मैं tempdb के बारे में वही सिफारिशें कर रहा हूं क्योंकि मैंने 15 साल पहले SQL सर्वर के साथ काम करना शुरू किया था, जब मैं संस्करण 2000 चलाने वाले ग्राहकों के साथ काम कर रहा था। इसका सार:एक ही ऑटो के साथ एक ही आकार की कई डेटा फाइलें बनाएं -ग्रोथ सेटिंग्स, ट्रेस फ्लैग 1118 (और शायद 1117) को सक्षम करें, और अपने tempdb उपयोग को कम करें। ग्राहक की ओर से, SQL सर्वर 2019 तक क्या किया जा सकता है* की यही सीमा रही है।
*कुछ अतिरिक्त कोडिंग अनुशंसाएं हैं जिन पर पाम लाहौद ने अपनी बहुत ही जानकारीपूर्ण पोस्ट, TEMPDB - फ़ाइलें और ट्रेस फ़्लैग्स और अपडेट, ओह माय! में चर्चा की है।
मुझे जो दिलचस्प लगता है, वह यह है कि इतने समय के बाद भी, tempdb अभी भी एक समस्या है। SQL सर्वर टीम ने पिछले कुछ वर्षों में समस्याओं को कम करने और कम करने के लिए कई बदलाव किए हैं, लेकिन दुरुपयोग जारी है। SQL सर्वर टीम द्वारा नवीनतम अनुकूलन tempdb के लिए सिस्टम टेबल (मेटाडेटा) को इन-मेमोरी OLTP (उर्फ मेमोरी-ऑप्टिमाइज़्ड) में ले जा रहा है। SQL सर्वर 2019 रिलीज़ नोट्स में कुछ जानकारी उपलब्ध है, और PASS समिट कीनोट के पहले दिन के दौरान बॉब वार्ड और कॉनर कनिंघम का एक डेमो था। पाम लाहौद ने अपने पास शिखर सम्मेलन के सामान्य सत्र में एक त्वरित डेमो भी किया। अब जबकि 2019 CTP 3.2 बाहर हो गया है, मुझे लगा कि यह समय खुद को परखने का है।
सेटअप
मेरे पास मेरी वर्चुअल मशीन पर SQL Server 2019 CTP 3.2 स्थापित है, जिसमें 8GB मेमोरी (अधिकतम सर्वर मेमोरी 6 GB पर सेट है) और 4 vCPU हैं। मैंने चार (4) tempdb डेटा फ़ाइलें बनाईं, जिनमें से प्रत्येक का आकार 1GB है।
मैंने वाइडवर्ल्ड इम्पोर्टर्स की एक प्रति को पुनर्स्थापित किया और फिर तीन संग्रहीत कार्यविधियाँ (नीचे परिभाषाएँ) बनाईं। प्रत्येक संग्रहीत कार्यविधि एक दिनांक इनपुट स्वीकार करती है, और उस दिनांक के लिए Sales.Order और Sales.OrderLines से सभी पंक्तियों को अस्थायी ऑब्जेक्ट में धकेलती है। Sales.usp_OrderInfoTV में ऑब्जेक्ट एक तालिका चर है, Sales.usp_OrderInfoTT में ऑब्जेक्ट एक अस्थायी तालिका है जिसे SELECT… INTO के माध्यम से परिभाषित किया गया है, बाद में एक गैर-क्लस्टर जोड़ा गया है, और Sales.usp_OrderInfoTTALT में ऑब्जेक्ट एक पूर्व-निर्धारित अस्थायी तालिका है जिसे तब बदल दिया जाता है। एक अतिरिक्त कॉलम रखने के लिए। डेटा को अस्थायी ऑब्जेक्ट में जोड़ने के बाद, उस ऑब्जेक्ट के विरुद्ध एक चयन कथन होता है जो Sales.Customers तालिका में शामिल होता है।
/* संग्रहीत कार्यविधियाँ बनाएँ */ उपयोग करें [WideWorldImporters]; GO DROP प्रक्रिया यदि मौजूद है Sales.usp_OrderInfoTV जाओ प्रक्रिया बनाएँ Sales.usp_OrderInfoTV @OrderDate दिनांक के रूप में प्रारंभ घोषणा @OrdersInfo तालिका (ऑर्डरआईडी INT, OrderLineID INT, CustomerID INT, StockItemID INT, मात्रा दिष्ट, इकाई) इकाई; INSERT INTO @OrdersInfo (OrderID, OrderLineID, CustomerID, StockItemID, Quantity, UnitPrice, OrderDate) o.OrderID, ol.OrderLineID, o.CustomerID, ol.StockItemID, ol.Quantity, ol.UnitPrice, OrderDate FROM Sales.Orders का चयन करें। INNER JOIN Sales.OrderLines ol ON o.OrderID =ol.OrderID जहां o.OrderDate =@OrderDate; चुनें o.OrderID, c.CustomerName, SUM (o.Quantity), SUM (o.UnitPrice) @OrdersInfo से o JOIN Sales.Customers c ON o.CustomerID =c.CustomerID GROUP BY o.OrderID, c.CustomerName; END GO DROP प्रक्रिया यदि मौजूद है, Sales.usp_OrderInfoTT GO CREATE PROCEDURE Sales.usp_OrderInfoTT @OrderDate DATE को प्रारंभ चुनें o.OrderID, ol.OrderLineID, o.CustomerID, ol.StockItemID, ol.UnitPrice, OrderDate INTO #. Sales.Orders o INNER JOIN Sales.OrderLines ol ON o.OrderID =ol.OrderID जहां o.OrderDate =@OrderDate; चुनें o.OrderID, c.CustomerName, SUM (o.Quantity), SUM (o.UnitPrice) #temporderinfo से o JOIN Sales.Customers c ON o.CustomerID =c.CustomerID GROUP BY o.OrderID, c.CustomerName END GO ड्रॉप प्रक्रिया अगर मौजूद है Sales.usp_OrderInfoTTALT GO CREATE PROCEDURE Sales.usp_OrderInfoTTALT @OrderDate दिनांक जैसे प्रारंभ तालिका #temporderinfo (orderID INT, OrderLineID INT, CustomerID INT, StockItemID INT, मात्रा दशमलव, यूनिट)); #temporderinfo (OrderID, OrderLineID, CustomerID, StockItemID, मात्रा, UnitPrice) में INSERT करें o.OrderID, ol.OrderLineID, o.CustomerID, ol.StockItemID, ol.Quantity, ol.UnitPrice FROM Sales.Orders o INNER सेलेक्ट करें। ऑर्डरलाइन ओएल ऑन ओ। ऑर्डरआईडी =ओएल। ऑर्डर आईडी जहां ओ। ऑर्डरडेट =@ ऑर्डरडेट; चुनें o.OrderID, c.CustomerName, SUM (o.Quantity), SUM (o.UnitPrice) #temporderinfo से o JOIN Sales.Customers c ON o.CustomerID c.CustomerID GROUP BY o.OrderID, c.CustomerName END GO / * परीक्षण डेटा रखने के लिए टेबल बनाएं */ उपयोग करें [वाइडवर्ल्ड इम्पोर्टर्स]; जाओ टेबल बनाएं [डीबीओ]। टेबल बनाएं [डीबीओ]। [PerfTesting_WaitStats] ([टेस्टआईडी] [int] न्यूल नहीं, [कैप्चरडेट] [डेटाटाइम] न्यूल डिफॉल्ट नहीं (sysdatetime ()), [वेट टाइप] [nvarchar] (60) न्यूल नहीं, [Wait_S] [दशमलव] (16, 2) NULL, [Resource_S] [दशमलव] (16, 2) NULL, [Signal_S] [दशमलव] (16, 2) NULL, [वेटकाउंट] [बिगिन्ट] NULL, [प्रतिशत] [दशमलव] (5, 2) NULL, [AvgWait_S] [दशमलव] (16, 4) NULL, [AvgRes_S] [दशमलव] (16, 4) NULL, [AvgSig_S] [दशमलव] (16, 4) NULL) ऑन [प्राथमिक]; GO /* क्वेरी स्टोर सक्षम करें (परीक्षण सेटिंग्स, ठीक वैसा नहीं जैसा मैं उत्पादन के लिए सुझाऊंगा) */ USE [मास्टर]; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE =ON; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE ( OPERATION_MODE =READ_WRITE, CLEANUP_POLICY =(STALE_QUERY_THRESHOLD_DAYS =30), DATA_FLUSH_INTERVAL_SECONDS =600, INTERVAL_LENGTH_MINUTES =10, MAX_STORAGE_SIZE_MB =1024, QUERY_CAPTURE_MODE =AUTO, SIZE_BASED_CLEANUP_MODE =AUTO); जाओ
परीक्षण
SQL सर्वर 2019 के लिए डिफ़ॉल्ट व्यवहार यह है कि tempdb मेटाडेटा स्मृति-अनुकूलित नहीं है, और हम sys.configurations की जाँच करके इसकी पुष्टि कर सकते हैं:
चुनें * sys.configurations से जहां कॉन्फ़िगरेशन_आईडी =1589;

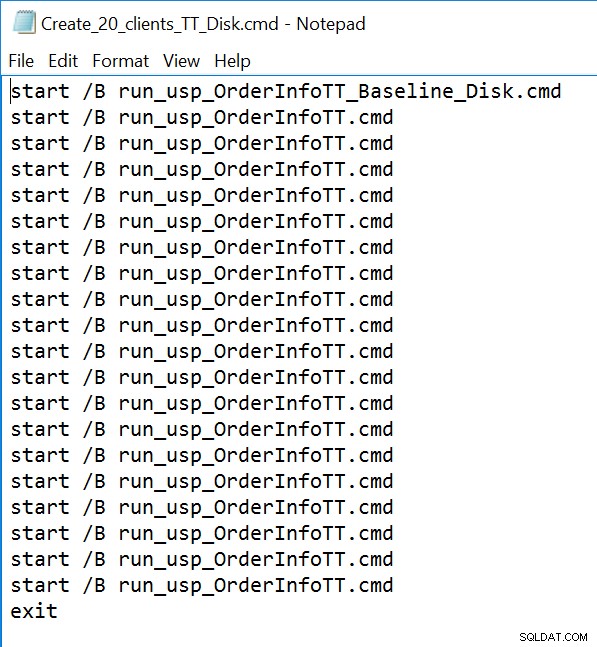
सभी तीन संग्रहीत प्रक्रियाओं के लिए हम दो अलग-अलग .sql फ़ाइलों में से एक को चलाने वाले 20 समवर्ती धागे उत्पन्न करने के लिए sqlcmd का उपयोग करेंगे। पहली .sql फ़ाइल, जो 19 थ्रेड्स द्वारा उपयोग की जाएगी, प्रक्रिया को 1000 बार लूप में निष्पादित करेगी। दूसरी .sql फ़ाइल, जिसमें केवल एक (1) थ्रेड होगा, प्रक्रिया को लूप में 3000 बार निष्पादित करेगा। फ़ाइल में रुचि के दो मीट्रिक कैप्चर करने के लिए TSQL भी शामिल है:कुल अवधि और प्रतीक्षा आँकड़े। प्रक्रिया के लिए औसत अवधि को कैप्चर करने के लिए हम क्वेरी स्टोर का उपयोग करेंगे।
/* पहली .sql फ़ाइल का उदाहरण जो SP को 1000 बार कॉल करता है */ SET NOCOUNT ON; उपयोग करें [वाइडवर्ल्ड इम्पोर्टर्स]; GO DECLARE @StartDate DATE; घोषणा @MaxDate दिनांक; DECLARE @Date DATE; घोषणा @ काउंटर INT =1; [वाइडवर्ल्ड इम्पोर्टर्स] से @StartDATE =MIN (ऑर्डरडेट) चुनें। [सेल्स]। [ऑर्डर]; [वाइडवर्ल्ड इम्पोर्टर्स] से @MaxDATE =MAX (ऑर्डरडेट) चुनें। [बिक्री]। [ऑर्डर]; सेट @ दिनांक =@ प्रारंभ दिनांक; जबकि @ काउंटर <=1000 EXEC [बिक्री] शुरू करें। [usp_OrderInfoTT] @Date; IF @Date <=@MaxDate BEGIN SET @Date =DATEADD(DAY, 1, @Date); END ELSE BEGIN SET @Date =@StartDate; अंत सेट @ काउंटर =@ काउंटर + 1; END GO /* दूसरी .sql फ़ाइल का उदाहरण जो SP को 3000 बार कॉल करता है और कुल अवधि को कैप्चर करता है और आँकड़ों की प्रतीक्षा करता है */ सेट NOCOUNT ON; उपयोग करें [वाइडवर्ल्ड इम्पोर्टर्स]; GO DECLARE @StartDate DATE; घोषणा @MaxDate दिनांक; DECLARE @DATE DATE; घोषणा @ काउंटर INT =1; DECLARE @TestID INT; DECLARE @TestName VARCHAR(200) ='usp_OrderInfoTT का निष्पादन - डिस्क आधारित सिस्टम टेबल्स'; [WideWorldImporters].[dbo].[PerfTesting_Tests] ([TestName]) VALUES (@TestName); [वाइडवर्ल्ड इम्पोर्टर्स] से @TestID =MAX (TestID) चुनें। [dbo]। [PerfTesting_Tests]; [वाइडवर्ल्ड इम्पोर्टर्स] से @StartDATE =MIN (ऑर्डरडेट) चुनें। [सेल्स]। [ऑर्डर]; [वाइडवर्ल्ड इम्पोर्टर्स] से @MaxDATE =MAX (ऑर्डरडेट) चुनें। [बिक्री]। [ऑर्डर]; सेट @ दिनांक =@ प्रारंभ दिनांक; अगर मौजूद है (चुनें * से [tempdb]। [sys]। [ऑब्जेक्ट्स] जहां [नाम] =N'##SQLskillsStats1') ड्रॉप टेबल [##SQLskillsStats1]; यदि मौजूद है (चुनें * से [tempdb]। [sys]। [ऑब्जेक्ट्स] जहां [नाम] =N'##SQLskillsStats2') ड्रॉप टेबल [##SQLskillsStats2]; sys.dm_os_wait_stats से ##SQLskillsStats1 में [wait_type], [waiting_tasks_count], [wait_time_ms], [max_wait_time_ms], [signal_wait_time_ms] को चुनें; /* प्रारंभ समय सेट करें */ अद्यतन करें [वाइडवर्ल्ड आयातक]। जबकि @ काउंटर <=3000 EXEC [बिक्री] शुरू करें। [usp_OrderInfoTT] @Date; IF @Date <=@MaxDate BEGIN SET @Date =DATEADD(DAY, 1, @Date); END ELSE BEGIN SET @Date =@StartDate; END SET @Counter =@Counter + 1 END /* सेट एंड टाइम */ UPDATE [WideWorldImporters].[dbo].[PerfTesting_Tests] SET [TestEndTime] =SYSDATETIME() जहां [TestID] =@TestID; [wait_type], [waiting_tasks_count], [wait_time_ms], [max_wait_time_ms], [signal_wait_time_ms] को sys.dm_os_wait_stats से ##SQLskillsStats2 में चुनें; [DiffWaits] AS के साथ (चुनें - प्रतीक्षा करें जो पहले स्नैपशॉट [ts2] में नहीं थे। [wait_type], [ts2]। [wait_time_ms], [ts2]। [signal_wait_time_ms], [ts2]। [waiting_tasks_count] से [##SQLskillsStats2] के रूप में [ts2] बाएँ बाहरी जॉइन [##SQLskillsStats1] [ts1] पर [ts2] के रूप में। [प्रतीक्षा_प्रकार] =[ts1]। [प्रतीक्षा_प्रकार] जहां [ts1]। ].[wait_time_ms]> 0 UNION SELECT -- दोनों स्नैपशॉट में प्रतीक्षा का अंतर [ts2].[wait_type], [ts2].[wait_time_ms] - [ts1].[wait_time_ms] AS [wait_time_ms], [ts2].[ सिग्नल_वेट_टाइम_एमएस] - [टीएस 1]। [सिग्नल_वेट_टाइम_एमएस] एएस [सिग्नल_वेट_टाइम_एमएस], [टीएस 2]। [वेटिंग_टास्क_काउंट] - [टीएस 1]। SQLskillsStats1] AS [ts1] ऑन [ts2]। t]> 0 और [ts2]। [wait_time_ms] - [ts1]। [wait_time_ms] > 0), [प्रतीक्षा करता है] एएस (चुनें [प्रतीक्षा_प्रकार], [प्रतीक्षा_समय_एमएस] / 1000.0 एएस [प्रतीक्षा करें], ([प्रतीक्षा_समय_एमएस] - [सिग्नल_वेट_टाइम_एमएस]) / 1000.0 एएस [संसाधन], [सिग्नल_वेट_टाइम_एमएस] / 1000.0 एएस [सिग्नलएस], [ वेटिंग_टास्क_काउंट] एएस [वेटकाउंट], 100.0 * [वेट_टाइम_एमएस] / एसयूएम ([वेट_टाइम_एमएस]) ओवर () एएस [प्रतिशत], ROW_NUMBER () ओवर (ऑर्डर बाय [वेट_टाइम_एमएस] डीईएससी) एएस [RowNum] से [DiffWaits_type] जहां से [प्रतीक्षा करें] ] NOT IN (-- ये प्रतीक्षा प्रकार लगभग 100% कभी भी कोई समस्या नहीं हैं और इसलिए उन्हें परिणामों को तिरछा करने से बचने के लिए फ़िल्टर किया जाता है। N'BROKER_EVENTHANDLER', N'BROKER_RECEIVE_WAITFOR', N'BROKER_TASK_STOP', N'BROKER_TO_FLUSH' , N'BROKER_TRANSMITTER', N'CHECKPOINT_QUEUE', N'CHKPT', N'CLR_AUTO_EVENT', N'CLR_MANUAL_EVENT', N'CLR_SEMAPHORE', N'CXCONSUMER', N'DBMIRROR_DBM_EVENT', N'DBMIRROR_DBM_EVENT', N'DBMIRROR_DBM_EVENT', N'DBMIRROR_DBM_EVENT' , N'DBMIRRORING_CMD', N'DIRTY_PAGE_POLL ', एन'DISPATCHER_QUEUE_SEMAPHORE', N'EXECSYNC', N'FSAGENT', N'FT_IFTS_SCHEDULER_IDLE_WAIT', N'FT_IFTSHC_MUTEX', N'HADR_CLUSAPI_CALL', N'HADR_FILESTREAM_'NHADRATION_', N'NUEITLO', N'QUILESTREAM_IOMHADRATION_', N'QUITLO', N'QUILESTREAM_IOMHADRATION_', TIME ', N'HADR_WORK_QUEUE', N'KSOURCE_WAKEUP', N'LAZYWRITER_SLEEP', N'LOGMGR_QUEUE', N'MEMORY_ALLOCATION_EXT', N'ONDEMAND_TASK_QUEUE', N'PARALLEL_REDO_'NPARONCRED_ORKER', N'PARALLEL_REDO_'NPARONCRED_ORKER', N'PARALLEL_REDO_'NPARONCERALL_WORKER', N'PARALLEL_REDO_NTRANCPARAL_WORKER', NTRAALL_DERO_DRAALL'SYREDO_WORKER_LOGYWRITER_SLEEP', N'LOGMGR_QUEUE' ', N'PARALLEL_REDO_WORKER_WAIT_WORK', N'PREEMPTIVE_XE_GETTARGETSTATE', N'PWAIT_ALL_COMPONENTS_INITIALIZED', N'PWAIT_DIRECTLOGCONSUMER_GETNEXT', N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP', N'QDS_ASYNC_QUEUE', N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP', N'QDS_SHUTDOWN_QUEUE', N'REDO_THREAD_PENDING_WORK', N'REQUEST_FOR_DEADLOCK_SEARCH ', N'RESOURCE_QUEUE', N'SERVER_IDLE_CHECK', N'SLEEP_BPOOL_FL USH', N'SLEEP_DBSTARTUP', N'SLEEP_DCOMSTARTUP', N'SLEEP_MASTERDBREADY', N'SLEEP_MASTERMDREADY', N'SLEEP_MASTERUPGRADED', N'SLEEP_MSDBSTARTUP', N'SLEEP_SYSUPLE',TASK', N'SLEEP_SYSUPLE_TASK', N'SLEEP_SYSUPLE_TASK' SNI_HTTP_ACCEPT', N'SOS_WORK_DISPATCHER', N'SP_SERVER_DIAGNOSTICS_SLEEP', N'SQLTRACE_BUFFER_FLUSH', N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP', N'SQLTRACE_WAIT_', NWAIT_', NWAIT_', NWAYFOR', NWIT_ENTRIES', NWIT_ENTRIES', NWIT_ENTRIES', NWIT_ENTRIES', NWIT_ENTRIES', NWIT_ENTRIES', NWIT_ENTI WAIT_XTP_HOST_WAIT', N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG', N'WAIT_XTP_CKPT_CLOSE', N'XE_DISPATCHER_JOIN', N'XE_DISPATCHER_WAIT', N'XE_DISPATCHER_WAIT', N'XE_TIMER_EVENT' INTest ] [WITporters] INSERT. , [Wait_S] , [Resource_S] , [Signal_S] , [WaitCount] , [प्रतिशत] , [AvgWait_S] , [AvgRes_S] , [AvgSig_S] ) CAST @TestID, [W1] चुनें। ([W1]। [प्रतीक्षा करें] डेसीमा के रूप में L (16, 2)) AS [Wait_S], CAST ([W1]। [ResourceS] AS DECIMAL (16, 2)) AS [Resource_S], CAST ([W1]। [SignalS] AS DECIMAL (16, 2) ) AS [Signal_S], [W1]। [WaitCount] AS [WaitCount], CAST ([W1]। [प्रतिशत] दशमलव के रूप में (5, 2)) AS [प्रतिशत], CAST (([W1]। [प्रतीक्षा करें) / [W1]। [WaitCount]) AS DECIMAL (16, 4)) AS [AvgWait_S], CAST (([W1]। [ResourceS] / [W1]। [WaitCount]) AS DECIMAL (16, 4)) AS [AvgRes_S], CAST (([W1]। [SignalS] / [W1]। [WaitCount]) AS DECIMAL (16, 4)) AS [AvgSig_S] FROM [वेट्स] AS [W1] इनर जॉइन [वेट्स] AS [ W2] ऑन [W2]। [RowNum] <=[W1]। [RowNum] ग्रुप बाय [W1]।[RowNum], [W1]। संसाधन एस], [डब्ल्यू 1]। [सिग्नल एस], [डब्ल्यू 1]। [प्रतीक्षा गणना], [डब्ल्यू 1]। [प्रतिशत] योग ([डब्ल्यू 2]। [प्रतिशत]) - [डब्ल्यू 1]। -- प्रतिशत सीमा GO -- क्लीनअप IF EXISTS (चुनें * [tempdb] से। [sys]। [ऑब्जेक्ट्स] जहां [name] =N'##SQLskillsStats1') ड्रॉप टेबल [##SQLskillsStats1]; यदि मौजूद है (चुनें * से [tempdb]। [sys]। [ऑब्जेक्ट्स] जहां [नाम] =N'##SQLskillsStats2') ड्रॉप टेबल [##SQLskillsStats2]; जाओ
कमांड लाइन फ़ाइल का उदाहरण:
परिणाम
प्रत्येक संग्रहीत कार्यविधि के लिए 20 थ्रेड उत्पन्न करने वाली कमांड लाइन फ़ाइलों को निष्पादित करने के बाद, प्रत्येक प्रक्रिया के 12,000 निष्पादन के लिए कुल अवधि की जाँच करने से निम्नलिखित पता चलता है:
[dbo] सेSELECT *, DATEDIFF(SECOND, TestStartTime, TestEndTime) AS [TotalDuration]।[PerfTesting_Tests] ऑर्डर बाय [TestID];

अस्थायी तालिकाओं (usp_OrderInfoTT और usp_OrderInfoTTC) के साथ संग्रहीत कार्यविधियाँ पूर्ण होने में अधिक समय लेती हैं। यदि हम व्यक्तिगत क्वेरी प्रदर्शन को देखें:
चुनें [क्यूएसक्यू]। , [rs]। [avg_duration], [rs]। [avg_logic_io_reads], [qst]। [query_sql_text] [sys] से। .[query_text_id] =[qst]। [query_text_id] [sys] में शामिल हों। [query_store_plan] [qsp] [qsq] पर। चालू [qsp]। usp_OrderInfoTV')) या ([qsq].[object_id] =OBJECT_ID('Sales.usp_OrderInfoTTALT')) [qsq] द्वारा ऑर्डर करें।

हम देख सकते हैं कि usp_OrderInfoTT के लिए SELECT… INTO में औसतन लगभग 28ms लगे (क्वेरी स्टोर में अवधि माइक्रोसेकंड में संग्रहीत होती है), और अस्थायी तालिका पूर्व-निर्मित होने पर केवल 9ms लगते हैं। तालिका चर के लिए, INSERT ने औसतन 22ms से अधिक समय लिया। दिलचस्प बात यह है कि अस्थायी तालिकाओं के लिए SELECT क्वेरी में केवल 1ms और तालिका चर के लिए लगभग 2.7ms का समय लगा।
प्रतीक्षा आँकड़े डेटा की जाँच से एक परिचित प्रतीक्षा_प्रकार, PAGELATCH*:
. मिलता है चुनें * [dbo] से।[PerfTesting_WaitStats] [TestID], [प्रतिशत] DESC द्वारा ऑर्डर करें;

ध्यान दें कि हम केवल देखते हैं कि PAGELATCH* परीक्षण 1 और 2 की प्रतीक्षा कर रहा है, जो अस्थायी तालिकाओं के साथ प्रक्रियाएं थीं। usp_OrderInfoTV के लिए, जो एक तालिका चर का उपयोग करता है, हम केवल SOS_SCHEDULER_YIELD प्रतीक्षा देखते हैं। कृपया ध्यान दें: इसका यह मतलब नहीं है कि आपको अस्थायी तालिकाओं के बजाय तालिका चर का उपयोग करना चाहिए , न ही इसका यह अर्थ है कि आप नहीं करेंगे PAGELATCH तालिका चर के साथ प्रतीक्षा कर रहा है। यह एक काल्पनिक परिदृश्य है; मैं अत्यधिक प्रतीक्षा_प्रकार क्या दिखाई देते हैं, यह देखने के लिए आप अपने कोड के साथ परीक्षण करने की सलाह देते हैं।
अब हम tempdb मेटाडेटा के लिए मेमोरी-ऑप्टिमाइज़्ड टेबल का उपयोग करने के लिए इंस्टेंस को बदल देंगे। इसे दो तरीकों से किया जा सकता है, वैकल्पिक सर्वर कॉन्फ़िगरेशन कमांड के माध्यम से, या sp_configure का उपयोग करके। चूंकि यह सेटिंग एक उन्नत विकल्प है, यदि आप sp_configure का उपयोग करते हैं तो आपको पहले उन्नत विकल्पों को सक्षम करना होगा।
ALTER सर्वर कॉन्फ़िगरेशन सेट MEMORY_OPTIMIZED TEMPDB_METADATA =ON;GO
इस बदलाव के बाद इंस्टेंस को रीस्टार्ट करना जरूरी है। (नोट:आप स्मृति-अनुकूलित तालिकाओं का उपयोग नहीं करने के लिए इसे वापस बदल सकते हैं, आपको बस इंस्टेंस को फिर से पुनरारंभ करना होगा।) पुनरारंभ करने के बाद, यदि हम फिर से sys.configurations की जाँच करते हैं तो हम देख सकते हैं कि मेटाडेटा तालिकाएँ स्मृति-अनुकूलित हैं:

कमांड लाइन फ़ाइलों को फिर से निष्पादित करने के बाद, प्रत्येक प्रक्रिया के 21,000 निष्पादन की कुल अवधि निम्नलिखित दिखाती है (ध्यान दें कि परिणाम आसान तुलना के लिए संग्रहीत कार्यविधि द्वारा आदेशित किए जाते हैं):

usp_OrderInfoTT और usp_OrderInfoTTC दोनों के प्रदर्शन में निश्चित रूप से सुधार हुआ था, और usp_OrderInfoTV के प्रदर्शन में मामूली वृद्धि हुई थी। आइए क्वेरी अवधियों की जांच करें:
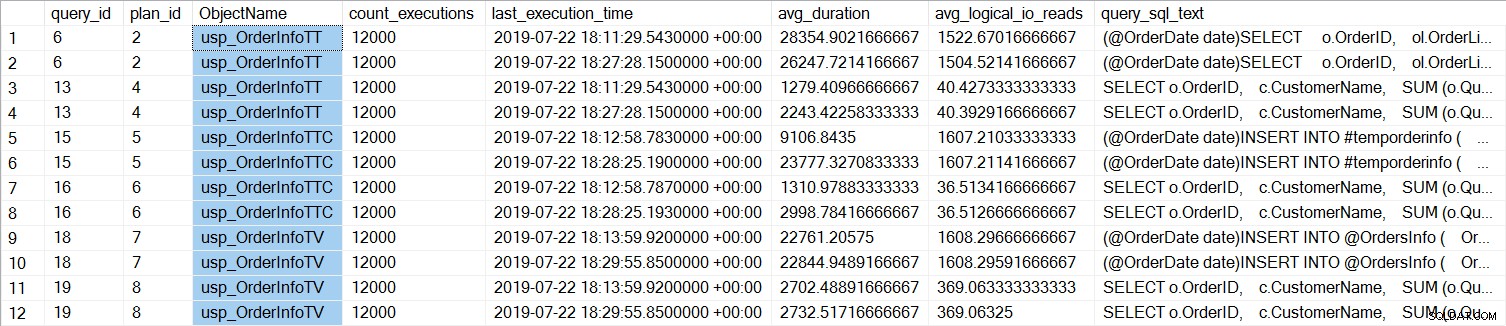
सभी प्रश्नों के लिए, क्वेरी अवधि लगभग समान होती है, जब तालिका पूर्व-निर्मित होती है, तो INSERT अवधि में वृद्धि को छोड़कर, जो पूरी तरह से अप्रत्याशित है। हम प्रतीक्षा आंकड़ों में एक दिलचस्प बदलाव देखते हैं:
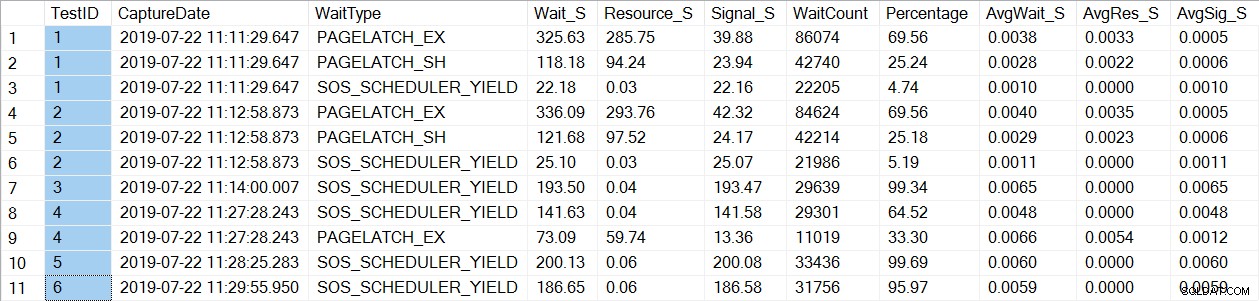
Usp_OrderInfoTT के लिए, अस्थायी तालिका बनाने के लिए एक चयन ... INTO निष्पादित किया जाता है। प्रतीक्षा PAGELATCH_EX और PAGELATCH_SH से केवल में बदल जाती है PAGELATCH_EX और SOS_SCHEDULER_YIELD. हम अब PAGELATCH_SH प्रतीक्षा नहीं देखते हैं।
Usp_OrderInfoTTC के लिए, जो अस्थायी तालिका बनाता है और फिर सम्मिलित करता है, PAGELATCH_EX और PAGELATCH_SH प्रतीक्षा अब प्रकट नहीं होते हैं, और हम केवल SOS_SCHEDULER_YIELD प्रतीक्षा देखते हैं।
अंत में, ऑर्डरइन्फो टीवी के लिए, प्रतीक्षा सुसंगत हैं - केवल SOS_SCHEDULER_YIELD, लगभग समान कुल प्रतीक्षा समय के साथ।
सारांश
इस परीक्षण के आधार पर, हम सभी मामलों में सुधार देखते हैं, अस्थायी तालिकाओं के साथ संग्रहीत प्रक्रियाओं के लिए महत्वपूर्ण रूप से। तालिका परिवर्तनीय प्रक्रिया के लिए थोड़ा सा बदलाव है। यह याद रखना अत्यंत महत्वपूर्ण है कि यह एक छोटा लोड परीक्षण के साथ एक परिदृश्य है। मुझे इन तीन बहुत ही सरल परिदृश्यों को आज़माने में बहुत दिलचस्पी थी, यह समझने और समझने के लिए कि tempdb मेटाडेटा मेमोरी-अनुकूलित बनाने से सबसे अधिक क्या लाभ हो सकता है। यह कार्यभार छोटा था और बहुत सीमित समय के लिए चलता था - वास्तव में मेरे पास अधिक थ्रेड्स के साथ अधिक विविध परिणाम थे, जो किसी अन्य पोस्ट में देखने लायक है। सबसे बड़ा उपाय यह है कि, सभी नई सुविधाओं और कार्यक्षमता के साथ, परीक्षण महत्वपूर्ण है। इस सुविधा के लिए, आप चाहते हैं कि मौजूदा प्रदर्शन की आधार रेखा हो, जिससे बैच अनुरोध/सेक जैसे मीट्रिक की तुलना की जा सके और मेटाडेटा को स्मृति-अनुकूलित करने के बाद आंकड़ों की प्रतीक्षा की जा सके।
अतिरिक्त विचार
इन-मेमोरी OLTP का उपयोग करने के लिए MEMORY OPTIMIZED DATA प्रकार के फ़ाइलग्रुप की आवश्यकता होती है। हालाँकि, MEMORY_OPTIMIZED TEMPDB_METADATA को सक्षम करने के बाद, tempdb के लिए कोई अतिरिक्त फ़ाइल समूह नहीं बनाया गया है। इसके अलावा, यह ज्ञात नहीं है कि स्मृति-अनुकूलित तालिकाएँ टिकाऊ (SCHEMA_AND_DATA) हैं या नहीं (SCHEMA_ONLY)। आम तौर पर इसे sys.tables (durability_desc) के माध्यम से निर्धारित किया जा सकता है, लेकिन समर्पित व्यवस्थापक कनेक्शन का उपयोग करते समय भी tempdb में इसे क्वेरी करते समय शामिल सिस्टम टेबल के लिए कुछ भी नहीं लौटाता है। आपके पास स्मृति-अनुकूलित तालिकाओं के लिए गैर-संकुल अनुक्रमणिका देखने की क्षमता है। आप निम्न क्वेरी का उपयोग यह देखने के लिए कर सकते हैं कि कौन सी तालिकाएं tempdb में स्मृति-अनुकूलित हैं:
चुनें * से tempdb.sys.dm_db_xtp_object_stats x जॉइन tempdb.sys.objects o ON x.object_id =o.object_id जॉइन tempdb.sys.schemas s ON o.schema_id =s.schema_id;
फिर, किसी भी तालिका के लिए, उदाहरण के लिए, sp_helpindex चलाएँ:
EXEC sys.sp_helpindex N'sys.sysobjvalues';

ध्यान दें कि यदि यह एक हैश इंडेक्स है (जिसके लिए निर्माण के हिस्से के रूप में BUCKET_COUNT का अनुमान लगाने की आवश्यकता है), तो विवरण में "गैर-संकुल हैश" शामिल होगा।