किसी ने गलती से डेटाबेस का हिस्सा हटा दिया। कोई व्यक्ति DELETE क्वेरी में WHERE क्लॉज शामिल करना भूल गया, या उन्होंने गलत तालिका छोड़ दी। इस तरह की चीजें हो सकती हैं और होंगी, यह अपरिहार्य और मानवीय है। लेकिन प्रभाव विनाशकारी हो सकता है। ऐसी स्थितियों से खुद को बचाने के लिए आप क्या कर सकते हैं, और आप अपना डेटा कैसे पुनर्प्राप्त कर सकते हैं? इस ब्लॉग पोस्ट में, हम डेटा हानि के कुछ सबसे विशिष्ट मामलों को कवर करेंगे, और आप खुद को कैसे तैयार कर सकते हैं ताकि आप उनसे ठीक हो सकें।
तैयारी
सुचारू रूप से ठीक होने के लिए आपको कुछ चीजें करनी चाहिए। आइए उनके माध्यम से चलते हैं। कृपया ध्यान रखें कि यह "एक चुनें" स्थिति नहीं है - आदर्श रूप से आप उन सभी उपायों को लागू करेंगे जिनके बारे में हम नीचे चर्चा करने जा रहे हैं।
बैकअप
आपके पास एक बैकअप होना चाहिए, इससे दूर होने का कोई उपाय नहीं है। आपको अपनी बैकअप फ़ाइलों का परीक्षण करवाना चाहिए - जब तक आप अपने बैकअप का परीक्षण नहीं करते हैं, आप सुनिश्चित नहीं हो सकते कि क्या वे अच्छे हैं और यदि आप उन्हें कभी भी पुनर्स्थापित करने में सक्षम होंगे। डिजास्टर रिकवरी के लिए आपको अपने बैकअप की एक कॉपी अपने डेटासेंटर के बाहर कहीं रखनी चाहिए - बस अगर पूरा डेटासेंटर अनुपलब्ध हो जाता है। पुनर्प्राप्ति में तेजी लाने के लिए, बैकअप की एक प्रति डेटाबेस नोड्स पर भी रखना बहुत उपयोगी है। यदि आपका डेटासेट बड़ा है, तो इसे नेटवर्क पर बैकअप सर्वर से डेटाबेस नोड में कॉपी करने में महत्वपूर्ण समय लग सकता है। नवीनतम बैकअप को स्थानीय रूप से रखने से पुनर्प्राप्ति समय में उल्लेखनीय रूप से सुधार हो सकता है।
लॉजिकल बैकअप
आपका पहला बैकअप, सबसे अधिक संभावना है, एक भौतिक बैकअप होगा। MySQL या MariaDB के लिए, यह या तो xtrabackup जैसा कुछ होगा या किसी प्रकार का फाइल सिस्टम स्नैपशॉट। ऐसे बैकअप संपूर्ण डेटासेट को पुनर्स्थापित करने या नए नोड्स के प्रावधान के लिए बहुत अच्छे हैं। हालांकि, डेटा के एक सबसेट को हटाने के मामले में, वे महत्वपूर्ण ओवरहेड से ग्रस्त हैं। सबसे पहले, आप सभी डेटा को पुनर्स्थापित करने में सक्षम नहीं हैं, अन्यथा आप उन सभी परिवर्तनों को अधिलेखित कर देंगे जो बैकअप बनने के बाद हुए थे। आप जो खोज रहे हैं वह डेटा के केवल एक सबसेट को पुनर्स्थापित करने की क्षमता है, केवल उन पंक्तियों को जिन्हें गलती से हटा दिया गया था। भौतिक बैकअप के साथ ऐसा करने के लिए, आपको इसे एक अलग होस्ट पर पुनर्स्थापित करना होगा, हटाई गई पंक्तियों का पता लगाना होगा, उन्हें डंप करना होगा और फिर उन्हें उत्पादन क्लस्टर पर पुनर्स्थापित करना होगा। केवल कुछ पंक्तियों को पुनर्प्राप्त करने के लिए सैकड़ों गीगाबाइट डेटा की प्रतिलिपि बनाना और पुनर्स्थापित करना कुछ ऐसा है जिसे हम निश्चित रूप से एक महत्वपूर्ण ओवरहेड कहेंगे। इससे बचने के लिए आप तार्किक बैकअप का उपयोग कर सकते हैं - भौतिक डेटा संग्रहीत करने के बजाय, ऐसे बैकअप डेटा को टेक्स्ट प्रारूप में संग्रहीत करते हैं। इससे हटाए गए सटीक डेटा का पता लगाना आसान हो जाता है, जिसे बाद में सीधे उत्पादन क्लस्टर पर पुनर्स्थापित किया जा सकता है। इसे और भी आसान बनाने के लिए, आप इस तरह के तार्किक बैकअप को भागों में विभाजित कर सकते हैं और प्रत्येक तालिका को एक अलग फ़ाइल में बैकअप कर सकते हैं। यदि आपका डेटासेट बड़ा है, तो जितना संभव हो सके एक बड़ी टेक्स्ट फ़ाइल को विभाजित करना समझ में आता है। यह बैकअप को असंगत बना देगा, लेकिन अधिकांश मामलों के लिए, यह कोई समस्या नहीं है - यदि आपको संपूर्ण डेटासेट को एक सुसंगत स्थिति में पुनर्स्थापित करने की आवश्यकता होगी, तो आप भौतिक बैकअप का उपयोग करेंगे, जो इस संबंध में बहुत तेज़ है। यदि आपको डेटा के केवल एक सबसेट को पुनर्स्थापित करने की आवश्यकता है, तो एकरूपता की आवश्यकताएं कम कठोर हैं।
पॉइंट-इन-टाइम रिकवरी
बैकअप केवल एक शुरुआत है - आप अपने डेटा को उस बिंदु तक पुनर्स्थापित करने में सक्षम होंगे जिस पर बैकअप लिया गया था, लेकिन सबसे अधिक संभावना है कि उस समय के बाद डेटा हटा दिया गया था। नवीनतम बैकअप से लापता डेटा को पुनर्स्थापित करने से, आप बैकअप के बाद बदले गए किसी भी डेटा को खो सकते हैं। इससे बचने के लिए आपको पॉइंट-इन-टाइम रिकवरी लागू करनी चाहिए। MySQL के लिए इसका मूल रूप से मतलब है कि बैकअप के क्षण और डेटा हानि घटना के बीच हुए सभी परिवर्तनों को फिर से चलाने के लिए आपको बाइनरी लॉग का उपयोग करना होगा। नीचे दिया गया स्क्रीनशॉट दिखाता है कि इसमें ClusterControl कैसे मदद कर सकता है।
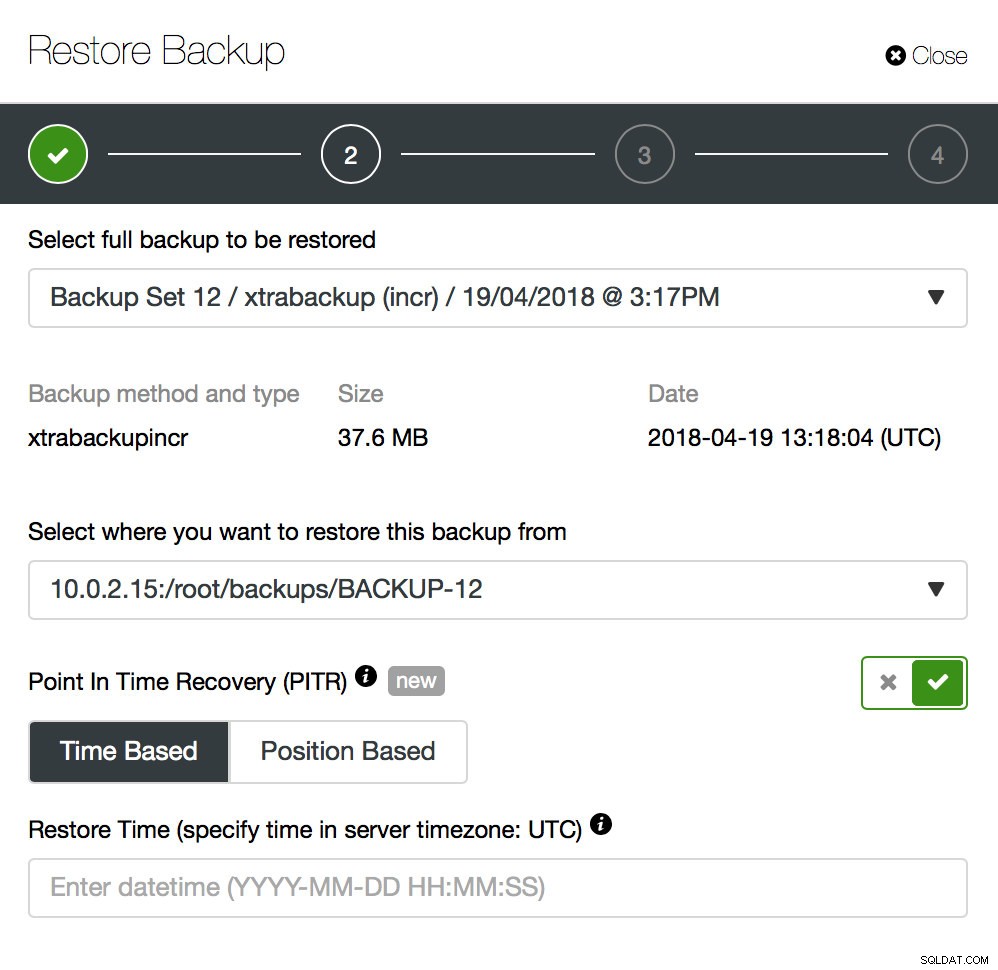
आपको यह करना होगा कि डेटा हानि से ठीक पहले इस बैकअप को पल भर तक पुनर्स्थापित करना है। उत्पादन क्लस्टर में परिवर्तन न करने के लिए आपको इसे एक अलग होस्ट पर पुनर्स्थापित करना होगा। एक बार जब आपके पास बैकअप बहाल हो जाता है, तो आप उस होस्ट में लॉग इन कर सकते हैं, लापता डेटा ढूंढ सकते हैं, उसे डंप कर सकते हैं और उत्पादन क्लस्टर पर पुनर्स्थापित कर सकते हैं।
विलंबित दास
ऊपर चर्चा की गई सभी विधियों में एक सामान्य दर्द बिंदु है - डेटा को पुनर्स्थापित करने में समय लगता है। जब आप सभी डेटा को पुनर्स्थापित करते हैं और फिर केवल दिलचस्प भाग को डंप करने का प्रयास करते हैं, तो इसमें अधिक समय लग सकता है। यदि आपके पास तार्किक बैकअप है तो इसमें कम समय लग सकता है और आप जिस डेटा को पुनर्स्थापित करना चाहते हैं, उसे जल्दी से ड्रिल-डाउन कर सकते हैं, लेकिन यह किसी भी तरह से एक त्वरित कार्य नहीं है। आपको अभी भी एक बड़ी टेक्स्ट फ़ाइल में कुछ पंक्तियां ढूंढनी होंगी। यह जितना बड़ा होता है, कार्य उतना ही जटिल होता जाता है - कभी-कभी फ़ाइल का विशाल आकार सभी क्रियाओं को धीमा कर देता है। उन समस्याओं से बचने का एक तरीका विलंबित दास होना है। दास आमतौर पर स्वामी के साथ अद्यतित रहने की कोशिश करते हैं लेकिन उन्हें कॉन्फ़िगर करना भी संभव है ताकि वे अपने स्वामी से दूरी बनाए रखें। नीचे दिए गए स्क्रीनशॉट में, आप देख सकते हैं कि इस तरह के दास को तैनात करने के लिए ClusterControl का उपयोग कैसे करें:
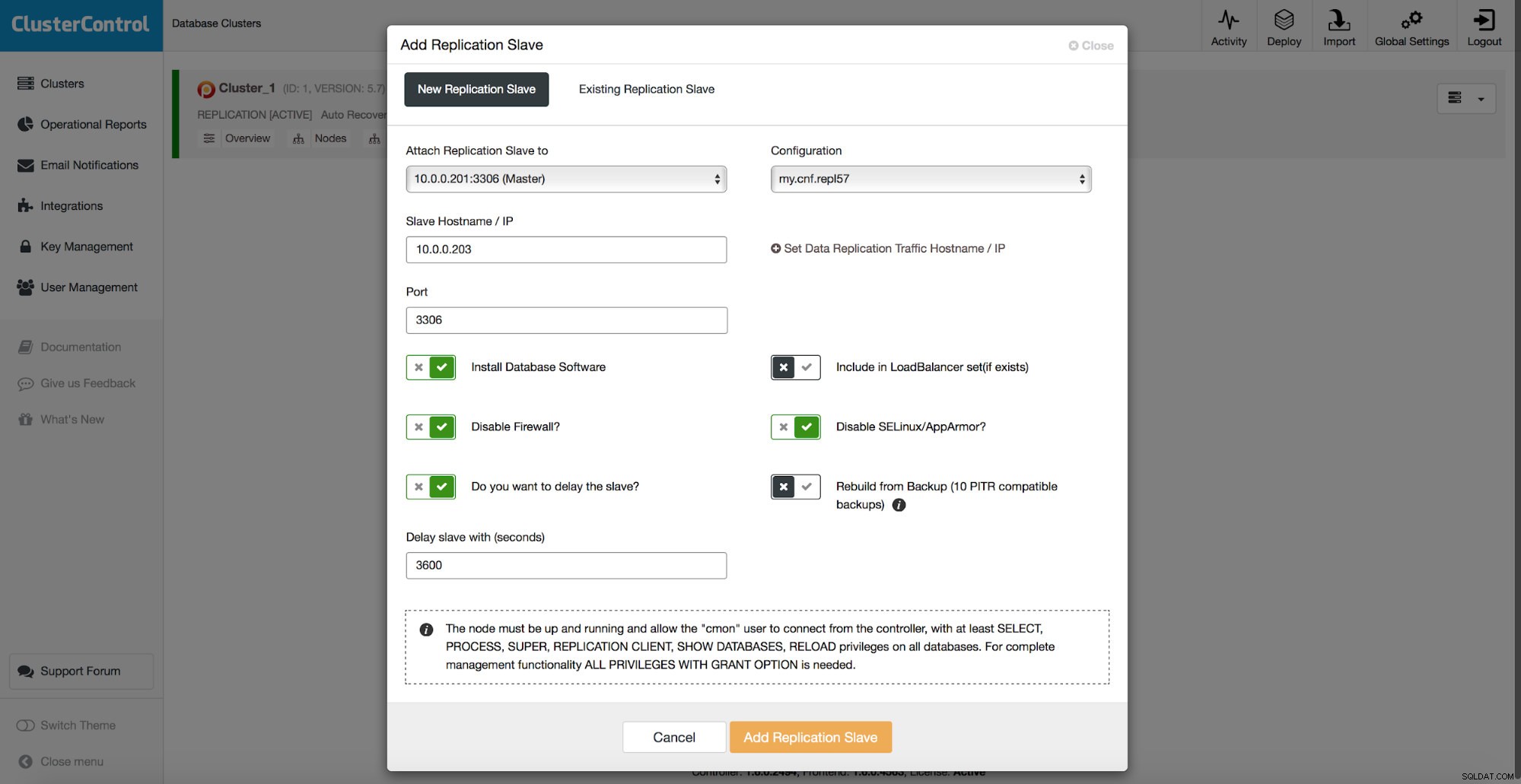
संक्षेप में, हमारे पास डेटाबेस सेटअप में एक प्रतिकृति दास जोड़ने और इसे विलंबित करने के लिए कॉन्फ़िगर करने का विकल्प है। ऊपर के स्क्रीनशॉट में, दास को 3600 सेकंड की देरी होगी, जो कि एक घंटा है। यह आपको हटाए गए डेटा को डेटा हटाने से एक घंटे तक पुनर्प्राप्त करने के लिए उस दास का उपयोग करने देता है। आपको बैकअप को पुनर्स्थापित करने की आवश्यकता नहीं होगी, यह mysqldump चलाने के लिए पर्याप्त होगा या अनुपलब्ध डेटा के लिए SELECT ... INTO OUTFILE और आपको अपने उत्पादन क्लस्टर पर पुनर्स्थापित करने के लिए डेटा प्राप्त होगा।
डेटा बहाल करना
इस खंड में, हम आकस्मिक डेटा विलोपन के कुछ उदाहरणों के माध्यम से जाएंगे और आप उनसे कैसे पुनर्प्राप्त कर सकते हैं। हम पूर्ण डेटा हानि से पुनर्प्राप्ति के माध्यम से चलेंगे, हम यह भी दिखाएंगे कि भौतिक और तार्किक बैकअप का उपयोग करते समय आंशिक डेटा हानि से कैसे पुनर्प्राप्त किया जाए। यदि आपके सेटअप में विलंबित स्लेव है, तो हम अंत में आपको दिखाएंगे कि गलती से हटाई गई पंक्तियों को कैसे पुनर्स्थापित किया जाए।
पूर्ण डेटा हानि
दुर्घटनावश "rm -rf" या "DROP SCHEMA myonlyschema;" निष्पादित किया गया है और आपके पास कोई डेटा नहीं है। यदि आप MySQL डेटा निर्देशिका के अलावा अन्य फ़ाइलों को भी हटाते हैं, तो आपको होस्ट को पुन:व्यवस्थित करने की आवश्यकता हो सकती है। चीजों को सरल रखने के लिए हम मान लेंगे कि केवल MySQL प्रभावित हुआ है। आइए दो मामलों पर विचार करें, विलंबित दास के साथ और एक के बिना।
कोई विलंबित दास नहीं
इस मामले में केवल एक चीज जो हम कर सकते हैं वह है अंतिम भौतिक बैकअप को पुनर्स्थापित करना। चूंकि हमारे सभी डेटा हटा दिए गए हैं, इसलिए हमें डेटा हानि के बाद हुई गतिविधि के बारे में चिंतित होने की आवश्यकता नहीं है क्योंकि डेटा के बिना, कोई गतिविधि नहीं है। हमें उस गतिविधि के बारे में चिंतित होना चाहिए जो बैकअप होने के बाद हुई। इसका मतलब है कि हमें पॉइंट-इन-टाइम रिस्टोर करना होगा। बेशक, बैकअप से डेटा को पुनर्स्थापित करने में अधिक समय लगेगा। यदि सभी डेटा को पुनर्स्थापित करने की तुलना में अपने डेटाबेस को जल्दी से ऊपर लाना अधिक महत्वपूर्ण है, तो आप बस एक बैकअप को पुनर्स्थापित कर सकते हैं और इसके साथ ठीक हो सकते हैं।
सबसे पहले, यदि आपके पास अभी भी सर्वर पर बाइनरी लॉग तक पहुंच है जिसे आप पुनर्स्थापित करना चाहते हैं, तो आप उन्हें पीआईटीआर के लिए उपयोग कर सकते हैं। सबसे पहले, हम आगे की जांच के लिए बाइनरी लॉग के प्रासंगिक भाग को टेक्स्ट फ़ाइल में बदलना चाहते हैं। हम जानते हैं कि डेटा हानि 13:00:00 के बाद हुई। सबसे पहले, आइए देखें कि हमें किस बिनलॉग फ़ाइल की जांच करनी चाहिए:
example@sqldat.com:~# ls -alh /var/lib/mysql/binlog.*
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:32 /var/lib/mysql/binlog.000001
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:33 /var/lib/mysql/binlog.000002
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:35 /var/lib/mysql/binlog.000003
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:38 /var/lib/mysql/binlog.000004
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:39 /var/lib/mysql/binlog.000005
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:41 /var/lib/mysql/binlog.000006
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:43 /var/lib/mysql/binlog.000007
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:45 /var/lib/mysql/binlog.000008
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:47 /var/lib/mysql/binlog.000009
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:49 /var/lib/mysql/binlog.000010
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:51 /var/lib/mysql/binlog.000011
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:53 /var/lib/mysql/binlog.000012
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:55 /var/lib/mysql/binlog.000013
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:57 /var/lib/mysql/binlog.000014
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:59 /var/lib/mysql/binlog.000015
-rw-r----- 1 mysql mysql 306M Apr 23 13:18 /var/lib/mysql/binlog.000016जैसा कि देखा जा सकता है, हम अंतिम बिनलॉग फ़ाइल में रुचि रखते हैं।
example@sqldat.com:~# mysqlbinlog --start-datetime='2018-04-23 13:00:00' --verbose /var/lib/mysql/binlog.000016 > sql.outएक बार हो जाने के बाद, आइए इस फ़ाइल की सामग्री पर एक नज़र डालें। हम विम में 'ड्रॉप स्कीमा' की खोज करेंगे। यहाँ फ़ाइल का एक प्रासंगिक हिस्सा है:
# at 320358785
#180423 13:18:58 server id 1 end_log_pos 320358850 CRC32 0x0893ac86 GTID last_committed=307804 sequence_number=307805 rbr_only=no
SET @@SESSION.GTID_NEXT= '52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415'/*!*/;
# at 320358850
#180423 13:18:58 server id 1 end_log_pos 320358946 CRC32 0x487ab38e Query thread_id=55 exec_time=1 error_code=0
SET TIMESTAMP=1524489538/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
drop schema sbtest
/*!*/;जैसा कि हम देख सकते हैं, हम 320358785 स्थिति तक पुनर्स्थापित करना चाहते हैं। हम इस डेटा को ClusterControl UI में पास कर सकते हैं:
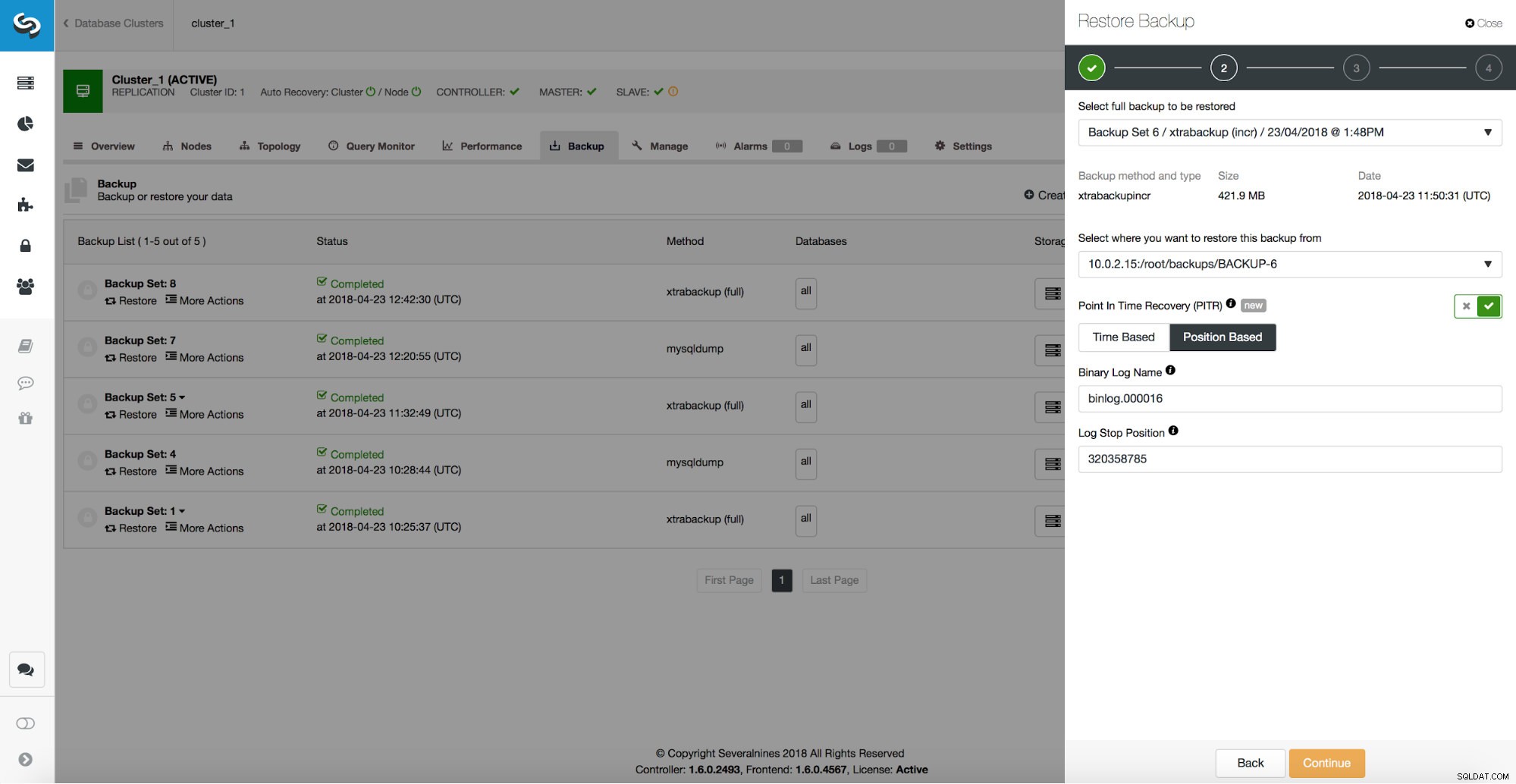
विलंबित दास
यदि हमारे पास एक विलंबित दास है और वह मेजबान सभी ट्रैफ़िक को संभालने के लिए पर्याप्त है, तो हम इसका उपयोग कर सकते हैं और इसे मास्टर करने के लिए बढ़ावा दे सकते हैं। सबसे पहले, हमें यह सुनिश्चित करना होगा कि यह डेटा हानि के बिंदु तक पुराने मास्टर के साथ पकड़ा जाए। ऐसा करने के लिए हम यहां कुछ सीएलआई का उपयोग करेंगे। सबसे पहले, हमें यह पता लगाने की जरूरत है कि डेटा हानि किस स्थिति में हुई। फिर हम दास को रोक देंगे और इसे डेटा हानि की घटना तक चलने देंगे। हमने दिखाया कि पिछले खंड में सही स्थिति कैसे प्राप्त करें - बाइनरी लॉग की जांच करके। हम या तो उस स्थिति का उपयोग कर सकते हैं (binlog.000016, स्थिति 320358785) या, यदि हम एक मल्टीथ्रेडेड स्लेव का उपयोग करते हैं, तो हमें डेटा हानि घटना (52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415) के GTID का उपयोग करना चाहिए और प्रश्नों को फिर से चलाना चाहिए वह GTID.
सबसे पहले, दास को रोकें और विलंब को अक्षम करें:
mysql> STOP SLAVE;
Query OK, 0 rows affected (0.01 sec)
mysql> CHANGE MASTER TO MASTER_DELAY = 0;
Query OK, 0 rows affected (0.02 sec)फिर हम इसे किसी दिए गए बाइनरी लॉग पोजीशन तक शुरू कर सकते हैं।
mysql> START SLAVE UNTIL MASTER_LOG_FILE='binlog.000016', MASTER_LOG_POS=320358785;
Query OK, 0 rows affected (0.01 sec)अगर हम GTID का उपयोग करना चाहते हैं, तो कमांड अलग दिखाई देगी:
mysql> START SLAVE UNTIL SQL_BEFORE_GTIDS = ‘52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415’;
Query OK, 0 rows affected (0.01 sec)एक बार प्रतिकृति बंद हो जाने के बाद (जिसका अर्थ है कि हमारे द्वारा मांगी गई सभी घटनाओं को निष्पादित किया गया है), हमें यह सत्यापित करना चाहिए कि मेजबान में लापता डेटा है। यदि ऐसा है, तो आप इसे मास्टर करने के लिए प्रचारित कर सकते हैं और फिर डेटा के स्रोत के रूप में नए मास्टर का उपयोग करके अन्य होस्ट का पुनर्निर्माण कर सकते हैं।
यह हमेशा सबसे अच्छा विकल्प नहीं होता है। सब कुछ इस बात पर निर्भर करता है कि आपका दास कितना विलंबित है - यदि इसमें कुछ घंटों की देरी होती है, तो इसे पकड़ने के लिए प्रतीक्षा करने का कोई मतलब नहीं हो सकता है, खासकर यदि लेखन यातायात आपके वातावरण में भारी है। ऐसे मामले में, भौतिक बैकअप का उपयोग करके मेजबानों के पुनर्निर्माण की सबसे अधिक संभावना है। दूसरी ओर, यदि आपके पास कम मात्रा में ट्रैफ़िक है, तो यह वास्तव में समस्या को जल्दी से ठीक करने, नए मास्टर को बढ़ावा देने और ट्रैफ़िक की सेवा के साथ आगे बढ़ने का एक अच्छा तरीका हो सकता है, जबकि बाकी नोड्स को पृष्ठभूमि में फिर से बनाया जा रहा है। ।
आंशिक डेटा हानि - भौतिक बैकअप
आंशिक डेटा हानि के मामले में, भौतिक बैकअप अक्षम हो सकते हैं, लेकिन चूंकि वे बैकअप का सबसे सामान्य प्रकार हैं, इसलिए यह जानना बहुत महत्वपूर्ण है कि आंशिक पुनर्स्थापना के लिए उनका उपयोग कैसे किया जाए। डेटा हानि घटना से पहले एक समय तक बैकअप को पुनर्स्थापित करने के लिए पहला कदम हमेशा होगा। इसे एक अलग होस्ट पर पुनर्स्थापित करना भी बहुत महत्वपूर्ण है। ClusterControl भौतिक बैकअप के लिए xtrabackup का उपयोग करता है इसलिए हम दिखाएंगे कि इसका उपयोग कैसे करना है। आइए मान लें कि हमने निम्नलिखित गलत क्वेरी चलाई:
DELETE FROM sbtest1 WHERE id < 23146;
हम केवल एक पंक्ति (WHERE क्लॉज में '=') को हटाना चाहते थे, इसके बजाय हमने उनमें से एक गुच्छा (
अब, आउटपुट फ़ाइल को देखें और देखें कि हम वहां क्या पा सकते हैं। हम पंक्ति-आधारित प्रतिकृति का उपयोग कर रहे हैं इसलिए हम सटीक SQL नहीं देखेंगे जिसे निष्पादित किया गया था। इसके बजाय (जब तक हम mysqlbinlog के लिए --verbose ध्वज का उपयोग करेंगे) हम नीचे की तरह की घटनाओं को देखेंगे:
जैसा कि देखा जा सकता है, MySQL बहुत सटीक WHERE स्थिति का उपयोग करके पंक्तियों को हटाने के लिए पहचानता है। मानव-पठनीय टिप्पणी में रहस्यमय संकेत, "@1", "@2", का अर्थ है "पहला स्तंभ", "दूसरा स्तंभ"। हम जानते हैं कि पहला कॉलम 'आईडी' है, जिसमें हम रुचि रखते हैं। हमें 'sbtest1' टेबल पर एक बड़ी DELETE घटना खोजने की जरूरत है। जिन टिप्पणियों का अनुसरण किया जाएगा उनमें 1 की आईडी, फिर '2' की आईडी, फिर '3' और इसी तरह - '23145' की आईडी तक का उल्लेख होना चाहिए। सभी को एक ही लेनदेन में निष्पादित किया जाना चाहिए (बाइनरी लॉग में एकल घटना)। 'कम' का उपयोग करके आउटपुट का विश्लेषण करने के बाद, हमने पाया:
वह इवेंट, जिसमें ये टिप्पणियां संलग्न हैं, यहां शुरू हुई:
इसलिए, हम पिछली प्रतिबद्धता तक बैकअप को 29600687 की स्थिति में पुनर्स्थापित करना चाहते हैं। चलो अब ऐसा करते हैं। हम उसके लिए बाहरी सर्वर का उपयोग करेंगे। हम उस स्थिति तक बैकअप को पुनर्स्थापित करेंगे और हम पुनर्स्थापना सर्वर को चालू रखेंगे ताकि बाद में हम लापता डेटा को निकाल सकें।
एक बार पुनर्स्थापना पूर्ण हो जाने पर, आइए सुनिश्चित करें कि हमारा डेटा पुनर्प्राप्त कर लिया गया है:
अछा लगता है। अब हम इस डेटा को एक फ़ाइल में निकाल सकते हैं जिसे हम वापस मास्टर पर लोड करेंगे।
कुछ सही नहीं है - ऐसा इसलिए है क्योंकि सर्वर केवल एक विशेष स्थान पर फ़ाइलें लिखने में सक्षम होने के लिए कॉन्फ़िगर किया गया है - यह सब सुरक्षा के बारे में है, हम उपयोगकर्ताओं को उनकी पसंद के अनुसार कहीं भी सामग्री को सहेजने नहीं देना चाहते हैं। आइए देखें कि हम अपनी फ़ाइल को कहाँ सहेज सकते हैं:
ठीक है, एक बार और कोशिश करते हैं:
अब यह बहुत बेहतर लग रहा है। आइए डेटा को मास्टर को कॉपी करें:
अब लापता पंक्तियों को मास्टर पर लोड करने और सफल होने पर परीक्षण करने का समय है:
बस इतना ही, हमने अपना गुम डेटा बहाल कर दिया।
पिछले खंड में, हमने भौतिक बैकअप और एक बाहरी सर्वर का उपयोग करके खोए हुए डेटा को पुनर्स्थापित किया था। क्या होगा अगर हमने तार्किक बैकअप बनाया था? चलो एक नज़र डालते हैं। सबसे पहले, आइए सत्यापित करें कि हमारे पास तार्किक बैकअप है:
हाँ, वहाँ है। अब, इसे डीकंप्रेस करने का समय आ गया है।
जब आप इसे देखेंगे, तो आप देखेंगे कि डेटा बहु-मूल्य वाले INSERT प्रारूप में संग्रहीत है। उदाहरण के लिए:
अब हमें केवल यह निर्धारित करने की आवश्यकता है कि हमारी तालिका कहाँ स्थित है और फिर जहाँ पंक्तियाँ, जो हमारे लिए रुचिकर हैं, संग्रहीत हैं। सबसे पहले, mysqldump पैटर्न (ड्रॉप टेबल, नया बनाएं, इंडेक्स अक्षम करें, डेटा डालें) जानने के लिए आइए जानें कि किस लाइन में 'sbtest1' टेबल के लिए टेबल स्टेटमेंट बनाएं:
अब, परीक्षण और त्रुटि की एक विधि का उपयोग करते हुए, हमें यह पता लगाने की आवश्यकता है कि हमारी पंक्तियों को कहाँ देखना है। हम आपको वह अंतिम आदेश दिखाएंगे जिसके साथ हम आए थे। पूरी तरकीब यह है कि sed का उपयोग करके अलग-अलग रेंज की लाइनों को प्रिंट करने की कोशिश करें और फिर जांचें कि क्या नवीनतम लाइन में पंक्तियों के करीब हैं, लेकिन बाद में हम जो खोज रहे हैं। नीचे दिए गए कमांड में हम 971 (क्रिएट टेबल) और 993 के बीच की लाइनों की तलाश करते हैं। हम sed को लाइन 994 पर पहुंचने के बाद छोड़ने के लिए भी कहते हैं क्योंकि बाकी फाइल हमारे लिए कोई दिलचस्पी नहीं है:
आउटपुट नीचे जैसा दिखता है:
इसका मतलब है कि हमारी पंक्ति सीमा (23145 की आईडी के साथ पंक्ति तक) करीब है। अगला, यह फ़ाइल की मैन्युअल सफाई के बारे में है। हम चाहते हैं कि यह पहली पंक्ति से शुरू हो जिसे हमें पुनर्स्थापित करने की आवश्यकता है:
और पुनर्स्थापित करने के लिए अंतिम पंक्ति के साथ समाप्त करें:
हमें कुछ अनावश्यक डेटा को ट्रिम करना था (यह मल्टीलाइन इंसर्ट है) लेकिन इस सब के बाद हमारे पास एक फाइल है जिसे हम मास्टर पर वापस लोड कर सकते हैं।
अंत में, अंतिम जांच:
सब ठीक है, डेटा बहाल कर दिया गया है।
इस मामले में, हम पूरी प्रक्रिया से नहीं गुजरेंगे। हमने पहले ही वर्णन किया है कि बाइनरी लॉग में डेटा हानि घटना की स्थिति की पहचान कैसे करें। हमने यह भी बताया कि विलंबित दास को कैसे रोका जाए और डेटा हानि घटना से पहले एक बिंदु तक प्रतिकृति को फिर से शुरू किया जाए। हमने यह भी बताया कि बाहरी सर्वर से डेटा निर्यात करने और उसे मास्टर पर लोड करने के लिए SELECT INTO OUTFILE और LOAD DATA INFILE का उपयोग कैसे करें। आपको बस इतना ही चाहिए। जब तक डेटा अभी भी विलंबित दास पर है, तब तक आपको इसे रोकना होगा। फिर आपको डेटा हानि घटना से पहले स्थिति का पता लगाने की आवश्यकता है, उस बिंदु तक दास को शुरू करें और, एक बार ऐसा करने के बाद, हटाए गए डेटा को निकालने के लिए विलंबित दास का उपयोग करें, फ़ाइल को मास्टर में कॉपी करें और डेटा को पुनर्स्थापित करने के लिए इसे लोड करें ।
खोए हुए डेटा को पुनर्स्थापित करना मज़ेदार नहीं है, लेकिन यदि आप इस ब्लॉग में हमारे द्वारा बताए गए चरणों का पालन करते हैं, तो आपके पास जो खोया है उसे पुनर्प्राप्त करने का एक अच्छा मौका होगा।mysqlbinlog --verbose /var/lib/mysql/binlog.000003 > bin.out### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=999296
### @2=1009782
### @3='96260841950-70557543083-97211136584-70982238821-52320653831-03705501677-77169427072-31113899105-45148058587-70555151875'
### @4='84527471555-75554439500-82168020167-12926542460-82869925404'### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=1
### @2=1006036
### @3='123'
### @4='43683718329-48150560094-43449649167-51455516141-06448225399'
### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=2
### @2=1008980
### @3='123'
### @4='05603373460-16140454933-50476449060-04937808333-32421752305'#180427 8:09:21 server id 1 end_log_pos 29600687 CRC32 0x8cfdd6ae Xid = 307686
COMMIT/*!*/;
# at 29600687
#180427 8:09:21 server id 1 end_log_pos 29600752 CRC32 0xb5aa18ba GTID last_committed=42844 sequence_number=42845 rbr_only=yes
/*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/;
SET @@SESSION.GTID_NEXT= '0c695e13-4931-11e8-9f2f-080027e8bf1b:55893'/*!*/;
# at 29600752
#180427 8:09:21 server id 1 end_log_pos 29600826 CRC32 0xc7b71da5 Query thread_id=44 exec_time=0 error_code=0
SET TIMESTAMP=1524816561/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
BEGIN
/*!*/;
# at 29600826
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.03 sec)mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE 'missing.sql';
ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statementmysql> SHOW VARIABLES LIKE "secure_file_priv";
+------------------+-----------------------+
| Variable_name | Value |
+------------------+-----------------------+
| secure_file_priv | /var/lib/mysql-files/ |
+------------------+-----------------------+
1 row in set (0.13 sec)mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE '/var/lib/mysql-files/missing.sql';
Query OK, 23145 rows affected (0.05 sec)example@sqldat.com:~# scp /var/lib/mysql-files/missing.sql 10.0.0.101:/var/lib/mysql-files/
missing.sql 100% 1744KB 1.7MB/s 00:00mysql> LOAD DATA INFILE '/var/lib/mysql-files/missing.sql' INTO TABLE sbtest.sbtest1;
Query OK, 23145 rows affected (2.22 sec)
Records: 23145 Deleted: 0 Skipped: 0 Warnings: 0
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)आंशिक डेटा हानि - तार्किक बैकअप
example@sqldat.com:~# ls -alh /root/backups/BACKUP-13/
total 5.8G
drwx------ 2 root root 4.0K Apr 27 07:35 .
drwxr-x--- 5 root root 4.0K Apr 27 07:14 ..
-rw-r--r-- 1 root root 2.4K Apr 27 07:35 cmon_backup.metadata
-rw------- 1 root root 5.8G Apr 27 07:35 mysqldump_2018-04-27_071434_complete.sql.gzexample@sqldat.com:~# mkdir /root/restore
example@sqldat.com:~# zcat /root/backups/BACKUP-13/mysqldump_2018-04-27_071434_complete.sql.gz > /root/restore/backup.sqlINSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399'),(2,1008980,'69708345057-48265944193-91002879830-11554672482-35576538285-03657113365-90301319612-18462263634-56608104414-27254248188','05603373460-16140454933-50476449060-04937808333-32421752305')example@sqldat.com:~/restore# grep -n "CREATE TABLE \`sbtest1\`" backup.sql > out
example@sqldat.com:~/restore# cat out
971:CREATE TABLE `sbtest1` (example@sqldat.com:~/restore# sed -n '971,993p; 994q' backup.sql > 1.sql
example@sqldat.com:~/restore# tail -n 1 1.sql | lessINSERT INTO `sbtest1` VALUES (31351,1007187,'23938390896-69688180281-37975364313-05234865797-89299459691-74476188805-03642252162-40036598389-45190639324-97494758464','60596247401-06173974673-08009930825-94560626453-54686757363'),INSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399')(23145,1001595,'37250617862-83193638873-99290491872-89366212365-12327992016-32030298805-08821519929-92162259650-88126148247-75122945670','60801103752-29862888956-47063830789-71811451101-27773551230');example@sqldat.com:~/restore# cat 1.sql | mysql -usbtest -psbtest -h10.0.0.101 sbtest
mysql: [Warning] Using a password on the command line interface can be insecure.mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)आंशिक डेटा हानि, विलंबित दास
निष्कर्ष