मैं PostgreSQL में EXPLAIN की मूल बातों पर लेखों की एक श्रृंखला जारी रखता हूं, जो कि Guillaume Lelarge द्वारा अंडरस्टैंडिंग EXPLAIN की एक छोटी समीक्षा है।
इस मुद्दे को बेहतर ढंग से समझने के लिए, मैं Guillaume Lelarge द्वारा मूल "ExPLAIN को समझना" की समीक्षा करने की अत्यधिक अनुशंसा करता हूं और मेरा पहला और दूसरा लेख पढ़ें।
आदेश दें
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

सबसे पहले, आप foo तालिका के अनुक्रमिक स्कैन (Seq स्कैन) को निष्पादित करते हैं और फिर, सॉर्टिंग (सॉर्ट) करते हैं। EXPLAIN कमांड का -> चिह्न चरणों (नोड) के पदानुक्रम को इंगित करता है। पहले चरण को निष्पादित किया जाता है, उसके पास उतना ही बड़ा इंडेंट होता है।
सॉर्ट कुंजी सॉर्ट करने की एक शर्त है।
सॉर्ट करने की विधि:एक्सटर्नल मर्ज डिस्क पर 4592 kB की क्षमता वाली एक अस्थायी फ़ाइल को सॉर्ट करते समय उपयोग किया जाता है।
बफ़र्स विकल्प के साथ जांचें:
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;
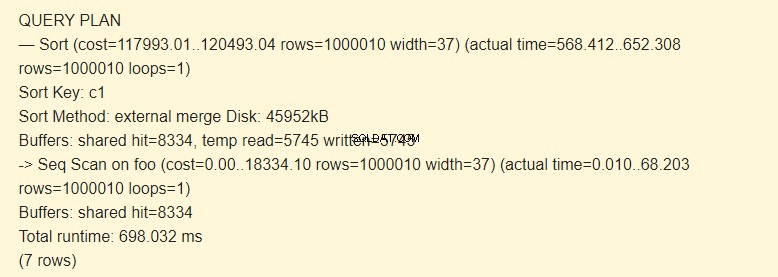
दरअसल, अस्थायी पढ़ने =5745 लिखित =5745 लाइन का मतलब है कि 45960 केबी (प्रत्येक 8 केबी के 5745 ब्लॉक) अस्थायी फ़ाइल में संग्रहीत और पढ़े गए थे। 8334 ब्लॉक के साथ संचालन कैश में निष्पादित किया गया।
फ़ाइल सिस्टम के साथ संचालन RAM में संचालन की तुलना में धीमा है।
आइए वर्क_मेम की मेमोरी क्षमता बढ़ाने की कोशिश करें:
SET work_mem TO '200MB'; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

सॉर्ट विधि:क्विकॉर्ट मेमोरी:102702kB - संपूर्ण सॉर्टिंग RAM में निष्पादित की गई थी।
इंडेक्स इस प्रकार है:
CREATE INDEX ON foo(c1); EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

हमारे पास केवल इंडेक्स स्कैन रह गया है, जिसने क्वेरी की गति को महत्वपूर्ण रूप से प्रभावित किया है।
सीमा
पहले बनाई गई अनुक्रमणिका हटाएं:
DROP INDEX foo_c2_idx1; EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%';
जैसी अपेक्षित थी, Seq स्कैन और फ़िल्टर का उपयोग किया जाता है।
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%' LIMIT 10;

Seq स्कैन तालिका की पंक्तियों को पढ़ता है और स्थिति के साथ उनकी (फ़िल्टर) तुलना करता है। जैसे ही 10 रिकॉर्ड इस शर्त को पूरा करते हैं, स्कैन समाप्त हो जाएगा। हमारे मामले में, 10 परिणाम पंक्तियाँ प्राप्त करने के लिए, हमें पूरी तालिका के बजाय केवल 3063 रिकॉर्ड्स को पढ़ना पड़ा। इस संख्या की 3053 पंक्तियों को अस्वीकार कर दिया गया था (फ़िल्टर द्वारा हटाई गई पंक्तियाँ)।
अनुक्रमणिका स्कैन के साथ भी ऐसा ही होता है।
शामिल हों
एक नई तालिका बनाएं और उसके लिए आंकड़े तैयार करें:
CREATE TABLE bar (c1 integer, c2 boolean); INSERT INTO bar SELECT i, i%2=1 FROM generate_series(1, 500000) AS i; ANALYZE bar;
दो तालिकाओं के लिए क्वेरी इस प्रकार है:
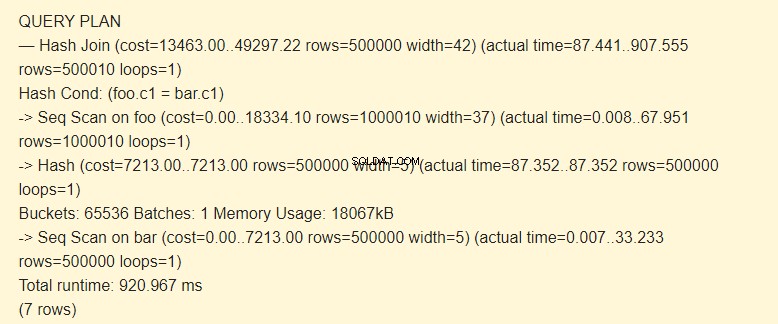
EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;
सबसे पहले, अनुक्रमिक स्कैन (Seq स्कैन) बार तालिका को पढ़ता है। प्रत्येक पंक्ति के लिए एक हैश (हैश) की गणना की जाती है।
फिर, यह foo तालिका को स्कैन करता है, और प्रत्येक पंक्ति के लिए, एक हैश की गणना की जाती है जिसकी हैश कंडीशन द्वारा बार तालिका के हैश के साथ तुलना (हैश जॉइन) की जाती है। यदि वे मेल खाते हैं, तो एक परिणामी स्ट्रिंग आउटपुट होती है।
बार के लिए हैश स्टोर करने के लिए 18067kB मेमोरी का उपयोग किया जाता है।
अनुक्रमणिका जोड़ें:
CREATE INDEX ON bar(c1); EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;

हैश का अब उपयोग नहीं किया जाता है। दोनों तालिकाओं के सूचकांकों पर शामिल हों और अनुक्रमणिका स्कैन को मिलाएं, प्रदर्शन में काफी सुधार होता है।
बाएं शामिल हों:
EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
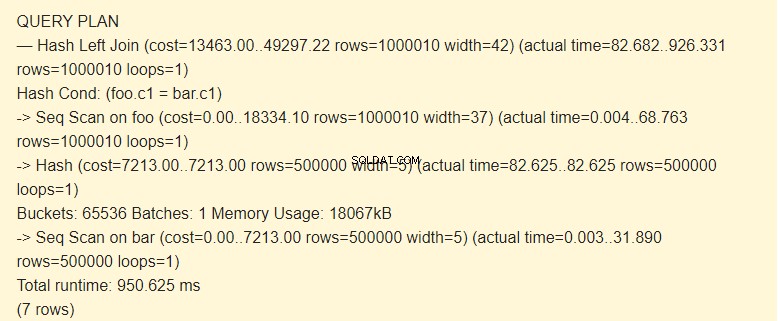
सेक स्कैन?
आइए देखें कि यदि हम Seq स्कैन को अक्षम कर देते हैं तो हमें क्या परिणाम प्राप्त होंगे।
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

शेड्यूलर के अनुसार, हैश का उपयोग करने की तुलना में इंडेक्स का उपयोग करना अधिक महंगा है। यह पर्याप्त मात्रा में आवंटित स्मृति के साथ संभव है। क्या आपको याद है कि हम वर्क_मेम बढ़ा रहे हैं?
हालांकि, अगर आपके पास पर्याप्त मेमोरी नहीं है, तो शेड्यूलर अलग तरह से व्यवहार करेगा:
SET work_mem TO '15MB'; SET enable_seqscan TO ON; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

यदि हम अनुक्रमणिका स्कैन को अक्षम कर देते हैं, तो EXPLAIN क्या परिणाम प्रदर्शित करेगा?
SET work_mem TO '15MB'; SET enable_indexscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
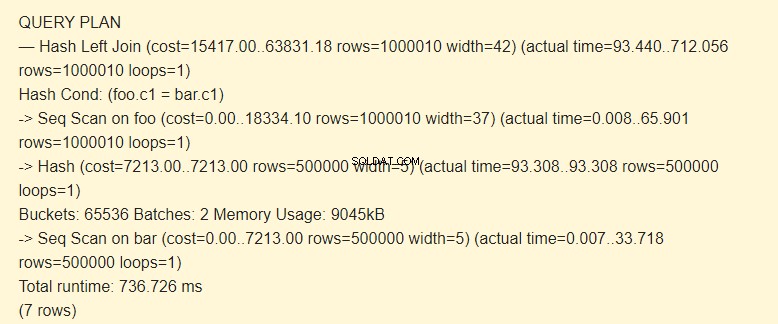
बैच:2 की लागत बढ़ गई है। पूरा हैश स्मृति में फिट नहीं हुआ; हमें इसे 9045kB के दो पैकेजों में विभाजित करना पड़ा।
मेरे लेख पढ़ने के लिए धन्यवाद! मुझे आशा है कि वे उपयोगी थे। यदि आपके पास कोई टिप्पणी या प्रतिक्रिया है, तो बेझिझक मुझे बताएं।