तियों की संख्या default_statistics_target पैरामीटर पर निर्भर करती है।
वास्तविक डेटा
EXPLAIN कमांड के आउटपुट में हमने ऊपर जो कुछ भी देखा, वह वही है जो प्लानर को मिलने की उम्मीद है। आइए वास्तविक डेटा पर परिणामों के साथ उनकी तुलना करने का प्रयास करें। ऐसा करने के लिए, EXPLAIN (विश्लेषण) का उपयोग करें।
EXPLAIN (ANALYZE) SELECT * FROM foo;

ऐसी क्वेरी वास्तव में की जाएगी। इसलिए, यदि आप INSERT, DELETE, या UPDATE स्टेटमेंट के लिए EXPLAIN (ANALYZE) निष्पादित करते हैं, तो आपका डेटा बदल जाएगा। ध्यान से! इन मामलों में, रोलबैक कमांड का उपयोग करें।
कमांड निम्नलिखित अतिरिक्त पैरामीटर प्रदर्शित करता है:
- वास्तविक समय क्रमशः पहली पंक्ति और सभी पंक्तियों को प्राप्त करने के लिए खर्च किए गए मिलीसेकंड में वास्तविक समय है।
- पंक्तियां Seq स्कैन के साथ प्राप्त पंक्तियों की वास्तविक संख्या है।
- लूप वह संख्या है, जितनी बार Seq स्कैन ऑपरेशन करना पड़ा।
- कुल रनटाइम क्वेरी निष्पादन का कुल समय है।
आगे पढ़ना:
PostgreSQL में क्वेरी ऑप्टिमाइज़ेशन। मूल बातें समझाएं - भाग 2
PostgreSQL में क्वेरी ऑप्टिमाइज़ेशन। मूल बातें समझाएं - भाग 3