जहां तक ग्राफिकल एक्जीक्यूशन प्लान का सवाल है, SQL सर्वर में फिजिकल सॉर्ट के लिए सिर्फ एक आइकन है:

इसी आइकॉन का इस्तेमाल तीन लॉजिकल सॉर्ट ऑपरेटर्स के लिए किया जाता है:सॉर्ट, टॉप एन सॉर्ट, और डिस्टिंक्ट सॉर्ट:
एक स्तर पर जाने पर, निष्पादन इंजन में सॉर्ट के चार अलग-अलग कार्यान्वयन हैं (अनुकूलित लूप जॉइन के लिए बैच सॉर्टिंग की गणना नहीं करना, जो पूर्ण प्रकार नहीं है, और वैसे भी योजनाओं में दिखाई नहीं देता है)। यदि आप SQL सर्वर 2014 का उपयोग कर रहे हैं, तो निष्पादन इंजन सॉर्ट कार्यान्वयन की संख्या बढ़कर सात हो जाती है:
- CQScanSortNew
- CQScanTopSortNew
- CQScanIndexSortNew
- CQScanPartitionSortNew (केवल SQL सर्वर 2014)
- CQScanInMemSortNew
- इन-मेमोरी OLTP (हेकाटन) मूल रूप से संकलित प्रक्रिया टॉप एन सॉर्ट (केवल SQL सर्वर 2014)
- इन-मेमोरी OLTP (हेकाटन) मूल रूप से संकलित प्रक्रिया सामान्य सॉर्ट (केवल SQL सर्वर 2014)
यह आलेख इस प्रकार के कार्यान्वयन को देखता है और जब प्रत्येक SQL सर्वर में उपयोग किया जाता है। भाग एक सूची में पहले चार आइटम शामिल करता है।
1. CQScanSortNew
यह सबसे सामान्य प्रकार का वर्ग है, जिसका उपयोग तब किया जाता है जब अन्य उपलब्ध विकल्पों में से कोई भी लागू नहीं होता है। सामान्य सॉर्ट क्वेरी निष्पादन शुरू होने से ठीक पहले आरक्षित कार्यस्थान स्मृति अनुदान का उपयोग करता है। यह अनुदान कार्डिनैलिटी अनुमानों और औसत पंक्ति आकार अपेक्षाओं के समानुपाती है, और बढ़ाया नहीं जा सकता क्वेरी निष्पादन शुरू होने के बाद।
वर्तमान कार्यान्वयन विभिन्न प्रकार के आंतरिक मर्ज सॉर्ट (शायद बाइनरी मर्ज सॉर्ट) का उपयोग करता प्रतीत होता है, यदि आरक्षित मेमोरी अपर्याप्त हो जाती है, तो बाहरी मर्ज सॉर्ट (यदि आवश्यक हो तो कई पास के साथ) में संक्रमण होता है। बाहरी मर्ज सॉर्ट भौतिक tempdb का उपयोग करता है सॉर्ट रन के लिए स्थान जो मेमोरी में फिट नहीं होता (आमतौर पर सॉर्ट स्पिल के रूप में जाना जाता है)। छँटाई ऑपरेशन के दौरान विशिष्टता लागू करने के लिए सामान्य प्रकार को भी कॉन्फ़िगर किया जा सकता है।
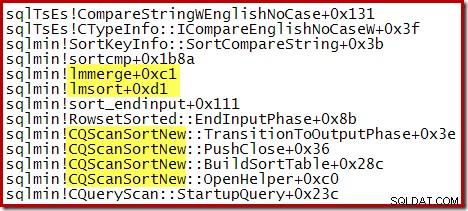
निम्नलिखित आंशिक स्टैक ट्रेस CQScanSortNew . का एक उदाहरण दिखाता है आंतरिक मर्ज सॉर्ट का उपयोग करके क्लास सॉर्टिंग स्ट्रिंग्स:
निष्पादन योजनाओं में, सॉर्ट समग्र क्वेरी वर्कस्पेस मेमोरी ग्रांट के अंश के बारे में जानकारी प्रदान करता है जो रिकॉर्ड्स (इनपुट चरण) पढ़ते समय सॉर्ट करने के लिए उपलब्ध होता है, और जब सॉर्ट किए गए आउटपुट को मूल योजना ऑपरेटरों (आउटपुट चरण) द्वारा उपभोग किया जाता है तो अंश उपलब्ध होता है )।
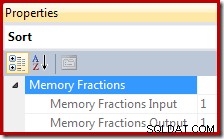
मेमोरी ग्रांट फ्रैक्शन 0 और 1 के बीच की एक संख्या है (जहाँ दी गई मेमोरी का 1 =100%) और SSMS में सॉर्ट को हाइलाइट करके और प्रॉपर्टीज विंडो में देखकर दिखाई देता है। नीचे दिया गया उदाहरण केवल एक सॉर्ट ऑपरेटर वाली क्वेरी से लिया गया था, इसलिए इसमें इनपुट और आउटपुट दोनों चरणों के दौरान पूर्ण क्वेरी वर्कस्पेस मेमोरी ग्रांट उपलब्ध है:
मेमोरी अंश इस तथ्य को दर्शाते हैं कि अपने इनपुट चरण के दौरान, सॉर्ट को समग्र क्वेरी मेमोरी अनुदान को निष्पादन योजना में समवर्ती-निष्पादित स्मृति-खपत ऑपरेटरों के साथ साझा करना होता है। इसी तरह, आउटपुट चरण के दौरान, सॉर्ट को दी गई मेमोरी को निष्पादन योजना में इसके ऊपर समवर्ती-निष्पादित मेमोरी-खपत ऑपरेटरों के साथ साझा करना होता है।
क्वेरी प्रोसेसर यह जानने के लिए पर्याप्त स्मार्ट है कि कुछ ऑपरेटर ब्लॉक कर रहे हैं (स्टॉप-एंड-गो), प्रभावी रूप से उन सीमाओं को चिह्नित कर रहे हैं जहां मेमोरी अनुदान को पुनर्नवीनीकरण और पुन:उपयोग किया जा सकता है। समानांतर योजनाओं में, सामान्य सॉर्ट के लिए उपलब्ध मेमोरी ग्रांट अंश को थ्रेड्स के बीच समान रूप से विभाजित किया जाता है, और स्क्यू (समानांतर सॉर्ट योजनाओं में स्पिलिंग का एक सामान्य कारण) के मामले में रनटाइम पर पुन:संतुलित नहीं किया जा सकता है।
SQL सर्वर 2012 और बाद में स्मृति-खपत योजना ऑपरेटरों को प्रारंभ करने के लिए आवश्यक न्यूनतम कार्यक्षेत्र स्मृति अनुदान और वांछित के बारे में अतिरिक्त जानकारी शामिल है स्मृति अनुदान (स्मृति में पूरे ऑपरेशन को पूरा करने के लिए आवश्यक स्मृति की "आदर्श" मात्रा)। निष्पादन के बाद ("वास्तविक") निष्पादन योजना में, स्मृति अनुदान प्राप्त करने में किसी भी देरी, वास्तव में उपयोग की जाने वाली स्मृति की अधिकतम मात्रा और NUMA नोड्स में स्मृति आरक्षण कैसे वितरित किया गया था, के बारे में भी नई जानकारी है।
निम्नलिखित एडवेंचरवर्क्स उदाहरण सभी एक CQScanSortNew . का उपयोग करते हैं सामान्य प्रकार:
-- एक साधारण सॉर्ट (CQScanSortNew) P.FirstName, P.MiddleName, P.LastNameFROM Person.P.P.P.FirstName, P.MiddleName, P.LastName द्वारा ऑर्डर के रूप में चुनें; - डिस्टिक्ट सॉर्ट (CQScanSortNew भी) P.FirstName, P.MiddleName, P.LastNameFROM Person.P.P.FirstName, P.MiddleName, P.LastName द्वारा ऑर्डर के रूप में P.FirstName चुनें; -- GROUP BY का उपयोग करके व्यक्त की गई समान क्वेरी-- समान विशिष्ट सॉर्ट (CQScanSortNew) निष्पादन योजना चुनें P.FirstName, P.MiddleName, P.LastNameFROM Person.Person as PGROUP by P.FirstName, P.MiddleName, P.LastNameORDER by P.FirstName , P.MiddleName, P.LastName;
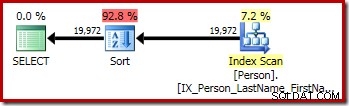
पहली क्वेरी (एक गैर-विशिष्ट प्रकार) निम्नलिखित निष्पादन योजना तैयार करती है:
दूसरे और तीसरे (समकक्ष) प्रश्न इस योजना का निर्माण करते हैं:
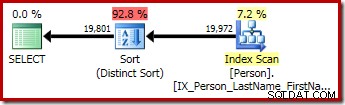
CQScanSortNew तार्किक सामान्य क्रमबद्ध और तार्किक विशिष्ट प्रकार दोनों के लिए उपयोग किया जा सकता है।
2. CQScanTopSortNew
CQScanTopSortNew CQScanSortNew . का एक उपवर्ग है टॉप एन सॉर्ट को लागू करने के लिए उपयोग किया जाता है (जैसा कि नाम से पता चलता है)। CQScanTopSortNew अधिकांश मुख्य कार्य CQScanSortNew . को सौंपते हैं , लेकिन एन के मान के आधार पर विस्तृत व्यवहार को अलग-अलग तरीकों से संशोधित करता है।
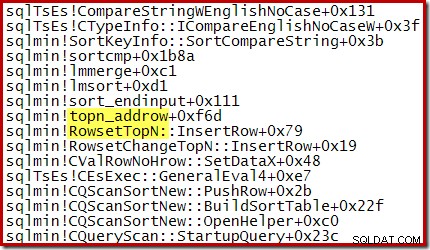
N> 100 के लिए, CQScanTopSortNew अनिवार्य रूप से केवल एक नियमित CQScanSortNew है सॉर्ट करें जो स्वचालित रूप से N पंक्तियों के बाद क्रमबद्ध पंक्तियों का उत्पादन बंद कर देता है। N <=100 के लिए, CQScanTopSortNew सॉर्ट ऑपरेशन के दौरान केवल वर्तमान शीर्ष N परिणामों को बनाए रखता है, और न्यूनतम कुंजी मान का ट्रैक रखता है जो वर्तमान में योग्यता प्राप्त करता है।
उदाहरण के लिए, एक अनुकूलित टॉप एन सॉर्ट (जहां एन <=100) के दौरान कॉल स्टैक में RowsetTopN की सुविधा होती है जबकि सेक्शन 1 में सामान्य प्रकार के साथ हमने RowsetSorted . देखा :
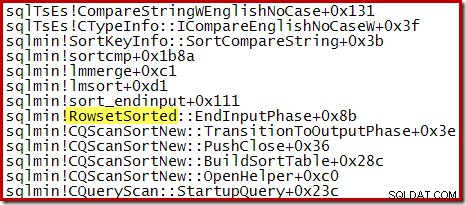
शीर्ष N सॉर्ट के लिए जहां N> 100, निष्पादन के समान चरण में कॉल स्टैक पहले देखे गए सामान्य सॉर्ट के समान होता है:
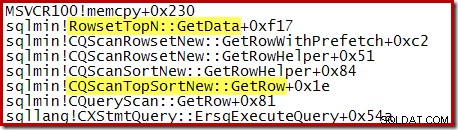
ध्यान दें कि CQScanTopSortNew वर्ग का नाम उन स्टैक ट्रेस में से किसी में भी प्रकट नहीं होता है। यह सब-क्लासिंग के काम करने के तरीके के कारण है। इन प्रश्नों के निष्पादन के दौरान अन्य बिंदुओं पर, CQScanTopSortNew विधियाँ (जैसे Open, GetRow, और CreateTopNTable) कॉल स्टैक पर स्पष्ट रूप से दिखाई देती हैं। एक उदाहरण के रूप में, निम्नलिखित को बाद में क्वेरी निष्पादन में लिया गया था और CQScanTopSortNew दिखाता है कक्षा का नाम:
टॉप एन सॉर्ट और क्वेरी ऑप्टिमाइज़र
क्वेरी ऑप्टिमाइज़र टॉप एन सॉर्ट के बारे में कुछ नहीं जानता है, जो केवल एक निष्पादन इंजन ऑपरेटर है। जब ऑप्टिमाइज़र एक (गैर-विशिष्ट) भौतिक सॉर्ट के ठीक ऊपर एक भौतिक टॉप ऑपरेटर के साथ एक आउटपुट ट्री बनाता है, तो एक पोस्ट-ऑप्टिमाइज़ेशन पुनर्लेखन दो भौतिक संचालन को एक एकल टॉप एन सॉर्ट ऑपरेटर में ध्वस्त कर सकता है। N> 100 मामले में भी, यह एक सॉर्ट आउटपुट और एक शीर्ष इनपुट के बीच पुनरावृत्त रूप से गुजरने वाली पंक्तियों पर बचत का प्रतिनिधित्व करता है।
निम्न क्वेरी ऑप्टिमाइज़र आउटपुट और पोस्ट-ऑप्टिमाइज़ेशन को क्रिया में फिर से लिखने के लिए कुछ गैर-दस्तावेजी ट्रेस फ़्लैग का उपयोग करती है:
शीर्ष चुनें (10) P.FirstName, P.MiddleName, P.LastNameFROM Person.P.P.P.FirstName, P.MiddleName, P.LastNameOPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 7352);
ऑप्टिमाइज़र का आउटपुट ट्री अलग-अलग भौतिक टॉप और सॉर्ट ऑपरेटर दिखाता है:
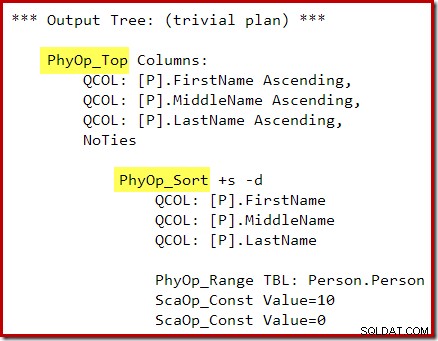
पोस्ट-ऑप्टिमाइज़ेशन पुनर्लेखन के बाद, टॉप और सॉर्ट को एकल टॉप एन सॉर्ट में संक्षिप्त कर दिया गया है:
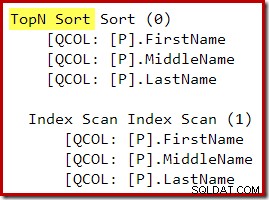
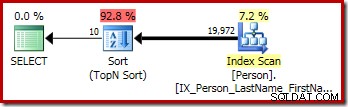
ऊपर टी-एसक्यूएल क्वेरी के लिए ग्राफिकल निष्पादन योजना एकल टॉप एन सॉर्ट ऑपरेटर को दिखाती है:
ब्रेकिंग द टॉप एन सॉर्ट पुनर्लेखन
टॉप एन सॉर्ट पोस्ट-ऑप्टिमाइज़ेशन पुनर्लेखन केवल आसन्न टॉप और गैर-विशिष्ट सॉर्ट को टॉप एन सॉर्ट में संक्षिप्त कर सकता है। ऊपर दी गई क्वेरी में DISTINCT (या समकक्ष ग्रुप बाय क्लॉज) जोड़ने से टॉप एन सॉर्ट पुनर्लेखन को रोका जा सकेगा:
DISTINCT TOP चुनें (10) P.FirstName, P.MiddleName, P.LastNameFROM Person.Person as P.FirstName, P.MiddleName, P.LastName;
इस क्वेरी के लिए अंतिम निष्पादन योजना में अलग टॉप और सॉर्ट (डिस्टिंक्ट सॉर्ट) ऑपरेटर शामिल हैं:
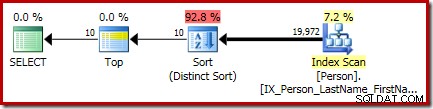
वहाँ क्रमबद्ध करें सामान्य CQScanSortNew . है क्लास अलग मोड में चल रहा है जैसा कि पहले सेक्शन 1 में देखा गया था।
टॉप एन सॉर्ट में पुनर्लेखन को रोकने का दूसरा तरीका टॉप और सॉर्ट के बीच एक या अधिक अतिरिक्त ऑपरेटरों को पेश करना है। उदाहरण के लिए:
सेलेक्ट टॉप (10) P.FirstName, P.MiddleName, P.LastName, rn =RANK() ओवर (P.FirstName द्वारा ऑर्डर) व्यक्ति से। P.FirstName, P.MiddleName, P. अंतिम नाम;
क्वेरी ऑप्टिमाइज़र के आउटपुट में अब टॉप और सॉर्ट के बीच एक ऑपरेशन होता है, इसलिए पोस्ट-ऑप्टिमाइज़ेशन रीराइट चरण के दौरान टॉप एन सॉर्ट उत्पन्न नहीं होता है:
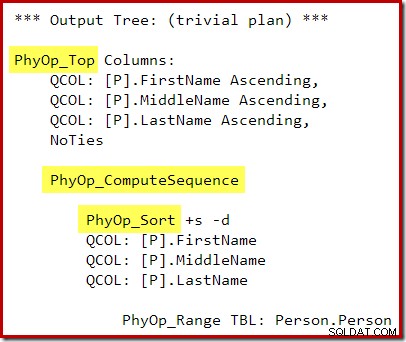
निष्पादन योजना है:

टॉप और सॉर्ट के बीच कंप्यूट सीक्वेंस (दो सेगमेंट और एक सीक्वेंस प्रोजेक्ट के रूप में लागू) टॉप के पतन को रोकता है और सिंगल टॉप एन सॉर्ट ऑपरेटर को सॉर्ट करता है। निश्चित रूप से इस योजना से अभी भी सही परिणाम प्राप्त होंगे, लेकिन संयुक्त टॉप एन सॉर्ट ऑपरेटर के साथ निष्पादन की तुलना में निष्पादन थोड़ा कम कुशल हो सकता है।
3. CQScanIndexSortNew
CQScanIndexSortNew केवल डीडीएल इंडेक्स बिल्डिंग प्लान में छँटाई के लिए उपयोग किया जाता है। यह कुछ सामान्य प्रकार की सुविधाओं का पुन:उपयोग करता है जिन्हें हमने पहले ही देखा है, लेकिन अनुक्रमणिका सम्मिलन के लिए विशिष्ट अनुकूलन जोड़ता है। यह एकमात्र प्रकार का वर्ग भी है जो गतिशील रूप से अधिक मेमोरी का अनुरोध कर सकता है निष्पादन शुरू होने के बाद।
सूचकांक निर्माण योजना के लिए कार्डिनैलिटी का अनुमान अक्सर सटीक होता है क्योंकि तालिका में पंक्तियों की कुल संख्या आमतौर पर एक ज्ञात मात्रा होती है। इसका मतलब यह नहीं है कि इंडेक्स बिल्डिंग प्लान के प्रकार के लिए मेमोरी ग्रांट हमेशा सटीक होगा; यह सिर्फ इसे डेमो के लिए थोड़ा कम आसान बनाता है। इसलिए, निम्न उदाहरण एक अनिर्दिष्ट, लेकिन यथोचित रूप से प्रसिद्ध, अद्यतन सांख्यिकी कमांड के विस्तार का उपयोग करता है ताकि ऑप्टिमाइज़र को यह सोचने में मूर्ख बनाया जा सके कि हम जिस तालिका पर एक इंडेक्स बना रहे हैं, उसकी केवल एक पंक्ति है:
- टेस्ट टेबल टेबल डीबीओ बनाएं। लोग (प्रथम नाम डीबीओ। नाम न्यूल नहीं, अंतिम नाम डीबीओ। नाम न्यूल नहीं); जाओ-- व्यक्ति से पंक्तियों की प्रतिलिपि बनाएँ। .फर्स्टनाम, P.LastNameFROM Person.Person AS P;GO-- दिखाओ तालिका में केवल 1 पंक्ति और 1 पृष्ठ है अद्यतन सांख्यिकी dbo। ROWCOUNT वाले लोग =1, पृष्ठ काउंट =1; GO-- अनुक्रमणिका निर्माण योजना क्लस्टर इंडेक्स cxON dbo बनाएं। लोग (LastName, FirstName);GO-- साफ अपड्रॉप टेबल dbo.People;
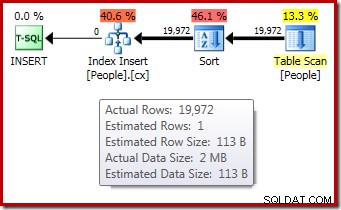
अनुक्रमणिका निर्माण के लिए निष्पादन के बाद ("वास्तविक") निष्पादन योजना 1-पंक्ति अनुमान और वास्तव में क्रमबद्ध 19,972 पंक्तियों के बावजूद एक स्पिल्ड सॉर्ट (जब SQL सर्वर 2012 या बाद में चलाए जाते हैं) के लिए कोई चेतावनी नहीं दिखाती है:
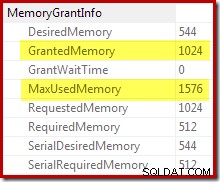
पुष्टि है कि प्रारंभिक स्मृति अनुदान गतिशील रूप से विस्तारित किया गया था रूट इटरेटर के गुणों को देखने से आता है। क्वेरी को शुरू में 1024KB मेमोरी दी गई थी, लेकिन अंततः 1576KB की खपत हुई:
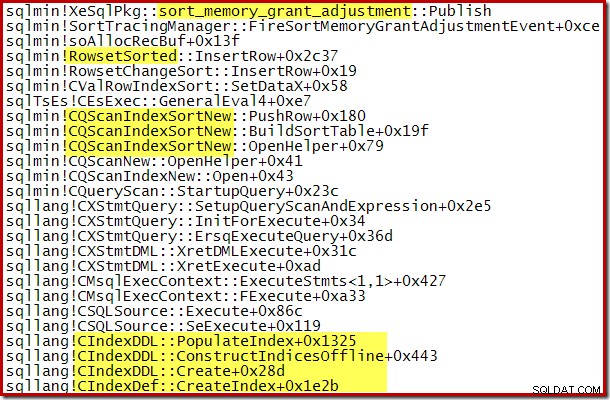
डिबग चैनल एक्सटेंडेड इवेंट sort_memory_grant_adjustment. का उपयोग करके दी गई मेमोरी में गतिशील वृद्धि को भी ट्रैक किया जा सकता है। यह घटना हर बार स्मृति आवंटन गतिशील रूप से बढ़ने पर उत्पन्न होती है। यदि इस घटना की निगरानी की जा रही है, तो हम एक स्टैक ट्रेस को प्रकाशित होने पर कैप्चर कर सकते हैं, या तो विस्तारित ईवेंट के माध्यम से (कुछ अजीब कॉन्फ़िगरेशन और ट्रेस फ़्लैग के साथ) या संलग्न डीबगर से, जैसा कि नीचे दिया गया है:
गतिशील स्मृति अनुदान विस्तार समानांतर सूचकांक निर्माण योजनाओं में भी मदद कर सकता है जहां धागे में पंक्तियों का वितरण असमान है। हालाँकि, इस तरह से खपत की जा सकने वाली मेमोरी की मात्रा असीमित नहीं है। SQL सर्वर हर बार यह देखने के लिए विस्तार की आवश्यकता की जाँच करता है कि क्या अनुरोध उस समय उपलब्ध संसाधनों को देखते हुए उचित है।
इस प्रक्रिया के बारे में कुछ अंतर्दृष्टि अनिर्दिष्ट ट्रेस फ्लैग 1504 को सक्षम करके 3604 (कंसोल में संदेश आउटपुट के लिए) या 3605 (SQL सर्वर त्रुटि लॉग के लिए आउटपुट) के साथ प्राप्त की जा सकती है। यदि अनुक्रमणिका निर्माण योजना समानांतर है, तो केवल 3605 प्रभावी है क्योंकि समानांतर कार्यकर्ता ट्रेस संदेशों को कंसोल पर क्रॉस-थ्रेड नहीं भेज सकते हैं।
ट्रेस आउटपुट का निम्न खंड सीमित मेमोरी के साथ SQL Server 2014 इंस्टेंस पर मामूली बड़ी अनुक्रमणिका बनाते समय कैप्चर किया गया था:
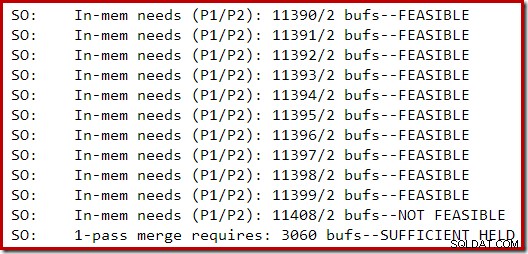
सॉर्ट के लिए मेमोरी विस्तार तब तक जारी रहा जब तक कि अनुरोध को अव्यवहारिक नहीं माना गया, जिस बिंदु पर यह निर्धारित किया गया था कि सिंगल-पास सॉर्ट स्पिल को पूरा करने के लिए पर्याप्त मेमोरी पहले से ही आयोजित की गई थी।
4. CQScanPartitionSortNew
यह वर्ग नाम सुझाव दे सकता है कि इस प्रकार का उपयोग विभाजित तालिका डेटा के लिए किया जाता है, या विभाजित तालिकाओं पर अनुक्रमणिका बनाते समय, लेकिन उनमें से कोई भी वास्तव में मामला नहीं है। विभाजित डेटा को छांटना CQScanSortNew का उपयोग करता है या CQScanTopSortNew सामान्य रूप में; विभाजित अनुक्रमणिका में प्रविष्टि के लिए पंक्तियों को क्रमबद्ध करना आमतौर पर CQScanIndexSortNew का उपयोग करता है जैसा कि खंड 3 में देखा गया है।
CQScanPartitionSortNew सॉर्ट क्लास केवल SQL सर्वर 2014 में मौजूद है। इसका उपयोग केवल विभाजन आईडी द्वारा पंक्तियों को सॉर्ट करते समय किया जाता है, विभाजित क्लस्टर्ड कॉलमस्टोर इंडेक्स में सम्मिलन से पहले . ध्यान दें कि इसका उपयोग केवल विभाजन . के लिए किया जाता है क्लस्टर्ड कॉलमस्टोर; नियमित (गैर-विभाजित) क्लस्टर्ड कॉलमस्टोर इंसर्ट प्लान एक प्रकार से लाभ नहीं उठाते हैं।
एक विभाजित क्लस्टर्ड कॉलमस्टोर इंडेक्स में सम्मिलन हमेशा एक प्रकार की सुविधा नहीं देगा। यह एक लागत-आधारित निर्णय है जो सम्मिलित की जाने वाली पंक्तियों की अनुमानित संख्या पर निर्भर करता है। अगर ऑप्टिमाइज़र का अनुमान है कि I/O को ऑप्टिमाइज़ करने के लिए इन्सर्ट को विभाजन के आधार पर छाँटना उचित है, तो कॉलमस्टोर इंसर्ट ऑपरेटर के पास DMLRequestSort होगा। संपत्ति सत्य पर सेट है, और एक CQScanPartitionSortNew निष्पादन योजना में सॉर्ट दिखाई दे सकता है।
इस खंड में डेमो अनुक्रमिक संख्याओं की एक स्थायी तालिका का उपयोग करता है। यदि आपके पास उनमें से एक नहीं है, तो निम्न स्क्रिप्ट का उपयोग एक बनाने के लिए किया जा सकता है:
-- L0 AS के साथ इट्ज़िक बेन-गण की पंक्ति जनरेटर (चयन 1 के रूप में संघ सभी का चयन करें 1), L1 के रूप में (एक क्रॉस जॉइन L0 AS B के रूप में L0 से 1 के रूप में चयन करें), L2 AS (से 1 के रूप में चयन करें) L1 एक क्रॉस जॉइन के रूप में L1 AS B), L3 AS (एक क्रॉस जॉइन L2 AS B के रूप में L2 से C चुनें), L4 AS (एक क्रॉस जॉइन L3 AS B के रूप में L3 से 1 AS c चुनें), L5 AS (चुनें) 1 के रूप में एल4 से एक क्रॉस जॉइन एल4 एएस बी के रूप में), अंक के रूप में (चयन ROW_NUMBER() ओवर (ऑर्डर द्वारा (नल का चयन करें)) एल 5 से एन के रूप में) चुनें - गंतव्य कॉलम प्रकार पूर्णांक न्यूल ISNULL नहीं है (कन्वर्ट (पूर्णांक, N.n), 0) nINTO dbo के रूप में। N.n >=1AND N.n <=1000000OPTION (MAXDOP 1);GOALTER TABLE dbo.NumbersADD CONSTRAINT PK_Numbers_n PRIMARY KEY CLUSTERED (SORT_INDTEM_n PRIMARY KEY CLUSTERED) के साथ N.n >=1AND N.n. =100);
डेमो में ही एक विभाजित क्लस्टर्ड कॉलमस्टोर इंडेक्स्ड टेबल बनाना और ऑप्टिमाइज़र को प्री-इंसर्ट पार्टीशन सॉर्ट का उपयोग करने के लिए मनाने के लिए पर्याप्त पंक्तियों को सम्मिलित करना शामिल है:
CREATE PARTITION FUNCTION PF (पूर्णांक) मानों के लिए रेंज राइट के रूप में (1000, 2000, 3000);GOCREATE PARTITION SCHEME PSAS PARTITION PFALL TO ([प्राथमिक]); GO-- एक विभाजित हेपक्रिएट टेबल dbo.Partitioned(col1 पूर्णांक नहीं NULL, col2 पूर्णांक नहीं पूर्ण डिफ़ॉल्ट ABS (चेकसम (नया ())), col3 पूर्णांक नहीं पूर्ण डिफ़ॉल्ट ABS (चेकसम (नया ())) PS (col1) पर; GO-- हीप को विभाजित क्लस्टर कॉलमस्टोर में कनवर्ट करें क्लस्टर किए गए कॉलमस्टोर इंडेक्स बनाएं ccsiON dbo.PartitionedON PS (col1);GO-- विभाजित क्लस्टर्ड कॉलमस्टोर टेबल में पंक्तियां जोड़ें।सम्मिलित करने के लिए निष्पादन योजना यह सुनिश्चित करने के लिए उपयोग की जाने वाली तरह दिखाती है कि पंक्तियों को क्लस्टर्ड कॉलमस्टोर पर आने के लिए विभाजन आईडी क्रम में पुनरावर्तक सम्मिलित करें:
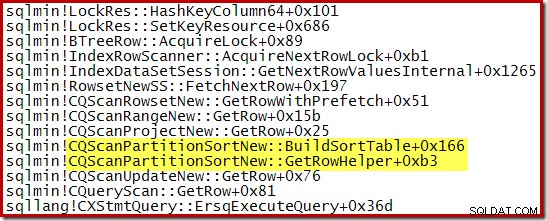
CQScanPartitionSortNew . के दौरान एक कॉल स्टैक कैप्चर किया गया क्रमाकुंचन प्रगति पर था नीचे दिखाया गया है:
इस तरह के वर्ग के बारे में कुछ और दिलचस्प है। सॉर्ट आम तौर पर अपने ओपन मेथड कॉल में अपने पूरे इनपुट का उपभोग करते हैं। छँटाई के बाद, वे अपने मूल ऑपरेटर को नियंत्रण वापस कर देते हैं। बाद में, सॉर्ट GetRow कॉल के माध्यम से सामान्य तरीके से एक बार में सॉर्ट की गई आउटपुट पंक्तियों को उत्पन्न करना शुरू कर देता है। CQScanPartitionSortNew अलग है, जैसा कि आप ऊपर कॉल स्टैक में देख सकते हैं:यह अपनी ओपन विधि के दौरान अपने इनपुट का उपभोग नहीं करता है - यह तब तक प्रतीक्षा करता है जब तक GetRow को उसके माता-पिता द्वारा पहली बार कॉल नहीं किया जाता है।
विभाजन आईडी पर हर प्रकार का नहीं जो एक निष्पादन योजना में दिखाई देता है जो एक विभाजित क्लस्टर कॉलमस्टोर इंडेक्स में पंक्तियों को सम्मिलित करता है, वह CQScanPartitionSortNew नहीं होगा। क्रम से लगाना। यदि कॉलमस्टोर इंडेक्स इंसर्ट ऑपरेटर के दाईं ओर सॉर्ट तुरंत दिखाई देता है, तो संभावना बहुत अच्छी है कि यह एक CQScanPartitionSortNew है। क्रमबद्ध करें।
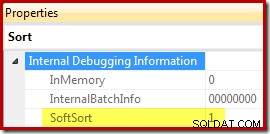
अंत में, CQScanPartitionSortNew केवल दो प्रकार के वर्गों में से एक है जो सॉफ्ट सॉर्ट संपत्ति को उजागर करता है जब सॉर्ट ऑपरेटर निष्पादन योजना गुण अनिर्दिष्ट ट्रेस ध्वज 8666 सक्षम के साथ उत्पन्न होते हैं:
इस संदर्भ में "नरम प्रकार" का अर्थ स्पष्ट नहीं है। इसे क्वेरी ऑप्टिमाइज़र के ढांचे में एक संपत्ति के रूप में ट्रैक किया जाता है, और ऐसा लगता है कि अनुकूलित विभाजित डेटा सम्मिलन से संबंधित होने की संभावना है, लेकिन इसका सही अर्थ निर्धारित करने के लिए और अधिक शोध की आवश्यकता है। इस बीच, इस संपत्ति का उपयोग यह अनुमान लगाने के लिए किया जा सकता है कि CQScanPartitionSortNew के साथ एक सॉर्ट लागू किया गया है। डीबगर संलग्न किए बिना। ऊपर दिखाए गए इनमेमोरी संपत्ति ध्वज का अर्थ भाग 2 में शामिल किया जाएगा। यह नहीं करता है इंगित करें कि स्मृति में नियमित सॉर्ट किया गया था या नहीं।
भाग एक का सारांश

- CQScanSortNew जब कोई अन्य विकल्प लागू नहीं होता है तो सामान्य प्रकार का वर्ग उपयोग किया जाता है। ऐसा प्रतीत होता है कि मेमोरी में विभिन्न प्रकार के आंतरिक मर्ज सॉर्ट का उपयोग करता है, tempdb का उपयोग करके बाहरी मर्ज सॉर्ट में संक्रमण करता है यदि दी गई स्मृति कार्यक्षेत्र अपर्याप्त हो जाता है। इस वर्ग का उपयोग सामान्य सॉर्ट और विशिष्ट सॉर्ट के लिए किया जा सकता है।
- CQScanTopSortNew टॉप एन सॉर्ट को लागू करता है। जहां एन <=100, एक इन-मेमोरी आंतरिक मर्ज सॉर्ट किया जाता है, और कभी भी tempdb तक नहीं फैलता है . सॉर्ट के दौरान स्मृति में केवल वर्तमान शीर्ष n आइटम बनाए जाते हैं। N> 100 के लिए CQScanTopSortNew एक CQScanSortNew . के बराबर है सॉर्ट करें जो N पंक्तियों के आउटपुट होने के बाद स्वचालित रूप से बंद हो जाता है। एक एन> 100 प्रकार tempdb . तक फैल सकता है यदि आवश्यक हो।
- निष्पादन योजनाओं में देखा जाने वाला टॉप एन सॉर्ट एक पोस्ट-क्वेरी-ऑप्टिमाइज़ेशन रीराइट है। यदि क्वेरी ऑप्टिमाइज़र आसन्न टॉप और गैर-विशिष्ट सॉर्ट के साथ आउटपुट ट्री उत्पन्न करता है, तो यह पुनर्लेखन दो भौतिक ऑपरेटरों को एक ही टॉप एन सॉर्ट ऑपरेटर में संक्षिप्त कर सकता है।
- CQScanIndexSortNew केवल इंडेक्स बिल्डिंग डीडीएल योजनाओं में उपयोग किया जाता है। यह एकमात्र मानक सॉर्ट क्लास है जो निष्पादन के दौरान गतिशील रूप से अधिक मेमोरी प्राप्त कर सकता है। इंडेक्स बिल्डिंग प्रकार अभी भी कुछ परिस्थितियों में डिस्क पर फैल सकता है, जिसमें SQL सर्वर यह तय करता है कि अनुरोधित स्मृति वृद्धि वर्तमान कार्यभार के अनुकूल नहीं है।
- CQScanPartitionSortNew केवल SQL सर्वर 2014 में मौजूद है और इसका उपयोग केवल एक विभाजित क्लस्टर्ड कॉलमस्टोर इंडेक्स में इन्सर्ट को ऑप्टिमाइज़ करने के लिए किया जाता है। यह एक "सॉफ्ट सॉर्ट" प्रदान करता है।
इस लेख का दूसरा भाग CQScanInMemSortNew . को देखेगा , और दो इन-मेमोरी OLTP मूल रूप से संकलित संग्रहीत कार्यविधि प्रकार।



