परिचय
कुछ साल पहले हमें "सुलह" नामक किसी चीज़ के उद्देश्य के लिए एक विशिष्ट प्रारूप में कार्ड डेटा के लिए व्यावसायिक आवश्यकता का काम सौंपा गया था। विचार एक तालिका में डेटा को एक ऐसे एप्लिकेशन में प्रस्तुत करना था जो डेटा का उपभोग और संसाधित करेगा जिसमें छह महीने की अवधारण अवधि होगी। हमें इस व्यवसाय की आवश्यकता के लिए एक नया डेटाबेस बनाना था और फिर विभाजित तालिका के रूप में कोर टेबल बनाना था। यहां वर्णित प्रक्रिया वह प्रक्रिया है जिसका उपयोग हम यह सुनिश्चित करने के लिए करते हैं कि छह महीने से अधिक पुराने डेटा को तालिका से साफ तरीके से हटा दिया जाए।
विभाजन के बारे में कुछ जानकारी
टेबल पार्टिशनिंग एक डेटाबेस तकनीक है जो आपको एक तार्किक इकाई (तालिका) से संबंधित डेटा को विभाजन के एक सेट के रूप में संग्रहीत करने की अनुमति देती है जो SQL सर्वर में फ़ाइल समूह नामक एक अमूर्त परत के माध्यम से अलग भौतिक संरचना - डेटा फ़ाइलों पर बैठेगी। इस विभाजित तालिका को बनाने की प्रक्रिया में दो प्रमुख वस्तुएं शामिल हैं:
एक विभाजन समारोह :एक पार्टीशन फंक्शन परिभाषित करता है कि एक निर्दिष्ट कॉलम (पार्टीशन कॉलम) के मूल्यों के आधार पर एक विभाजित तालिका की पंक्तियों को कैसे मैप किया जाता है। विभाजित तालिका या तो सूची . पर आधारित हो सकती है या एक रेंज। हमारे उपयोग के मामले (केवल छह महीने के डेटा को संरक्षित करने) के उद्देश्य के लिए, हमने रेंज विभाजन का उपयोग किया . एक पार्टीशन फंक्शन को RANGE RIGHT या RANGE LEFT के रूप में परिभाषित किया जा सकता है। हमने RANGE RIGHT का उपयोग किया है जैसा कि लिस्टिंग 1 में कोड में दिखाया गया है, जिसका अर्थ है कि सीमा मान सीमा मान अंतराल के दाईं ओर से संबंधित होगा जब मानों को बाएं से दाएं आरोही क्रम में क्रमबद्ध किया जाता है।
-- लिस्टिंग 1:एक विभाजन फ़ंक्शन बनाएंउपयोग करें [post_office_history]GOCREATE PARTITION FUNCTIONPostTranPartFunc (datetime) as RANGE RIGHTFOR VALUES ('20190201','20190301','20190401','20190501','20190601','20190701', '20190801','20190901','20191001','20191101','20191201')जाओ विभाजन योजना :एक विभाजन योजना विभाजन समारोह पर आधारित होती है और यह निर्धारित करती है कि प्रत्येक विभाजन से संबंधित भौतिक संरचनाओं की पंक्तियों को किस भौतिक संरचना पर रखा जाएगा। यह ऐसी पंक्तियों को फाइलग्रुप में मैप करके हासिल किया जाता है। लिस्टिंग 2 एक विभाजन योजना बनाने के लिए कोड दिखाता है। विभाजन योजना बनाने से पहले, जिस फ़ाइल समूह को यह संदर्भित करेगा, वह मौजूद होना चाहिए।
-- लिस्टिंग 2:विभाजन योजना बनाएं ---- चरण 1:फ़ाइल समूह बनाएं - उपयोग करें [मास्टर] गोल्टर डेटाबेस [पोस्ट_ऑफ़िस_इतिहास] फ़ाइल समूह जोड़ें [जन] वैकल्पिक डेटाबेस [पोस्ट_ऑफ़िस_इतिहास] फ़ाइल समूह जोड़ें [फ़रवरी] डेटाबेस बदलें [पोस्ट_ऑफ़िस_इतिहास] ] फ़ाइल समूह जोड़ें [मार्च] वैकल्पिक डेटाबेस [पोस्ट_ऑफ़िस_इतिहास] फ़ाइल समूह जोड़ें [एपीआर] वैकल्पिक डेटाबेस [पोस्ट_ऑफ़िस_इतिहास] फ़ाइल समूह जोड़ें [मई] डेटाबेस बदलें [पोस्ट_ऑफ़िस_इतिहास] फ़ाइल समूह जोड़ें [जून]ALTER_ऑफ़िस डेटाबेस [पोस्ट ऑफिस डेटाबेस [पोस्ट_ऑफ़िस डेटाबेस [पोस्ट ऑफिस डेटाबेस]ALTER_ऑफ़िस डेटाबेस [पोस्ट ऑफिस डेटाबेस इतिहास] ] फ़ाइल समूह जोड़ें [अगस्त] वैकल्पिक डेटाबेस [पोस्ट_ऑफ़िस_इतिहास] फ़ाइल समूह जोड़ें [सितंबर] वैकल्पिक डेटाबेस [पोस्ट_ऑफ़िस_इतिहास] फ़ाइल समूह जोड़ें [अक्टूबर] डेटाबेस बदलें [पोस्ट_ऑफ़िस_इतिहास] फ़ाइल समूह जोड़ें [नवंबर] पोस्ट-ऑफ़िस कदम 2:प्रत्येक फ़ाइल समूह में डेटा फ़ाइलें जोड़ें --USE [मास्टर]GOALTER DATABASE [post_office_history] फ़ाइल जोड़ें (NAME =N'post_office_history_part_01', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_01.ndf', SIZE =2097152KB, FILEGROWTH=1048576 केबी) फ़ाइल समूह [जन] डेटाबेस [पोस्ट_ऑफ़िस_इतिहास] फ़ाइल जोड़ें (नाम =N'post_office_history_part_02', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_02.ndf', SIZE =2097152KB, [ FILEGROWTH =1048576KB, [FILEGROWTH =1048576KB) में FEB]डाटाबेस [post_office_history] जोड़ें फ़ाइल (NAME =N'post_office_history_part_03', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_03.ndf', SIZE =2097152KB, FILEGROWTH_ FILEGROWTH_ 1048576KB) ] फ़ाइल जोड़ें (NAME =N'post_office_history_part_04', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_04.ndf', SIZE =2097152KB, FILEGROWTH =1048576KB) फ़ाइल में फ़ाइल करने के लिए (नाम =कहानी N'post_office_history_part_05', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_05.ndf', SIZE =2097152KB, FILEGROWTH =1048576KB) से FILEGROUP [NAME]ALTER DATABASE [post_DD__LE_story (LE_NAY]ALTER DATABASE [post_office_history (LE_LE) A =N'G:\MSSQL\DATA\post_office_history_part_06. ndf', SIZE =2097152KB, FILEGROWTH =1048576KB) फ़ाइलग्रुप में [जून] डेटाबेस बदलें [post_office_history] फ़ाइल जोड़ें (NAME =N'post_office_history_part_07', FILENAME =N'G:\MSSQL\152KB_post_office.ndE =SIZ:\MSSQL\152KB_post_office. , FILEGROWTH =1048576KB) फ़ाइलग्रुप में [JUL] डेटाबेस बदलें [post_office_history] फ़ाइल जोड़ें (NAME =N'post_office_history_part_08', FILENAME =N'G:\MSSQL\DATA\post_office_history_part_76KB) TO 2097152 SIZH फ़ाइलग्रुप [अगस्त] डेटाबेस बदलें [post_office_history] फ़ाइल जोड़ें (NAME =N'post_office_history_part_09', FILENAME =N'G:\MSSQL\DATA\post_office_history_part_09.ndf', SIZE =2097152KB, 10BAFILEGROWTH तक फ़ाइल =10BAFILEGROWTH) [post_office_history] फ़ाइल जोड़ें (NAME =N'post_office_history_part_10', FILENAME =N'G:\MSSQL\DATA\post_office_history_part_10.ndf', SIZE =2097152KB, FILEGROWTH =1048576KB) फ़ाइल को फ़ाइल करने के लिए NAME =N'post_office_history_part_09', FILENAME =N'G:\MS SQL\DATA\post_office_history_part_11.ndf', SIZE =2097152KB, FILEGROWTH =1048576KB) फ़ाइलग्रुप में [NOV] वैकल्पिक डेटाबेस [post_office_history] ADD FILE (NAME =SQL N'post_office_office_part_10_', FILENAME =post_office_office_part_10_', FILENAME:ndf', SIZE =2097152KB, FILEGROWTH =1048576KB) से FILEGROUP [DEC]GO-- चरण 3:विभाजन योजना बनाएं --PRINT 'विभाजन योजना बनाना ...' GOUSE [post_office_history]GOCREATE PARTITION SCHEME PostTranPartS AS PARTITION TO(JANPartF) ,फरवरी,मार्च,अप्रैल,मई,जून,जुलाई,अगस्त,सितंबर,अक्टूबर,नवंबर,दिसंबर)जाओ
ध्यान दें कि N . के लिए विभाजन, हमेशा रहेंगे N-1 सीमाएँ। विभाजन योजना में पहले फ़ाइल समूह को परिभाषित करते समय सावधानी बरतनी चाहिए। पार्टिशन फंक्शन में सूचीबद्ध पहली सीमा पहले और दूसरे फाइलग्रुप्स के बीच होगी इस प्रकार यह सीमा मान (20190201) दूसरे विभाजन (FEB) में बैठेगा। इसके अलावा, सभी विभाजन को एक फ़ाइल समूह में रखना वास्तव में संभव है लेकिन हमने इस मामले में अलग फ़ाइल समूह चुना है।
अपने हाथों को गंदा करना
तो आइए विभाजन को बदलने के कार्य पर ध्यान दें!
पहली चीज जो हमें करने की ज़रूरत है वह यह निर्धारित करना है कि हमारा डेटा विभाजन के बीच कैसे वितरित किया जाता है ताकि हम जान सकें कि हम किस विभाजन को स्विच करना चाहते हैं। आम तौर पर हम सबसे पुराने विभाजन को बदल देंगे।
-- लिस्टिंग 3:विभाजनों में डेटा वितरण की जाँच करें --USE POST_OFFICE_HISTORYGOSELECT $PARTITION.POSTTRANPARTFUNC(DATETIME_TRAN_LOCAL) AS [PARTITION NUMBER] , MIN(DATETIME_TRAN_LOCAL) AS [MIN DATE] , MAX(DATETIME_TRAN_LOCAL) AS [MAX DATE], MAX(DATETIME_TRAN_LOCAL) COUNT(*) के रूप में [भाग में पंक्तियाँ]DBO से.POST_TRAN_TAB -- $PARTITION द्वारा विभाजित TABLEGROUP।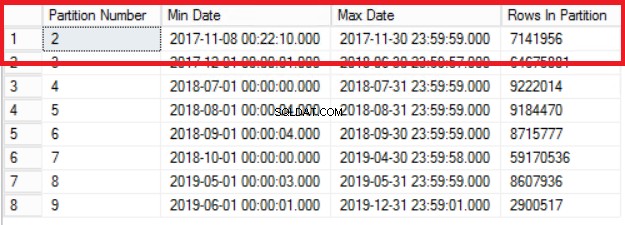
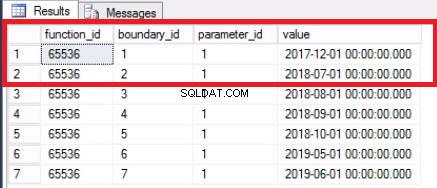
चित्र 1 लिस्टिंग 3 का आउटपुट
अंजीर। 1 हमें लिस्टिंग 3 में क्वेरी का आउटपुट दिखाता है। सबसे पुराना विभाजन विभाजन 2 है जिसमें वर्ष 2017 की पंक्तियाँ हैं। हम इसे लिस्टिंग 4 में क्वेरी के साथ सत्यापित करते हैं। लिस्टिंग 4 हमें यह भी दिखाती है कि कौन सा फ़ाइलग्रुप विभाजन में डेटा रखता है। 2.
-- लिस्टिंग 4:पार्टीशन से जुड़े फाइलग्रुप की जांच करें -- POST_OFFICE_HISTORYGOSELECT PS.NAME AS PSNAME, DDS.DESTINATION_ID AS PARTITIONNUMBER, FG.NAME AS FILEGROUPNAMEFROM (((SYS.TABLES AS T INNER JOIN SYS.INDEXES as I ON) (T.OBJECT_ID =I.OBJECT_ID)) इनर जॉइन SYS.PARTITION_SCHEMES AS PS ON (I.DATA_SPACE_ID =PS.DATA_SPACE_ID)) इनर जॉइन SYS.DESTINATION_DATA_SPACES AS DDS ON (PS.DATA_SPART. DDS.DATA_SPACE_ID =FG.DATA_SPACE_IDWHERE (T.NAME ='POST_TRAN_TAB') और (I.INDEX_ID IN (0,1)) और DDS.DESTINATION_ID =$PARTITION.POSTTRANPARTFUNC('20171108');>चित्र 1 लिस्टिंग 3 का आउटपुट
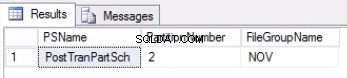
अंजीर। 2 लिस्टिंग 4 का आउटपुट
लिस्टिंग 4 हमें दिखाती है कि पार्टीशन 2 से जुड़ा फाइलग्रुप NOV है . पार्टिशन 2 को स्विच आउट करने के लिए, हमें एक हिस्ट्री टेबल की आवश्यकता होती है, जो लाइव टेबल की प्रतिकृति होती है, लेकिन उसी फाइलग्रुप पर बैठती है, जिस पार्टीशन को हम स्विच आउट करना चाहते हैं। चूंकि हमारे पास पहले से ही यह तालिका है, इसलिए हमें केवल वांछित फाइलग्रुप पर इसे फिर से बनाने की आवश्यकता है। आपको संकुल अनुक्रमणिका को फिर से बनाने की भी आवश्यकता है। ध्यान दें कि इस संकुल अनुक्रमणिका की वही परिभाषा है जो तालिका post_tran_tab पर संकुल अनुक्रमणिका की है और post_tran_tab_hist . के समान फ़ाइल समूह पर भी बैठता है टेबल।
-- लिस्टिंग 5:हिस्ट्री टेबल को फिर से बनाएं -- हिस्ट्री टेबल को फिर से बनाएं --USE [post_office_history]GOSET ANSI_NULLS ONGOSET QUOTED_IDENTIFIER ONGOSET ANSI_PADDING ONGODROP TABLE [dbo]।[post_tran_tab_hist] [GOCREATE TABLE]। post_tran_tab_hist]( [tran_nr] [bigint] NOT NULL, [tran_type] [char](2) NULL, [tran_reversed] [char](2) NULL, [batch_nr] [int] NULL, [message_type] [char](4 ) NULL, [source_node_name] [varchar](12) NULL, [system_trace_audit_nr] [char](6) NULL, [settle_currency_code] [char](3) NULL, [sink_node_name] [varchar](30) NULL, [sink_node_currency_code] [चार](3) NULL, [to_account_id] [varchar](30) NULL, [पैन] [varchar](19) NULL, [pan_encrypted] [char](18) NULL, [pan_reference] [char](70) ) न्यूल, [डेटटाइम_ट्रान_लोकल] [डेटटाइम] नॉट न्यूल, [ट्रान_अमाउंट_रेक] [फ्लोट] नॉट न्यूल, [ट्रान_अमाउंट_आरएसपी] [फ्लोट] नॉट न्यूल, [ट्रान_कैश_रेक] [फ्लोट] नॉट न्यूल, [ट्रान_कैश_आरएसपी] [फ्लोट] नॉट न्यूल, [डेटटाइम_ट्रान_जीएमटी ] [चार](10) नल, [व्यापारी_प्रकार] [चार](4) नल, [pos_entry_mode] [चार] (3) NULL, [pos_condition_code] [char](2) NULL, [acquiring_inst_id_code] [varchar](11) NULL, [retrival_reference_nr] [char](12) NULL, [auth_id_rsp] [char](6) NULL, [ rsp_code_rsp] [char](2) NULL, [service_restriction_code] [char](3) NULL, [terminal_id] [char](8) NULL, [terminal_owner] [varchar](25) NULL, [card_acceptor_id_code] [char]( 15) NULL, [card_acceptor_name_loc] [char](40) NULL, [from_account_id] [varchar](28) NULL, [auth_reason] [char](1) NULL, [auth_type] [char](1) NULL, [message_reason_code ] [चार](4) NULL, [datetime_req] [डेटाटाइम] NULL, [datetime_rsp] [डेटाटाइम] NULL, [from_account_type] [char](2) NULL, [to_account_type] [char](2) NULL, [insert_date] [डेटाटाइम] नॉट न्यूल, [ट्रान_पोस्टिलियन_ओरिजिनेटेड] [इंट] नॉट न्यूल, [कार्ड_प्रोडक्ट] [वर्कर](20) न्यूल, [कार्ड_सेक_एनआर] [चार] (3) न्यूल, [एक्सपायरी_डेट] [चार] (4) न्यूल, [srcnode_cash_स्वीकृत ] [फ्लोट] नॉट न्यूल, [ट्रान_कम्प्लीटेड] [चार](2) न्यूल) ऑन [नवंबर] GOSET ANSI_PADDING OFFGO-- क्लस्टर्ड इंडेक्स को फिर से बनाएं --USE [post_office_history]GO [dbo] पर क्लस्टर्ड इंडेक्स [IX_Datetime_Local] बनाएं। , ALLOW_ROW_LOCKS =ON, ALLOW_PAGE_LOCKS =ON) ऑन [NOV]GOअंतिम विभाजन को बदलना अब एक-पंक्ति का आदेश है। इस एक-पंक्ति कमांड को निष्पादित करने से पहले और बाद में दोनों तालिकाओं की गिनती करने से यह आश्वासन मिलेगा कि हमारे पास वांछित सभी डेटा हैं।
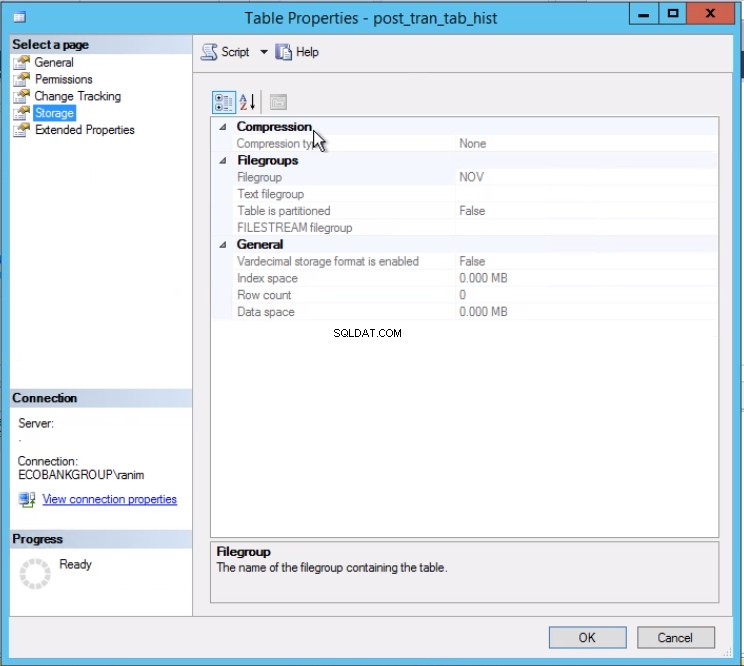
अंजीर। 3 टेबल पोस्ट_ट्रान_टैब_हिस्ट एनओवी फाइलग्रुप पर बैठता है
-- लिस्टिंग 6:'POST_TRAN_TAB' से COUNT(*) अंतिम विभाजन को स्विच आउट करना; 'POST_TRAN_TAB_HIST' से COUNT(*) चुनें; [POST_OFFICE_HISTORY]GOALTER TABLE POST_TRAN_TAB स्विच करें 'पार्टिशन 2 से POST_HISTGO_TA' चुनें POST_TRAN_TAB';'POST_TRAN_TAB_HIST' से COUNT(*) चुनें;चूंकि हमने पिछले विभाजन को बदल दिया है, हमें अब सीमा की आवश्यकता नहीं है। हम लिस्टिंग 7 में कमांड का उपयोग करके उस सीमा से पहले विभाजित दो श्रेणियों को मर्ज करते हैं। हम इतिहास तालिका को आगे बढ़ाते हैं जैसा कि लिस्टिंग 8 में दिखाया गया है। हम ऐसा इसलिए कर रहे हैं क्योंकि यह संपूर्ण बिंदु है:पुराने डेटा को हटाना जिसकी हमें अब आवश्यकता नहीं है।
-- लिस्टिंग 7:मर्जिंग पार्टिशन रेंज-- मर्ज रेंजUSE [POST_OFFICE_HISTORY]GOALTER PARTITION FUNCTION POSTTRANPARTFUNC() MERGE RANGE ('20171101');-- रेंज मर्ज किए गए हैं की पुष्टि करें [POST_OFFICE_HISTORY]GOSELECT * FROM SYS.pre_VALUESGO_>
अंजीर। 4 सीमा विलय
-- लिस्टिंग 8:हिस्ट्री टेबल को छोटा करें [post_office_history]GOTRUNCATE TABLE post_tran_tab_hist;GO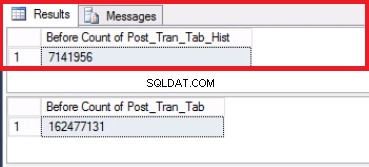
अंजीर। 5 पंक्तियों की गणना से पहले दोनों तालिकाओं के लिए छंटनी
ध्यान दें कि इतिहास तालिका में पंक्तियों की संख्या ठीक वैसी ही है जैसी पहले विभाजन 2 में पंक्तियों की संख्या थी जैसा कि चित्र 1 में दिखाया गया है। विभाजन। यह उपयोगी होगा यदि आपको नए डेटा के लिए इस स्थान की आवश्यकता है जो पहले के विभाजन पर बैठेगा। यदि आपको लगता है कि आपके वातावरण में पर्याप्त जगह है तो यह कदम आवश्यक नहीं हो सकता है।
-- लिस्टिंग 9:ऑपरेटिंग सिस्टम पर स्पेस रिकवर करें-- निर्धारित करें कि फाइल खाली हो गई हैUSE [post_office_history]GOSELECT DF.FILE_ID, DF.NAME, DF.PHYSICAL_NAME, DS.NAME, DS.TYPE, DF.STATE_DESC SYS से .DATABASE_FILES DFJOIN SYS.DATA_SPACES DS ON DF.DATA_SPACE_ID =DS.DATA_SPACE_ID;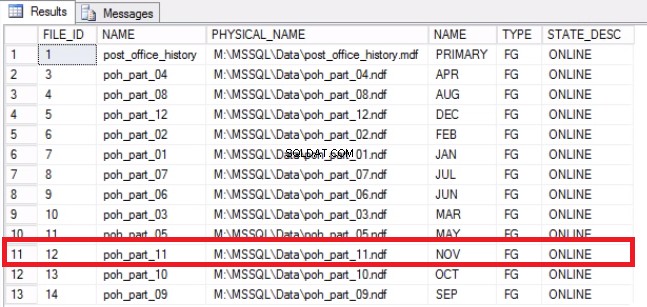
चित्र 7 फाइल टू फाइलग्रुप मैपिंग्स
-- फाइल को 2GBUSE तक सिकोड़ें [post_office_history]GODBCC SHRINKFILE (N'post_office_history_part_11', 2048)GO-- OS से डिस्क पर फ्री स्पेस की पुष्टि करें DISTINCT DB_NAME (S.DATABASE_ID) AS DATABASE_NAME,S.S.DATABASE_ID VOLUME_MOUNT_POINT--, S.VOLUME_ID, S.LOGICAL_VOLUME_NAME, S.FILE_SYSTEM_TYPE, S.TOTAL_BYTES/1024/1024/1024 AS [TOTAL_SIZE (GB)], S.AVAILABLE_BYTES/1024/1024/1024 AS [FREE] बाएँ ((ROUND (((S.AVAILABLE_BYTES*1.0)/S.TOTAL_BYTES), 4)*100),4) PERCENT_FREEFROM SYS.MASTER_FILES AS FCROSS APPLY SYS.DM_OS_VOLUME_STATS (F.DATABASE_ID, F.FILE_ID) AS SWHERE_ (S.DATABASE_ID) ='POST_OFFICE_HISTORY';
चित्र. 8 ऑपरेटिंग सिस्टम पर खाली जगह
निष्कर्ष
इस लेख में, हमने विभाजन तालिका से विभाजन को बदलने की प्रक्रिया का पूर्वाभ्यास किया है। यह SQL सर्वर में मूल रूप से डेटा वृद्धि को प्रबंधित करने का एक बहुत ही कुशल तरीका है। अधिक उन्नत प्रौद्योगिकियां जैसे स्ट्रेच डेटाबेस SQL सर्वर के वर्तमान संस्करणों में उपलब्ध हैं।
संदर्भ
इसाकोव, वी। (2018)। परीक्षा रेफरी 70-764 एक SQL डेटाबेस इन्फ्रास्ट्रक्चर का प्रशासन। पियर्सन एजुकेशन
SQL सर्वर में विभाजित टेबल और इंडेक्स