आपके प्रश्न का उत्तर देने के लिए कि SQL सर्वर ऐसा क्यों कर रहा है, उत्तर यह है कि क्वेरी को तार्किक क्रम में संकलित नहीं किया गया है, प्रत्येक कथन को अपनी योग्यता पर संकलित किया गया है, इसलिए जब आपके चयन कथन के लिए क्वेरी योजना तैयार की जा रही है, तो ऑप्टिमाइज़र नहीं जानता कि @val1 और @Val2 क्रमशः 'val1' और 'val2' बन जाएंगे।
जब SQL सर्वर को मान नहीं पता होता है, तो उसे इस बारे में सबसे अच्छा अनुमान लगाना होता है कि वह चर तालिका में कितनी बार दिखाई देगा, जिससे कभी-कभी उप-इष्टतम योजनाएँ बन सकती हैं। मेरा मुख्य बिंदु यह है कि विभिन्न मूल्यों के साथ एक ही प्रश्न विभिन्न योजनाएं उत्पन्न कर सकता है। इस सरल उदाहरण की कल्पना करें:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 991 1
FROM sys.all_objects a
UNION ALL
SELECT TOP 9 ROW_NUMBER() OVER(ORDER BY a.object_id) + 1
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
मैंने यहां केवल एक साधारण तालिका बनाई है, और कॉलम val के लिए मान 1-10 के साथ 1000 पंक्तियां जोड़ें। , हालांकि 1 991 बार प्रकट होता है, और अन्य 9 केवल एक बार दिखाई देते हैं। इस क्वेरी का आधार:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 1;
खोज के लिए अनुक्रमणिका का उपयोग करने की तुलना में संपूर्ण तालिका को स्कैन करने के लिए अधिक कुशल होगा, फिर Filler के लिए मान प्राप्त करने के लिए 991 बुकमार्क लुकअप करें। , हालांकि केवल 1 पंक्ति के साथ निम्नलिखित क्वेरी:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 2;
अनुक्रमणिका खोज करने के लिए अधिक कुशल होगा, और Filler के लिए मान प्राप्त करने के लिए एकल बुकमार्क लुकअप होगा (और इन दो प्रश्नों को चलाने से इसकी पुष्टि हो जाएगी)
मुझे पूरा यकीन है कि खोज और बुकमार्क लुकअप के लिए कट ऑफ वास्तव में स्थिति के आधार पर भिन्न होता है, लेकिन यह काफी कम है। उदाहरण तालिका का उपयोग करते हुए, कुछ परीक्षण और त्रुटि के साथ, मैंने पाया कि मुझे Val . की आवश्यकता है ऑप्टिमाइज़र द्वारा इंडेक्स सीक और बुकमार्क लुकअप पर पूर्ण तालिका स्कैन के लिए जाने से पहले स्तंभ में मान 2 के साथ 38 पंक्तियाँ हों:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
DECLARE @I INT = 38;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP (991 - @i) 1
FROM sys.all_objects a
UNION ALL
SELECT TOP (@i) 2
FROM sys.all_objects a
UNION ALL
SELECT TOP 8 ROW_NUMBER() OVER(ORDER BY a.object_id) + 2
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
SELECT COUNT(Filler), COUNT(*)
FROM #T
WHERE Val = 2;
तो इस उदाहरण के लिए मिलान पंक्तियों की सीमा 3.7% है।
चूंकि क्वेरी यह नहीं जानती है कि जब आप एक चर का उपयोग कर रहे हैं तो कितनी पंक्तियों का मिलान होगा, और इसका सबसे आसान तरीका कुल संख्या पंक्तियों का पता लगाना है, और इसे कॉलम में अलग-अलग मानों की कुल संख्या से विभाजित करना है, तो इस उदाहरण में WHERE val = @Val . के लिए पंक्तियों की अनुमानित संख्या 1000/10 =100 है, वास्तविक एल्गोरिदम इससे अधिक जटिल है, लेकिन उदाहरण के लिए यह करेगा। इसलिए जब हम इसके लिए निष्पादन योजना को देखते हैं:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
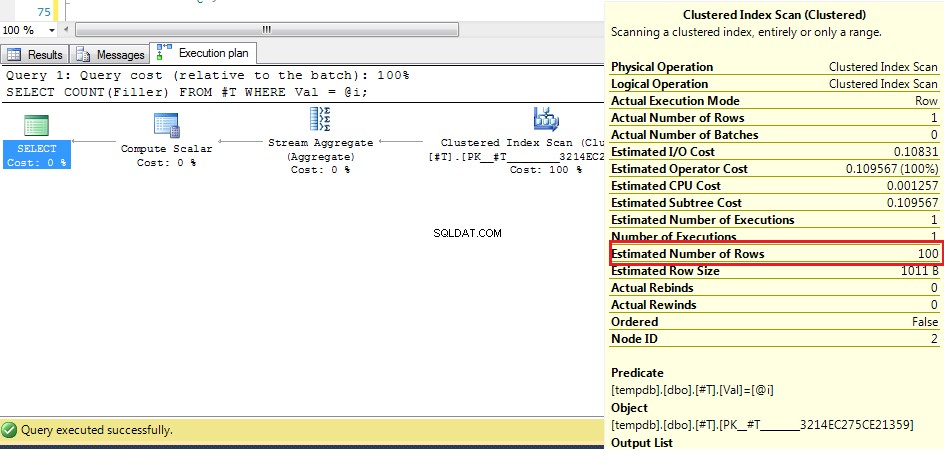
हम यहां (मूल डेटा के साथ) देख सकते हैं कि पंक्तियों की अनुमानित संख्या 100 है, लेकिन वास्तविक पंक्तियाँ 1 हैं। पिछले चरणों से हम जानते हैं कि 38 से अधिक पंक्तियों के साथ ऑप्टिमाइज़र एक इंडेक्स पर क्लस्टर्ड इंडेक्स स्कैन का विकल्प चुनेगा। तलाश करें, इसलिए चूंकि पंक्तियों की संख्या के लिए सबसे अच्छा अनुमान इससे अधिक है, अज्ञात चर के लिए योजना एक क्लस्टर इंडेक्स स्कैन है।
सिद्धांत को और सिद्ध करने के लिए, यदि हम समान रूप से वितरित संख्याओं की 1000 पंक्तियों के साथ तालिका बनाते हैं (तो अनुमानित पंक्ति गणना लगभग 1000/27 =37.037) होगी।
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 27 ROW_NUMBER() OVER(ORDER BY a.object_id)
FROM sys.all_objects a;
INSERT #T (val)
SELECT TOP 973 t1.Val
FROM #T AS t1
CROSS JOIN #T AS t2
CROSS JOIN #T AS t3
ORDER BY t2.Val, t3.Val;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
फिर क्वेरी को फिर से चलाएँ, हमें एक इंडेक्स सीक वाला प्लान मिलता है:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
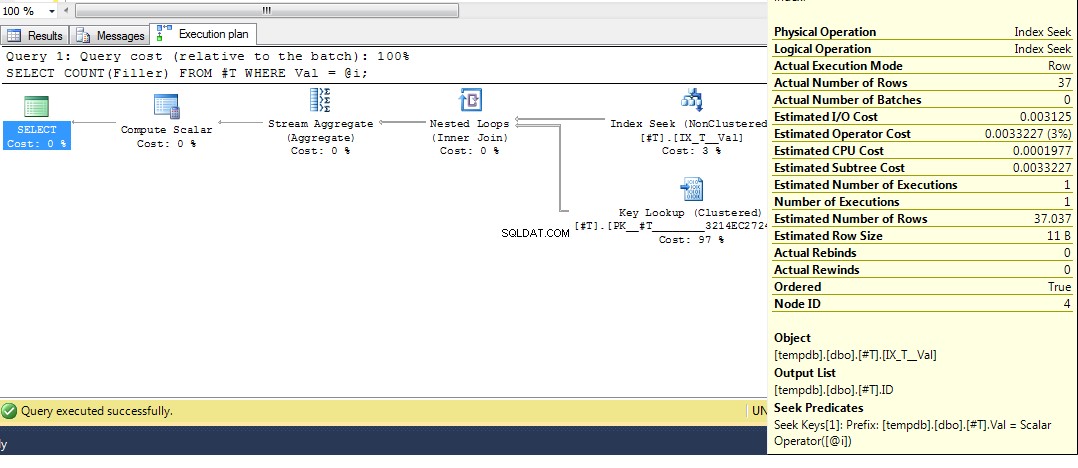
तो उम्मीद है कि काफी व्यापक रूप से कवर किया गया है कि आपको वह योजना क्यों मिलती है। अब मुझे लगता है कि अगला प्रश्न यह है कि आप एक अलग योजना को कैसे लागू करते हैं, और इसका उत्तर है, क्वेरी संकेत का उपयोग करना OPTION (RECOMPILE) , क्वेरी को निष्पादन समय पर संकलित करने के लिए बाध्य करने के लिए जब पैरामीटर का मान ज्ञात हो। मूल डेटा पर वापस लौटना, जहां Val = 2 . के लिए सर्वोत्तम योजना है एक लुकअप है, लेकिन एक वेरिएबल का उपयोग करके एक इंडेक्स स्कैन के साथ एक योजना तैयार करता है, हम चला सकते हैं:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
GO
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i
OPTION (RECOMPILE);
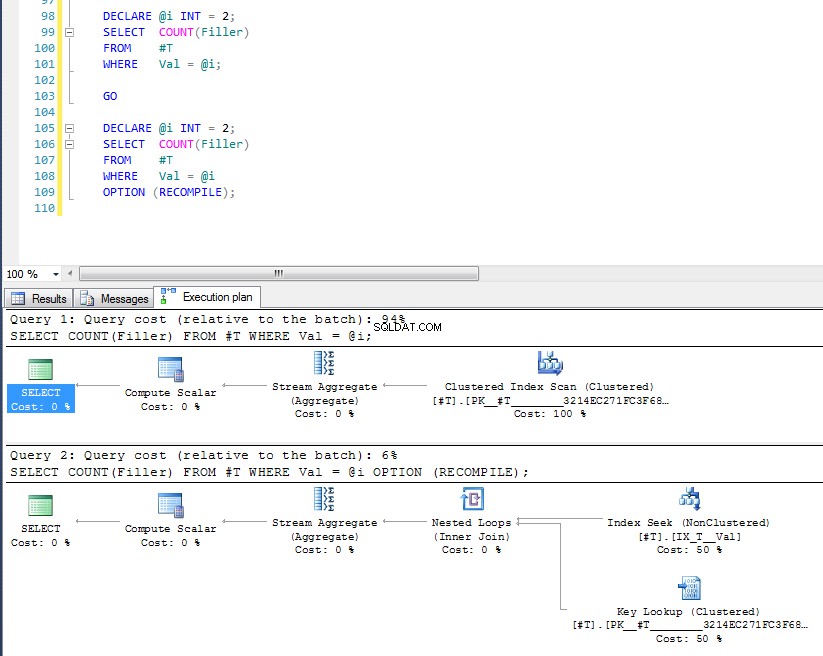
हम देख सकते हैं कि बाद वाला इंडेक्स सीक और की लुकअप का उपयोग करता है क्योंकि इसने निष्पादन के समय चर के मूल्य की जाँच की है, और उस विशिष्ट मूल्य के लिए सबसे उपयुक्त योजना का चयन किया जाता है। OPTION (RECOMPILE) . के साथ समस्या इसका मतलब है कि आप कैश्ड क्वेरी योजनाओं का लाभ नहीं उठा सकते हैं, इसलिए हर बार क्वेरी को संकलित करने की एक अतिरिक्त लागत होती है।



