डेटाबेस किसी भी व्यवसाय या संगठन का एक महत्वपूर्ण और महत्वपूर्ण हिस्सा है। बढ़ते रुझान का अनुमान है कि 82% उद्यम अगले 12 महीनों में डेटाबेस की संख्या में वृद्धि की उम्मीद करते हैं। प्रत्येक डीबीए की एक बड़ी चुनौती यह पता लगाना है कि बड़े पैमाने पर डेटा वृद्धि से कैसे निपटा जाए, और यह एक सबसे महत्वपूर्ण लक्ष्य होने जा रहा है। आप अपने उपयोगकर्ताओं को सर्वोत्तम संभव अनुभव देने के लिए डेटाबेस प्रदर्शन, कम लागत और डाउनटाइम को कैसे समाप्त कर सकते हैं? क्या डेटा कम्प्रेशन एक विकल्प है? आइए शुरू करें और देखें कि ऐसी स्थितियों से निपटने के लिए कुछ मौजूदा सुविधाएं कैसे उपयोगी हो सकती हैं।
इस लेख में, हम यह जानने जा रहे हैं कि डेटा संपीड़न समाधान हमें डेटा प्रबंधन समाधान को अनुकूलित करने में कैसे मदद कर सकता है। इस गाइड में, हम निम्नलिखित विषयों को शामिल करेंगे:
- संपीड़न का एक सिंहावलोकन
- संपीड़न के लाभ
- डेटा के बारे में एक रूपरेखा संपीड़न तकनीक है
- विभिन्न प्रकार के डेटा संपीड़न की चर्चा
- डेटा संपीड़न के बारे में तथ्य
- कार्यान्वयन विचार
- और भी बहुत कुछ...
संपीड़न
संपीड़न एक तकनीक है और इस प्रकार, एक संसाधन-संवेदनशील ऑपरेशन है, लेकिन हार्डवेयर ट्रेड-ऑफ के साथ। निम्नलिखित लाभों के लिए डेटा संपीड़न को परिनियोजित करने के बारे में सोचना चाहिए:
- प्रभावी अंतरिक्ष प्रबंधन
- दक्षतापूर्ण लागत घटाने की तकनीक
- डेटाबेस बैकअप प्रबंधन में आसानी
- प्रभावी एन/डब्ल्यू बैंडविड्थ उपयोग
- सुरक्षित और तेज़ रिकवरी या बहाली
- बेहतर प्रदर्शन - सिस्टम के मेमोरी फ़ुटप्रिंट को कम करता है
नोट: यदि SQL सर्वर CPU या स्मृति बाधित है तो संपीड़न आपके वातावरण के अनुकूल नहीं हो सकता है।
डेटा संपीड़न इस पर लागू होता है:
- ढेर
- संकुल अनुक्रमणिका
- गैर-संकुल अनुक्रमणिका
- विभाजन
- अनुक्रमित दृश्य
नोट: बड़ी वस्तुएं संकुचित नहीं होती हैं (उदाहरण के लिए, LOB और BLOB)
निम्नलिखित अनुप्रयोगों के लिए सबसे उपयुक्त:
- लॉग टेबल
- ऑडिट टेबल
- तथ्य सारणी
- रिपोर्टिंग
परिचय
डेटा कम्प्रेशन एक ऐसी तकनीक है जो SQL Server 2008 के आसपास से है। डेटा कंप्रेशन का विचार यह है कि आप डेटाबेस के भीतर चुनिंदा टेबल, इंडेक्स या विभाजन चुन सकते हैं। I/O डेटाबेस के अंदर और बाहर जानकारी को स्थानांतरित करने में एक बाधा बना हुआ है। डेटा संपीड़न इस प्रकार का लाभ उठाता है और डेटाबेस की दक्षता बढ़ाने में मदद करता है। जैसा कि हम जानते हैं कि नेटवर्क की गति प्रसंस्करण गति की तुलना में बहुत धीमी है, डेटाबेस में डेटा को संपीड़ित करने के लिए प्रसंस्करण शक्ति का उपयोग करके दक्षता लाभ प्राप्त करना संभव है, ताकि यह तेजी से यात्रा कर सके। और फिर दूसरे छोर पर डेटा को असम्पीडित करने के लिए फिर से प्रसंस्करण शक्ति का उपयोग करें। सामान्य तौर पर, डेटा संपीड़न डेटा के कब्जे वाले स्थान को कम कर देता है। डेटा संपीड़न की तकनीक प्रत्येक डेटाबेस के लिए उपलब्ध है और यह SQL सर्वर 2016 SP1 के सभी संस्करणों द्वारा समर्थित है। इससे पहले, यह केवल SQL सर्वर एंटरप्राइज़ या डेवलपर संस्करणों पर उपलब्ध था, मानक या एक्सप्रेस पर नहीं।
सुविधा समर्थन

डेटा संपीड़न प्रकार
SQL सर्वर में दो प्रकार के डेटा कंप्रेशन उपलब्ध हैं, पंक्ति-स्तर और पृष्ठ-स्तर।
पंक्ति-स्तरीय संपीड़न पर्दे के पीछे काम करता है और किसी भी निश्चित लंबाई डेटा प्रकारों को चर लंबाई प्रकारों में परिवर्तित करता है। यहां धारणा यह है कि अक्सर डेटा एक निश्चित लंबाई प्रकार में संग्रहीत किया जाता है, जैसे कि चार 100, और वे वास्तव में प्रत्येक रिकॉर्ड के लिए पूरे 100 वर्ण नहीं भरते हैं। तालिका से इस अतिरिक्त स्थान को हटाकर छोटे लाभ प्राप्त किए जा सकते हैं। बेशक, यदि आपकी डेटा तालिकाएँ निश्चित लंबाई के टेक्स्ट और संख्यात्मक फ़ील्ड का उपयोग नहीं करती हैं, या यदि वे करते हैं और आप वास्तव में वर्णों और अंकों की पूरी तरह से स्वीकार्य संख्या को संग्रहीत करते हैं, तो पंक्ति-स्तरीय योजना के तहत संपीड़न लाभ न्यूनतम होने जा रहा है। सबसे अच्छा।
संपीड़न की अवधारणा चार, इंट और फ्लोट सहित सभी निश्चित-लंबाई वाले डेटा प्रकारों तक फैली हुई है। SQL सर्वर डेटा को संग्रहीत करके स्थान बचाने की अनुमति देता है जैसे कि यह एक चर आकार का प्रकार था; डेटा दिखाई देगा और एक निश्चित लंबाई की तरह व्यवहार करेगा।
उदाहरण के लिए, यदि आपने 100 का मान int . में संग्रहीत किया है कॉलम, SQL सर्वर को सभी 32 बिट्स का उपयोग करने की आवश्यकता नहीं है, इसके बजाय, यह केवल 8 बिट्स (1 बाइट) का उपयोग करता है।
पृष्ठ स्तर का संपीड़न चीजों को दूसरे स्तर पर ले जाता है। सबसे पहले, यह स्वचालित रूप से निश्चित लंबाई डेटा फ़ील्ड पर पंक्ति-स्तरीय संपीड़न लागू करता है, ताकि आप डिफ़ॉल्ट रूप से उन लाभों को स्वचालित रूप से प्राप्त कर सकें। फिर उसके ऊपर, यह उपसर्ग संपीड़न नामक कुछ लागू करता है, और एक अन्य तकनीक जिसे शब्दकोश संपीड़न कहा जाता है।
पंक्ति संपीड़न
पंक्ति संपीड़न संपीड़न का एक आंतरिक स्तर है जो रिक्त वर्णों को संग्रहीत न करके चर-लंबाई प्रारूप का उपयोग करके निश्चित वर्ण स्ट्रिंग को संग्रहीत करता है। निम्न चरणों को पंक्ति-स्तरीय संपीड़न में किया जाता है।
- सभी संख्यात्मक डेटा प्रकार जैसे int , फ्लोट , दशमलव, और पैसा परिवर्तनीय लंबाई डेटा प्रकारों में परिवर्तित हो जाते हैं। उदाहरण के लिए, कॉलम में संग्रहीत 125 और कॉलम का डेटा प्रकार एक पूर्णांक है। तब हम जानते हैं कि पूर्णांक मान को संग्रहीत करने के लिए 4 बाइट्स का उपयोग किया जाता है। लेकिन 125 को 1 बाइट में स्टोर किया जा सकता है क्योंकि 1 बाइट 0 से 255 तक के मानों को स्टोर कर सकता है। इसलिए, 125 को एक छोटे int के रूप में स्टोर किया जा सकता है। , ताकि 3 बाइट सहेजे जा सकें।
- चार और नचार डेटा प्रकारों को चर लंबाई डेटा प्रकारों के रूप में संग्रहीत किया जाता है। उदाहरण के लिए, “SQL” को char . में संग्रहित किया जाता है (20) कॉलम टाइप करें। लेकिन संपीड़न के बाद, केवल 3 बाइट्स ही उपयोग करेंगे। डेटा संपीड़न के बाद, इस प्रकार के डेटा के साथ कोई रिक्त वर्ण संग्रहीत नहीं किया जाता है।
- रिकॉर्ड का मेटाडेटा कम कर दिया गया है।
- NULL और 0 मान अनुकूलित हैं और कोई स्थान खर्च नहीं होता है।
पृष्ठ संपीड़न
पृष्ठ संपीड़न डेटा संपीड़न का एक उन्नत स्तर है। डिफ़ॉल्ट रूप से, एक पृष्ठ संपीड़न पंक्ति स्तर संपीड़न को भी लागू करता है। पृष्ठ संपीड़न को दो प्रकारों में वर्गीकृत किया जाता है
- उपसर्ग संपीड़न और
- शब्दकोश संपीड़न।
उपसर्ग संपीड़न
प्रत्येक पृष्ठ के लिए उपसर्ग संपीड़न में, पृष्ठ के प्रत्येक स्तंभ के लिए, सभी पंक्तियों से एक सामान्य मान प्राप्त किया जाता है और प्रत्येक स्तंभ में शीर्षलेख के नीचे संग्रहीत किया जाता है। अब प्रत्येक पंक्ति में, सामान्य मान के बजाय उस मान का संदर्भ संग्रहीत किया जाता है।
शब्दकोश संपीड़न
शब्दकोश संपीड़न उपसर्ग संपीड़न के समान है लेकिन सामान्य मान सभी स्तंभों से पुनर्प्राप्त किए जाते हैं और शीर्षलेख के बाद दूसरी पंक्ति में संग्रहीत किए जाते हैं। शब्दकोश संपीड़न प्रत्येक पृष्ठ पर सभी स्तंभों और पंक्तियों में सटीक मान मिलान की तलाश करता है।
हम निम्नलिखित डेटाबेस ऑब्जेक्ट्स के लिए पंक्ति और पृष्ठ स्तर संपीड़न कर सकते हैं।
- एक टेबल ढेर में संग्रहीत।
- एक संपूर्ण तालिका को संकुल अनुक्रमणिका के रूप में संग्रहीत किया जाता है।
- अनुक्रमित दृश्य।
- गैर-संकुल अनुक्रमणिका।
- विभाजित अनुक्रमणिका और तालिकाएँ।
नोट: हम डेटा कम्प्रेशन या तो क्रिएट टेबल, क्रिएट इंडेक्स जैसे निर्माण के समय या ALTER कमांड का उपयोग करके REBUILD विकल्प जैसे ALTER TABLE… के साथ निर्माण के बाद कर सकते हैं। के साथ पुनर्निर्माण करें।
डेमो
WideWorldImporters डेटाबेस का उपयोग संपूर्ण डेमो के माध्यम से किया जाता है। साथ ही, रीयल-टाइम DW डेटाबेस को कंप्रेशन ऑपरेशन के लिए माना जाता है।
आइए चरणों के बारे में विस्तार से जानते हैं:
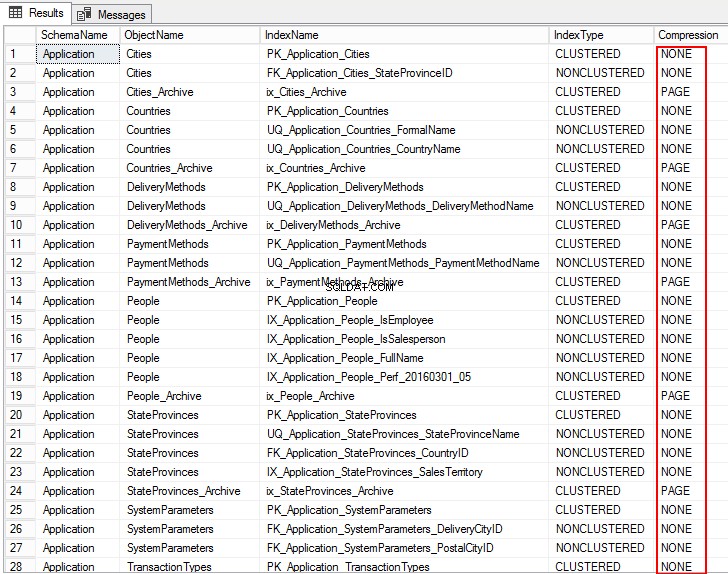
1. डेटाबेस में ऑब्जेक्ट्स के लिए कंप्रेशन सेटिंग्स देखने के लिए, निम्नलिखित T-SQL चलाएँ:
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' ORDER BY S.name, O.name, I.index_id; GO. द्वारा ऑर्डर करें
निम्न आउटपुट संपीड़न प्रकार को पृष्ठ, पंक्ति के रूप में दिखाता है, और कई तालिकाओं के लिए यह कोई नहीं है। इसका मतलब है कि यह संपीड़न के लिए कॉन्फ़िगर नहीं किया गया है।
2. संपीड़न का अनुमान लगाने के लिए, निम्न सिस्टम संग्रहीत कार्यविधि sp_estimate_data_compression_ Savings चलाएँ . इस मामले में, संग्रहीत कार्यविधि को BuyOrderLines टेबल पर निष्पादित किया जाता है।
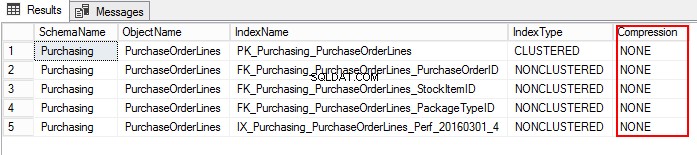
3. आइए निम्नलिखित टी-एसक्यूएल चलाकर खरीद ऑर्डरलाइन संपीड़न सेटिंग का पता लगाएं:
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' and o.name ='PurchaseOrderLines' ORDER BY S.name, O.name, I.index_id;
EXEC sp_estimate_data_compression_savings @schema_name = 'Purchasing', @object_name = 'PurchaseOrderLines', @index_id = NULL, @partition_number = NULL, @data_compression = 'Page'; GO

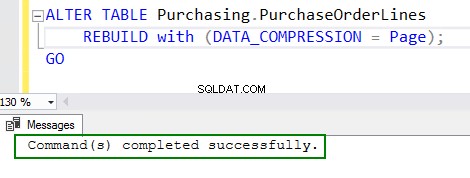
4. ALTER तालिका आदेश चलाकर संपीड़न सक्षम करें:
ALTER TABLE Purchasing.PurchaseOrderLines REBUILD with (DATA_COMPRESSION = Page); GO
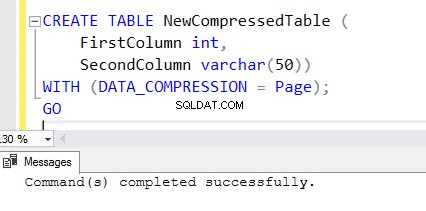
5. कंप्रेशन इनेबल्ड फीचर के साथ एक नई टेबल बनाने के लिए CREATE TABLE स्टेटमेंट के अंत में WITH क्लॉज जोड़ें। NewCompressedTable . बनाने के लिए आप नीचे दिए गए CREATE TABLE स्टेटमेंट को देख सकते हैं ।
CREATE TABLE NewCompressedTable (
FirstColumn int,
SecondColumn varchar(50))
WITH (DATA_COMPRESSION = Page);
GO
डेटा संपीड़न तथ्य
आइए हम संपीड़न के बारे में कुछ वास्तविक जानकारी देखें
- संपीड़न सिस्टम तालिकाओं पर लागू नहीं किया जा सकता
- पंक्ति का आकार 8060 बाइट्स से अधिक होने पर तालिका को संपीड़न के लिए सक्षम नहीं किया जा सकता है।
- संपीड़ित डेटा बफर पूल में कैश किया जाता है; इसका मतलब है तेज प्रतिक्रिया समय
- संपीड़न को सक्षम करने से क्वेरी योजना बदल सकती है क्योंकि डेटा अलग-अलग पृष्ठों और प्रति पृष्ठ पंक्तियों की संख्या का उपयोग करके संग्रहीत किया जाता है।
- गैर-संकुल अनुक्रमणिका संपीड़न गुण इनहेरिट नहीं करते हैं
- जब एक ढेर पर एक संकुल सूचकांक बनाया जाता है, तो संकुल सूचकांक हीप की संपीड़न स्थिति को इनहेरिट करता है जब तक कि कोई वैकल्पिक संपीड़न स्थिति निर्दिष्ट न हो।
- रो और पेज स्तर के कंप्रेशन को ऑफ़लाइन या ऑनलाइन सक्षम और अक्षम किया जा सकता है।
- यदि हीप सेटिंग बदली जाती है, तो सभी गैर-संकुल अनुक्रमणिका को फिर से बनाया जाना है।
- पंक्ति या पृष्ठ संपीड़न को सक्षम या अक्षम करने के लिए डिस्क स्थान की आवश्यकताएं इंडेक्स बनाने या पुनर्निर्माण के लिए समान हैं।
- जब विभाजन को ALTER PARTITION कथन का उपयोग करके विभाजित किया जाता है, तो दोनों विभाजन मूल विभाजन की डेटा संपीड़न विशेषता को इनहेरिट करते हैं।
- जब दो विभाजन मर्ज किए जाते हैं, तो परिणामी विभाजन को गंतव्य विभाजन की डेटा संपीड़न विशेषता विरासत में मिलती है।
- विभाजन को बदलने के लिए, विभाजन का डेटा संपीड़न गुण तालिका के संपीड़न गुण से मेल खाना चाहिए।
- कॉलमस्टोर टेबल और इंडेक्स हमेशा कॉलमस्टोर कम्प्रेशन के साथ स्टोर किए जाते हैं।
- डेटा संपीड़न विरल स्तंभों के साथ असंगत है इसलिए तालिका को संपीड़ित नहीं किया जा सकता है।
रीयल-टाइम परिदृश्य
आइए हम डेटा संपीड़न तकनीक के माध्यम से चलते हैं और डेटा संपीड़न के प्रमुख मापदंडों को समझते हैं।
प्रत्येक तालिका द्वारा उपयोग किए गए स्थान की जांच करने के लिए, निम्न T-SQL चलाएँ। क्वेरी का आउटपुट हमें प्रत्येक तालिका के उपयोग के बारे में विस्तृत जानकारी देता है। यह डेटा संपीड़न के कार्यान्वयन के लिए निर्णायक कारक होगा।
SELECT
t.NAME AS TableName,
i.name as indexName,
sum(p.rows) as RowCounts,
sum(a.total_pages) as TotalPages,
sum(a.used_pages) as UsedPages,
sum(a.data_pages) as DataPages,
(sum(a.total_pages) * 8) / 1024 as TotalSpaceMB,
(sum(a.used_pages) * 8) / 1024 as UsedSpaceMB,
(sum(a.data_pages) * 8) / 1024 as DataSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
WHERE
t.NAME NOT LIKE 'dt%' AND
i.OBJECT_ID > 255 AND
i.index_id <= 1
GROUP BY
t.NAME, i.object_id, i.index_id, i.name
ORDER BY
TotalSpaceMB desc
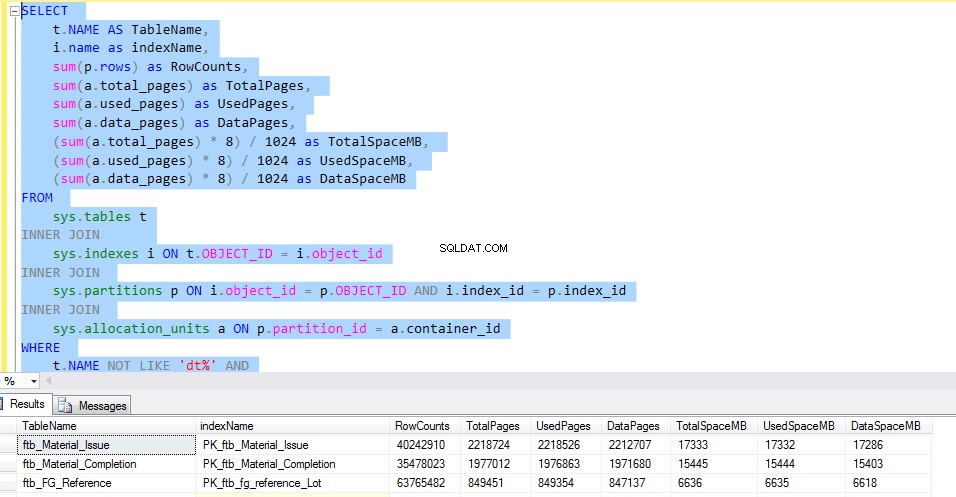
आइए हम ftb_material_Issue . पर विचार करें तथ्य तालिका। तथ्य तालिका में संख्यात्मक BIGINT डेटा प्रकार होते हैं।
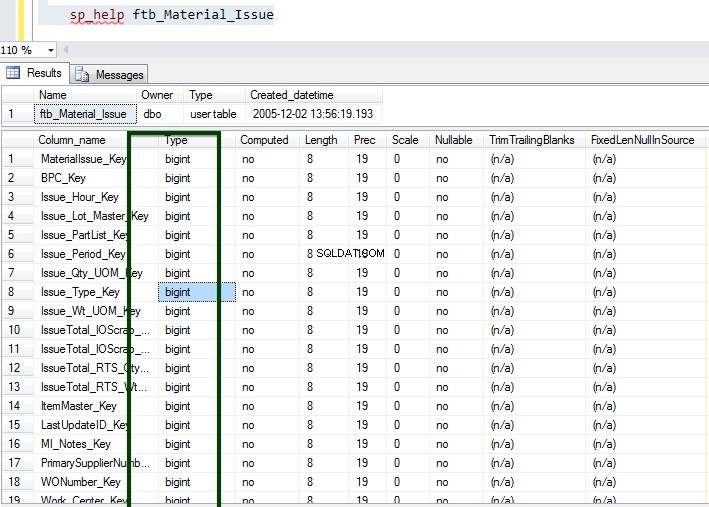
अब, तालिका के विवरण को समझने के लिए sp_spaceused संग्रहीत कार्यविधि चलाएँ। आप यहां sp_spaceused कमांड के बारे में अधिक जान सकते हैं।
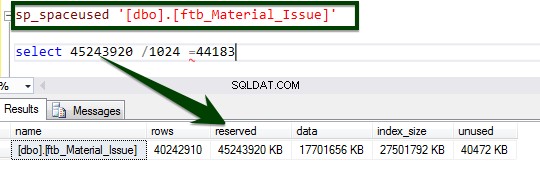
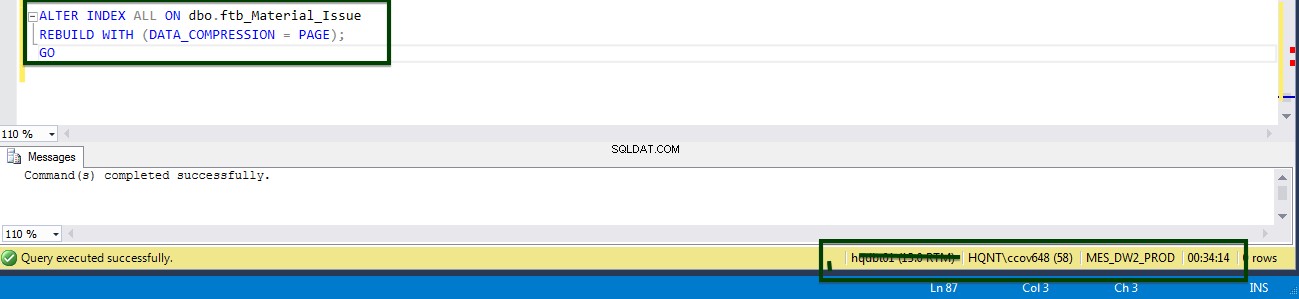
निम्न T-SQL चलाकर तालिका-स्तरीय संपीड़न सक्षम करें। निम्न T-SQL को सर्वर पर निष्पादित किया गया था और तालिका-स्तर पर पृष्ठ को संपीड़ित करने में 34 मिनट 14 सेकंड का समय लगा।
ALTER TABLE dbo.ftb_material_Issue REBUILD with (DATA_COMPRESSION = Page);
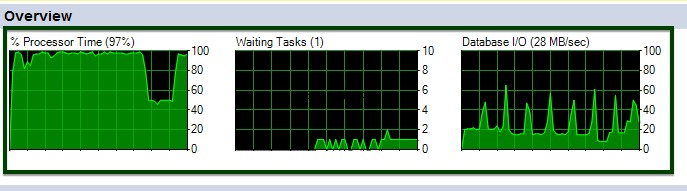
आप ALTER टेबल कमांड के निष्पादन के दौरान CPU और I/O उतार-चढ़ाव देख सकते हैं।
अब, डेटा संपीड़न तुलना के बाद पहले v/s करते हैं। तालिका का आकार लगभग ~45 GB को घटाकर ~15 GB कर दिया गया है।
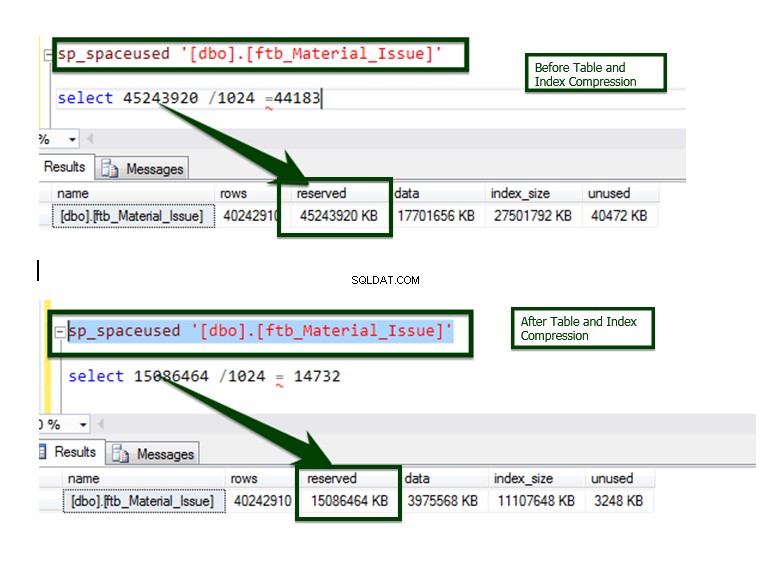
प्रक्रिया स्वचालित स्क्रिप्ट का उपयोग करके अधिकांश वस्तुओं पर लागू की जाती है और यहां तुलना का अंतिम परिणाम है।
इंडेक्स कंप्रेशन ऑपरेशन से पहले और बाद में डेटा तुलना।

सारांश
डेटा के आकार को कम करने के लिए डेटा संपीड़न एक बहुत प्रभावी तकनीक है; कम किए गए डेटा के लिए कम I/O प्रक्रियाओं की आवश्यकता होती है। डेटाबेस में कम्प्रेशन जोड़ने से CPU आवश्यकताओं पर भार बढ़ जाता है। आपको यह सुनिश्चित करने की आवश्यकता होगी कि इन परिवर्तनों को एक कुशल तरीके से समायोजित करने के लिए आपके पास उपलब्ध संसाधन क्षमता है। इसलिए पहले थोड़ा शोध करना और डेटा संपीड़न को सक्षम करने के लिए संशोधनों को लागू करने से पहले किस प्रकार के लाभ की उम्मीद की जा सकती है, यह बेहतर है। यह क्लाउड डेटाबेस सेटअप में बहुत फायदेमंद है जहां लागत शामिल है।
संपीड़न को चरणबद्ध करें (उन सभी को एक बार में न करें) और कम-गतिविधि समय अवधि के दौरान संपीड़ित करें। डेटा कम्प्रेशन और बैकअप कम्प्रेशन अच्छी तरह से मौजूद हैं और इसके परिणामस्वरूप अतिरिक्त संग्रहण स्थान की बचत हो सकती है, इसलिए आगे बढ़ें और शामिल हों।
संपीड़न न केवल भौतिक फ़ाइल आकार को कम करता है, बल्कि यह डिस्क I/O को भी कम करता है, जो डेटाबेस बैकअप के साथ-साथ कई डेटाबेस अनुप्रयोगों के प्रदर्शन को बढ़ा सकता है।
यदि हम अंतर्निहित बुनियादी ढांचे और व्यावसायिक आवश्यकताओं को जानते हैं तो संपीड़न को लागू करने का निर्णय लेना आसान है। कंप्रेशन बचत को समझने और अनुमान लगाने के लिए हम निश्चित रूप से उपलब्ध सिस्टम प्रक्रिया का उपयोग कर सकते हैं। यह संग्रहीत कार्यविधि ऐसा कोई विवरण प्रदान नहीं करती है जो आपको बताए कि संपीड़न आपके सिस्टम को कैसे सकारात्मक या नकारात्मक रूप से प्रभावित करेगा। यह स्पष्ट है कि किसी भी प्रकार के संपीड़न के लिए ट्रेड-ऑफ हैं। यदि आपके पास विशाल डेटा के समान पैटर्न हैं, तो संपीड़न स्थान बचाने की कुंजी है। सीपीयू की शक्ति बढ़ने और प्रत्येक प्रणाली बहु-कोर संरचनाओं से बंधी होने के साथ, संपीड़न कई प्रणालियों के लिए उपयुक्त हो सकता है। मैं आपके सिस्टम का परीक्षण करने की अनुशंसा करता हूं। यह सुनिश्चित करने के लिए परीक्षण करें कि प्रदर्शन नकारात्मक रूप से प्रभावित नहीं है। यदि किसी इंडेक्स में बहुत सारे अपडेट और डिलीट होते हैं, तो डेटा को संपीड़ित और डीकंप्रेस करने के लिए CPU लागत डेटा संपीड़न से I/O और RAM बचत से अधिक हो सकती है। प्रत्येक डेटाबेस या तालिका स्वचालित रूप से संपीड़न लागू करने के लिए एक अच्छा उम्मीदवार नहीं होगा, इसलिए अपने डेटाबेस पर डेटा संपीड़न को सक्षम करने के लिए संशोधनों को लागू करने से पहले किस प्रकार के लाभ की उम्मीद की जा सकती है, यह देखने के लिए पहले थोड़ा शोध करना सबसे अच्छा है। आपको यह देखने के लिए संपीड़न का परीक्षण करने की आवश्यकता है कि क्या यह आपके वातावरण में अच्छा काम करता है, क्योंकि यह भारी-सम्मिलित डेटाबेस में अच्छी तरह से काम नहीं कर सकता है।
संदर्भ
SQL सर्वर 2016 के संस्करण और समर्थित विशेषताएं
डेटा संपीड़न
पंक्ति संपीड़न कार्यान्वयन
पृष्ठ संपीड़न कार्यान्वयन