अपने पिछले लेख में, मैंने संक्षेप में डेटाबेस आँकड़ों, इसके महत्व और आँकड़ों को अद्यतन क्यों किया जाना चाहिए, इसके बारे में बताया है। इसके अलावा, मैंने आंकड़ों को अद्यतन करने के लिए SQL सर्वर रखरखाव योजना बनाने के लिए चरण दर चरण प्रक्रिया का प्रदर्शन किया है। इस लेख में, निम्नलिखित मुद्दों की व्याख्या की जाएगी:1. टी-एसक्यूएल कमांड का उपयोग करके आंकड़े कैसे अपडेट करें। 2. टी-एसक्यूएल का उपयोग करते हुए बार-बार अद्यतन की जाने वाली तालिकाओं की पहचान कैसे करें और बार-बार सम्मिलित/अद्यतन/हटाए गए डेटा के साथ तालिकाओं के आंकड़ों को कैसे अद्यतन करें।
T-SQL का उपयोग करके आंकड़े अपडेट करना
आप टी-एसक्यूएल स्क्रिप्ट का उपयोग करके आंकड़े अपडेट कर सकते हैं। यदि आप टी-एसक्यूएल या एसक्यूएल सर्वर प्रबंधन स्टूडियो का उपयोग करके आंकड़े अपडेट करना चाहते हैं, तो आपको डेटाबेस में बदलाव . की आवश्यकता होगी डेटाबेस पर अनुमति। किसी विशिष्ट तालिका के आँकड़ों को अद्यतन करने के लिए T-SQL कोड उदाहरण देखें:
UPDATE STATISTICS <schema_name>.<table_name>.
आइए ऑर्डरलाइन . के आंकड़ों को अपडेट करने के उदाहरण पर विचार करें WideWorldImporters . की तालिका डेटाबेस। निम्नलिखित स्क्रिप्ट ऐसा करेगी।
UPDATE STATISTICS [Sales].[OrderLines]
यदि आप किसी विशिष्ट अनुक्रमणिका के आँकड़ों को अद्यतन करना चाहते हैं, तो आप निम्न स्क्रिप्ट का उपयोग कर सकते हैं:
UPDATE STATISTICS <schema_name>.<table_name> <index_name>
यदि आप IX_Sales_OrderLines_Perf_20160301_02 के आंकड़े अपडेट करना चाहते हैं ऑर्डरलाइन . की अनुक्रमणिका तालिका, आप निम्न स्क्रिप्ट निष्पादित कर सकते हैं:
UPDATE STATISTICS [Sales].[OrderLines] [IX_Sales_OrderLines_Perf_20160301_02]
आप पूरे डेटाबेस के आंकड़े भी अपडेट कर सकते हैं। यदि आपके पास कुछ तालिकाओं और कम मात्रा में डेटा वाला बहुत छोटा डेटाबेस है, तो आप डेटाबेस के भीतर सभी तालिकाओं के आंकड़ों को अपडेट कर सकते हैं। निम्न स्क्रिप्ट देखें:
USE wideworldimporters go EXEC Sp_updatestats
अक्सर डाले गए/अपडेट/हटाए गए डेटा वाली तालिकाओं के आंकड़े अपडेट करना
बड़े डेटाबेस पर, सांख्यिकी कार्य को शेड्यूल करना जटिल हो जाता है, विशेष रूप से जब आपके पास अनुक्रमणिका रखरखाव करने, आँकड़ों को अद्यतन करने और अन्य रखरखाव कार्यों को पूरा करने के लिए केवल कुछ घंटे होते हैं। एक बड़े डेटाबेस से मेरा मतलब एक ऐसे डेटाबेस से है जिसमें हजारों टेबल होते हैं और प्रत्येक टेबल में हजारों पंक्तियाँ होती हैं। उदाहरण के लिए, हमारे पास X नाम का एक डेटाबेस है। इसमें सैकड़ों टेबल हैं, और प्रत्येक तालिका में लाखों पंक्तियाँ हैं। और केवल कुछ टेबल ही बार-बार अपडेट होते हैं। अन्य तालिकाओं को शायद ही कभी बदला जाता है और उन पर बहुत कम लेनदेन किए जाते हैं। जैसा कि मैंने पहले उल्लेख किया है, डेटाबेस के प्रदर्शन को बनाए रखने के लिए, तालिका के आँकड़े अद्यतित होने चाहिए। इसलिए हम एक्स डेटाबेस के भीतर सभी तालिकाओं के आंकड़ों को अद्यतन करने के लिए एक SQL रखरखाव योजना बनाते हैं। जब SQL सर्वर किसी तालिका के आँकड़ों को अद्यतन करता है, तो यह महत्वपूर्ण मात्रा में संसाधनों का उपयोग करता है जिससे प्रदर्शन समस्या हो सकती है। इसलिए, सैकड़ों बड़ी तालिकाओं के आँकड़ों को अद्यतन करने में एक लंबा समय लगता है और जब आँकड़े अद्यतन किए जा रहे होते हैं, तो डेटाबेस का प्रदर्शन काफी कम हो जाता है। ऐसी परिस्थितियों में, हमेशा सलाह दी जाती है कि केवल उन तालिकाओं के लिए आँकड़ों को अद्यतन किया जाए जिन्हें अक्सर अद्यतन किया जाता है। आप निम्न गतिशील प्रबंधन दृश्यों का उपयोग करके समय के साथ डेटा मात्रा या पंक्तियों की संख्या में हुए परिवर्तनों पर नज़र रख सकते हैं:1. sys.partitions तालिका में पंक्तियों की कुल संख्या के बारे में जानकारी प्रदान करता है। 2. sys.dm_db_partition_stats प्रति विभाजन पंक्ति गणना और पृष्ठ गणना के बारे में जानकारी प्रदान करता है। 3. sys.dm_db_index_physical_stats पंक्तियों और पृष्ठों की संख्या के बारे में जानकारी प्रदान करता है, साथ ही अनुक्रमणिका विखंडन के बारे में जानकारी और बहुत कुछ प्रदान करता है। डेटा वॉल्यूम के बारे में विवरण महत्वपूर्ण हैं, लेकिन वे डेटाबेस गतिविधि की तस्वीर को पूर्ण नहीं बनाते हैं। उदाहरण के लिए, एक स्टेजिंग टेबल जिसमें लगभग समान संख्या में रिकॉर्ड होते हैं, उसे टेबल से हटाया जा सकता है या हर दिन एक टेबल में डाला जा सकता है। उसके कारण, पंक्तियों की संख्या का एक स्नैपशॉट यह सुझाव देगा कि तालिका स्थिर है। यह संभव हो सकता है कि जोड़े और हटाए गए रिकॉर्ड में बहुत भिन्न मान हों जो डेटा वितरण को भारी रूप से बदलते हैं। इस स्थिति में, SQL सर्वर में आँकड़ों को स्वचालित रूप से अद्यतन करना आँकड़ों को अर्थहीन बना देता है। इसलिए, किसी तालिका में संशोधनों की संख्या को ट्रैक करना बहुत उपयोगी है। यह निम्नलिखित तरीकों से किया जा सकता है:1. rowmodctr sys.sysindexes 2 में कॉलम। modified_count sys.system_internals_partition_columns में कॉलम 3. modification_counter sys.dm_db_stats_properties में कॉलम इस प्रकार, जैसा कि मैंने पहले बताया, यदि आपके पास डेटाबेस रखरखाव के लिए सीमित समय है, तो हमेशा डेटा परिवर्तन की उच्च आवृत्ति (सम्मिलित / अद्यतन / हटाएं) के साथ केवल तालिकाओं के लिए आंकड़ों को अद्यतन करने की सलाह दी जाती है। इसे कुशलतापूर्वक करने के लिए, मैंने एक स्क्रिप्ट बनाई है जो "सक्रिय" तालिकाओं के आंकड़ों को अद्यतन करती है। स्क्रिप्ट निम्नलिखित कार्य करती है:• आवश्यक पैरामीटर घोषित करता है • #tempstatistics नामक एक अस्थायी तालिका बनाता है तालिका का नाम, स्कीमा नाम और डेटाबेस नाम संग्रहीत करने के लिए • #tempdatabase नामक एक अन्य तालिका बनाता है डेटाबेस नाम स्टोर करने के लिए। सबसे पहले, दो टेबल बनाने के लिए निम्न स्क्रिप्ट निष्पादित करें:
DECLARE @databasename VARCHAR(500) DECLARE @i INT=0 DECLARE @DBCOunt INT DECLARE @SQLCOmmand NVARCHAR(max) DECLARE @StatsUpdateCOmmand NVARCHAR(max) CREATE TABLE #tempstatistics ( databasename VARCHAR(max), tablename VARCHAR(max), schemaname VARCHAR(max) ) CREATE TABLE #tempdatabases ( databasename VARCHAR(max) ) INSERT INTO #tempdatabases (databasename) SELECT NAME FROM sys.databases WHERE database_id > 4 ORDER BY NAME
इसके बाद, एक गतिशील SQL क्वेरी बनाने के लिए थोड़ी देर लूप लिखें जो सभी डेटाबेस के माध्यम से पुनरावृत्त होती है और उन तालिकाओं की एक सूची सम्मिलित करती है जिनका संशोधन काउंटर 200 से अधिक है #tempstatistics टेबल। डेटा परिवर्तनों के बारे में जानकारी प्राप्त करने के लिए, मैं sys.dm_db_stats_properties का उपयोग करता हूं . निम्नलिखित कोड उदाहरण का अध्ययन करें:
SET @DBCOunt=(SELECT Count(*) FROM #tempdatabases) WHILE ( @i < @DBCOunt ) BEGIN DECLARE @DBName VARCHAR(max) SET @DBName=(SELECT TOP 1 databasename FROM #tempdatabases) SET @SQLCOmmand= ' use [' + @DBName + ']; select distinct ''' + @DBName+ ''', a.TableName,a.SchemaName from (SELECT obj.name as TableName, b.name as SchemaName,obj.object_id, stat.name, stat.stats_id, last_updated, modification_counter FROM [' + @DBName+ '].sys.objects AS obj inner join ['+ @DBName + '].sys.schemas b on obj.schema_id=b.schema_id INNER JOIN [' + @DBName+ '].sys.stats AS stat ON stat.object_id = obj.object_id CROSS APPLY [' + @DBName+'].sys.dm_db_stats_properties(stat.object_id, stat.stats_id) AS sp WHERE modification_counter > 200 and obj.name not like ''sys%''and b.name not like ''sys%'')a' INSERT INTO #tempstatistics (databasename, tablename, schemaname) EXEC Sp_executesql @SQLCOmmand
अब, पहले लूप के भीतर दूसरा लूप बनाएं। यह एक गतिशील SQL क्वेरी उत्पन्न करेगा जो पूर्ण स्कैन के साथ आँकड़ों को अद्यतन करता है। नीचे दिए गए कोड उदाहरण देखें:
DECLARE @j INT=0 DECLARE @StatCount INT SET @StatCount =(SELECT Count(*) FROM #tempstatistics) WHILE @J < @StatCount BEGIN DECLARE @DatabaseName_Stats VARCHAR(max) DECLARE @Table_Stats VARCHAR(max) DECLARE @Schema_Stats VARCHAR(max) DECLARE @StatUpdateCommand NVARCHAR(max) SET @DatabaseName_Stats=(SELECT TOP 1 databasename FROM #tempstatistics) SET @Table_Stats=(SELECT TOP 1 tablename FROM #tempstatistics) SET @Schema_Stats=(SELECT TOP 1 schemaname FROM #tempstatistics) SET @StatUpdateCommand='Update Statistics [' + @DatabaseName_Stats + '].[' + @Schema_Stats + '].[' + @Table_Stats + '] with fullscan' EXEC Sp_executesql @StatUpdateCommand SET @example@sqldat.com + 1 DELETE FROM #tempstatistics WHERE databasename = @DatabaseName_Stats AND tablename = @Table_Stats AND schemaname = @Schema_Stats END SET @example@sqldat.com + 1 DELETE FROM #tempdatabases WHERE databasename = @DBName END
एक बार स्क्रिप्ट का निष्पादन पूरा हो जाने पर, यह सभी अस्थायी तालिकाओं को छोड़ देगा।
SELECT * FROM #tempstatistics DROP TABLE #tempdatabases DROP TABLE #tempstatistics
पूरी स्क्रिप्ट इस प्रकार दिखाई देगी:
--set count on CREATE PROCEDURE Statistics_maintenance AS BEGIN DECLARE @databasename VARCHAR(500) DECLARE @i INT=0 DECLARE @DBCOunt INT DECLARE @SQLCOmmand NVARCHAR(max) DECLARE @StatsUpdateCOmmand NVARCHAR(max) CREATE TABLE #tempstatistics ( databasename VARCHAR(max), tablename VARCHAR(max), schemaname VARCHAR(max) ) CREATE TABLE #tempdatabases ( databasename VARCHAR(max) ) INSERT INTO #tempdatabases (databasename) SELECT NAME FROM sys.databases WHERE database_id > 4 ORDER BY NAME SET @DBCOunt=(SELECT Count(*) FROM #tempdatabases) WHILE ( @i < @DBCOunt ) BEGIN DECLARE @DBName VARCHAR(max) SET @DBName=(SELECT TOP 1 databasename FROM #tempdatabases) SET @SQLCOmmand= ' use [' + @DBName + ']; select distinct ''' + @DBName+ ''', a.TableName,a.SchemaName from (SELECT obj.name as TableName, b.name as SchemaName,obj.object_id, stat.name, stat.stats_id, last_updated, modification_counter FROM [' + @DBName+ '].sys.objects AS obj inner join ['+ @DBName + '].sys.schemas b on obj.schema_id=b.schema_id INNER JOIN [' + @DBName+ '].sys.stats AS stat ON stat.object_id = obj.object_id CROSS APPLY [' + @DBName+'].sys.dm_db_stats_properties(stat.object_id, stat.stats_id) AS sp WHERE modification_counter > 200 and obj.name not like ''sys%''and b.name not like ''sys%'')a' INSERT INTO #tempstatistics (databasename, tablename, schemaname) EXEC Sp_executesql @SQLCOmmand DECLARE @j INT=0 DECLARE @StatCount INT SET @StatCount =(SELECT Count(*) FROM #tempstatistics) WHILE @J < @StatCount BEGIN DECLARE @DatabaseName_Stats VARCHAR(max) DECLARE @Table_Stats VARCHAR(max) DECLARE @Schema_Stats VARCHAR(max) DECLARE @StatUpdateCommand NVARCHAR(max) SET @DatabaseName_Stats=(SELECT TOP 1 databasename FROM #tempstatistics) SET @Table_Stats=(SELECT TOP 1 tablename FROM #tempstatistics) SET @Schema_Stats=(SELECT TOP 1 schemaname FROM #tempstatistics) SET @StatUpdateCommand='Update Statistics [' + @DatabaseName_Stats + '].[' + @Schema_Stats + '].[' + @Table_Stats + '] with fullscan' EXEC Sp_executesql @StatUpdateCommand SET @example@sqldat.com + 1 DELETE FROM #tempstatistics WHERE databasename = @DatabaseName_Stats AND tablename = @Table_Stats AND schemaname = @Schema_Stats END SET @example@sqldat.com + 1 DELETE FROM #tempdatabases WHERE databasename = @DBName END SELECT * FROM #tempstatistics DROP TABLE #tempdatabases DROP TABLE #tempstatistics END
आप SQL सर्वर एजेंट जॉब बनाकर इस स्क्रिप्ट को स्वचालित भी कर सकते हैं जो इसे एक निर्धारित समय पर निष्पादित करेगा। इस कार्य को स्वचालित करने का चरण-दर-चरण निर्देश नीचे दिया गया है।
SQL जॉब बनाना
सबसे पहले, प्रक्रिया को स्वचालित करने के लिए एक SQL जॉब बनाएं। ऐसा करने के लिए, SSMS खोलें, वांछित सर्वर से कनेक्ट करें और SQL सर्वर एजेंट का विस्तार करें, नौकरियां पर राइट-क्लिक करें और नई नौकरी . चुनें . 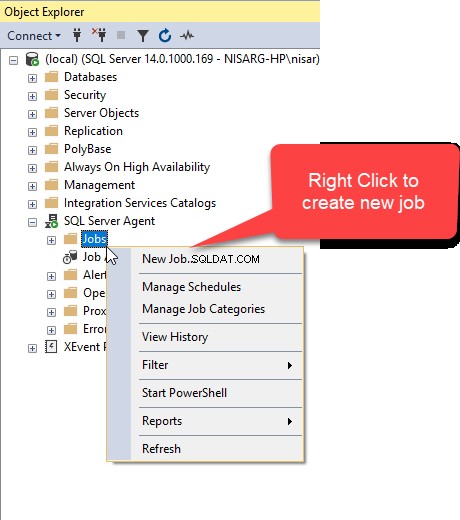 नई नौकरी में डायलॉग बॉक्स में, नाम . में वांछित नाम टाइप करें खेत।
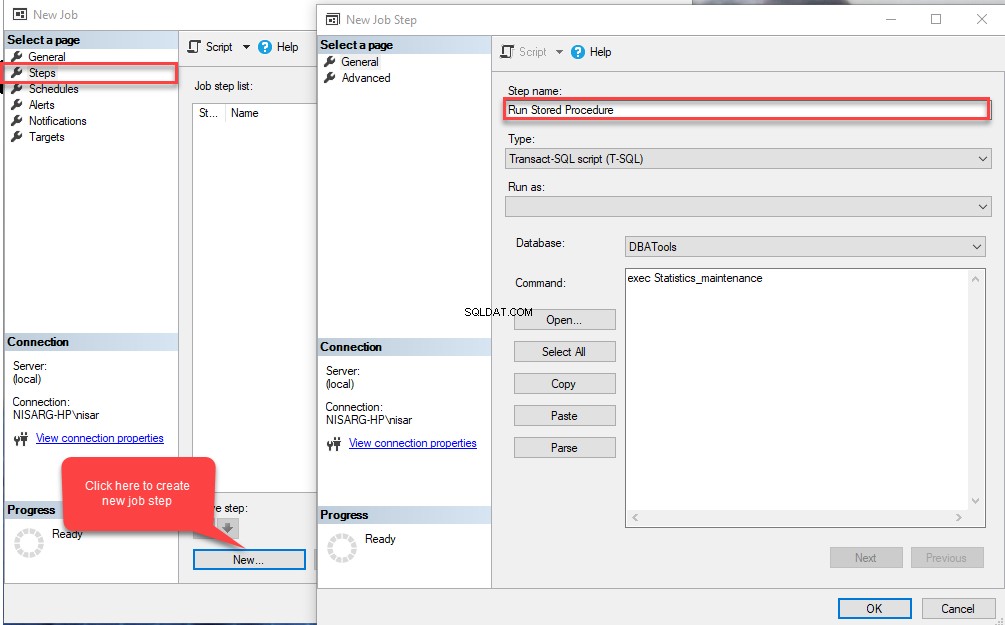
नई नौकरी में डायलॉग बॉक्स में, नाम . में वांछित नाम टाइप करें खेत। 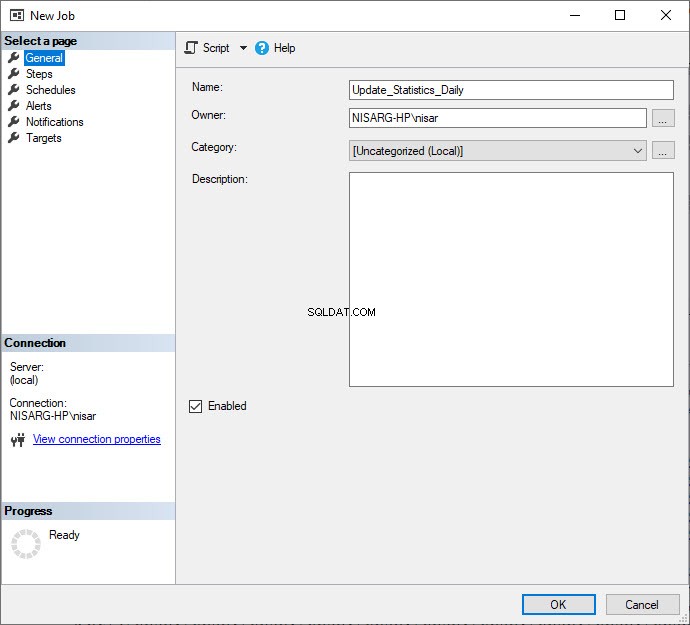 अब, कदम क्लिक करें नई नौकरी . के बाएं पैनल पर मेनू विकल्प डायलॉग बॉक्स, फिर नया . क्लिक करें चरणों . में खिड़की। नए कार्य चरण . में खुलने वाला डायलॉग बॉक्स चरण नाम . में वांछित नाम प्रदान करें खेत। इसके बाद, लेन-देन-एसक्यूएल स्क्रिप्ट (टी-एसक्यूएल) चुनें प्रकार . में ड्रॉप डाउन बॉक्स। फिर, DBAtools . चुनें डेटाबेस . में ड्रॉप-डाउन बॉक्स और कमांड टेक्स्ट बॉक्स में निम्न क्वेरी लिखें:
अब, कदम क्लिक करें नई नौकरी . के बाएं पैनल पर मेनू विकल्प डायलॉग बॉक्स, फिर नया . क्लिक करें चरणों . में खिड़की। नए कार्य चरण . में खुलने वाला डायलॉग बॉक्स चरण नाम . में वांछित नाम प्रदान करें खेत। इसके बाद, लेन-देन-एसक्यूएल स्क्रिप्ट (टी-एसक्यूएल) चुनें प्रकार . में ड्रॉप डाउन बॉक्स। फिर, DBAtools . चुनें डेटाबेस . में ड्रॉप-डाउन बॉक्स और कमांड टेक्स्ट बॉक्स में निम्न क्वेरी लिखें:
EXEC Statistics_maintenance
 कार्य का शेड्यूल कॉन्फ़िगर करने के लिए, शेड्यूल क्लिक करें नई नौकरी . में मेनू विकल्प संवाद बकस। नई कार्य अनुसूची डायलॉग बॉक्स खुलता है। नाम . में फ़ील्ड, वांछित शेड्यूल नाम प्रदान करें। हमारे उदाहरण में, हम चाहते हैं कि यह कार्य हर रात 1 बजे निष्पादित किया जाए, इसलिए होता है फ़्रीक्वेंसी . में ड्रॉप-डाउन बॉक्स अनुभाग में, दैनिक . चुनें . में एक बार होता है दैनिक आवृत्ति . में फ़ील्ड अनुभाग, 01:00:00 दर्ज करें।
कार्य का शेड्यूल कॉन्फ़िगर करने के लिए, शेड्यूल क्लिक करें नई नौकरी . में मेनू विकल्प संवाद बकस। नई कार्य अनुसूची डायलॉग बॉक्स खुलता है। नाम . में फ़ील्ड, वांछित शेड्यूल नाम प्रदान करें। हमारे उदाहरण में, हम चाहते हैं कि यह कार्य हर रात 1 बजे निष्पादित किया जाए, इसलिए होता है फ़्रीक्वेंसी . में ड्रॉप-डाउन बॉक्स अनुभाग में, दैनिक . चुनें . में एक बार होता है दैनिक आवृत्ति . में फ़ील्ड अनुभाग, 01:00:00 दर्ज करें। 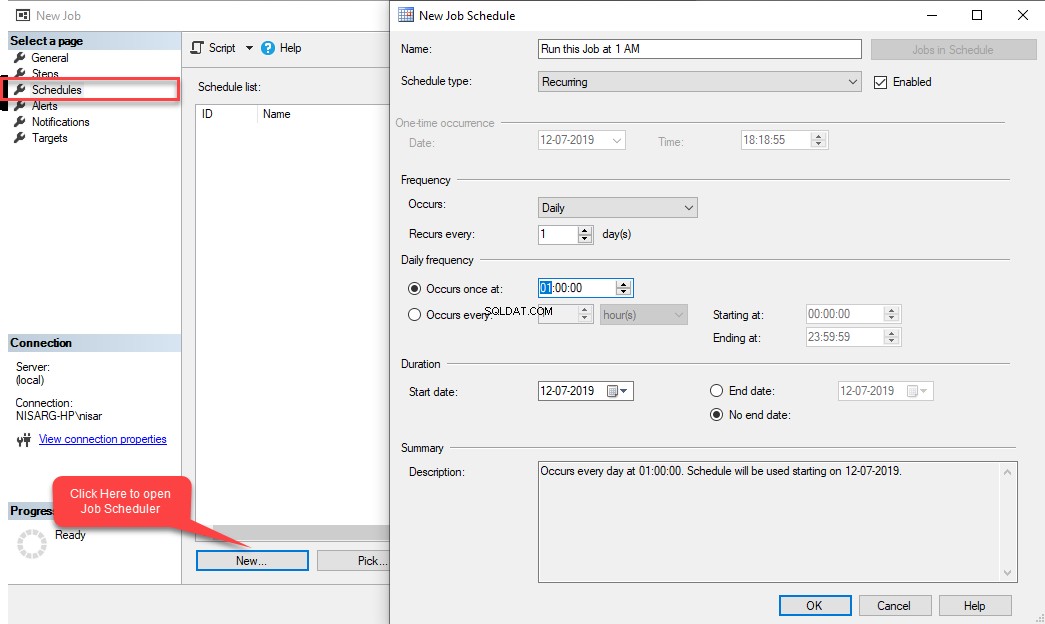 ठीक क्लिक करें नई कार्य अनुसूची को बंद करने के लिए विंडो और फिर ठीक . क्लिक करें फिर से नई नौकरी . में इसे बंद करने के लिए डायलॉग बॉक्स। आइए अब इस कार्य का परीक्षण करें। SQL सर्वर एजेंट के अंतर्गत, Update_Statistics_Daily पर राइट-क्लिक करें .
ठीक क्लिक करें नई कार्य अनुसूची को बंद करने के लिए विंडो और फिर ठीक . क्लिक करें फिर से नई नौकरी . में इसे बंद करने के लिए डायलॉग बॉक्स। आइए अब इस कार्य का परीक्षण करें। SQL सर्वर एजेंट के अंतर्गत, Update_Statistics_Daily पर राइट-क्लिक करें . 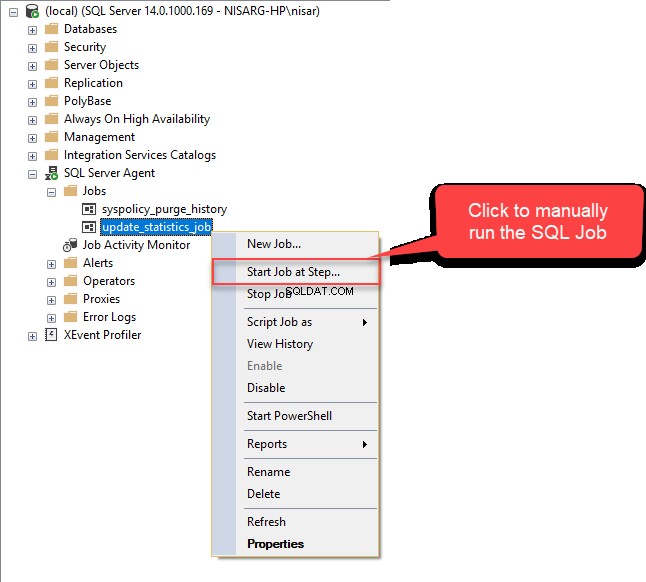 यदि कार्य सफलतापूर्वक निष्पादित हो गया है, तो आपको निम्न विंडो दिखाई देगी।
यदि कार्य सफलतापूर्वक निष्पादित हो गया है, तो आपको निम्न विंडो दिखाई देगी। 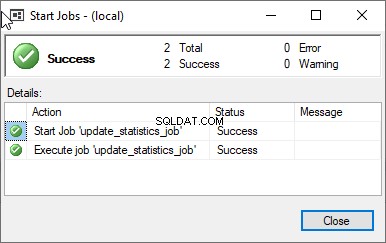
सारांश
इस लेख में, निम्नलिखित मुद्दों को शामिल किया गया है:1. टी-एसक्यूएल स्क्रिप्ट का उपयोग करके टेबल के आंकड़ों को कैसे अपडेट करें। 2. डेटा वॉल्यूम में परिवर्तन और डेटा परिवर्तन की आवृत्ति के बारे में जानकारी कैसे प्राप्त करें। 3. सक्रिय तालिकाओं पर आंकड़ों को अद्यतन करने वाली स्क्रिप्ट कैसे बनाएं। 4. निर्धारित समय पर स्क्रिप्ट निष्पादित करने के लिए SQL सर्वर एजेंट जॉब कैसे बनाएं।



