पूरा पुनर्लेखन:
;WITH new_grp AS (
SELECT r1.UserId, r1.StartTime
FROM @requests r1
WHERE NOT EXISTS (
SELECT *
FROM @requests r2
WHERE r1.UserId = r2.UserId
AND r2.StartTime < r1.StartTime
AND r2.EndTime >= r1.StartTime)
GROUP BY r1.UserId, r1.StartTime -- there can be > 1
),r AS (
SELECT r.RequestId, r.UserId, r.StartTime, r.EndTime
,count(*) AS grp -- guaranteed to be 1+
FROM @requests r
JOIN new_grp n ON n.UserId = r.UserId AND n.StartTime <= r.StartTime
GROUP BY r.RequestId, r.UserId, r.StartTime, r.EndTime
)
SELECT min(RequestId) AS RequestId
,UserId
,min(StartTime) AS StartTime
,max(EndTime) AS EndTime
FROM r
GROUP BY UserId, grp
ORDER BY UserId, grp
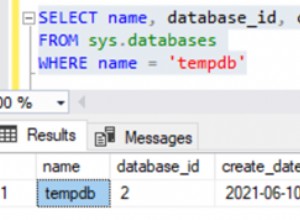
अब अनुरोधित परिणाम देता है और वास्तव में सभी संभावित मामलों को शामिल करता है, जिसमें उप-समूह और डुप्लिकेट शामिल हैं। परीक्षण डेटा पर टिप्पणियों पर एक नज़र डालें data.SE पर कार्यशील डेमो ।
-
सीटीई 1
अद्वितीय (अद्वितीय!) बिंदुओं को समय पर ढूंढें जहां ओवरलैपिंग अंतराल का एक नया समूह शुरू होता है। -
सीटीई 2
नए समूह के प्रारंभ की गणना प्रत्येक व्यक्तिगत अंतराल तक (और शामिल) करें, जिससे प्रति उपयोगकर्ता एक अद्वितीय समूह संख्या बनती है। -
अंतिम चयन
समूहों को मर्ज करें, समूहों के लिए प्रारंभिक शुरुआत और नवीनतम अंत लें।
मुझे कुछ कठिनाई का सामना करना पड़ा, क्योंकि टी-एसक्यूएल विंडो कार्य करती है max() या sum() ORDER BY स्वीकार न करें एक विंडो में क्लॉज। वे प्रति विभाजन केवल एक मान की गणना कर सकते हैं, जिससे प्रति विभाजन चल रहे योग/गणना की गणना करना असंभव हो जाता है। PostgreSQL या Oracle में काम करेगा (लेकिन निश्चित रूप से MySQL में नहीं - इसमें न तो विंडो फ़ंक्शन हैं और न ही CTE)।
अंतिम समाधान एक अतिरिक्त सीटीई का उपयोग करता है और उतना ही तेज़ होना चाहिए।