क्लाउड इन्फ्रास्ट्रक्चर पर चल रहे डेटाबेस इन दिनों तेजी से लोकप्रिय हो रहे हैं। हालांकि क्लाउड वीएम एंटरप्राइज़-ग्रेड सर्वर के रूप में विश्वसनीय नहीं हो सकता है, मुख्य क्लाउड प्रदाता सेवा उपलब्धता बढ़ाने के लिए विभिन्न प्रकार के टूल प्रदान करते हैं। इस ब्लॉग पोस्ट में, हम आपको दिखाएंगे कि क्लाउड में उच्च उपलब्धता के लिए अपने MySQL या MariaDB डेटाबेस को कैसे तैयार किया जाए। हम विशेष रूप से Amazon Web Services और Google Cloud Platform पर ध्यान देंगे, लेकिन अधिकांश युक्तियों का उपयोग अन्य क्लाउड प्रदाताओं के साथ भी किया जा सकता है।
AWS और Google दोनों अपने क्लाउड पर डेटाबेस सेवाएँ प्रदान करते हैं, और इन सेवाओं को उच्च उपलब्धता के लिए कॉन्फ़िगर किया जा सकता है। किसी क्षेत्र के भीतर सेवाओं की आंशिक विफलता से बचने के आपके अवसरों को बढ़ाने के लिए, विभिन्न उपलब्धता क्षेत्रों (या GCP में क्षेत्र) में प्रतियां होना संभव है। यद्यपि एक होस्टेड सेवा डेटाबेस चलाने का एक बहुत ही सुविधाजनक तरीका है, ध्यान दें कि सेवा को एक विशिष्ट तरीके से व्यवहार करने के लिए डिज़ाइन किया गया है और यह आपकी आवश्यकताओं के अनुरूप हो भी सकता है और नहीं भी। उदाहरण के लिए, जब विफलता से निपटने की बात आती है, तो MySQL के लिए AWS RDS में विकल्पों की एक बहुत सीमित सूची होती है। प्रलेखन के अनुसार मल्टी-एजेड की तैनाती 60-120 सेकंड के फेलओवर समय के साथ आती है। वास्तव में, "छाया" MySQL उदाहरण को "दूषित" डेटासेट से शुरू करना पड़ता है, इसमें और भी अधिक समय लग सकता है क्योंकि InnoDB रीडो लॉग से लेनदेन को लागू करने या वापस रोल करने पर अधिक काम की आवश्यकता हो सकती है। दास को स्वामी बनने के लिए प्रोत्साहित करने का एक विकल्प है, लेकिन यह संभव नहीं है क्योंकि आप मौजूदा दासों को नए स्वामी से मुक्त नहीं कर सकते। एक प्रबंधित सेवा के मामले में, प्रदर्शन समस्याओं का पता लगाना आंतरिक रूप से अधिक जटिल और कठिन है। इस ब्लॉग पोस्ट में MySQL के लिए RDS और इसकी सीमाओं के बारे में अधिक जानकारी।
दूसरी ओर, यदि आप डेटाबेस को प्रबंधित करने का निर्णय लेते हैं, तो आप संभावनाओं की एक अलग दुनिया में हैं। कई चीजें जो आप नंगे धातु पर कर सकते हैं, ईसी 2 या कंप्यूट इंजन इंस्टेंस पर भी संभव है। आपके पास अंतर्निहित हार्डवेयर को प्रबंधित करने का ओवरहेड नहीं है, और फिर भी सिस्टम को आर्किटेक्ट करने के तरीके पर नियंत्रण बनाए रखें। MySQL उपलब्धता के लिए डिज़ाइन करते समय दो मुख्य विकल्प होते हैं - MySQL प्रतिकृति और गैलेरा क्लस्टर। आइए उन पर चर्चा करें।
MySQL प्रतिकृति
MySQL प्रतिकृति डेटा की कई प्रतियों के साथ MySQL को स्केल करने का एक सामान्य तरीका है। एसिंक्रोनस या सेमी-सिंक्रोनस, यह एक लेखक, मास्टर, प्रतिकृतियों / दासों पर निष्पादित परिवर्तनों को प्रचारित करने की अनुमति देता है - जिनमें से प्रत्येक में पूर्ण डेटा सेट होगा और नए मास्टर बनने के लिए प्रचारित किया जा सकता है। प्रतिकृति का उपयोग रीडिंग को स्केल करने के लिए भी किया जा सकता है, रीड ट्रैफिक को प्रतिकृतियों पर निर्देशित करके और इस तरह से मास्टर को ऑफलोड कर सकता है। प्रतिकृति का मुख्य लाभ उपयोग में आसानी है - यह इतना व्यापक रूप से ज्ञात और लोकप्रिय है (इसे कॉन्फ़िगर करना भी आसान है) कि इसे प्रबंधित और कॉन्फ़िगर करने में आपकी सहायता के लिए कई संसाधन और टूल हैं। हमारा अपना ClusterControl उनमें से एक है - आप इसका उपयोग एकीकृत लोड बैलेंसर के साथ एक MySQL प्रतिकृति सेटअप को आसानी से परिनियोजित करने, टोपोलॉजी परिवर्तन, फ़ेलओवर/पुनर्प्राप्ति आदि को प्रबंधित करने के लिए कर सकते हैं।
MySQL प्रतिकृति के साथ एक प्रमुख मुद्दा यह है कि इसे नेटवर्क विभाजन या मास्टर की विफलता को संभालने के लिए डिज़ाइन नहीं किया गया है। यदि कोई मास्टर नीचे चला जाता है, तो आपको प्रतिकृतियों में से एक को बढ़ावा देना होगा। यह एक मैनुअल प्रक्रिया है, हालांकि इसे बाहरी उपकरणों (जैसे ClusterControl) के साथ स्वचालित किया जा सकता है। कोई कोरम तंत्र भी नहीं है और MySQL प्रतिकृति में विफल मास्टर इंस्टेंस की बाड़ लगाने के लिए कोई समर्थन नहीं है। दुर्भाग्य से, इससे वितरित वातावरण में गंभीर समस्याएं हो सकती हैं - यदि आपने एक नए मास्टर को पदोन्नत किया है, जबकि आपका पुराना ऑनलाइन वापस आता है, तो आप दो नोड्स को लिखना समाप्त कर सकते हैं, डेटा बहाव पैदा कर सकते हैं और गंभीर डेटा स्थिरता समस्याएं पैदा कर सकते हैं।
हम इस पोस्ट में बाद में कुछ उदाहरणों पर गौर करेंगे, जो आपको नेटवर्क विभाजन का पता लगाने और आपके MySQL प्रतिकृति सेटअप के लिए STONITH या किसी अन्य फेंसिंग तंत्र को लागू करने का तरीका दिखाता है।
गैलेरा क्लस्टर
हमने पिछले खंड में देखा था कि MySQL प्रतिकृति में फेंसिंग और कोरम समर्थन का अभाव है - यह वह जगह है जहां गैलेरा क्लस्टर चमकता है। इसमें कोरम सपोर्ट बिल्ट-इन है, इसमें एक फेंसिंग मैकेनिज्म भी है जो विभाजित नोड्स को लिखने को स्वीकार करने से रोकता है। यह गैलेरा क्लस्टर को मल्टी-डेटासेंटर सेटअप में प्रतिकृति की तुलना में अधिक उपयुक्त बनाता है। गैलेरा क्लस्टर कई लेखकों का भी समर्थन करता है, और लेखन संघर्षों को हल करने में सक्षम है। इसलिए आप बहु-डेटासेंटर सेटअप में एक लेखक तक सीमित नहीं हैं, प्रत्येक डेटासेंटर में एक लेखक होना संभव है जो आपके एप्लिकेशन और डेटाबेस स्तर के बीच विलंबता को कम करता है। यह लेखन को गति नहीं देता है क्योंकि प्रमाणीकरण के लिए प्रत्येक गैलेरा नोड को अभी भी प्रत्येक लेखन भेजा जाना है, लेकिन WAN के सभी एप्लिकेशन सर्वर से एक एकल दूरस्थ मास्टर को लिखना अभी भी आसान है।
गैलेरा जितना अच्छा है, यह हमेशा सभी कार्यभार के लिए सबसे अच्छा विकल्प नहीं होता है। गैलेरा MySQL/InnoDB के लिए ड्रॉप-इन प्रतिस्थापन नहीं है। यह "सामान्य" MySQL के साथ सामान्य सुविधाओं को साझा करता है - यह स्टोरेज इंजन के रूप में InnoDB का उपयोग करता है, इसमें प्रत्येक नोड पर संपूर्ण डेटासेट होता है, जो जॉइन को संभव बनाता है। फिर भी, गैलेरा की कुछ प्रदर्शन विशेषताएँ (जैसे कि नेटवर्क विलंबता से प्रभावित लेखन का प्रदर्शन) प्रतिकृति सेटअप से आपकी अपेक्षा से भिन्न होती हैं। रखरखाव भी अलग दिखता है:स्कीमा परिवर्तन प्रबंधन थोड़ा अलग काम करता है। कुछ स्कीमा डिज़ाइन इष्टतम नहीं हैं:यदि आपके टेबल में हॉटस्पॉट हैं, जैसे बार-बार अपडेट किए गए काउंटर, तो इससे प्रदर्शन संबंधी समस्याएं हो सकती हैं। बैच प्रोसेसिंग से संबंधित सर्वोत्तम प्रथाओं में भी अंतर है - बड़े लेनदेन में प्रश्नों को निष्पादित करने के बजाय, आप चाहते हैं कि आपके लेनदेन छोटे हों।
प्रॉक्सी टियर
प्रॉक्सी के बिना अत्यधिक उपलब्ध सेटअप बनाना बहुत कठिन और बोझिल है। निश्चित रूप से, आप डेटाबेस इंस्टेंस का ट्रैक रखने के लिए अपने एप्लिकेशन में कोड लिख सकते हैं, अस्वस्थ लोगों को ब्लैकलिस्ट कर सकते हैं, लिखने योग्य मास्टर का ट्रैक रख सकते हैं, और इसी तरह। लेकिन यह केवल एक समापन बिंदु पर ट्रैफ़िक भेजने की तुलना में कहीं अधिक जटिल है - जहां एक प्रॉक्सी आती है। ClusterControl आपको ProxySQL, HAProxy और MaxScale को परिनियोजित करने की अनुमति देता है। हम ProxySQL का उपयोग करके कुछ उदाहरण देंगे, क्योंकि यह हमें डेटाबेस ट्रैफ़िक को नियंत्रित करने में अच्छा लचीलापन देता है।
ProxySQL को दो तरह से तैनात किया जा सकता है। शुरुआत के लिए, इसे अलग-अलग होस्ट पर तैनात किया जा सकता है और वर्चुअल आईपी प्रदान करने के लिए Keepalived का उपयोग किया जा सकता है। वर्चुअल आईपी को इधर-उधर ले जाया जाएगा, प्रॉक्सीएसक्यूएल इंस्टेंस में से एक के विफल होने पर। क्लाउड में, यह सेटअप समस्याग्रस्त हो सकता है क्योंकि आमतौर पर इंटरफ़ेस में IP जोड़ना पर्याप्त नहीं होता है। लोचदार आईपी (या स्थिर-हालांकि इसे आपके क्लाउड प्रदाता द्वारा कहा जा सकता है) के साथ काम करने के लिए आपको Keepalived कॉन्फ़िगरेशन और स्क्रिप्ट को संशोधित करना होगा। फिर कोई इस आईपी पते को दूसरे होस्ट में स्थानांतरित करने के लिए क्लाउड एपीआई या सीएलआई का उपयोग करेगा। इस कारण से, हम एप्लिकेशन के साथ ProxySQL को जोड़ने का सुझाव देंगे। प्रत्येक एप्लिकेशन सर्वर को यूनिक्स सॉकेट्स का उपयोग करके स्थानीय प्रॉक्सीएसक्यूएल से कनेक्ट करने के लिए कॉन्फ़िगर किया जाएगा। जैसा कि ProxySQL एक एंजेल प्रक्रिया का उपयोग करता है, ProxySQL क्रैश का पता लगाया जा सकता है / एक सेकंड के भीतर पुनरारंभ किया जा सकता है। हार्डवेयर क्रैश होने की स्थिति में, वह विशेष एप्लिकेशन सर्वर ProxySQL के साथ डाउन हो जाएगा। शेष एप्लिकेशन सर्वर अभी भी अपने संबंधित स्थानीय प्रॉक्सीएसक्यूएल इंस्टेंस तक पहुंच सकते हैं। इस विशेष सेटअप में अतिरिक्त विशेषताएं हैं। सुरक्षा - प्रोक्सीएसक्यूएल, संस्करण 1.4.8 के अनुसार, क्लाइंट-साइड एसएसएल के लिए समर्थन नहीं है। यह केवल ProxySQL और बैकएंड के बीच SSL कनेक्शन सेटअप कर सकता है। एप्लिकेशन होस्ट पर ProxySQL को कॉलोकेट करना और यूनिक्स सॉकेट्स का उपयोग करना एक अच्छा समाधान है। ProxySQL में प्रश्नों को कैश करने की क्षमता भी है और यदि आप इस सुविधा का उपयोग करने जा रहे हैं, तो विलंबता को कम करने के लिए इसे एप्लिकेशन के जितना संभव हो उतना करीब रखना समझ में आता है। हम ProxySQL को परिनियोजित करने के लिए इस पैटर्न का उपयोग करने का सुझाव देंगे।
विशिष्ट सेटअप
आइए अत्यधिक उपलब्ध सेटअप के उदाहरण देखें।
एकल डेटासेंटर, MySQL प्रतिकृति
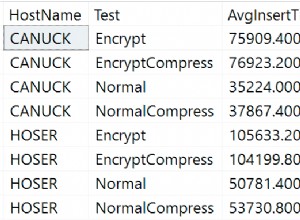
यहाँ धारणा यह है कि डेटासेंटर के भीतर दो अलग-अलग क्षेत्र हैं। प्रत्येक क्षेत्र में एक साथ दो क्षेत्रों के विफल होने की संभावना को कम करने के लिए अनावश्यक और अलग बिजली, नेटवर्किंग और कनेक्टिविटी है। दोनों क्षेत्रों में फैले प्रतिकृति टोपोलॉजी को स्थापित करना संभव है।
यहां हम विफलता को प्रबंधित करने के लिए ClusterControl का उपयोग करते हैं। उपलब्धता क्षेत्रों के बीच स्प्लिट-ब्रेन परिदृश्य को हल करने के लिए, हम सक्रिय क्लस्टरकंट्रोल को मास्टर के साथ मिलाते हैं। हम यह सुनिश्चित करने के लिए अन्य उपलब्धता क्षेत्र में दासों को भी ब्लैकलिस्ट करते हैं कि स्वचालित विफलता के परिणामस्वरूप दो मास्टर उपलब्ध नहीं होंगे।
एकाधिक डेटासेंटर, MySQL प्रतिकृति
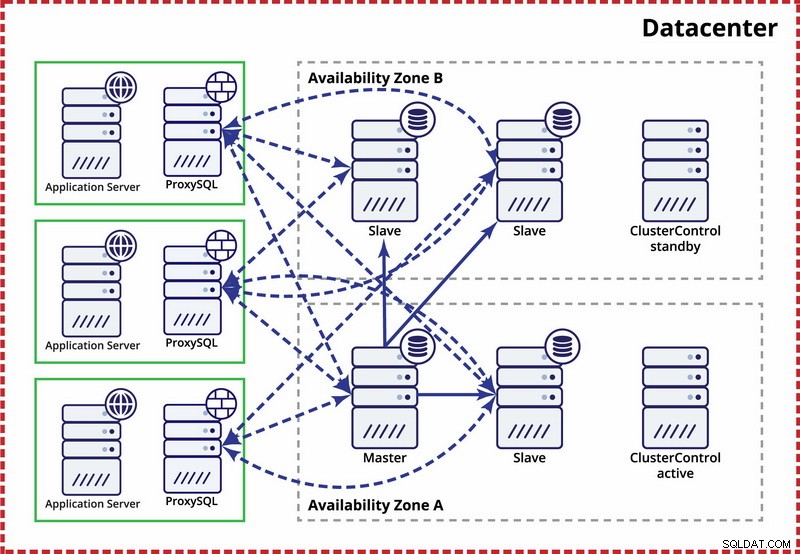
इस उदाहरण में हम कोरम की गणना के लिए तीन डेटासेंटर और ऑर्केस्ट्रेटर/राफ्ट का उपयोग करते हैं। यदि मास्टर बुनियादी ढांचे के विभाजित खंड में है, तो आपको STONITH को लागू करने के लिए अपनी स्क्रिप्ट लिखनी पड़ सकती है। ClusterControl का उपयोग नोड पुनर्प्राप्ति और प्रबंधन कार्यों के लिए किया जाता है।
एकाधिक डेटासेंटर, गैलेरा क्लस्टर
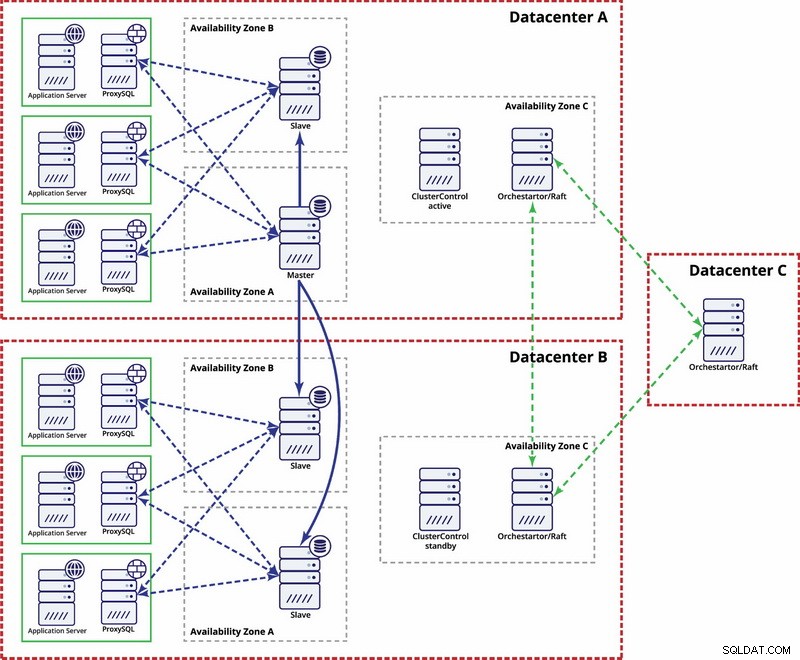
इस मामले में हम तीसरे में गैलेरा मध्यस्थ के साथ तीन डेटासेंटर का उपयोग करते हैं - यह संपूर्ण डेटासेंटर विफलता को संभालना संभव बनाता है और नेटवर्क विभाजन के जोखिम को कम करता है क्योंकि तीसरे डेटासेंटर को रिले के रूप में उपयोग किया जा सकता है।
आगे पढ़ने के लिए, "अत्यधिक उपलब्ध ओपन सोर्स डेटाबेस वातावरण कैसे डिज़ाइन करें" श्वेतपत्र पर एक नज़र डालें और वेबिनार रीप्ले "उच्च उपलब्धता के लिए ओपन सोर्स डेटाबेस डिज़ाइन करना" देखें।