अपने पिछले लेख में, हमने EXPLAIN कमांड की बुनियादी बातों का वर्णन करना शुरू किया और विश्लेषण किया कि किसी क्वेरी को निष्पादित करते समय PostgreSQL में क्या होता है।
मैं PostgreSQL में EXPLAIN की मूल बातें लिखना जारी रखूंगा। जानकारी गिलाउम लेलर्ज द्वारा अंडरस्टैंडिंग एक्सप्लेन की एक संक्षिप्त समीक्षा है। मैं मूल पढ़ने की अत्यधिक अनुशंसा करता हूं क्योंकि कुछ जानकारी छूट गई है।
कैश
हमारी क्वेरी को क्रियान्वित करते समय भौतिक स्तर पर क्या होता है? आइए इसका पता लगाते हैं। मैंने अपने सर्वर को Ubuntu 13.10 पर परिनियोजित किया और OS स्तर के डिस्क कैश का उपयोग किया।
मैं PostgreSQL को रोकता हूं, फ़ाइल सिस्टम में परिवर्तन करता हूं, कैश साफ़ करता हूं, और PostgreSQL चलाता हूं:
> sudo service postgresql-9.3 stop > sudo sync > sudo su - # echo 3 > /proc/sys/vm/drop_caches # exit > sudo service postgresql-9.3 start
जब कैशे साफ़ हो जाए, तो क्वेरी को BUFFERS विकल्प के साथ चलाएँ
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

हम ब्लॉक द्वारा तालिका पढ़ते हैं। कैश खाली है। डिस्क से पूरी तालिका को पढ़ने के लिए हमें 8334 ब्लॉकों तक पहुंचना था।
बफ़र्स:साझा पठन डिस्क से PostgreSQL द्वारा पढ़े जाने वाले ब्लॉकों की संख्या है।
पिछली क्वेरी चलाएँ
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

बफ़र्स:साझा हिट PostgreSQL कैश से पुनर्प्राप्त किए गए ब्लॉक की संख्या है।
प्रत्येक क्वेरी के साथ, PostgreSQL कैश से अधिक से अधिक डेटा लेता है, इस प्रकार, अपना स्वयं का कैश भरता है।
कैश रीड ऑपरेशंस डिस्क रीड ऑपरेशंस की तुलना में तेज़ हैं। आप कुल रनटाइम मान को ट्रैक करके इस प्रवृत्ति को देख सकते हैं।
कैश संग्रहण आकार को postgresql.conf फ़ाइल में साझा_बफ़र्स स्थिरांक द्वारा परिभाषित किया गया है।
कहां
क्वेरी में शर्त जोड़ें
EXPLAIN SELECT * FROM foo WHERE c1 > 500;
मेज पर कोई अनुक्रमणिका नहीं हैं। क्वेरी निष्पादित करते समय, तालिका के प्रत्येक रिकॉर्ड को क्रमिक रूप से स्कैन किया जाता है (Seq स्कैन) और c1> 500 स्थिति के साथ तुलना की जाती है। यदि शर्त पूरी होती है, तो रिकॉर्ड को परिणाम में जोड़ दिया जाता है। अन्यथा, इसे त्याग दिया जाता है। फ़िल्टर इस व्यवहार को इंगित करता है, साथ ही लागत मूल्य बढ़ता है।
पंक्तियों की अनुमानित संख्या घट जाती है।
मूल लेख बताता है कि लागत यह मान क्यों लेती है, और पंक्तियों की अनुमानित संख्या की गणना कैसे की जाती है।
इंडेक्स बनाने का समय आ गया है।
CREATE INDEX ON foo(c1); EXPLAIN SELECT * FROM foo WHERE c1 > 500;

पंक्तियों की अनुमानित संख्या बदल गई है। सूचकांक के बारे में क्या?
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

1 मिलियन से अधिक की केवल 510 पंक्तियों को फ़िल्टर किया जाता है। PostgreSQL को तालिका के 99.9% से अधिक पढ़ना पड़ा।
हम Seq स्कैन को अक्षम करके अनुक्रमणिका का उपयोग करने के लिए बाध्य करेंगे:
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

इंडेक्स स्कैन और इंडेक्स कोंड में, फ़िल्टर के बजाय foo_c1_idx इंडेक्स का उपयोग किया जाता है।
संपूर्ण तालिका का चयन करते समय, अनुक्रमणिका का उपयोग करने से क्वेरी निष्पादित करने की लागत और समय बढ़ जाएगा।
Seq स्कैन सक्षम करें:
SET enable_seqscan TO on;
क्वेरी संशोधित करें:
EXPLAIN SELECT * FROM foo WHERE c1 < 500;
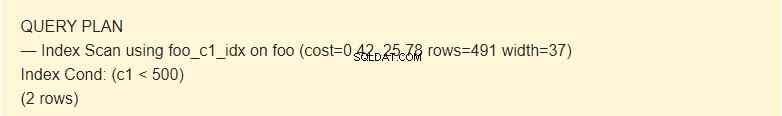
यहां योजनाकार सूचकांक का उपयोग करता है।
अब, टेक्स्ट फ़ील्ड जोड़कर मान को जटिल बनाते हैं।
EXPLAIN SELECT * FROM foo
WHERE c1 < 500 AND c2 LIKE 'abcd%';

जैसा कि आप देख सकते हैं, c1 <500 के लिए foo_c1_idx अनुक्रमणिका का उपयोग किया जाता है। c2 ~~ 'abcd%'::text करने के लिए, फ़िल्टर का उपयोग करें।
यह ध्यान दिया जाना चाहिए कि LIKE ऑपरेटर के POSIX प्रारूप का उपयोग परिणामों के आउटपुट में किया जाता है। यदि स्थिति में केवल टेक्स्ट फ़ील्ड है:
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Seq स्कैन लागू किया जाता है।
c2 द्वारा अनुक्रमणिका बनाएँ:
CREATE INDEX ON foo(c2); EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

अनुक्रमणिका लागू नहीं है क्योंकि परीक्षण फ़ील्ड के लिए मेरा डेटाबेस UTF-8 एन्कोडिंग का उपयोग करता है।
अनुक्रमणिका बनाते समय, text_pattern_ops ऑपरेटर के वर्ग को निर्दिष्ट करना आवश्यक है:
CREATE INDEX ON foo(c2 text_pattern_ops); EXPLAIN SELECT * FROM foo WHERE c2 LIKE 'abcd%';

महान! यह काम कर गया!
बिटमैप इंडेक्स स्कैन हमें आवश्यक रिकॉर्ड निर्धारित करने के लिए foo_c2_idx1 इंडेक्स का उपयोग करता है। फिर, PostgreSQL यह सुनिश्चित करने के लिए तालिका (बिटमैप हीप स्कैन) पर जाता है कि ये रिकॉर्ड वास्तव में मौजूद हैं। यह व्यवहार PostgreSQL के संस्करण को संदर्भित करता है।
यदि आप पूरी पंक्ति के बजाय केवल उस फ़ील्ड का चयन करते हैं, जिस पर अनुक्रमणिका बनी है:
EXPLAIN SELECT c1 FROM foo WHERE c1 < 500;

इंडेक्स स्कैन की तुलना में इंडेक्स ओनली स्कैन तेजी से किया जाएगा, इस तथ्य के कारण कि तालिका की पंक्ति को पढ़ना आवश्यक नहीं है:चौड़ाई =4।
निष्कर्ष
- Seq स्कैन पूरी तालिका पढ़ता है
- इंडेक्स स्कैन WHERE स्टेटमेंट के लिए इंडेक्स का उपयोग करता है और पंक्तियों का चयन करते समय टेबल को पढ़ता है
- बिटमैप इंडेक्स स्कैन तालिका के माध्यम से इंडेक्स स्कैन और चयन नियंत्रण का उपयोग करता है। बड़ी संख्या में पंक्तियों के लिए प्रभावी।
- केवल अनुक्रमणिका स्कैन सबसे तेज़ ब्लॉक है, जो केवल अनुक्रमणिका को पढ़ता है।
आगे पढ़ना:
PostgreSQL में क्वेरी ऑप्टिमाइज़ेशन। मूल बातें समझाएं - भाग 3