मान लीजिए कि आप किसी कंपनी के सीईओ के लिए SQL सर्वर डेटाबेस एप्लिकेशन डिज़ाइन कर रहे हैं और आपको कंपनी में पांचवें सबसे अधिक वेतन पाने वाले कर्मचारी को प्रदर्शित करना है।
आप क्या करेंगे? एक समाधान इस तरह से एक प्रश्न लिखना है:
कर्मचारियों से कर्मचारी का नाम चुनें वेतन के आधार पर DESCOFFSET 4 ROWSFETCH केवल पहली 1 पंक्तियाँ;
ऊपर की क्वेरी बोझिल लगती है, खासकर यदि आपको सभी कर्मचारियों को रैंक करना है। उस स्थिति में, एक उपाय यह है कि कर्मचारियों को वेतन के अवरोही क्रम से सूचीबद्ध किया जाए और फिर कर्मचारी के सूचकांक को रैंक के रूप में लिया जाए। हालांकि, अगर कई कर्मचारियों का वेतन समान हो तो चीजें जटिल हो जाती हैं। आप उन्हें कैसे रैंक करेंगे?
सौभाग्य से, SQL सर्वर अंतर्निहित रैंकिंग फ़ंक्शन के साथ आता है जिसका उपयोग विभिन्न तरीकों से रिकॉर्ड को रैंक करने के लिए किया जा सकता है। इस लेख में, हम SQL सर्वर रैंकिंग फ़ंक्शंस को उदाहरणों के साथ विस्तार से पेश करेंगे।
SQL सर्वर में चार अलग-अलग प्रकार के रैंकिंग फ़ंक्शन हैं:
- रैंक ()
- Dense_Rank()
- पंक्ति संख्या ()
- एनटाइल ()
यह उल्लेख करना महत्वपूर्ण है कि SQL सर्वर में सभी रैंकिंग कार्यों के लिए ORDER BY क्लॉज की आवश्यकता होती है।
इससे पहले कि हम प्रत्येक रैंकिंग फ़ंक्शन को विस्तार से देखें, पहले हम डमी डेटा बनाते हैं जिसका उपयोग हम इस लेख में रैंकिंग फ़ंक्शन की व्याख्या करने के लिए करेंगे। निम्न स्क्रिप्ट निष्पादित करें:
डेटाबेस शोरूम बनाएं, शोरूम का उपयोग करें, टेबल कार बनाएं (CarId int पहचान (1,1) प्राथमिक कुंजी, नाम varchar (100), varchar (100), मॉडल int, मूल्य int, प्रकार varchar (20)) कार में डालें (नाम , मेक, मॉडल, मूल्य, प्रकार) मान ('कोरोला', 'टोयोटा', 2015, 20000, 'सेडान'), ('सिविक', 'होंडा', 2018, 25000, 'सेडान'), ('पासो' , 'टोयोटा', 2012, 18000, 'हैचबैक'), ('लैंड क्रूजर', 'टोयोटा', 2017, 40000, 'एसयूवी'), ('कोरोला', 'टोयोटा', 2011, 17000, 'सेडान') ,('विट्ज़', 'टोयोटा', 2014, 15000, 'हैचबैक'), ('एकॉर्ड', 'होंडा', 2018, 28000, 'सेडान'), ('7500', 'बीएमडब्ल्यू', 2015, 50000, 'सेडान'), ('पैराडो', 'टोयोटा', 2011, 25000, 'एसयूवी'), ('सी200', 'मर्सिडीज', 2010, 26000, 'सेडान'), ('कोरोला', 'टोयोटा', 2014, 19000, 'सेडान'), ('सिविक', 'होंडा', 2015, 20000, 'सेडान') ऊपर की स्क्रिप्ट में, हम एक टेबल कार के साथ शोरूम डेटाबेस बनाते हैं। कार तालिका में पांच विशेषताएं हैं:CarId, नाम, मेक, मॉडल, मूल्य और प्रकार।
इसके बाद, हमने कार तालिका में 12 डमी रिकॉर्ड जोड़े।
अब, आप प्रत्येक रैंकिंग फ़ंक्शन को देखते हैं।
<एच3>1. रैंक फ़ंक्शनSQL सर्वर में रैंक फ़ंक्शन ORDER BY क्लॉज द्वारा आदेशित प्रत्येक रिकॉर्ड को रैंक प्रदान करता है। उदाहरण के लिए, यदि आप कार तालिका में पांचवीं सबसे महंगी कार देखना चाहते हैं, तो आप निम्न प्रकार से रैंक फ़ंक्शन का उपयोग कर सकते हैं:
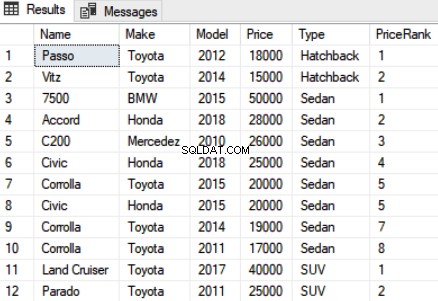
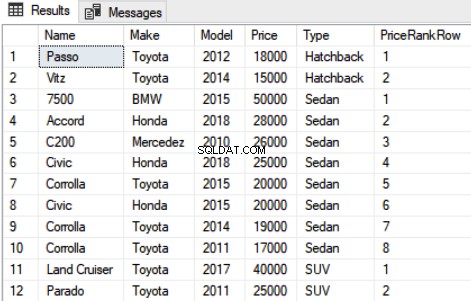
शोरूम का उपयोग करें नाम, मेक, मॉडल, मूल्य, प्रकार, रैंक() ओवर (मूल्य डीईएससी द्वारा ऑर्डर) PriceRankFROM कार के रूप में
उपरोक्त स्क्रिप्ट में, "प्राइसरैंक" कॉलम के रूप में प्राइस द्वारा ऑर्डर की गई प्रत्येक कार का नाम, मेक, मॉडल, मूल्य, प्रकार और रैंक चुनें। रैंक फ़ंक्शन के लिए सिंटैक्स सरल है। आपको फ़ंक्शन RANK और उसके बाद OVER ऑपरेटर लिखना होगा। OVER ऑपरेटर के अंदर, आपको ORDER BY क्लॉज पास करना होगा जो डेटा को सॉर्ट करता है। ऊपर की स्क्रिप्ट का आउटपुट इस तरह दिखता है:
आप प्रत्येक कार के लिए रैंक देख सकते हैं। यह उल्लेख करना महत्वपूर्ण है कि यदि दो रिकॉर्ड के रैंक के बीच एक टाई है, तो अगली रैंकिंग स्थिति को छोड़ दिया जाता है। उदाहरण के लिए, आउटपुट में रिकॉर्ड 5 और 6 के बीच एक टाई है। Parado और Civic दोनों की कीमतें समान हैं, और इसलिए उन्हें 5 रैंक दिया गया है। हालांकि, अगली रैंक, विशेष रूप से, रैंक 6 को छोड़ दिया गया है और सूची में अगली दो कारों को 7 रैंक दिया गया है क्योंकि उनकी कीमत भी समान है। 7वीं रैंक के बाद, रैंक 8 को फिर से छोड़ दिया जाता है और अगली नियत रैंक 9 होती है।
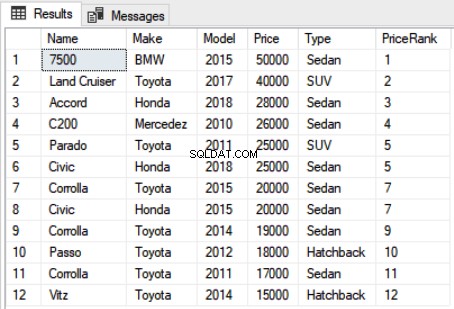
आप डेटा को विभाजन में विभाजित कर सकते हैं और फिर रैंकिंग को अलग-अलग विभाजनों पर लागू कर सकते हैं। निम्नलिखित लिपि में, प्रकार के अनुसार अभिलेखों का विभाजन है। हम प्रत्येक विभाजन के अंदर कारों को रैंक करते हैं।
कार से प्राइसरैंक के रूप में नाम, मेक, मॉडल, मूल्य, प्रकार, रैंक () ओवर (पार्टीशन बाय टाइप ऑर्डर बाय प्राइस डीईएससी) चुनें।ऊपर की स्क्रिप्ट का आउटपुट इस तरह दिखता है:
आउटपुट से यह स्पष्ट है कि रिकॉर्ड को कार के प्रकार के अनुसार विभाजित किया गया है और विभाजन के अंदर रैंक को स्थानीय रूप से सौंपा गया है। उदाहरण के लिए, पहले दो रिकॉर्ड "हैचबैक" विभाजन से संबंधित हैं और उन्हें 1 और 2 रैंक दिया गया है। अगले विभाजन, यानी "सेडान" के लिए, रैंक को 1 पर रीसेट कर दिया गया है।
<एच3>2. Dense_Rank फ़ंक्शनसघन_रैंक फ़ंक्शन रैंक फ़ंक्शन के समान है। हालाँकि, सघन_रैंक के मामले में, यदि रैंक के संदर्भ में दो रिकॉर्ड के बीच एक टाई है, तो अगली रैंक को नहीं छोड़ा जाता है। आइए इसे उदाहरण के साथ प्रदर्शित करते हैं। निम्न स्क्रिप्ट निष्पादित करें:
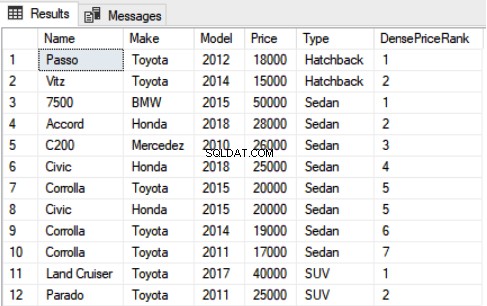
कार से DensePriceRank के रूप में शोरूम का चयन करें नाम, मेक, मॉडल, मूल्य, प्रकार, DENSE_RANK() OVER(ORDER by Price DESC) का उपयोग करें
फिर से आप देख सकते हैं कि 5वें और 6वें रिकॉर्ड का मूल्य के लिए समान मूल्य है और दोनों को रैंक 5 सौंपा गया है। हालांकि, रैंक फ़ंक्शन के विपरीत जो अगली रैंक को छोड़ देता है, सघन_रैंक फ़ंक्शन अगले रैंक को नहीं छोड़ता है, और रैंक 6 अगले रिकॉर्ड को सौंपा गया है।
रैंक फ़ंक्शन की तरह, घने_रैंक फ़ंक्शन को खंड द्वारा विभाजन पर भी लागू किया जा सकता है। निम्नलिखित स्क्रिप्ट को देखें:
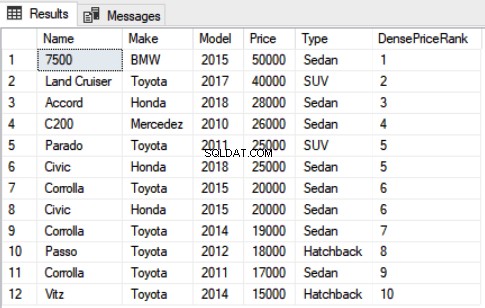
कार से DensePriceRank के रूप में नाम, मेक, मॉडल, मूल्य, प्रकार, DENSE_RANK () ओवर (मूल्य DESC द्वारा क्रम से विभाजन) चुनेंऊपर की स्क्रिप्ट का आउटपुट इस तरह दिखता है:
<एच3>3. Row_Number फ़ंक्शन
Row_number फ़ंक्शन ORDER BY क्लॉज द्वारा निर्दिष्ट शर्तों के अनुसार रिकॉर्ड को रैंक भी करता है। हालांकि, रैंक और सघन_रैंक फ़ंक्शन के विपरीत, पंक्ति_नंबर फ़ंक्शन समान रैंक प्रदान नहीं करता है जहां ORDER BY क्लॉज द्वारा निर्दिष्ट कॉलम के लिए डुप्लिकेट मान होते हैं। निम्नलिखित स्क्रिप्ट को देखें:
नाम, मेक, मॉडल, मूल्य, प्रकार, DENSE_RANK () ओवर (पार्टीशन बाय टाइप ऑर्डर बाय प्राइस डीईएससी) DensePriceRankFROM कार के रूप में चुनेंऊपर की स्क्रिप्ट का आउटपुट इस तरह दिखता है:
ऊपर की स्क्रिप्ट से, आप देख सकते हैं कि मूल्य कॉलम के लिए 5वें और 6वें दोनों रिकॉर्ड का मान समान है, लेकिन उन्हें दी गई रैंक अलग है।
इसी तरह, विभाजित डेटा पर row_number फ़ंक्शन लागू किया जा सकता है। उदाहरण के लिए निम्न स्क्रिप्ट को देखें।
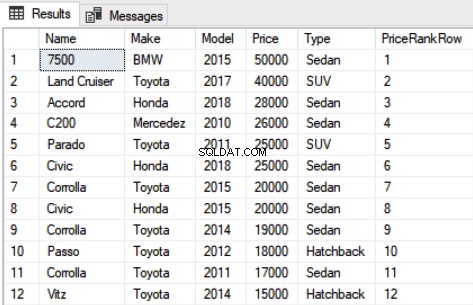
नाम, मेक, मॉडल, मूल्य, प्रकार, ROW_NUMBER() ओवर (मूल्य डीईएससी द्वारा क्रम के अनुसार विभाजन) कार से PriceRankRow के रूप में चुनेंऊपर की स्क्रिप्ट का आउटपुट इस तरह दिखता है:
<एच3>4. NTILE फंक्शन
NTILE फ़ंक्शन रैंकिंग को समूहीकृत करता है। मान लीजिए कि आपके पास एक तालिका में 12 रिकॉर्ड हैं, और आप उन्हें 4 के समूहों में रैंक करना चाहते हैं। पहले तीन रिकॉर्ड में रैंक 1 होगा, अगले तीन रिकॉर्ड में रैंक 2 होगा और इसी तरह।
आइए NTILE फ़ंक्शन के एक उदाहरण पर एक नज़र डालें।
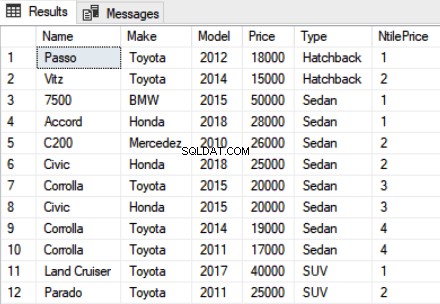
शोरूम का उपयोग करेंनाम, मेक, मॉडल, मूल्य, प्रकार, NTILE(4) OVER(ऑर्डर बाय प्राइस DESC) NtilePriceFROM कार के रूप मेंउपरोक्त स्क्रिप्ट में, हमने NTILE फ़ंक्शन के पैरामीटर के रूप में 4 पास किया है। चूंकि हमारे पास 12 रिकॉर्ड हैं, आप कुल 4 अलग-अलग रैंक देखेंगे जहां 1 रैंक तीन रिकॉर्ड को सौंपा जाएगा। आउटपुट इस तरह दिखता है:
आप देख सकते हैं कि पहली तीन सबसे महंगी कारों को 1 स्थान दिया गया है, अगले तीन को दूसरा स्थान दिया गया है और इसी तरह।
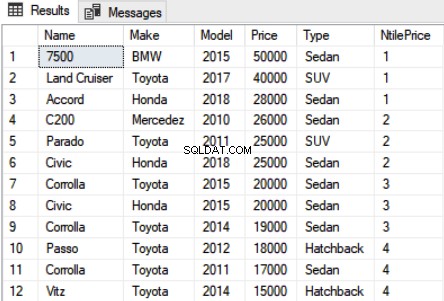
NTILE फ़ंक्शन को विभाजित डेटा पर भी लागू किया जा सकता है। निम्नलिखित स्क्रिप्ट को देखें:
नाम, मेक, मॉडल, मूल्य, प्रकार, NTILE(4) ओवर (पार्टीशन बाय टाइप ऑर्डर बाय प्राइस DESC) को NtilePriceFROM कार के रूप में चुनें
निष्कर्ष
SQL सर्वर में रैंकिंग फ़ंक्शन का उपयोग डेटा को विभिन्न तरीकों से रैंक करने के लिए किया जाता है। इस रीड में, हमने उदाहरणों के साथ विभिन्न प्रकार के रैंकिंग फ़ंक्शन पेश किए। रैंक और डेंस_रैंक फ़ंक्शन ORDER BY क्लॉज में समान मान वाले डेटा को समान रैंक देते हैं जबकि row_number फ़ंक्शन टाई होने पर भी वृद्धिशील तरीके से रिकॉर्ड को रैंक करता है।
निर्दिष्ट कॉलम में कोई डुप्लिकेट रिकॉर्ड नहीं होने की स्थिति में ORDER BY क्लॉज, रैंक, डेंस_रैंक और रो_नंबर फ़ंक्शंस एक समान तरीके से व्यवहार करते हैं।