आप शायद जानते हैं कि एकल या एकाधिक VALUES क्लॉज का उपयोग करके किसी तालिका में रिकॉर्ड कैसे सम्मिलित करें। आप यह भी जानते हैं कि SQL INSERT INTO SELECT का उपयोग करके बल्क इंसर्ट कैसे करें। लेकिन आपने फिर भी लेख पर क्लिक किया। क्या यह डुप्लिकेट को संभालने के बारे में है?
कई लेख SQL INSERT INTO SELECT को कवर करते हैं। Google या Bing इसे और वह शीर्षक चुनें जो आपको सबसे अच्छा लगे - यह करेगा। मैं बुनियादी उदाहरणों को कवर नहीं करूंगा कि यह कैसे किया जाता है। इसके बजाय, आपको इसका उपयोग करने और एक ही समय में डुप्लिकेट को संभालने के उदाहरण दिखाई देंगे . तो, आप अपने INSERT प्रयासों से यह परिचित संदेश बना सकते हैं:
Msg 2601, Level 14, State 1, Line 14
Cannot insert duplicate key row in object 'dbo.Table1' with unique index 'UIX_Table1_Key1'. The duplicate key value is (value1).
लेकिन पहले चीज़ें पहले।

[sendpulse-form id="12989″]
चुनें कोड नमूने में SQL INSERT के लिए परीक्षण डेटा तैयार करें
मैं इस बार पास्ता के बारे में सोच रहा हूं। इसलिए, मैं पास्ता व्यंजनों के बारे में डेटा का उपयोग करूंगा। मुझे विकिपीडिया में पास्ता व्यंजनों की एक अच्छी सूची मिली, जिसका उपयोग हम वेब डेटा स्रोत का उपयोग करके Power BI में कर सकते हैं और निकाल सकते हैं। मैंने विकिपीडिया URL दर्ज किया। फिर मैंने पृष्ठ से 2-टेबल डेटा निर्दिष्ट किया। इसे थोड़ा साफ किया और एक्सेल में डेटा कॉपी किया।
अब हमारे पास डेटा है - आप इसे यहां से डाउनलोड कर सकते हैं। यह कच्चा है क्योंकि हम इसमें से 2 रिलेशनल टेबल बनाने जा रहे हैं। INSERT INTO SELECT का उपयोग करने से हमें यह कार्य करने में मदद मिलेगी,
SQL सर्वर में डेटा आयात करें
आप या तो SQL सर्वर प्रबंधन स्टूडियो का उपयोग कर सकते हैं या SQL सर्वर के लिए dbForge स्टूडियो का उपयोग एक्सेल फ़ाइल में 2 शीट आयात करने के लिए कर सकते हैं।
डेटा आयात करने से पहले एक रिक्त डेटाबेस बनाएँ। मैंने टेबलों को dbo.ItalianPastaDishes . नाम दिया है और dbo.NonItalianPastaDishes ।
2 और टेबल बनाएं
आइए SQL सर्वर ALTER TABLE कमांड के साथ दो आउटपुट टेबल को परिभाषित करें।
CREATE TABLE [dbo].[Origin](
[OriginID] [int] IDENTITY(1,1) NOT NULL,
[Origin] [varchar](50) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_Origin] PRIMARY KEY CLUSTERED
(
[OriginID] ASC
))
GO
ALTER TABLE [dbo].[Origin] ADD CONSTRAINT [DF_Origin_Modified] DEFAULT (getdate()) FOR [Modified]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_Origin] ON [dbo].[Origin]
(
[Origin] ASC
)
GO
CREATE TABLE [dbo].[PastaDishes](
[PastaDishID] [int] IDENTITY(1,1) NOT NULL,
[PastaDishName] [nvarchar](75) NOT NULL,
[OriginID] [int] NOT NULL,
[Description] [nvarchar](500) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_PastaDishes_1] PRIMARY KEY CLUSTERED
(
[PastaDishID] ASC
))
GO
ALTER TABLE [dbo].[PastaDishes] ADD CONSTRAINT [DF_PastaDishes_Modified_1] DEFAULT (getdate()) FOR [Modified]
GO
ALTER TABLE [dbo].[PastaDishes] WITH CHECK ADD CONSTRAINT [FK_PastaDishes_Origin] FOREIGN KEY([OriginID])
REFERENCES [dbo].[Origin] ([OriginID])
GO
ALTER TABLE [dbo].[PastaDishes] CHECK CONSTRAINT [FK_PastaDishes_Origin]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_PastaDishes_PastaDishName] ON [dbo].[PastaDishes]
(
[PastaDishName] ASC
)
GO
नोट:दो तालिकाओं पर अद्वितीय अनुक्रमणिकाएँ बनाई गई हैं। यह हमें बाद में डुप्लीकेट रिकॉर्ड डालने से रोकेगा। प्रतिबंध इस यात्रा को थोड़ा कठिन लेकिन रोमांचक बना देंगे।
अब जब हम तैयार हैं, तो आइए इसमें गोता लगाते हैं।
चयन में SQL INSERT का उपयोग करके डुप्लिकेट को संभालने के 5 आसान तरीके
डुप्लिकेट को संभालने का सबसे आसान तरीका अद्वितीय बाधाओं को दूर करना है, है ना?
गलत!
अद्वितीय बाधाओं के साथ, गलती करना और डेटा को दो या अधिक बार सम्मिलित करना आसान है। हम ऐसा नहीं चाहते। और क्या होगा यदि हमारे पास पास्ता डिश की उत्पत्ति को चुनने के लिए एक ड्रॉपडाउन सूची के साथ एक यूजर इंटरफेस है? क्या डुप्लीकेट आपके उपयोगकर्ताओं को खुश करेंगे?
इसलिए, अद्वितीय बाधाओं को हटाना एसक्यूएल में डुप्लिकेट रिकॉर्ड को संभालने या हटाने के पांच तरीकों में से एक नहीं है। हमारे पास बेहतर विकल्प हैं।
<एच3>1. INSERT INTO SELECT DISTINCT का उपयोग करनाSQL में SQL रिकॉर्ड की पहचान कैसे करें, इसका पहला विकल्प अपने SELECT में DISTINCT का उपयोग करना है। मामले का पता लगाने के लिए, हम मूल . को पॉप्युलेट करेंगे टेबल। लेकिन पहले, गलत तरीके का उपयोग करें:
-- This is wrong and will trigger duplicate key errors
INSERT INTO Origin
(Origin)
SELECT origin FROM NonItalianPastaDishes
GO
INSERT INTO Origin
(Origin)
SELECT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
GO
यह निम्नलिखित डुप्लिकेट त्रुटियों को ट्रिगर करेगा:
Msg 2601, Level 14, State 1, Line 2
Cannot insert a duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (United States).
The statement has been terminated.
Msg 2601, Level 14, State 1, Line 6
Cannot insert duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (Lombardy, Italy).
जब आप SQL में डुप्लिकेट पंक्तियों का चयन करने का प्रयास करते हैं तो एक समस्या होती है। पहले मौजूद डुप्लिकेट के लिए SQL जाँच शुरू करने के लिए, मैंने INSERT INTO SELECT स्टेटमेंट का SELECT भाग चलाया:
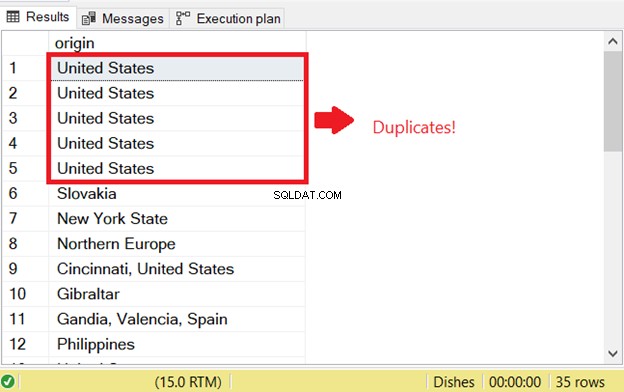
पहली SQL डुप्लिकेट त्रुटि का यही कारण है। इसे रोकने के लिए, परिणाम सेट को विशिष्ट बनाने के लिए DISTINCT कीवर्ड जोड़ें। यहाँ सही कोड है:
-- The correct way to INSERT
INSERT INTO Origin
(Origin)
SELECT DISTINCT origin FROM NonItalianPastaDishes
INSERT INTO Origin
(Origin)
SELECT DISTINCT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
यह रिकॉर्ड को सफलतापूर्वक सम्मिलित करता है। और हमने मूल . का काम पूरा कर लिया है टेबल।
DISTINCT का उपयोग करने से SELECT स्टेटमेंट से अद्वितीय रिकॉर्ड बन जाएगा। हालांकि, यह गारंटी नहीं देता है कि लक्ष्य तालिका में डुप्लिकेट मौजूद नहीं हैं। यह अच्छा है जब आप सुनिश्चित हों कि लक्ष्य तालिका में वे मान नहीं हैं जिन्हें आप सम्मिलित करना चाहते हैं।
इसलिए, इन कथनों को एक से अधिक बार न चलाएं।
<एच3>2. व्हेयर नॉट इन का उपयोग करनाइसके बाद, हम पास्ता व्यंजन . को भरते हैं टेबल। उसके लिए, हमें सबसे पहले ItalianPastaDishes . से रिकॉर्ड डालने होंगे टेबल। यह रहा कोड:
INSERT INTO [dbo].[PastaDishes]
(PastaDishName,OriginID, Description)
SELECT
a.DishName
,b.OriginID
,a.Description
FROM ItalianPastaDishes a
INNER JOIN Origin b ON a.ItalianRegion + ', ' + 'Italy' = b.Origin
WHERE a.DishName NOT IN (SELECT PastaDishName FROM PastaDishes)
चूंकि इतालवी पास्ता व्यंजन कच्चा डेटा है, हमें उत्पत्ति . में शामिल होने की आवश्यकता है OriginID . के बजाय टेक्स्ट . अब, एक ही कोड को दो बार चलाने का प्रयास करें। दूसरी बार चलने पर इसमें रिकॉर्ड सम्मिलित नहीं होंगे। यह NOT IN ऑपरेटर के साथ WHERE क्लॉज के कारण होता है। यह उन रिकॉर्ड्स को फ़िल्टर करता है जो लक्ष्य तालिका में पहले से मौजूद हैं।
इसके बाद, हमें पास्ता व्यंजन . को भरना होगा गैर-इतालवी पास्ता व्यंजन . से तालिका टेबल। चूंकि हम इस पोस्ट के दूसरे बिंदु पर हैं, इसलिए हम सब कुछ सम्मिलित नहीं करेंगे।
हमने संयुक्त राज्य अमेरिका और फिलीपींस से पास्ता व्यंजन चुने। ये रहा:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using NOT IN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
AND b.OriginID IN (15,22)
इस कथन से 9 रिकॉर्ड डाले गए हैं - नीचे चित्र 2 देखें:
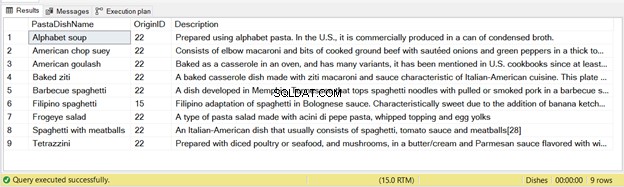
दोबारा, यदि आप ऊपर दिए गए कोड को दो बार चलाते हैं, तो दूसरे रन में रिकॉर्ड सम्मिलित नहीं होंगे।
<एच3>3. जहां मौजूद नहीं है वहां का उपयोग करनाSQL में डुप्लीकेट खोजने का दूसरा तरीका WHERE क्लॉज में NOT EXISTS का उपयोग करना है। आइए इसे पिछले अनुभाग की समान शर्तों के साथ आज़माएँ:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using WHERE NOT EXISTS
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
AND b.OriginID IN (15,22)
उपरोक्त कोड वही 9 रिकॉर्ड सम्मिलित करेगा जो आपने चित्र 2 में देखे थे। यह एक ही रिकॉर्ड को एक से अधिक बार सम्मिलित करने से बच जाएगा।
<एच3>4. IF NOT EXISTS का उपयोग करनाकभी-कभी आपको डेटाबेस में एक तालिका तैनात करने की आवश्यकता हो सकती है और यह जांचना आवश्यक है कि डुप्लिकेट से बचने के लिए समान नाम वाली तालिका पहले से मौजूद है या नहीं। इस मामले में, SQL DROP TABLE IF EXISTS कमांड बहुत मददगार हो सकती है। यह सुनिश्चित करने का एक और तरीका है कि आप डुप्लीकेट नहीं डालेंगे IF NOT EXISTS का उपयोग कर रहे हैं। फिर से, हम पिछले अनुभाग की समान शर्तों का उपयोग करेंगे:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using IF NOT EXISTS
IF NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
BEGIN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
END
उपरोक्त कोड पहले 9 रिकॉर्ड के अस्तित्व की जांच करेगा। अगर यह सच हो जाता है, तो INSERT आगे बढ़ेगा।
5. COUNT(*) =0
. का उपयोग करनाअंत में, WHERE क्लॉज में COUNT(*) का उपयोग यह भी सुनिश्चित कर सकता है कि आप डुप्लीकेट नहीं डालेंगे। यहां एक उदाहरण दिया गया है:
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
AND (SELECT COUNT(*) FROM PastaDishes pd
WHERE pd.OriginID IN (15,22)) = 0
डुप्लिकेट से बचने के लिए, उपरोक्त सबक्वेरी द्वारा लौटाए गए COUNT या रिकॉर्ड शून्य होने चाहिए।
नोट :आप SQL सर्वर के लिए dbForge Studio की क्वेरी बिल्डर सुविधा का उपयोग करके आरेख में किसी भी क्वेरी को विज़ुअल रूप से डिज़ाइन कर सकते हैं।
डुप्लिकेट को संभालने के विभिन्न तरीकों की तुलना SQL INSERT INTO SELECT के साथ करना
4 अनुभागों ने एक ही आउटपुट का उपयोग किया लेकिन एक सेलेक्ट स्टेटमेंट के साथ बल्क रिकॉर्ड डालने के लिए अलग-अलग दृष्टिकोण। आपको आश्चर्य हो सकता है कि क्या अंतर सिर्फ सतह पर है। हम सांख्यिकी IO से उनके तार्किक पठन की जांच कर सकते हैं कि वे कितने भिन्न हैं।
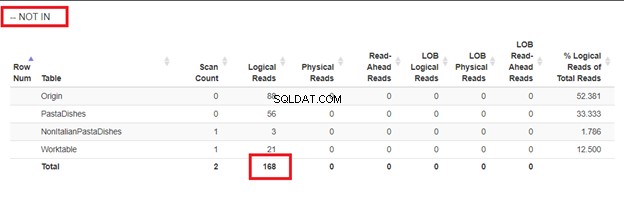
व्हेयर नॉट इन का उपयोग करना:
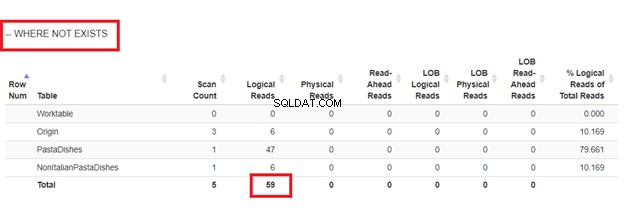
मौजूद नहीं का उपयोग करना:
IF NOT EXISTS का उपयोग करना:
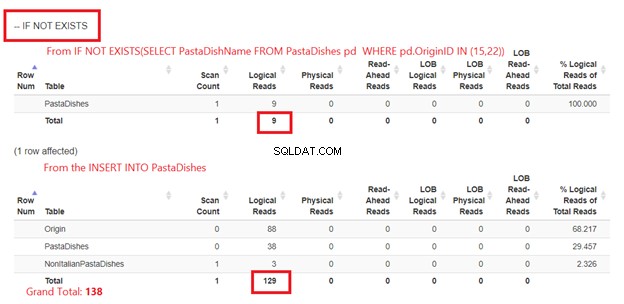
चित्रा 5 थोड़ा अलग है। पास्ता व्यंजन . के लिए 2 तार्किक पठन दिखाई देते हैं टेबल। पहला IF NOT EXISTS से है (चुनें PastaDishName पास्ता व्यंजन . से जहां OriginID आईएन (15,22))। दूसरा INSERT कथन से है।
अंत में, COUNT(*) =0
. का उपयोग करके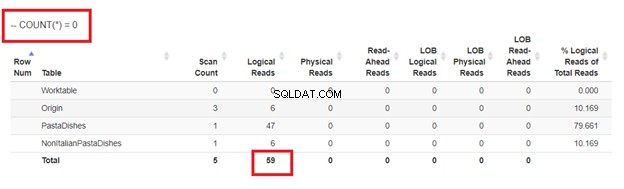
हमारे पास 4 दृष्टिकोणों के तार्किक पठन से, सबसे अच्छा विकल्प है जहां मौजूद नहीं है या COUNT(*) =0. जब हम उनकी निष्पादन योजनाओं का निरीक्षण करते हैं, तो हम देखते हैं कि उनके पास समान QueryHashPlan है . इस प्रकार, उनकी समान योजनाएँ हैं। इस बीच, सबसे कम कुशल एक NOT IN का उपयोग कर रहा है।
क्या इसका मतलब यह है कि WHERE NOT EXISTS हमेशा NOT IN से बेहतर होता है? बिलकुल नहीं।
हमेशा तार्किक पठन और अपने प्रश्नों की निष्पादन योजना का निरीक्षण करें!
लेकिन इससे पहले कि हम निष्कर्ष निकालें, हमें कार्य को पूरा करने की आवश्यकता है। फिर हम बाकी रिकॉर्ड डालेंगे और परिणामों का निरीक्षण करेंगे।
-- Insert the rest of the records
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
GO
-- View the output
SELECT
a.PastaDishID
,a.PastaDishName
,b.Origin
,a.Description
,a.Modified
FROM PastaDishes a
INNER JOIN Origin b ON a.OriginID = b.OriginID
ORDER BY b.Origin, a.PastaDishName
एशिया से यूरोप तक 179 पास्ता व्यंजनों की सूची से ब्राउज़ करने से मुझे भूख लगती है। नीचे से इटली, रूस और अन्य से सूची का एक हिस्सा देखें:

निष्कर्ष
SQL INSERT INTO SELECT में डुप्लिकेट से बचना इतना कठिन नहीं है। आपको उस स्तर तक ले जाने के लिए आपके पास ऑपरेटर और कार्य हैं। जो बेहतर है उसकी तुलना करने के लिए निष्पादन योजना और तार्किक पठन की जांच करना भी एक अच्छी आदत है।
अगर आपको लगता है कि इस पोस्ट से किसी और को फायदा होगा, तो कृपया इसे अपने पसंदीदा सोशल मीडिया प्लेटफॉर्म पर शेयर करें। और अगर आपके पास जोड़ने के लिए कुछ है जो हम भूल गए हैं, तो हमें नीचे टिप्पणी अनुभाग में बताएं।