इसी विषय पर अन्य स्टैक ओवरफ्लो चर्चाएं हैं (नीचे लिंक)। जैसा कि ऊपर की टिप्पणियों में उल्लेख किया गया है, इसका इंडेक्स और ऑप्टिमाइज़र के भ्रमित होने और गलत का उपयोग करने से कुछ लेना-देना हो सकता है।
मेरा पहला विचार यह है कि आप (सेलेक्ट *....) से चुनिंदा टॉप सर्विस आईडी कर रहे हैं और ऑप्टिमाइज़र को क्वेरी को आंतरिक प्रश्नों तक धकेलने और इंडेक्स का उपयोग करने में कठिनाई हो सकती है।
इसे फिर से लिखने पर विचार करें
select top 10 ServiceRequestID
from big_table_1
inner join big_table_2 cap2
on cap1.servicerequestid = cap2.customerreferencenumber
and big_table_1.statusid = 2
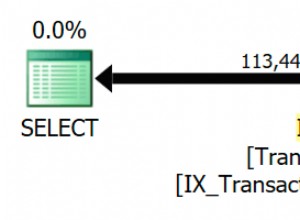
आपकी क्वेरी में, डेटाबेस शायद परिणामों को मर्ज करने और उन्हें वापस करने का प्रयास कर रहा है और फिर इसे बाहरी क्वेरी में शीर्ष 10 तक सीमित कर देता है। उपरोक्त क्वेरी में डेटाबेस को केवल पहले 10 परिणामों को इकट्ठा करना होगा क्योंकि परिणाम मर्ज किए जा रहे हैं, जिससे समय की बचत होती है। और अगर servicerequestID अनुक्रमित है, तो इसका उपयोग करना सुनिश्चित होगा। आपके उदाहरण में, क्वेरी एक परिणाम सेट में servicerequestid कॉलम की तलाश कर रही है जो पहले से ही वर्चुअल, अनइंडेक्स किए गए प्रारूप में लौटाया जा चुका है।
आशा है कि यह समझ में आता है। जबकि काल्पनिक रूप से ऑप्टिमाइज़र को जो भी प्रारूप हम एसक्यूएल में डालते हैं और हर बार मूल्यों को वापस करने का सबसे अच्छा तरीका समझते हैं, सच्चाई यह है कि जिस तरह से हम अपने एसक्यूएल को एक साथ रखते हैं वह वास्तव में उस क्रम को प्रभावित कर सकता है जिसमें कुछ कदम किए जाते हैं डीबी.
सेलेक्ट टॉप धीमा है, ऑर्डर BY पर ध्यान दिए बिना
SQL सर्वर में इंडेक्स किए गए कॉलम पर टॉप(1) क्यों धीमा कर रहा है?