SQL सर्वर में समूहबद्ध संयोजन एक आम समस्या है, इसका समर्थन करने के लिए कोई प्रत्यक्ष और जानबूझकर सुविधाएँ नहीं हैं (जैसे Oracle में XMLAGG, STRING_AGG या ARRAY_TO_STRING (ARRAY_AGG ()) PostgreSQL में, और MySQL में GROUP_CONCAT)। यह अनुरोध किया गया है, लेकिन अभी तक कोई सफलता नहीं मिली है, जैसा कि इन कनेक्ट आइटमों में दिखाया गया है:
- कनेक्ट #247118 :SQL को MySQL group_Concat फ़ंक्शन के संस्करण की आवश्यकता है (स्थगित)
- कनेक्ट #728969 :ऑर्डर किए गए सेट फंक्शन - ग्रुप क्लॉज के भीतर (बंद के रूप में ठीक नहीं होगा)
** अद्यतन जनवरी 2017 ** :STRING_AGG() SQL सर्वर 2017 में होगा; इसके बारे में यहाँ, यहाँ और यहाँ पढ़ें।
ग्रुपेड कॉन्सटेनेशन क्या है?
गैर-आरंभिक के लिए, समूहबद्ध संयोजन तब होता है जब आप डेटा की कई पंक्तियाँ लेना चाहते हैं और उन्हें एक ही स्ट्रिंग में संपीड़ित करना चाहते हैं (आमतौर पर अल्पविराम, टैब या रिक्त स्थान जैसे सीमांकक के साथ)। कुछ लोग इसे "क्षैतिज जुड़ाव" कह सकते हैं। एक त्वरित दृश्य उदाहरण यह दर्शाता है कि हम परिवार के प्रत्येक सदस्य से संबंधित पालतू जानवरों की सूची को सामान्यीकृत स्रोत से "चपटा" आउटपुट में कैसे संपीड़ित करेंगे:
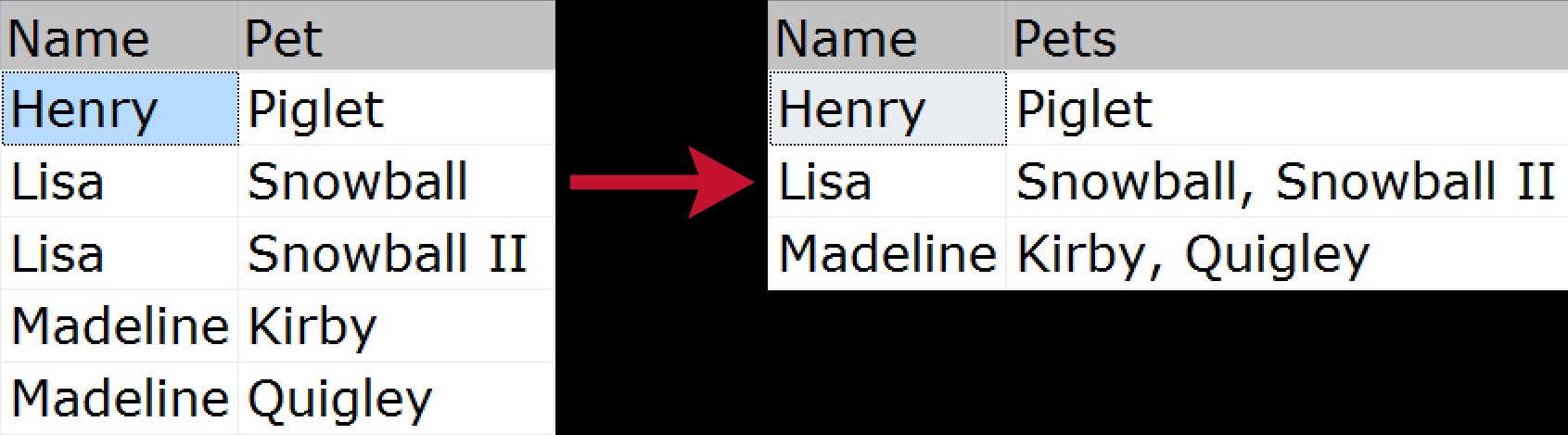
वर्षों से इस समस्या को हल करने के कई तरीके हैं; निम्नलिखित नमूना डेटा के आधार पर यहां कुछ ही हैं:
CREATE TABLE dbo.FamilyMemberPets ( Name SYSNAME, Pet SYSNAME, PRIMARY KEY(Name,Pet) ); INSERT dbo.FamilyMemberPets(Name,Pet) VALUES (N'Madeline',N'Kirby'), (N'Madeline',N'Quigley'), (N'Henry', N'Piglet'), (N'Lisa', N'Snowball'), (N'Lisa', N'Snowball II');
मैं हर समूहबद्ध संयोजन दृष्टिकोण की एक विस्तृत सूची प्रदर्शित नहीं करने जा रहा हूं, क्योंकि मैं अपने अनुशंसित दृष्टिकोण के कुछ पहलुओं पर ध्यान केंद्रित करना चाहता हूं, लेकिन मैं कुछ अधिक सामान्य लोगों को इंगित करना चाहता हूं:
स्केलर UDF
CREATE FUNCTION dbo.ConcatFunction
(
@Name SYSNAME
)
RETURNS NVARCHAR(MAX)
WITH SCHEMABINDING
AS
BEGIN
DECLARE @s NVARCHAR(MAX);
SELECT @s = COALESCE(@s + N', ', N'') + Pet
FROM dbo.FamilyMemberPets
WHERE Name = @Name
ORDER BY Pet;
RETURN (@s);
END
GO
SELECT Name, Pets = dbo.ConcatFunction(Name)
FROM dbo.FamilyMemberPets
GROUP BY Name
ORDER BY Name; नोट:हमारे द्वारा ऐसा न करने का एक कारण है:
SELECT DISTINCT Name, Pets = dbo.ConcatFunction(Name) FROM dbo.FamilyMemberPets ORDER BY Name;
DISTINCT . के साथ , फ़ंक्शन प्रत्येक पंक्ति के लिए चलाया जाता है, फिर डुप्लिकेट हटा दिए जाते हैं; GROUP BY . के साथ , डुप्लीकेट पहले हटा दिए जाते हैं।
सामान्य भाषा रनटाइम (CLR)
यह GROUP_CONCAT_S . का उपयोग करता है फ़ंक्शन https://groupconcat.codeplex.com/ पर पाया गया:
SELECT Name, Pets = dbo.GROUP_CONCAT_S(Pet, 1) FROM dbo.FamilyMemberPets GROUP BY Name ORDER BY Name;
पुनरावर्ती CTE
इस रिकर्सन पर कई भिन्नताएं हैं; यह एंकर के रूप में अलग-अलग नामों का एक सेट निकालता है:
;WITH x as
(
SELECT Name, Pet = CONVERT(NVARCHAR(MAX), Pet),
r1 = ROW_NUMBER() OVER (PARTITION BY Name ORDER BY Pet)
FROM dbo.FamilyMemberPets
),
a AS
(
SELECT Name, Pet, r1 FROM x WHERE r1 = 1
),
r AS
(
SELECT Name, Pet, r1 FROM a WHERE r1 = 1
UNION ALL
SELECT x.Name, r.Pet + N', ' + x.Pet, x.r1
FROM x INNER JOIN r
ON r.Name = x.Name
AND x.r1 = r.r1 + 1
)
SELECT Name, Pets = MAX(Pet)
FROM r
GROUP BY Name
ORDER BY Name
OPTION (MAXRECURSION 0); कर्सर
यहां कहने के लिए कुछ अधिक नहीं; कर्सर आमतौर पर इष्टतम दृष्टिकोण नहीं होते हैं, लेकिन यदि आप SQL Server 2000 पर अटके हुए हैं तो यह आपकी एकमात्र पसंद हो सकती है:
DECLARE @t TABLE(Name SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name));
INSERT @t(Name, Pets)
SELECT Name, N''
FROM dbo.FamilyMemberPets GROUP BY Name;
DECLARE @name SYSNAME, @pet SYSNAME, @pets NVARCHAR(MAX);
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR SELECT Name, Pet
FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
OPEN c;
FETCH c INTO @name, @pet;
WHILE @@FETCH_STATUS = 0
BEGIN
UPDATE @t SET Pets += N', ' + @pet
WHERE Name = @name;
FETCH c INTO @name, @pet;
END
CLOSE c; DEALLOCATE c;
SELECT Name, Pets = STUFF(Pets, 1, 1, N'')
FROM @t
ORDER BY Name;
GO अजीब अपडेट
कुछ लोग इस दृष्टिकोण को *प्यार* करते हैं; मैं आकर्षण को बिल्कुल नहीं समझता।
DECLARE @Name SYSNAME, @Pets NVARCHAR(MAX);
DECLARE @t TABLE(Name SYSNAME, Pet SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name, Pet));
INSERT @t(Name, Pet)
SELECT Name, Pet FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
UPDATE @t SET @Pets = Pets = COALESCE(
CASE COALESCE(@Name, N'')
WHEN Name THEN @Pets + N', ' + Pet
ELSE Pet END, N''),
@Name = Name;
SELECT Name, Pets = MAX(Pets)
FROM @t
GROUP BY Name
ORDER BY Name; एक्सएमएल पथ के लिए
काफी आसानी से मेरी पसंदीदा विधि, कम से कम आंशिक रूप से क्योंकि यह कर्सर या सीएलआर का उपयोग किए बिना *गारंटी* ऑर्डर करने का एकमात्र तरीका है। उस ने कहा, यह एक बहुत ही कच्चा संस्करण है जो कुछ अन्य अंतर्निहित समस्याओं का समाधान करने में विफल रहता है, जिन पर मैं आगे चर्चा करूंगा:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N'')), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
मैंने देखा है कि बहुत से लोग गलती से यह मान लेते हैं कि नया CONCAT() SQL सर्वर 2012 में पेश किया गया फ़ंक्शन इन सुविधा अनुरोधों का उत्तर था। वह फ़ंक्शन केवल एक पंक्ति में स्तंभों या चरों के विरुद्ध कार्य करने के लिए है; इसका उपयोग पंक्तियों में मानों को जोड़ने के लिए नहीं किया जा सकता है।
XML पाथ के बारे में अधिक जानकारी
FOR XML PATH('') अपने आप में पर्याप्त नहीं है - इसमें XML एंटाइटेलाइजेशन के साथ ज्ञात समस्याएं हैं। उदाहरण के लिए, यदि आप HTML ब्रैकेट या एम्परसेंड को शामिल करने के लिए पालतू जानवरों के नामों में से किसी एक को अपडेट करते हैं:
UPDATE dbo.FamilyMemberPets SET Pet = N'Qui>gle&y' WHERE Pet = N'Quigley';
ये कहीं न कहीं XML-सुरक्षित निकायों में अनुवादित हो जाते हैं:
Qui>gle&y
इसलिए मैं हमेशा PATH, TYPE).value() . का उपयोग करता हूं , इस प्रकार:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
मैं भी हमेशा NVARCHAR . का उपयोग करता हूं , क्योंकि आप कभी नहीं जानते कि कुछ अंतर्निहित कॉलम में यूनिकोड कब होगा (या बाद में ऐसा करने के लिए बदल दिया जाएगा)।
आप .value() . के अंदर निम्नलिखित किस्में देख सकते हैं , या अन्य भी:
... TYPE).value(N'.', ... ... TYPE).value(N'(./text())[1]', ...
ये विनिमेय हैं, सभी अंततः एक ही स्ट्रिंग का प्रतिनिधित्व करते हैं; उनके बीच प्रदर्शन अंतर (अधिक नीचे) नगण्य थे और संभवत:पूरी तरह से गैर-निर्धारिती थे।
एक और समस्या जो आपके सामने आ सकती है वह है कुछ ASCII वर्ण जिनका XML में प्रतिनिधित्व करना संभव नहीं है; उदाहरण के लिए, यदि स्ट्रिंग में वर्ण है 0x001A (CHAR(26) ), आपको यह त्रुटि संदेश मिलेगा:
एक्सएमएल के लिए नोड 'नोनाम' के लिए डेटा को क्रमबद्ध नहीं कर सका क्योंकि इसमें एक वर्ण (0x001A) है जिसकी XML में अनुमति नहीं है। FOR XML का उपयोग करके इस डेटा को पुनः प्राप्त करने के लिए, इसे बाइनरी, varbinary या छवि डेटा प्रकार में परिवर्तित करें और BINARY BASE64 निर्देश का उपयोग करें।
यह मेरे लिए बहुत जटिल लगता है, लेकिन उम्मीद है कि आपको इसके बारे में चिंता करने की ज़रूरत नहीं है क्योंकि आप इस तरह से डेटा संग्रहीत नहीं कर रहे हैं या कम से कम आप इसे समूहबद्ध संयोजन में उपयोग करने का प्रयास नहीं कर रहे हैं। यदि आप हैं, तो आपको अन्य तरीकों में से किसी एक पर वापस आना पड़ सकता है।
प्रदर्शन
उपरोक्त नमूना डेटा से यह साबित करना आसान हो जाता है कि ये सभी विधियां वही करती हैं जिनकी हम अपेक्षा करते हैं, लेकिन उनकी सार्थक रूप से तुलना करना कठिन है। इसलिए मैंने टेबल को बहुत बड़े सेट से भर दिया:
TRUNCATE TABLE dbo.FamilyMemberPets; INSERT dbo.FamilyMemberPets(Name,Pet) SELECT o.name, c.name FROM sys.all_objects AS o INNER JOIN sys.all_columns AS c ON o.[object_id] = c.[object_id] ORDER BY o.name, c.name;
मेरे लिए, यह 575 ऑब्जेक्ट था, जिसमें कुल 7,080 पंक्तियाँ थीं; सबसे चौड़ी वस्तु में 142 स्तंभ थे। अब फिर से, बेशक, मैंने SQL सर्वर के इतिहास में परिकल्पित हर एक दृष्टिकोण की तुलना करने के लिए निर्धारित नहीं किया था; मैंने ऊपर पोस्ट की गई कुछ हाइलाइट्स। ये रहे परिणाम:
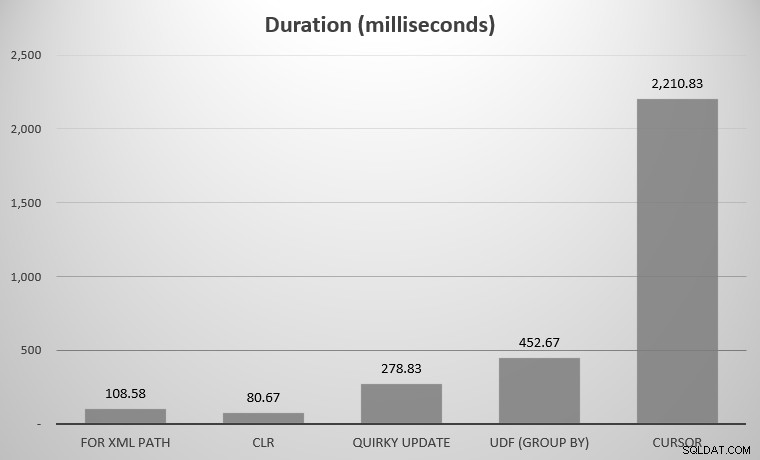
आप कुछ दावेदारों को लापता होते हुए देख सकते हैं; UDF DISTINCT . का उपयोग कर रहा है और पुनरावर्ती सीटीई चार्ट से इतने दूर थे कि वे पैमाने को तिरछा कर देंगे। यहाँ सभी सात दृष्टिकोणों के परिणाम सारणीबद्ध रूप में दिए गए हैं:
| दृष्टिकोण | अवधि (मिलीसेकंड) |
|---|---|
| XML पथ के लिए | 108.58 |
| सीएलआर | 80.67 |
| विचित्र अपडेट | 278.83 |
| UDF (ग्रुप बाय) | 452.67 |
| UDF (DISTINCT) | 5,893.67 |
| कर्सर | 2,210.83 |
| पुनरावर्ती CTE | 70,240.58 |
औसत अवधि, मिलीसेकंड में, सभी दृष्टिकोणों के लिए
यह भी ध्यान दें कि FOR XML PATH . पर भिन्नताएं स्वतंत्र रूप से परीक्षण किया गया था लेकिन बहुत मामूली अंतर दिखाया गया था इसलिए मैंने उन्हें औसत के लिए जोड़ दिया। यदि आप वास्तव में जानना चाहते हैं, .[1] मेरे परीक्षणों में अंकन सबसे तेजी से काम करता है; वाईएमएमवी.
निष्कर्ष
यदि आप ऐसी दुकान में नहीं हैं जहां सीएलआर किसी भी तरह से एक बाधा है, और विशेष रूप से यदि आप केवल साधारण नामों या अन्य तारों से निपट नहीं रहे हैं, तो आपको निश्चित रूप से कोडप्लेक्स प्रोजेक्ट पर विचार करना चाहिए। पहिया का पुन:आविष्कार करने का प्रयास न करें, CROSS APPLY करने के लिए अनजाने तरकीबें और हैक न करें या अन्य निर्माण उपरोक्त गैर-सीएलआर दृष्टिकोणों की तुलना में थोड़ा तेज काम करते हैं। बस जो काम करता है उसे लें और इसे प्लग इन करें। और ठीक है, चूंकि आपको स्रोत कोड भी मिलता है, आप इसमें सुधार कर सकते हैं या यदि आप चाहें तो इसे बढ़ा सकते हैं।
यदि CLR एक समस्या है, तो FOR XML PATH संभवतः आपका सबसे अच्छा विकल्प है, लेकिन आपको अभी भी मुश्किल पात्रों से सावधान रहना होगा। यदि आप SQL Server 2000 पर अटके हुए हैं, तो आपका एकमात्र संभव विकल्प UDF (या समान कोड UDF में लिपटा नहीं) है।
अगली बार
कुछ चीजें जिन्हें मैं फॉलो-ऑन पोस्ट में तलाशना चाहता हूं:सूची से डुप्लिकेट को हटाना, सूची को मूल्य के अलावा किसी अन्य चीज़ से ऑर्डर करना, ऐसे मामले जहां इनमें से किसी भी दृष्टिकोण को यूडीएफ में डालना दर्दनाक हो सकता है, और व्यावहारिक उपयोग के मामले इस कार्यक्षमता के लिए।