तालिका अनुक्रमण रणनीति सबसे महत्वपूर्ण प्रदर्शन ट्यूनिंग और अनुकूलन कुंजियों में से एक है। SQL सर्वर में, इंडेक्स (दोनों, क्लस्टर और गैर-क्लस्टर इंडेक्स) एक बी-ट्री संरचना का उपयोग करके बनाए जाते हैं, जिसमें प्रत्येक पृष्ठ एक डबल लिंक्ड सूची नोड के रूप में कार्य करता है, जिसमें पिछले और अगले पृष्ठों के बारे में जानकारी होती है। फॉरवर्ड स्कैन नामक यह बी-पेड़ संरचना, शुरुआत से अंत तक अपने पृष्ठों को स्कैन करके या खोजकर इंडेक्स से पंक्तियों को पढ़ना आसान बनाता है। हालांकि फॉरवर्ड स्कैन डिफ़ॉल्ट और अत्यधिक ज्ञात इंडेक्स स्कैनिंग विधि है, SQL सर्वर हमें अंत से शुरुआत तक बी-ट्री संरचना के भीतर इंडेक्स पंक्तियों को स्कैन करने की क्षमता प्रदान करता है। इस क्षमता को बैकवर्ड स्कैन कहा जाता है। इस लेख में, हम देखेंगे कि यह कैसे होता है और बैकवर्ड स्कैनिंग विधि के फायदे और नुकसान क्या हैं।
SQL सर्वर हमें फॉरवर्ड स्कैन विधि का उपयोग करके इंडेक्स बी-ट्री स्ट्रक्चर नोड्स को शुरुआत से अंत तक स्कैन करके टेबल इंडेक्स से डेटा पढ़ने की क्षमता प्रदान करता है, या बी ट्री स्ट्रक्चर नोड्स को अंत से शुरुआत तक पढ़ने की क्षमता प्रदान करता है। बैकवर्ड स्कैन विधि। जैसा कि नाम से संकेत मिलता है, बैकवर्ड स्कैन इंडेक्स में शामिल कॉलम के क्रम के विपरीत पढ़ते समय किया जाता है, जो कि ORDER BY T-SQL सॉर्टिंग स्टेटमेंट में DESC विकल्प के साथ किया जाता है, जो स्कैन ऑपरेशन की दिशा निर्दिष्ट करता है।
विशिष्ट परिस्थितियों में, SQL सर्वर इंजन पाता है कि बैकवर्ड स्कैन विधि के साथ अंत से शुरुआत तक इंडेक्स डेटा को पढ़ना फॉरवर्ड स्कैन विधि के साथ अपने सामान्य क्रम में पढ़ने से तेज़ है, जिसके लिए SQL द्वारा एक महंगी सॉर्टिंग प्रक्रिया की आवश्यकता हो सकती है इंजन। ऐसे मामलों में MAX () कुल फ़ंक्शन और परिस्थितियों का उपयोग शामिल होता है जब क्वेरी परिणाम की सॉर्टिंग इंडेक्स ऑर्डर के विपरीत होती है। बैकवर्ड स्कैन पद्धति का मुख्य दोष यह है कि SQL सर्वर क्वेरी ऑप्टिमाइज़र हमेशा समानांतर निष्पादन योजनाओं से लाभ लेने में सक्षम हुए बिना, सीरियल प्लान निष्पादन का उपयोग करके इसे निष्पादित करना चुनता है।
मान लें कि हमारे पास निम्न तालिका है जिसमें कंपनी के कर्मचारियों के बारे में जानकारी होगी। तालिका को नीचे T-SQL बनाएं कथन का उपयोग करके बनाया जा सकता है:
टेबल बनाएं [डीबीओ]। nvarchar](50) NULL, [EmpDepID] [int] नॉट न्यूल, [Emp_Status] [int] नॉट न्यूल, [EMP_PhoneNumber] [nvarchar](50) NULL, [Emp_Adress] [nvarchar](max) NULL, [Emp_EmploymentDate] [डेटटाइम] न्यूल, प्राइमरी की क्लस्टर ([आईडी] एएससी) ऑन [प्राथमिक]))
तालिका बनाने के बाद, हम नीचे दिए गए INSERT कथन का उपयोग करके इसे 10K डमी रिकॉर्ड से भर देंगे:
[dbo] मेंइन्सर्ट करें। AAA','BBB',4,1,9624488779,'AMM','2006-10-15')GO 10000
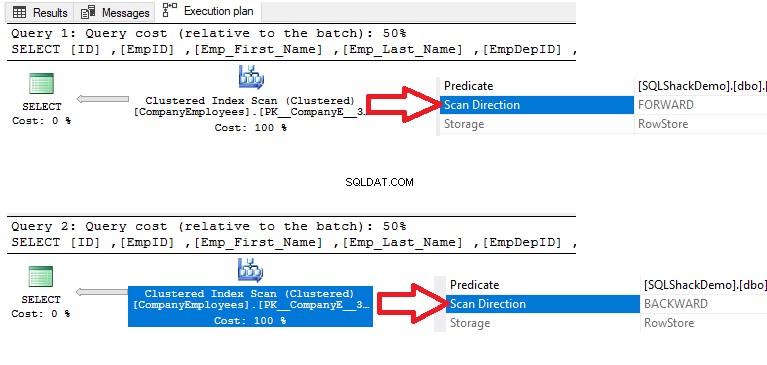
यदि हम पहले बनाई गई तालिका से डेटा पुनर्प्राप्त करने के लिए नीचे दिए गए चयन कथन को निष्पादित करते हैं, तो पंक्तियों को आरोही क्रम में आईडी कॉलम मानों के अनुसार क्रमबद्ध किया जाएगा, जो कि क्लस्टर इंडेक्स ऑर्डर के समान है:
चुनें [आईडी] ,[EmpID] ,[Emp_First_Name] ,[Emp_Last_Name] ,[EmpDepID] ,[Emp_Status] ,[EMP_PhoneNumber] ,[Emp_Adress] ,[Emp_EmploymentDate] FROM [SQLShackDemo]।[Dbo]। ] [आईडी] एएससी द्वारा आदेश
फिर उस क्वेरी के लिए निष्पादन योजना की जाँच करते हुए, नीचे दिए गए निष्पादन योजना में दिखाए गए अनुसार इंडेक्स से सॉर्ट किए गए डेटा को प्राप्त करने के लिए क्लस्टर्ड इंडेक्स पर एक स्कैन किया जाएगा:
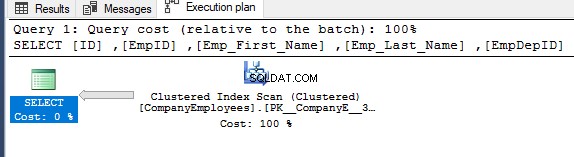
क्लस्टर इंडेक्स पर किए गए स्कैन की दिशा प्राप्त करने के लिए, नोड गुणों को ब्राउज़ करने के लिए इंडेक्स स्कैन नोड पर राइट-क्लिक करें। क्लस्टर्ड इंडेक्स स्कैन नोड प्रॉपर्टी से, स्कैन डायरेक्शन प्रॉपर्टी उस क्वेरी के भीतर इंडेक्स पर किए गए स्कैन की दिशा प्रदर्शित करेगी, जो कि फॉरवर्ड स्कैन है जैसा कि नीचे स्नैपशॉट में दिखाया गया है:

इंडेक्स स्कैनिंग दिशा को एक्सएमएल निष्पादन योजना से इंडेक्सस्कैन नोड के तहत स्कैनडायरेक्शन प्रॉपर्टी से भी पुनर्प्राप्त किया जा सकता है, जैसा कि नीचे दिखाया गया है:
मान लें कि हमें नीचे टी-एसक्यूएल क्वेरी का उपयोग करके पहले बनाई गई कंपनी कर्मचारी तालिका से अधिकतम आईडी मान प्राप्त करने की आवश्यकता है:
[dbo] सेMAX([ID]) चुनें।[कंपनी कर्मचारी]
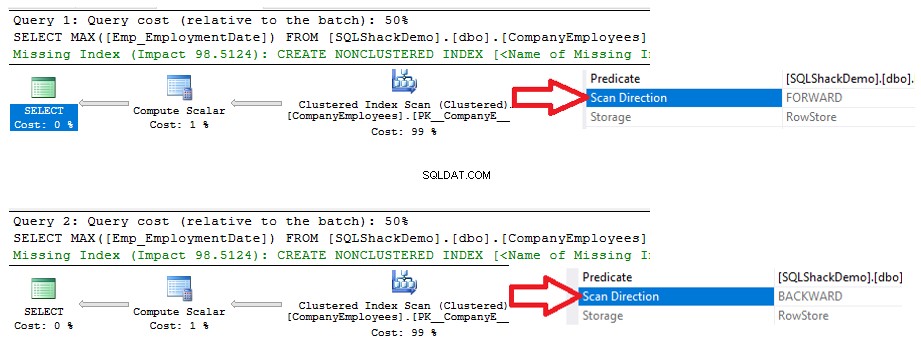
फिर उस क्वेरी को निष्पादित करने से उत्पन्न निष्पादन योजना की समीक्षा करें। आप देखेंगे कि क्लस्टर इंडेक्स पर एक स्कैन किया जाएगा जैसा कि नीचे निष्पादन योजना में दिखाया गया है:
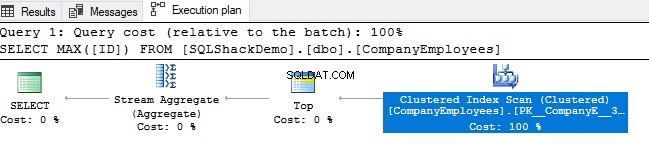
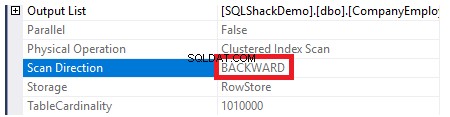
इंडेक्स स्कैन की दिशा की जांच करने के लिए, हम क्लस्टर्ड इंडेक्स स्कैन नोड के गुणों को ब्राउज़ करेंगे। परिणाम हमें दिखाएगा कि, SQL सर्वर इंजन क्लस्टर इंडेक्स को अंत से शुरुआत तक स्कैन करना पसंद करता है, जो इस मामले में तेज होगा, ताकि आईडी कॉलम का अधिकतम मूल्य प्राप्त हो सके, इस तथ्य के कारण कि इंडेक्स पहले से ही आईडी कॉलम के अनुसार क्रमबद्ध है, जैसा कि नीचे दिखाया गया है:
इसके अलावा, यदि हम निम्नलिखित SELECT स्टेटमेंट का उपयोग करके पहले से बनाए गए टेबल डेटा को पुनः प्राप्त करने का प्रयास करते हैं, तो रिकॉर्ड्स को आईडी कॉलम मानों के अनुसार सॉर्ट किया जाएगा, लेकिन इस बार, क्लस्टर इंडेक्स ऑर्डर के विपरीत, ORDER में DESC सॉर्टिंग विकल्प निर्दिष्ट करके BY खंड नीचे दिखाया गया है:
चुनें [आईडी] ,[EmpID] ,[Emp_First_Name] ,[Emp_Last_Name] ,[EmpDepID] ,[Emp_Status] ,[EMP_PhoneNumber] ,[Emp_Adress] ,[Emp_EmploymentDate] FROM [SQLShackDemo]।[Dbo]। ] [आईडी] डीईएससी द्वारा आदेश
यदि आप पिछली SELECT क्वेरी के निष्पादन के बाद उत्पन्न निष्पादन योजना की जाँच करते हैं, तो आप देखेंगे कि तालिका के अनुरोधित रिकॉर्ड प्राप्त करने के लिए क्लस्टर्ड इंडेक्स पर एक स्कैन किया जाएगा, जैसा कि नीचे दिखाया गया है:
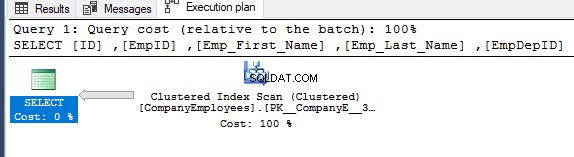
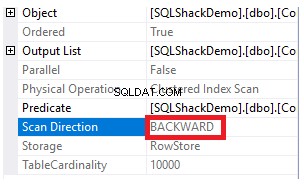
क्लस्टर्ड इंडेक्स स्कैन नोड गुण दिखाएगा कि स्कैन की दिशा जिसे SQL सर्वर इंजन लेना पसंद करता है, बैकवर्ड स्कैन दिशा है, जो इस मामले में तेज़ है, क्लस्टर इंडेक्स की वास्तविक सॉर्टिंग के विपरीत डेटा को सॉर्ट करने के कारण, यह ध्यान में रखते हुए कि सूचकांक पहले से ही आईडी कॉलम के अनुसार आरोही क्रम में क्रमबद्ध है, जैसा कि नीचे दिखाया गया है:
प्रदर्शन तुलना
मान लें कि हमारे पास नीचे दिए गए SELECT स्टेटमेंट हैं जो 2010 से दो बार हायर किए गए सभी कर्मचारियों के बारे में जानकारी प्राप्त करते हैं; पहली बार लौटाए गए परिणाम सेट को आईडी कॉलम मानों के अनुसार आरोही क्रम में क्रमबद्ध किया जाएगा, और दूसरी बार लौटाए गए परिणाम सेट को नीचे दिए गए टी-एसक्यूएल स्टेटमेंट का उपयोग करके आईडी कॉलम मानों के अनुसार अवरोही क्रम में क्रमबद्ध किया जाएगा:
चुनें [आईडी] ,[EmpID] ,[Emp_First_Name] ,[Emp_Last_Name] ,[EmpDepID] ,[Emp_Status] ,[EMP_PhoneNumber] ,[Emp_Adress] ,[Emp_EmploymentDate] FROM [SQLShackDemo]।[Dbo]। ] जहां Emp_EmploymentDate>='2010-01-01' [ID] ASC विकल्प (MAXDOP 1) द्वारा ऑर्डर करें, चुनें [ID] ,[EmpID] ,[Emp_First_Name] ,[Emp_Last_Name] ,[EmpDepID] ,[Emp_Status] ,[ EMP_PhoneNumber] ,[Emp_Adress] ,[Emp_EmploymentDate] [SQLShackDemo] से।[dbo]।दो चयन प्रश्नों को निष्पादित करके उत्पन्न निष्पादन योजनाओं की जाँच करने पर, परिणाम दिखाएगा कि डेटा को पुनः प्राप्त करने के लिए दो प्रश्नों में क्लस्टर इंडेक्स पर एक स्कैन किया जाएगा, लेकिन पहली क्वेरी में स्कैन की दिशा आगे होगी एएससी डेटा सॉर्टिंग के कारण स्कैन करें, और डीईएससी डेटा सॉर्टिंग का उपयोग करने के कारण दूसरी क्वेरी में बैकवर्ड स्कैन, डेटा को फिर से व्यवस्थित करने की आवश्यकता को बदलने के लिए, जैसा कि नीचे दिखाया गया है:
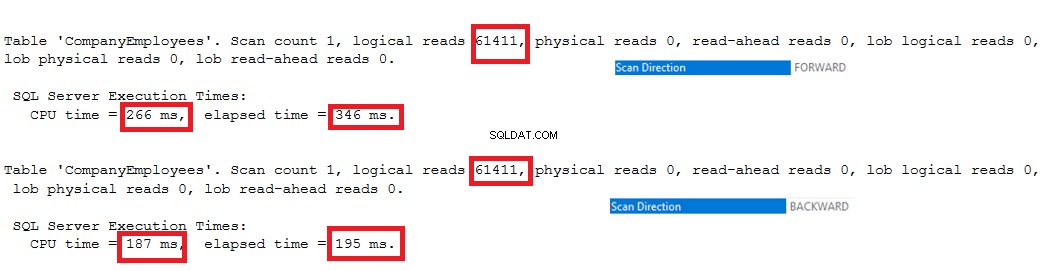
इसके अलावा, यदि हम दो प्रश्नों के IO और TIME निष्पादन आंकड़ों की जांच करते हैं, तो हम देखेंगे कि दोनों प्रश्न समान IO संचालन करते हैं और निष्पादन और CPU समय के निकट मूल्यों का उपभोग करते हैं।
ये मान हमें दिखाते हैं कि उपयोगकर्ता के लिए डेटा पुनर्प्राप्त करने के लिए सबसे उपयुक्त और सबसे तेज़ इंडेक्स स्कैनिंग दिशा चुनते समय SQL सर्वर इंजन कितना स्मार्ट है, जो पहले मामले में फॉरवर्ड स्कैन और दूसरे मामले में बैकवर्ड स्कैन है, जैसा कि नीचे दिए गए आंकड़ों से स्पष्ट है :
आइए हम पिछले MAX उदाहरण को फिर से देखें। मान लें कि हमें उन कर्मचारियों की अधिकतम आईडी प्राप्त करने की आवश्यकता है जिन्हें 2010 और बाद में काम पर रखा गया है। इसके लिए, हम निम्नलिखित सेलेक्ट स्टेटमेंट्स का उपयोग करेंगे जो पहली क्वेरी में एएससी सॉर्टिंग के साथ आईडी कॉलम वैल्यू के अनुसार रीड डेटा को सॉर्ट करेंगे और दूसरी क्वेरी में डीईएससी सॉर्टिंग के साथ:
सेलेक्ट MAX([Emp_EmploymentDate]) [SQLShackDemo] से। [एसक्यूएलशैकडेमो] से MAX([Emp_EmploymentDate]) चुनें।>आप दो सेलेक्ट स्टेटमेंट के निष्पादन से उत्पन्न निष्पादन योजनाओं से देखेंगे, कि दोनों क्वेरीज़ अधिकतम आईडी मान प्राप्त करने के लिए क्लस्टर इंडेक्स पर एक स्कैन ऑपरेशन करेंगे, लेकिन विभिन्न स्कैनिंग दिशाओं में; पहली क्वेरी में फॉरवर्ड स्कैन और दूसरी क्वेरी में बैकवर्ड स्कैन, एएससी और डीईएससी सॉर्टिंग विकल्पों के कारण, जैसा कि नीचे दिखाया गया है:
दो प्रश्नों द्वारा उत्पन्न IO आँकड़े दो स्कैनिंग दिशाओं के बीच कोई अंतर नहीं दिखाएंगे। लेकिन TIME के आंकड़े पंक्तियों की अधिकतम आईडी की गणना के बीच एक बड़ा अंतर दिखाते हैं जब इन पंक्तियों को शुरुआत से अंत तक फॉरवर्ड स्कैन विधि का उपयोग करके स्कैन किया जाता है और इसे बैकवर्ड स्कैन विधि का उपयोग करके अंत से शुरुआत तक स्कैन किया जाता है। नीचे दिए गए परिणाम से यह स्पष्ट है कि बैकवर्ड स्कैन विधि अधिकतम आईडी मान प्राप्त करने के लिए इष्टतम स्कैनिंग विधि है:
प्रदर्शन अनुकूलन
जैसा कि मैंने इस लेख की शुरुआत में उल्लेख किया है, प्रदर्शन ट्यूनिंग और अनुकूलन प्रक्रिया में क्वेरी इंडेक्सिंग सबसे महत्वपूर्ण कुंजी है। पिछली क्वेरी में, यदि हम नीचे दिए गए CREATE INDEX T-SQL स्टेटमेंट का उपयोग करके कंपनी एम्प्लॉयीज टेबल के एम्प्लॉयमेंटडेट कॉलम पर एक गैर-क्लस्टर इंडेक्स जोड़ने की व्यवस्था करते हैं:
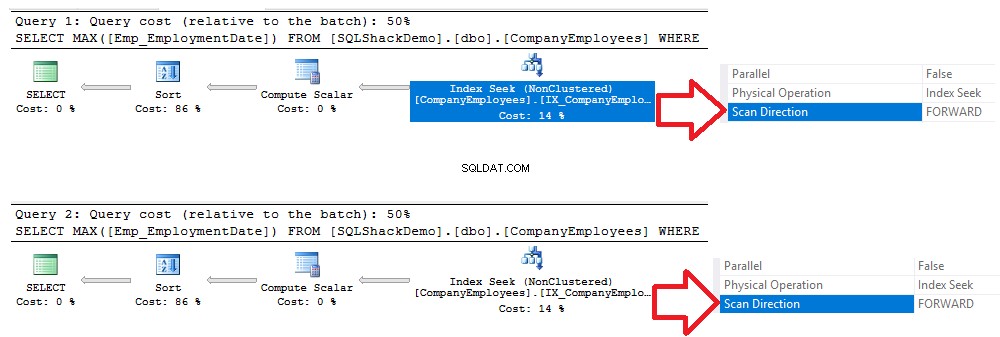
कंपनी के कर्मचारियों (Emp_EmploymentDate) पर गैर-अनुक्रमित सूचकांक IX_CompanyEmployees_Emp_EmploymentDate बनाएं उसके बाद, हम नीचे दिखाए गए समान पिछले प्रश्नों को निष्पादित करेंगे:[SQLShackDemo] से MAX([Emp_EmploymentDate]) का चयन करें। ='2017-01-01' [आईडी] एएससी विकल्प (MAXDOP 1) द्वारा आईडी आदेश द्वारा समूह [SQLShackDemo] से MAX([Emp_EmploymentDate]) चुनें।[dbo]। [कंपनी कर्मचारी] जहां [Emp_EmploymentDate]>='2017 -01-01' [आईडी] डीईएससी विकल्प (MAXDOP 1) द्वारा आईडी आदेश द्वारा समूह GOदो प्रश्नों के निष्पादन के बाद उत्पन्न निष्पादन योजनाओं की जाँच करते हुए, आप देखेंगे कि नए बनाए गए गैर-संकुल सूचकांक पर एक खोज की जाएगी, और दोनों प्रश्न सूचकांक को शुरुआत से अंत तक फॉरवर्ड स्कैन विधि का उपयोग किए बिना स्कैन करेंगे। डेटा पुनर्प्राप्ति में तेजी लाने के लिए एक बैकवर्ड स्कैन करने की आवश्यकता है, हालांकि हमने दूसरी क्वेरी में डीईएससी सॉर्टिंग विकल्प का उपयोग किया था। यह एक पूर्ण इंडेक्स स्कैन करने की आवश्यकता के बिना सीधे इंडेक्स की मांग के कारण हुआ, जैसा कि नीचे निष्पादन योजनाओं की तुलना में दिखाया गया है:
एक ही परिणाम पिछले दो प्रश्नों से उत्पन्न IO और TIME आँकड़ों से प्राप्त किया जा सकता है, जहाँ दो प्रश्न बहुत ही छोटे अंतर के साथ निष्पादन समय, CPU और IO संचालन की समान मात्रा का उपभोग करेंगे, जैसा कि नीचे दिए गए आँकड़ों के स्नैपशॉट में दिखाया गया है। :
उपयोगी टूल:
डीबीफोर्ज इंडेक्स मैनेजर - एसक्यूएल इंडेक्स की स्थिति का विश्लेषण करने और इंडेक्स विखंडन के साथ मुद्दों को ठीक करने के लिए आसान एसएसएमएस ऐड-इन।